


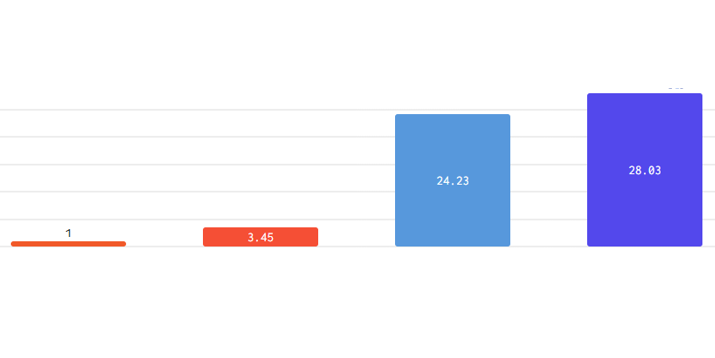
Cerebras Programs right now introduced what it stated is record-breaking efficiency for DeepSeek-R1-Distill-Llama-70B inference, reaching greater than 1,500 tokens per second – 57 occasions sooner than GPU-based options.
Cerebras stated this velocity permits instantaneous reasoning capabilities for one of many business’s most subtle open-weight fashions, working totally on U.S.-based AI infrastructure with zero knowledge retention.
“DeepSeek R1 represents a brand new frontier in AI reasoning capabilities, and right now we’re making it accessible on the business’s quickest speeds,” stated Hagay Lupesko, SVP of AI Cloud, Cerebras. “By reaching greater than 1,500 tokens per second on our Cerebras Inference platform, we’re reworking minutes-long reasoning processes into near-instantaneous responses, basically altering how builders and enterprises can leverage superior AI fashions.”
Powered by the Cerebras Wafer Scale Engine, the platform demonstrates real-world efficiency enhancements. A normal coding immediate that takes 22 seconds on aggressive platforms completes in simply 1.5 seconds on Cerebras – a 15x enchancment in time to outcome. This breakthrough permits sensible deployment of subtle reasoning fashions that historically require intensive computation time.
DeepSeek-R1-Distill-Llama-70B combines the superior reasoning capabilities of DeepSeek’s 671B parameter Combination of Consultants (MoE) mannequin with Meta’s widely-supported Llama structure. Regardless of its environment friendly 70B parameter measurement, the mannequin demonstrates superior efficiency on complicated arithmetic and coding duties in comparison with bigger fashions.
![]() “Safety and privateness are paramount for enterprise AI deployment,” continued Lupesko. “By processing all inference requests in U.S.-based knowledge facilities with zero knowledge retention, we’re making certain that organizations can leverage cutting-edge AI capabilities whereas sustaining strict knowledge governance requirements. Knowledge stays within the U.S. 100% of the time and belongs solely to the shopper.”
“Safety and privateness are paramount for enterprise AI deployment,” continued Lupesko. “By processing all inference requests in U.S.-based knowledge facilities with zero knowledge retention, we’re making certain that organizations can leverage cutting-edge AI capabilities whereas sustaining strict knowledge governance requirements. Knowledge stays within the U.S. 100% of the time and belongs solely to the shopper.”
The DeepSeek-R1-Distill-Llama-70B mannequin is on the market instantly via Cerebras Inference, with API entry obtainable to pick clients via a developer preview program. For extra details about accessing instantaneous reasoning capabilities for functions, go to www.cerebras.ai/contact-us.















{kind=link}