



We dug deep into find out how to finest characterize graphs as textual content so LLMs can perceive them — our investigation discovered three main components that have an effect on the outcomes.
Think about all of the issues round you — your pals, instruments in your kitchen, and even the elements of your bike. They’re all linked in numerous methods. In laptop science, the time period graph is used to explain connections between objects. Graphs include nodes (the objects themselves) and edges (connections between two nodes, indicating a relationship between them). Graphs are all over the place now. The web itself is a big graph of internet sites linked collectively. Even the information search engines like google and yahoo use is organized in a graph-like means.
Moreover, take into account the exceptional developments in synthetic intelligence — similar to chatbots that may write tales in seconds, and even software program that may interpret medical reviews. This thrilling progress is basically due to massive language fashions (LLMs). New LLM expertise is consistently being developed for various makes use of.
Since graphs are all over the place and LLM expertise is on the rise, in “Speak like a Graph: Encoding Graphs for Massive Language Fashions”, offered at ICLR 2024, we current a option to train highly effective LLMs find out how to higher purpose with graph data. Graphs are a helpful option to arrange data, however LLMs are largely skilled on common textual content. The target is to check totally different strategies to see what works finest and acquire sensible insights. Translating graphs into textual content that LLMs can perceive is a remarkably complicated job. The problem stems from the inherent complexity of graph constructions with a number of nodes and the intricate internet of edges that join them. Our work research find out how to take a graph and translate it right into a format that an LLM can perceive. We additionally design a benchmark referred to as GraphQA to check totally different approaches on totally different graph reasoning issues and present find out how to phrase a graph-related downside in a means that allows the LLM to unravel the graph downside. We present that LLM efficiency on graph reasoning duties varies on three basic ranges: 1) the graph encoding methodology, 2) the character of the graph job itself, and three) apparently, the very construction of the graph thought of. These findings give us clues on find out how to finest characterize graphs for LLMs. Choosing the right methodology could make the LLM as much as 60% higher at graph duties!

Pictured, the method of encoding a graph as textual content utilizing two totally different approaches and feeding the textual content and a query in regards to the graph to the LLM.
Graphs as textual content
To have the ability to systematically discover out what’s the easiest way to translate a graph to textual content, we first design a benchmark referred to as GraphQA. Consider GraphQA as an examination designed to judge highly effective LLMs on graph-specific issues. We need to see how nicely LLMs can perceive and remedy issues that contain graphs in numerous setups. To create a complete and lifelike examination for LLMs, we don’t simply use one kind of graph, we use a mixture of graphs making certain breadth within the variety of connections. That is primarily as a result of totally different graph sorts make fixing such issues simpler or tougher. This manner, GraphQA may help expose biases in how an LLM thinks in regards to the graphs, and the entire examination will get nearer to a sensible setup that LLMs would possibly encounter in the true world.
Overview of our framework for reasoning with graphs utilizing LLMs.
GraphQA focuses on easy duties associated to graphs, like checking if an edge exists, calculating the variety of nodes or edges, discovering nodes which can be linked to a selected node, and checking for cycles in a graph. These duties may appear fundamental, however they require understanding the relationships between nodes and edges. By overlaying various kinds of challenges, from figuring out patterns to creating new connections, GraphQA helps fashions learn to analyze graphs successfully. These fundamental duties are essential for extra complicated reasoning on graphs, like discovering the shortest path between nodes, detecting communities, or figuring out influential nodes. Moreover, GraphQA consists of producing random graphs utilizing numerous algorithms like Erdős-Rényi, scale-free networks, Barabasi-Albert mannequin, and stochastic block mannequin, in addition to less complicated graph constructions like paths, full graphs, and star graphs, offering a various set of information for coaching.
When working with graphs, we additionally want to search out methods to ask graph-related questions that LLMs can perceive. Prompting heuristics are totally different methods for doing this. Let’s break down the widespread ones:
- Zero-shot: merely describe the duty (“Is there a cycle on this graph?”) and inform the LLM to go for it. No examples offered.
- Few-shot: That is like giving the LLM a mini apply check earlier than the true deal. We offer a number of instance graph questions and their appropriate solutions.
- Chain-of-Thought: Right here, we present the LLM find out how to break down an issue step-by-step with examples. The aim is to show it to generate its personal “thought course of” when confronted with new graphs.
- Zero-CoT: Just like CoT, however as an alternative of coaching examples, we give the LLM a easy immediate, like “Let’s assume step-by-step,” to set off its personal problem-solving breakdown.
- BAG (construct a graph): That is particularly for graph duties. We add the phrase “Let’s construct a graph…” to the outline, serving to the LLM concentrate on the graph construction.
We explored alternative ways to translate graphs into textual content that LLMs can work with. Our key questions have been:
- Node encoding: How can we characterize particular person nodes? Choices examined embody easy integers, widespread names (individuals, characters), and letters.
- Edge encoding: How can we describe the relationships between nodes? Strategies concerned parenthesis notation, phrases like “are associates”, and symbolic representations like arrows.
Varied node and edge encodings have been mixed systematically. This led to features like those within the following determine:

Examples of graph encoding features used to encode graphs through textual content.
Evaluation and outcomes
We carried out three key experiments: one to check how LLMs deal with graph duties, and two to know how the scale of the LLM and totally different graph shapes affected efficiency. We run all our experiments on GraphQA.
How LLMs deal with graph duties
On this experiment, we examined how nicely pre-trained LLMs sort out graph issues like figuring out connections, cycles, and node levels. Here’s what we realized:
- LLMs battle: On most of those fundamental duties, LLMs didn’t do a lot better than a random guess.
- Encoding issues considerably: How we characterize the graph as textual content has a fantastic impact on LLM efficiency. The “incident” encoding excelled for many of the duties usually.
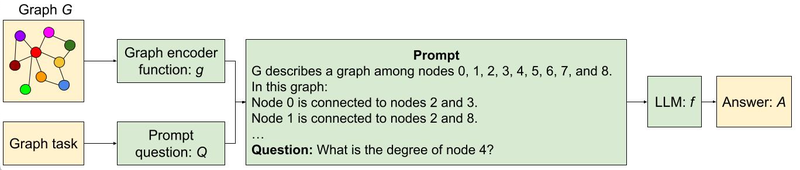
Our outcomes are summarized within the following chart.
Comparability of assorted graph encoder features based mostly on their accuracy on totally different graph duties. The primary conclusion from this determine is that the graph encoding features matter considerably.
Larger is (often) higher
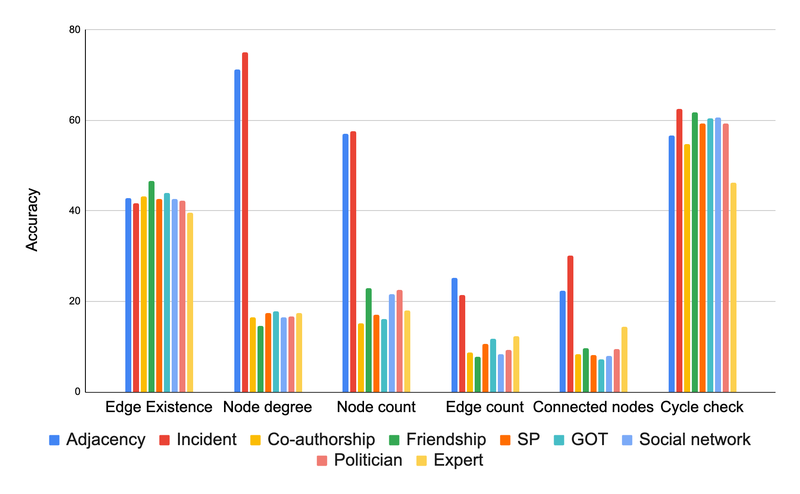
On this experiment, we needed to see if the scale of the LLM (when it comes to the variety of parameters) impacts how nicely they’ll deal with graph issues. For that, we examined the identical graph duties on the XXS, XS, S, and L sizes of PaLM 2. Here’s a abstract of our findings:
- On the whole, larger fashions did higher on graph reasoning duties. It looks as if the additional parameters gave them area to study extra complicated patterns.
- Oddly, dimension did not matter as a lot for the “edge existence” job (discovering out if two nodes in a graph are linked).
- Even the most important LLM could not persistently beat a easy baseline resolution on the cycle examine downside (discovering out if a graph comprises a cycle or not). This exhibits LLMs nonetheless have room to enhance with sure graph duties.
Impact of Mannequin Capability on graph reasoning job for PaLM 2-XXS, XS, S, and L.
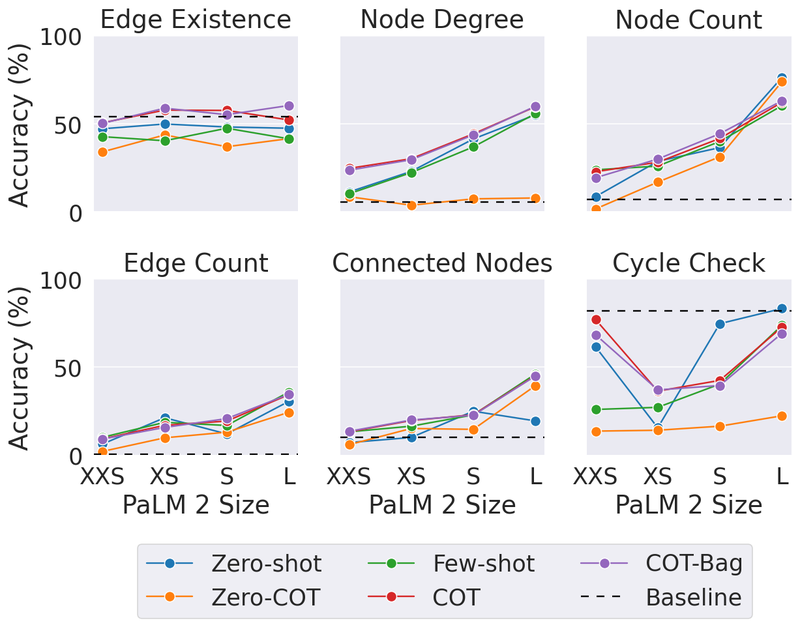
Do totally different graph shapes confuse LLMs
We questioned if the “form” of a graph (how nodes are linked) influences how nicely LLMs can remedy issues on it. Consider the next determine as totally different examples of graph shapes.

We discovered that graph construction has a big effect on LLM efficiency. For instance, in a job asking if a cycle exists, LLMs did nice on tightly interconnected graphs (cycles are widespread there) however struggled on path graphs (the place cycles by no means occur). Apparently, offering some blended examples helped it adapt. For example, for cycle examine, we added some examples containing a cycle and a few examples with no cycles as few-shot examples in our immediate. Related patterns occurred with different duties.
Conclusion
Briefly, we dug deep into find out how to finest characterize graphs as textual content so LLMs can perceive them. We discovered three main components that make a distinction:
- Tips on how to translate the graph to textual content: how we characterize the graph as textual content considerably influences LLM efficiency. The incident encoding excelled for many of the duties usually..
- Process kind: Sure forms of graph questions are usually tougher for LLMs, even with a great translation from graph to textual content.
- Graph construction: Surprisingly, the “form” of the graph that on which we do inference (dense with connections, sparse, and so forth.) influences how nicely an LLM does.
This research revealed key insights about find out how to put together graphs for LLMs. The correct encoding strategies can considerably enhance an LLM’s accuracy on graph issues (starting from round 5% to over 60% enchancment). Our new benchmark, GraphQA, will assist drive additional analysis on this space.
Acknowledgements
We wish to categorical our gratitude to our co-author, Jonathan Halcrow, for his helpful contributions to this work. We categorical our honest gratitude to Anton Tsitsulin, Dustin Zelle, Silvio Lattanzi, Vahab Mirrokni, and your entire graph mining crew at Google Analysis, for his or her insightful feedback, thorough proofreading, and constructive suggestions which drastically enhanced the standard of our work. We’d additionally like to increase particular due to Tom Small for creating the animation used on this publish.
We dug deep into find out how to finest characterize graphs as textual content so LLMs can perceive them — our investigation discovered three main components that have an effect on the outcomes.
Think about all of the issues round you — your pals, instruments in your kitchen, and even the elements of your bike. They’re all linked in numerous methods. In laptop science, the time period graph is used to explain connections between objects. Graphs include nodes (the objects themselves) and edges (connections between two nodes, indicating a relationship between them). Graphs are all over the place now. The web itself is a big graph of internet sites linked collectively. Even the information search engines like google and yahoo use is organized in a graph-like means.
Moreover, take into account the exceptional developments in synthetic intelligence — similar to chatbots that may write tales in seconds, and even software program that may interpret medical reviews. This thrilling progress is basically due to massive language fashions (LLMs). New LLM expertise is consistently being developed for various makes use of.
Since graphs are all over the place and LLM expertise is on the rise, in “Speak like a Graph: Encoding Graphs for Massive Language Fashions”, offered at ICLR 2024, we current a option to train highly effective LLMs find out how to higher purpose with graph data. Graphs are a helpful option to arrange data, however LLMs are largely skilled on common textual content. The target is to check totally different strategies to see what works finest and acquire sensible insights. Translating graphs into textual content that LLMs can perceive is a remarkably complicated job. The problem stems from the inherent complexity of graph constructions with a number of nodes and the intricate internet of edges that join them. Our work research find out how to take a graph and translate it right into a format that an LLM can perceive. We additionally design a benchmark referred to as GraphQA to check totally different approaches on totally different graph reasoning issues and present find out how to phrase a graph-related downside in a means that allows the LLM to unravel the graph downside. We present that LLM efficiency on graph reasoning duties varies on three basic ranges: 1) the graph encoding methodology, 2) the character of the graph job itself, and three) apparently, the very construction of the graph thought of. These findings give us clues on find out how to finest characterize graphs for LLMs. Choosing the right methodology could make the LLM as much as 60% higher at graph duties!
Pictured, the method of encoding a graph as textual content utilizing two totally different approaches and feeding the textual content and a query in regards to the graph to the LLM.
Graphs as textual content
To have the ability to systematically discover out what’s the easiest way to translate a graph to textual content, we first design a benchmark referred to as GraphQA. Consider GraphQA as an examination designed to judge highly effective LLMs on graph-specific issues. We need to see how nicely LLMs can perceive and remedy issues that contain graphs in numerous setups. To create a complete and lifelike examination for LLMs, we don’t simply use one kind of graph, we use a mixture of graphs making certain breadth within the variety of connections. That is primarily as a result of totally different graph sorts make fixing such issues simpler or tougher. This manner, GraphQA may help expose biases in how an LLM thinks in regards to the graphs, and the entire examination will get nearer to a sensible setup that LLMs would possibly encounter in the true world.
Overview of our framework for reasoning with graphs utilizing LLMs.
GraphQA focuses on easy duties associated to graphs, like checking if an edge exists, calculating the variety of nodes or edges, discovering nodes which can be linked to a selected node, and checking for cycles in a graph. These duties may appear fundamental, however they require understanding the relationships between nodes and edges. By overlaying various kinds of challenges, from figuring out patterns to creating new connections, GraphQA helps fashions learn to analyze graphs successfully. These fundamental duties are essential for extra complicated reasoning on graphs, like discovering the shortest path between nodes, detecting communities, or figuring out influential nodes. Moreover, GraphQA consists of producing random graphs utilizing numerous algorithms like Erdős-Rényi, scale-free networks, Barabasi-Albert mannequin, and stochastic block mannequin, in addition to less complicated graph constructions like paths, full graphs, and star graphs, offering a various set of information for coaching.
When working with graphs, we additionally want to search out methods to ask graph-related questions that LLMs can perceive. Prompting heuristics are totally different methods for doing this. Let’s break down the widespread ones:
- Zero-shot: merely describe the duty (“Is there a cycle on this graph?”) and inform the LLM to go for it. No examples offered.
- Few-shot: That is like giving the LLM a mini apply check earlier than the true deal. We offer a number of instance graph questions and their appropriate solutions.
- Chain-of-Thought: Right here, we present the LLM find out how to break down an issue step-by-step with examples. The aim is to show it to generate its personal “thought course of” when confronted with new graphs.
- Zero-CoT: Just like CoT, however as an alternative of coaching examples, we give the LLM a easy immediate, like “Let’s assume step-by-step,” to set off its personal problem-solving breakdown.
- BAG (construct a graph): That is particularly for graph duties. We add the phrase “Let’s construct a graph…” to the outline, serving to the LLM concentrate on the graph construction.
We explored alternative ways to translate graphs into textual content that LLMs can work with. Our key questions have been:
- Node encoding: How can we characterize particular person nodes? Choices examined embody easy integers, widespread names (individuals, characters), and letters.
- Edge encoding: How can we describe the relationships between nodes? Strategies concerned parenthesis notation, phrases like “are associates”, and symbolic representations like arrows.
Varied node and edge encodings have been mixed systematically. This led to features like those within the following determine:
Examples of graph encoding features used to encode graphs through textual content.
Evaluation and outcomes
We carried out three key experiments: one to check how LLMs deal with graph duties, and two to know how the scale of the LLM and totally different graph shapes affected efficiency. We run all our experiments on GraphQA.
How LLMs deal with graph duties
On this experiment, we examined how nicely pre-trained LLMs sort out graph issues like figuring out connections, cycles, and node levels. Here’s what we realized:
- LLMs battle: On most of those fundamental duties, LLMs didn’t do a lot better than a random guess.
- Encoding issues considerably: How we characterize the graph as textual content has a fantastic impact on LLM efficiency. The “incident” encoding excelled for many of the duties usually.
Our outcomes are summarized within the following chart.
Comparability of assorted graph encoder features based mostly on their accuracy on totally different graph duties. The primary conclusion from this determine is that the graph encoding features matter considerably.
Larger is (often) higher
On this experiment, we needed to see if the scale of the LLM (when it comes to the variety of parameters) impacts how nicely they’ll deal with graph issues. For that, we examined the identical graph duties on the XXS, XS, S, and L sizes of PaLM 2. Here’s a abstract of our findings:
- On the whole, larger fashions did higher on graph reasoning duties. It looks as if the additional parameters gave them area to study extra complicated patterns.
- Oddly, dimension did not matter as a lot for the “edge existence” job (discovering out if two nodes in a graph are linked).
- Even the most important LLM could not persistently beat a easy baseline resolution on the cycle examine downside (discovering out if a graph comprises a cycle or not). This exhibits LLMs nonetheless have room to enhance with sure graph duties.
Impact of Mannequin Capability on graph reasoning job for PaLM 2-XXS, XS, S, and L.
Do totally different graph shapes confuse LLMs
We questioned if the “form” of a graph (how nodes are linked) influences how nicely LLMs can remedy issues on it. Consider the next determine as totally different examples of graph shapes.
We discovered that graph construction has a big effect on LLM efficiency. For instance, in a job asking if a cycle exists, LLMs did nice on tightly interconnected graphs (cycles are widespread there) however struggled on path graphs (the place cycles by no means occur). Apparently, offering some blended examples helped it adapt. For example, for cycle examine, we added some examples containing a cycle and a few examples with no cycles as few-shot examples in our immediate. Related patterns occurred with different duties.
Conclusion
Briefly, we dug deep into find out how to finest characterize graphs as textual content so LLMs can perceive them. We discovered three main components that make a distinction:
- Tips on how to translate the graph to textual content: how we characterize the graph as textual content considerably influences LLM efficiency. The incident encoding excelled for many of the duties usually..
- Process kind: Sure forms of graph questions are usually tougher for LLMs, even with a great translation from graph to textual content.
- Graph construction: Surprisingly, the “form” of the graph that on which we do inference (dense with connections, sparse, and so forth.) influences how nicely an LLM does.
This research revealed key insights about find out how to put together graphs for LLMs. The correct encoding strategies can considerably enhance an LLM’s accuracy on graph issues (starting from round 5% to over 60% enchancment). Our new benchmark, GraphQA, will assist drive additional analysis on this space.
Acknowledgements
We wish to categorical our gratitude to our co-author, Jonathan Halcrow, for his helpful contributions to this work. We categorical our honest gratitude to Anton Tsitsulin, Dustin Zelle, Silvio Lattanzi, Vahab Mirrokni, and your entire graph mining crew at Google Analysis, for his or her insightful feedback, thorough proofreading, and constructive suggestions which drastically enhanced the standard of our work. We’d additionally like to increase particular due to Tom Small for creating the animation used on this publish.
















{kind=link}