


Paper hyperlink: https://arxiv.org/abs/2412.06769
Launched: ninth of December 2024

a excessive deal with LLMs with reasoning capabilities, and for a very good purpose. Reasoning enhances the LLMs’ energy to sort out complicated points, fosters stronger generalization, and introduces an interpretable layer that sheds mild on a mannequin’s inside thought course of.
A Main milestone in LLM reasoning is the introduction of Chain-of-Thought Reasoning (CoT)[2], which proved that guiding fashions to purpose step-by-step results in important enhancements on arithmetic and symbolic reasoning duties.
Regardless of their energy, reasoning fashions nonetheless function primarily inside the confines of pure language, which may restrict their effectiveness. A lot of the token house is dedicated to sustaining linguistic coherence slightly than facilitating summary reasoning. Addressing this limitation, an intriguing paper from Meta, Coaching Massive Language Fashions to Purpose in a Steady Latent House[1], proposes redeeming the chain of thought out of pure language completely, solely translating again to language when obligatory.
Their contribution may be summarized in three key factors:
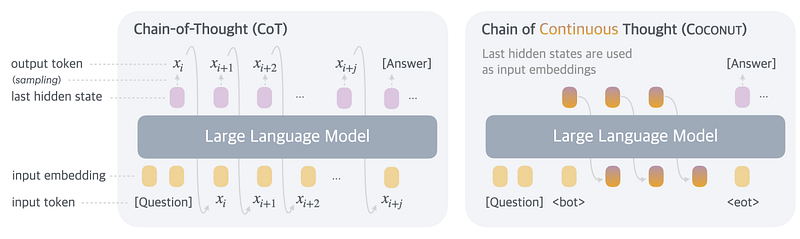
- Chain of Steady Thought (Coconut): An enhanced reasoning paradigm that builds on CoT. As an alternative of counting on the ultimate textual content output, Coconut makes use of the mannequin’s final embedding layer latent representations.
- An exploration of Coconut’s capabilities: indicating how a number of subsequent steps in reasoning may be encoded concurrently within the latent house.
- A deeper evaluation of the latent reasoning course of itself, in order that we are able to perceive Coconut’s inside illustration of data.
Coconut, Simplified
Earlier than delving into the implementation particulars of Steady Chain of Thought, it’s necessary to first set up some foundational grounds.
Given an enter of sequence x = [x(1),x(2),x(3) … ,x(T)] , a Chain-Of-Thought LLM (M), which predicts the subsequent token x(t+1) primarily based on the sequence of earlier tokens x(≤t) may be formally described as:
$$M_{CoT}(x_{t+1}|x<=t) = softmax(Wx_{t})$$
The place W is the burden matrix of our LLM, and x(t) is the enter tokens at step t.
Coconut extends this formulation by eradicating the dependency on textual enter tokens and as a substitute utilizing the mannequin’s final hidden state h(t) as enter. This adaptation modifies the LLM’s predictive operate into:
$$M_{Coconut}(x_{t+1}|x<=t) = softmax(Wh_{t})$$
$$H_{t} = Transformer(E_{t})$$
The place E(t) = [e(x1), e(x2), … e(xt)] represents the sequence of token embeddings, with e(⋅) denoting the embedding operate. H(t) captures the sequence of hidden states for all tokens as much as place t.
This new formulation permits Coconut to function in two distinct modes: Language Mode and Latent Mode, as illustrated in Determine 1 (left and proper, respectively). In Language Mode, the mannequin capabilities like a typical LLM, processing textual tokens as enter, whereas in Latent mode, it operates on the interior hidden states as a substitute.
Mode switching performs a vital function in Coconut’s coaching course of. It not solely allows the mannequin to discover ways to generate significant latent representations but additionally facilitates the decoding of those latent ideas. Mode transitions are managed utilizing two particular placeholder tokens:
$$E_{t}=[e_{x_{1}},e_{x_{2}},….,e_{x_{i}},h_{i},h_{i+1},..,h_{j-1},e_{x_{j}},e_{x_{j+1}},…,e_{x_{t}}]$$

Impressed by [3], Coconut employs a multi-stage coaching curriculum. At every stage okay, okay language-based reasoning steps are changed with L latent steps, the place L=okay⋅c, and c is a hyperparameter figuring out what number of latent steps substitute a single language reasoning step. This development is visualized in Determine 2, the place at stage okay=0, the mannequin trains purely on customary CoT examples.
The creator’s determination to use multi-stage coaching is to decompose the coaching course of into simpler goals, main to raised outcomes. This sample is already advised and backed up in [3], the place they proved that intermediately eradicating tokens enabled deeper internalization of reasoning.
Utilizing latent thought allows end-to-end gradient-based coaching by changing token-level transitions between reasoning steps with steady hidden representations, as with this alteration, the community is absolutely differentiable. Past that, it additionally permits the mannequin to encode a number of potential subsequent steps concurrently, refining the reasoning path because it advances. A deeper exploration of this mechanism is supplied within the Understanding Latent Reasoning part.
For instance, let’s study a easy instance drawn from GSM8K[4], one of many datasets used to coach Coconut.
Query:
“Betty is saving cash for a brand new pockets, which prices $100. Betty has solely half of the cash she wants. Her dad and mom determined to present her $15 for that goal, and her grandparents twice as a lot as her dad and mom. How far more cash does Betty want to purchase the pockets? “
Reasoning steps:
1.Betty has solely 100 / 2 = $<<100/2=50>>50.
2.Betty’s grandparents gave her 15 * 2 = $<<15*2=30>>30.
3.This implies, Betty wants 100–50–30–15 = $<<100–50–30–15=5>>5 extra.
4. Reply: 5
This query is then included into the coaching dataset and used throughout three distinct levels:

As proven in Determine 3, at stage 0, no latent ideas are current, solely language-based reasoning steps adopted by the ultimate reply. In subsequent levels 1 and a couple of, one language reasoning step is progressively changed by one latent thought (since c=1), till stage 3, the place all reasoning steps are latent. This process is utilized to every coaching instance within the dataset.
Key Findings & Evaluation
Three datasets had been used to judge Coconut’s effectiveness. One targeted on mathematical reasoning (GSM8K[4]) and two on logical reasoning: ProntoQA[5] and ProsQA. ProsQA (Proof with Search Query-Answering) is a modified model of ProntoQA, that includes randomly generated directed acyclic graphs (DAGs) of reasoning steps, designed to problem the mannequin with extra complicated planning duties. All fashions had been fine-tuned utilizing GPT-2 as the bottom mannequin, with c=1 for many datasets, aside from GSM8K, the place two latent ideas had been used (c=2).
Under is a simplified abstract of the outcomes reported within the paper:

The fashions used for comparability with the Coconut structure are:
- CoT: Mannequin skilled with Chain-of-Thought reasoning, using full reasoning chains throughout coaching.
- No-CoT: Mannequin skilled with none reasoning chains; customary language modeling with out intermediate reasoning steps.
- Coconut: The complete implementation proposed on this paper.
- w/o curriculum: The Coconut mannequin skilled with out the multi-stage curriculum; i.e., no gradual introduction of latent ideas.
- w/o thought: Coconut with multi-stage coaching retained, however with out introducing latent ideas. Language reasoning steps are merely eliminated over levels as a substitute.
- Pause as thought [6]: Mannequin skilled with out latent ideas completely, however particular
tokens are inserted rather than every eliminated thought. These tokens permit the mannequin extra computation steps earlier than producing a solution. Prior research [7] have reported improved efficiency utilizing this strategy.
A detailed examination of the earlier desk reveals three key insights into the Coconut coaching paradigm.
First, latent reasoning demonstrates superior efficiency over Chain-of-Thought on logical reasoning duties, outperforming it on benchmarks akin to ProntoQA[5] and ProsQA. The substantial accuracy acquire noticed in ProsQA (97.0% vs 77.5%) highlights Coconut’s effectiveness in dealing with extra complicated reasoning challenges. Sadly, the authors didn’t clarify the accuracy loss between CoT and Coconut (42.9% vs. 34.9%). This may very well be as a result of mathematical nature of GSM8k, which, not like ProsQA, requires much less reasoning prowess.
Second, evaluating Coconut with its non-multi-stage coaching counterpart, we attain the identical findings advised by [3]: breaking down the coaching course of into less complicated, extra manageable duties considerably enhances mannequin efficiency. Moreover, by means of evaluating “w/o curriculum” with “w/o thought” implementation, it’s clear that the impact of gradual multi-stage coaching is definitely extra outstanding than simply changing language steps with latent ideas in a single step. That is an attention-grabbing discovering displaying how essential gradual coaching is to the ultimate outcomes.
Lastly, even when supplying the mannequin with multi-stage coaching and sufficient computational capability with the pause as thought mannequin, the LLM nonetheless falls quick in comparison with the principle Coconut implementation. That is extra obvious when evaluating their GSM8K outcomes, reinforcing the speculation that incorporating latent ideas nonetheless boosts coaching effectiveness.
Understanding Latent Reasoning
One of many benefits of Coconut is that, not like language-based ideas, latent ideas have the flexibility to contemplate a number of instructions or outputs of their consideration. This results in a special reasoning course of than regular chaining, permitting us to interpret the reasoning course of as a hypothetical tree search. Every depth layer is the results of a respective latent step okay, and every node is a calculated chance of a selected possibility. This will likely be coated extra in Instance #2.
Two predominant examples of this phenomenon are offered within the paper. We are going to cowl each of them briefly for instance the latent reasoning energy of this new thought paradigm.
Instance #1:
The primary instance demonstrates how a latent thought can include a number of potential outcomes inside its reasoning tree. To discover this, the continual thought generated by the mannequin was decoded utilizing an LLM head, a course of completed solely for testing functions, permitting us to probe the continual thought and confirm whether or not these latent ideas had been being discovered appropriately.
Query:
James decides to run 3 sprints 3 occasions every week. He runs 60 meters every dash. What number of meters does he run every week?
Reasoning Steps:
1. He runs 3*3=9 sprints every week
2. So he runs 9*60=540
Reply: 540
Various Resolution:
1. He runs 3*60=180 meters every week
2. So he runs 3*180=540
After we decode the primary latent thought generated by the mannequin, we discover that the highest three potential outputs are:
1.”180” with a chance of 0.22
2.” 180” ( with an area) with prob. of 0.20
3.”90” with prob. of 0.13
This exhibits that the mannequin is certainly contemplating step one within the two viable options talked about above.
Instance #2:
The second instance provides a clearer illustration of how the tree search is constructed because the variety of ideas will increase, pruning older branches which are now not related to the reasoning course of and prioritizing extra “sound” nodes.

Query:
“Each grimpus is a yimpus. Each worpus is a jelpus. Each zhorpus is a sterpus. Each impus is a hilpus. Each jompus is a …grimpus is a gwompus. Each rempus is a gorpus. Alex is a sterpus. Each zhorpus is a rompus. Is Alex a gorpus or bompus?”
Reasoning Steps:
1.”Alex is a grimpus.”
2. “Each grimpus is a rorpus.”
3.”Each rorpus is a bompus.”
Reply: “Alex is a bompus.”
The chance for every possibility may be obtained by means of the multiplication of each token’s chance, as depicted in Determine 4. Right here we present the state of the search tree after one latent thought (left), and after two (proper).
We will see from the whole calculated chances that in the first step, the least possible possibility (0.01) is sterpus, whereas the second possible possibility is grimpus (0.32), which is the right first step of reasoning on this case. When the search tree is up to date with info from the second thought, the node for sterpus is totally disregarded, and the brand new node with the best chance is rorpus, which is the right second reasoning step.
This proves that Coconut has the ability of together with numerous subsequent steps in its reasoning course of, prioritizing extra necessary steps as we go (much like grimpus in the first step) and disregarding much less related ones (sterpus in the first step). This exhibits that Coconut has the flexibility to navigate a number of ideas in a tree method, till it reaches its remaining conclusion.
Conclusion
On this put up, we have now mentioned Coconut, a brand new reasoning paradigm elevating LLMs from the need of “considering” in language house, and using the latent house as a substitute. We now have mentioned Coconut’s important efficiency in comparison with different reasoning strategies, coated the significance of multi-stage coaching, and given examples to show and perceive how the latent reasoning course of works beneath the hood.
For my part, Coconut addresses an attention-grabbing analysis subject, sparking new exploration into latent reasoning approaches, paving the best way for the creation of extra refined machine reasoning fashions that aren’t sure by language syntax.
References
[1] S. Hao, S. Sukhbaatar, D. Su, X. Li, Z. Hu, J. Weston and Y. Tian, Coaching Massive Language Fashions to Purpose in a Steady Latent House (2024), arXiv preprint arXiv:2412.06769
[2] J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le and D. Zhou, Chain-of-Thought Prompting Elicits Reasoning in Massive Language Fashions (2022), arXiv preprint arXiv:2201.11903
[3] Y. Deng, Y. Choi and S. Shieber, From Specific CoT to Implicit CoT: Studying to Internalize CoT Step by Step (2024), arXiv preprint arXiv:2405.14838
[4] Okay. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse and J. Schulman, Coaching Verifiers to Clear up Math Phrase Issues (2021), arXiv preprint arXiv:2110.14168
[5] A. Saparov and H. He, Language Fashions Are Grasping Reasoners: A Systematic Formal Evaluation of Chain-of-Thought (2022), arXiv preprint arXiv:2210.01240
[6] S. Goyal, Z. Ji, A. S. Rawat, A. Okay. Menon, S. Kumar and V. Nagarajan, Assume Earlier than You Communicate: Coaching Language Fashions With Pause Tokens (2024), arXiv preprint arXiv:2310.02226
[7] J. Pfau, W. Merrill and S. R. Bowman, Let’s Assume Dot by Dot: Hidden Computation in Transformer Language Fashions (2024), arXiv preprint arXiv:2404.15758

















{kind=link}