



We define a framework for social studying wherein LLMs share information with one another in a privacy-aware method utilizing pure language. We consider the effectiveness of our framework on numerous datasets, and suggest quantitative strategies to measure privateness on this setting.
Giant language fashions (LLMs) have considerably improved the cutting-edge for fixing duties specified utilizing pure language, typically reaching efficiency near that of individuals. As these fashions more and more allow assistive brokers, it might be helpful for them to be taught successfully from one another, very similar to individuals do in social settings, which might permit LLM-based brokers to enhance one another’s efficiency.
To debate the training processes of people, Bandura and Walters described the idea of social studying in 1977, outlining completely different fashions of observational studying utilized by individuals. One widespread methodology of studying from others is thru a verbal instruction (e.g., from a trainer) that describes the best way to have interaction in a specific conduct. Alternatively, studying can occur by way of a stay mannequin by mimicking a stay instance of the conduct.
Given the success of LLMs mimicking human communication, in our paper “Social Studying: In direction of Collaborative Studying with Giant Language Fashions”, we examine whether or not LLMs are in a position to be taught from one another utilizing social studying. To this finish, we define a framework for social studying wherein LLMs share information with one another in a privacy-aware method utilizing pure language. We consider the effectiveness of our framework on numerous datasets, and suggest quantitative strategies that measure privateness on this setting. In distinction to earlier approaches to collaborative studying, akin to widespread federated studying approaches that always depend on gradients, in our framework, brokers train one another purely utilizing pure language.
Social studying for LLMs
To increase social studying to language fashions, we think about the situation the place a scholar LLM ought to be taught to resolve a process from a number of trainer entities that already know that process. In our paper, we consider the scholar’s efficiency on a wide range of duties, akin to spam detection in brief textual content messages (SMS), fixing grade faculty math issues, and answering questions primarily based on a given textual content.
A visualization of the social studying course of: A trainer mannequin offers directions or few-shot examples to a scholar mannequin with out sharing its personal information.
Language fashions have proven a outstanding capability to carry out duties given solely a handful of examples–a course of referred to as few-shot studying. With this in thoughts, we offer human-labeled examples of a process that permits the trainer mannequin to show it to a scholar. One of many major use instances of social studying arises when these examples can’t be instantly shared with the scholar due, for instance, to privateness considerations.
As an example this, let’s have a look at a hypothetical instance for a spam detection process. A trainer mannequin is positioned on-device the place some customers volunteer to mark incoming messages they obtain as both “spam” or “not spam”. That is helpful information that would assist practice a scholar mannequin to distinguish between spam and never spam, however sharing private messages with different customers is a breach of privateness and ought to be prevented. To forestall this, a social studying course of can switch the information from the trainer mannequin to the scholar so it learns what spam messages appear to be while not having to share the consumer’s private textual content messages.
We examine the effectiveness of this social studying strategy by analogy with the established human social studying idea that we mentioned above. In these experiments, we use PaLM 2-S fashions for each the trainer and the scholar.
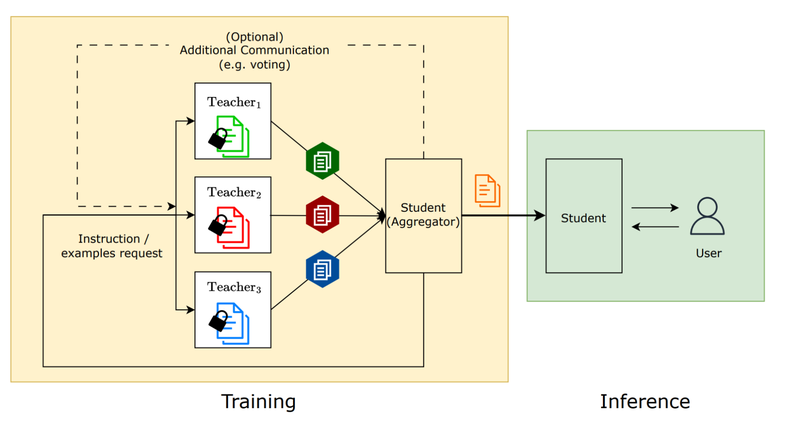
A techniques view of social studying: At coaching time, a number of academics train the scholar. At inference time, the scholar is utilizing what it realized from the academics.
Artificial examples
As a counterpart to the stay educating mannequin described for conventional social studying, we suggest a studying methodology the place the academics generate new artificial examples for the duty and share them with the scholar. That is motivated by the concept one can create a brand new instance that’s sufficiently completely different from the unique one, however is simply as academic. Certainly, we observe that our generated examples are sufficiently completely different from the actual ones to protect privateness whereas nonetheless enabling efficiency corresponding to that achieved utilizing the unique examples.
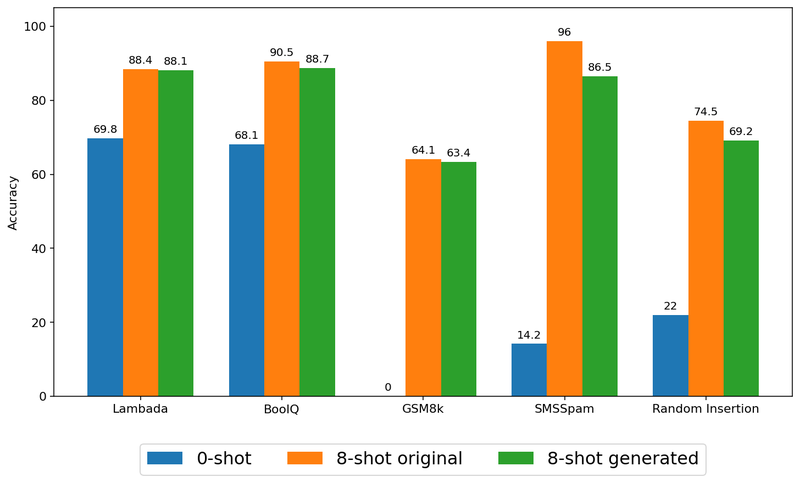
The 8 generated examples carry out in addition to the unique information for a number of duties (see our paper).
We consider the efficacy of studying by way of artificial examples on our process suite. Particularly when the variety of examples is excessive sufficient, e.g., n = 16, we observe no statistically important distinction between sharing authentic information and educating with synthesized information by way of social studying for almost all of duties, indicating that the privateness enchancment doesn’t have to come back at the price of mannequin high quality.
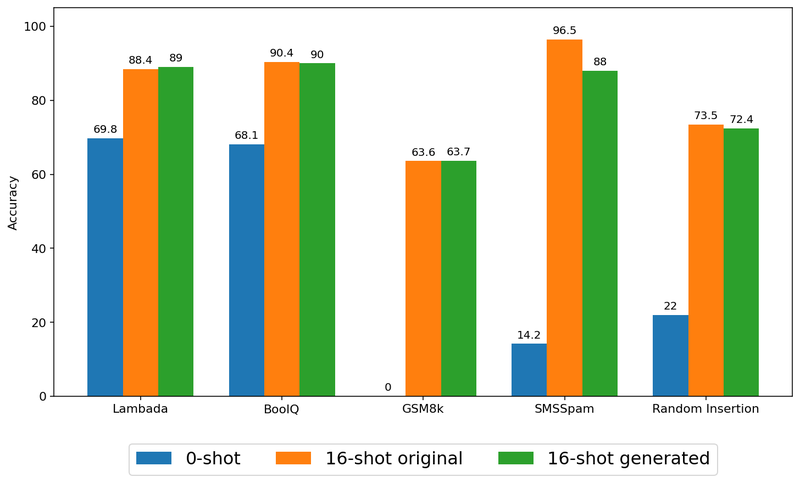
Producing 16 as an alternative of simply 8 examples additional reduces the efficiency hole relative to the unique examples.
The one exception is spam detection, for which educating with synthesized information yields decrease accuracy. This can be as a result of the coaching process of present fashions makes them biased to solely generate non-spam examples. Within the paper, we moreover look into aggregation strategies for choosing good subsets of examples to make use of.
Artificial instruction
Given the success of language fashions in following directions, the verbal instruction mannequin can be naturally tailored to language fashions by having the academics generate an instruction for the duty. Our experiments present that offering such a generated instruction successfully improves efficiency over zero-shot prompting, reaching accuracies corresponding to few-shot prompting with authentic examples. Nonetheless, we did discover that the trainer mannequin might fail on sure duties to supply a great instruction, for instance attributable to a sophisticated formatting requirement of the output.
For Lambada, GSM8k, and Random Insertion, offering artificial examples performs higher than offering generated directions, whereas within the different duties generated instruction obtains a better accuracy. This statement means that the selection of the educating mannequin relies on the duty at hand, just like how the simplest methodology for educating individuals varies by process.
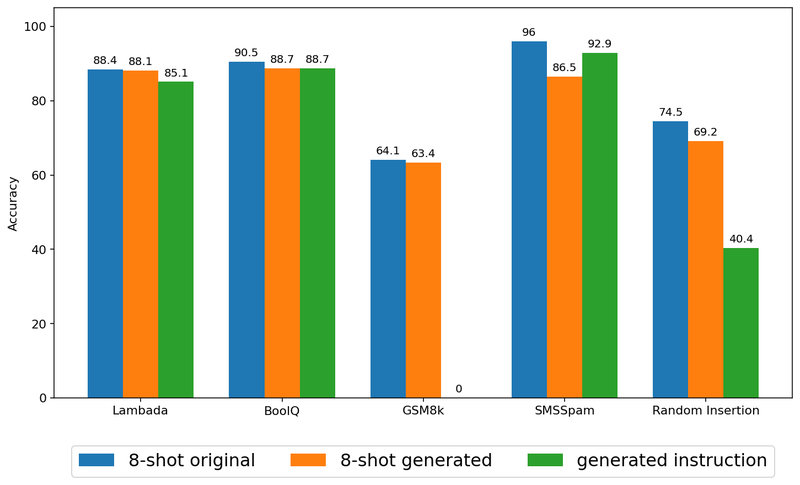
Relying on the duty, producing directions can work higher than producing new examples.
Memorization of the personal examples
We would like academics in social studying to show the scholar with out revealing specifics from the unique information. To quantify how susceptible this course of is to leaking data, we used Secret Sharer, a preferred methodology for quantifying to what extent a mannequin memorizes its coaching information, and tailored it to the social studying setting. We picked this methodology because it had beforehand been used for evaluating memorization in federated studying.
To use the Secret Sharer methodology to social studying, we design “canary” information factors such that we are able to concretely measure how a lot the coaching course of memorized them. These information factors are included within the datasets utilized by academics to generate new examples. After the social studying course of completes, we are able to then measure how rather more assured the scholar is within the secret information factors the trainer used, in comparison with related ones that weren’t shared even with the academics.
In our evaluation, mentioned intimately within the paper, we use canary examples that embrace names and codes. Our outcomes present that the scholar is barely barely extra assured within the canaries the trainer used. In distinction, when the unique information factors are instantly shared with the scholar, the arrogance within the included canaries is way larger than within the held-out set. This helps the conclusion that the trainer does certainly use its information to show with out merely copying it over.
Conclusion and subsequent steps
We launched a framework for social studying that permits language fashions with entry to non-public information to switch information by way of textual communication whereas sustaining the privateness of that information. On this framework, we recognized sharing examples and sharing directions as fundamental fashions and evaluated them on a number of duties. Moreover, we tailored the Secret Sharer metric to our framework, proposing a metric for measuring information leakage.
As subsequent steps, we’re searching for methods of enhancing the educating course of, for instance by including suggestions loops and iteration. Moreover, we wish to examine utilizing social studying for modalities apart from textual content.
Acknowledgements
We want to acknowledge and thank Matt Sharifi, Sian Gooding, Lukas Zilka, and Blaise Aguera y Arcas, who’re all co-authors on the paper. Moreover, we want to thank Victor Cărbune, Zachary Garrett, Tautvydas Misiunas, Sofia Neata and John Platt for his or her suggestions, which tremendously improved the paper. We’d additionally prefer to thank Tom Small for creating the animated determine.
We define a framework for social studying wherein LLMs share information with one another in a privacy-aware method utilizing pure language. We consider the effectiveness of our framework on numerous datasets, and suggest quantitative strategies to measure privateness on this setting.
Giant language fashions (LLMs) have considerably improved the cutting-edge for fixing duties specified utilizing pure language, typically reaching efficiency near that of individuals. As these fashions more and more allow assistive brokers, it might be helpful for them to be taught successfully from one another, very similar to individuals do in social settings, which might permit LLM-based brokers to enhance one another’s efficiency.
To debate the training processes of people, Bandura and Walters described the idea of social studying in 1977, outlining completely different fashions of observational studying utilized by individuals. One widespread methodology of studying from others is thru a verbal instruction (e.g., from a trainer) that describes the best way to have interaction in a specific conduct. Alternatively, studying can occur by way of a stay mannequin by mimicking a stay instance of the conduct.
Given the success of LLMs mimicking human communication, in our paper “Social Studying: In direction of Collaborative Studying with Giant Language Fashions”, we examine whether or not LLMs are in a position to be taught from one another utilizing social studying. To this finish, we define a framework for social studying wherein LLMs share information with one another in a privacy-aware method utilizing pure language. We consider the effectiveness of our framework on numerous datasets, and suggest quantitative strategies that measure privateness on this setting. In distinction to earlier approaches to collaborative studying, akin to widespread federated studying approaches that always depend on gradients, in our framework, brokers train one another purely utilizing pure language.
Social studying for LLMs
To increase social studying to language fashions, we think about the situation the place a scholar LLM ought to be taught to resolve a process from a number of trainer entities that already know that process. In our paper, we consider the scholar’s efficiency on a wide range of duties, akin to spam detection in brief textual content messages (SMS), fixing grade faculty math issues, and answering questions primarily based on a given textual content.
A visualization of the social studying course of: A trainer mannequin offers directions or few-shot examples to a scholar mannequin with out sharing its personal information.
Language fashions have proven a outstanding capability to carry out duties given solely a handful of examples–a course of referred to as few-shot studying. With this in thoughts, we offer human-labeled examples of a process that permits the trainer mannequin to show it to a scholar. One of many major use instances of social studying arises when these examples can’t be instantly shared with the scholar due, for instance, to privateness considerations.
As an example this, let’s have a look at a hypothetical instance for a spam detection process. A trainer mannequin is positioned on-device the place some customers volunteer to mark incoming messages they obtain as both “spam” or “not spam”. That is helpful information that would assist practice a scholar mannequin to distinguish between spam and never spam, however sharing private messages with different customers is a breach of privateness and ought to be prevented. To forestall this, a social studying course of can switch the information from the trainer mannequin to the scholar so it learns what spam messages appear to be while not having to share the consumer’s private textual content messages.
We examine the effectiveness of this social studying strategy by analogy with the established human social studying idea that we mentioned above. In these experiments, we use PaLM 2-S fashions for each the trainer and the scholar.
A techniques view of social studying: At coaching time, a number of academics train the scholar. At inference time, the scholar is utilizing what it realized from the academics.
Artificial examples
As a counterpart to the stay educating mannequin described for conventional social studying, we suggest a studying methodology the place the academics generate new artificial examples for the duty and share them with the scholar. That is motivated by the concept one can create a brand new instance that’s sufficiently completely different from the unique one, however is simply as academic. Certainly, we observe that our generated examples are sufficiently completely different from the actual ones to protect privateness whereas nonetheless enabling efficiency corresponding to that achieved utilizing the unique examples.
The 8 generated examples carry out in addition to the unique information for a number of duties (see our paper).
We consider the efficacy of studying by way of artificial examples on our process suite. Particularly when the variety of examples is excessive sufficient, e.g., n = 16, we observe no statistically important distinction between sharing authentic information and educating with synthesized information by way of social studying for almost all of duties, indicating that the privateness enchancment doesn’t have to come back at the price of mannequin high quality.
Producing 16 as an alternative of simply 8 examples additional reduces the efficiency hole relative to the unique examples.
The one exception is spam detection, for which educating with synthesized information yields decrease accuracy. This can be as a result of the coaching process of present fashions makes them biased to solely generate non-spam examples. Within the paper, we moreover look into aggregation strategies for choosing good subsets of examples to make use of.
Artificial instruction
Given the success of language fashions in following directions, the verbal instruction mannequin can be naturally tailored to language fashions by having the academics generate an instruction for the duty. Our experiments present that offering such a generated instruction successfully improves efficiency over zero-shot prompting, reaching accuracies corresponding to few-shot prompting with authentic examples. Nonetheless, we did discover that the trainer mannequin might fail on sure duties to supply a great instruction, for instance attributable to a sophisticated formatting requirement of the output.
For Lambada, GSM8k, and Random Insertion, offering artificial examples performs higher than offering generated directions, whereas within the different duties generated instruction obtains a better accuracy. This statement means that the selection of the educating mannequin relies on the duty at hand, just like how the simplest methodology for educating individuals varies by process.
Relying on the duty, producing directions can work higher than producing new examples.
Memorization of the personal examples
We would like academics in social studying to show the scholar with out revealing specifics from the unique information. To quantify how susceptible this course of is to leaking data, we used Secret Sharer, a preferred methodology for quantifying to what extent a mannequin memorizes its coaching information, and tailored it to the social studying setting. We picked this methodology because it had beforehand been used for evaluating memorization in federated studying.
To use the Secret Sharer methodology to social studying, we design “canary” information factors such that we are able to concretely measure how a lot the coaching course of memorized them. These information factors are included within the datasets utilized by academics to generate new examples. After the social studying course of completes, we are able to then measure how rather more assured the scholar is within the secret information factors the trainer used, in comparison with related ones that weren’t shared even with the academics.
In our evaluation, mentioned intimately within the paper, we use canary examples that embrace names and codes. Our outcomes present that the scholar is barely barely extra assured within the canaries the trainer used. In distinction, when the unique information factors are instantly shared with the scholar, the arrogance within the included canaries is way larger than within the held-out set. This helps the conclusion that the trainer does certainly use its information to show with out merely copying it over.
Conclusion and subsequent steps
We launched a framework for social studying that permits language fashions with entry to non-public information to switch information by way of textual communication whereas sustaining the privateness of that information. On this framework, we recognized sharing examples and sharing directions as fundamental fashions and evaluated them on a number of duties. Moreover, we tailored the Secret Sharer metric to our framework, proposing a metric for measuring information leakage.
As subsequent steps, we’re searching for methods of enhancing the educating course of, for instance by including suggestions loops and iteration. Moreover, we wish to examine utilizing social studying for modalities apart from textual content.
Acknowledgements
We want to acknowledge and thank Matt Sharifi, Sian Gooding, Lukas Zilka, and Blaise Aguera y Arcas, who’re all co-authors on the paper. Moreover, we want to thank Victor Cărbune, Zachary Garrett, Tautvydas Misiunas, Sofia Neata and John Platt for his or her suggestions, which tremendously improved the paper. We’d additionally prefer to thank Tom Small for creating the animated determine.















{kind=link}