



[1] examined how highly effective machine studying can look deceptively convincing when the analysis setup is flawed. Nevertheless, in spatial prediction issues, similar to actual property functions involving capital good points estimation, hire forecasting, or value prediction, the issue doesn’t finish with fixing temporal leakage. Even when time is dealt with accurately, fashions can nonetheless seem much better than they are surely if spatial dependence, repeated-asset constructions, and uneven regional protection are ignored. In these settings, the toughest half is commonly not becoming a versatile mannequin, however designing an analysis framework that tells us whether or not the mannequin really generalizes past the neighborhoods, asset varieties, and market segments it has already seen.
Spatial knowledge more and more performs an essential function in guiding sustainable initiatives. Geographic data can be utilized not solely to evaluate actual property values, but in addition to guage territorial vulnerability for city planning and infrastructure funding, optimize logistics and mobility companies, enhance accessibility, and estimate insurance coverage threat to assist forestall main catastrophe losses, amongst different functions. In these contexts, geography isn’t just one other function, it shapes the operational and financial setting wherein outcomes are generated.
Spatial knowledge it’s not organized like strange unbiased rows. It comes with geometry, proximity, adjacency, and dependence. Close by locations usually behave extra equally than distant ones, an thought generally summarized by Tobler’s first regulation of geography: every part is expounded to every part else, however close to issues are extra associated than distant issues [2]. So, in these instances the modeling drawback modifications. Coaching and check samples will not be longer unbiased, repeated geographic items could make forecasting look simpler than true generalization, and uneven protection could make a mannequin seem dependable solely as a result of it’s being judged on dense, well-observed areas.
Despite the fact that, in follow, AutoML and code brokers [3, 4] can now automate most components of the workflow, the toughest components stay human: understanding how spatial dependence, panel construction, and protection form the credibility of the outcomes.
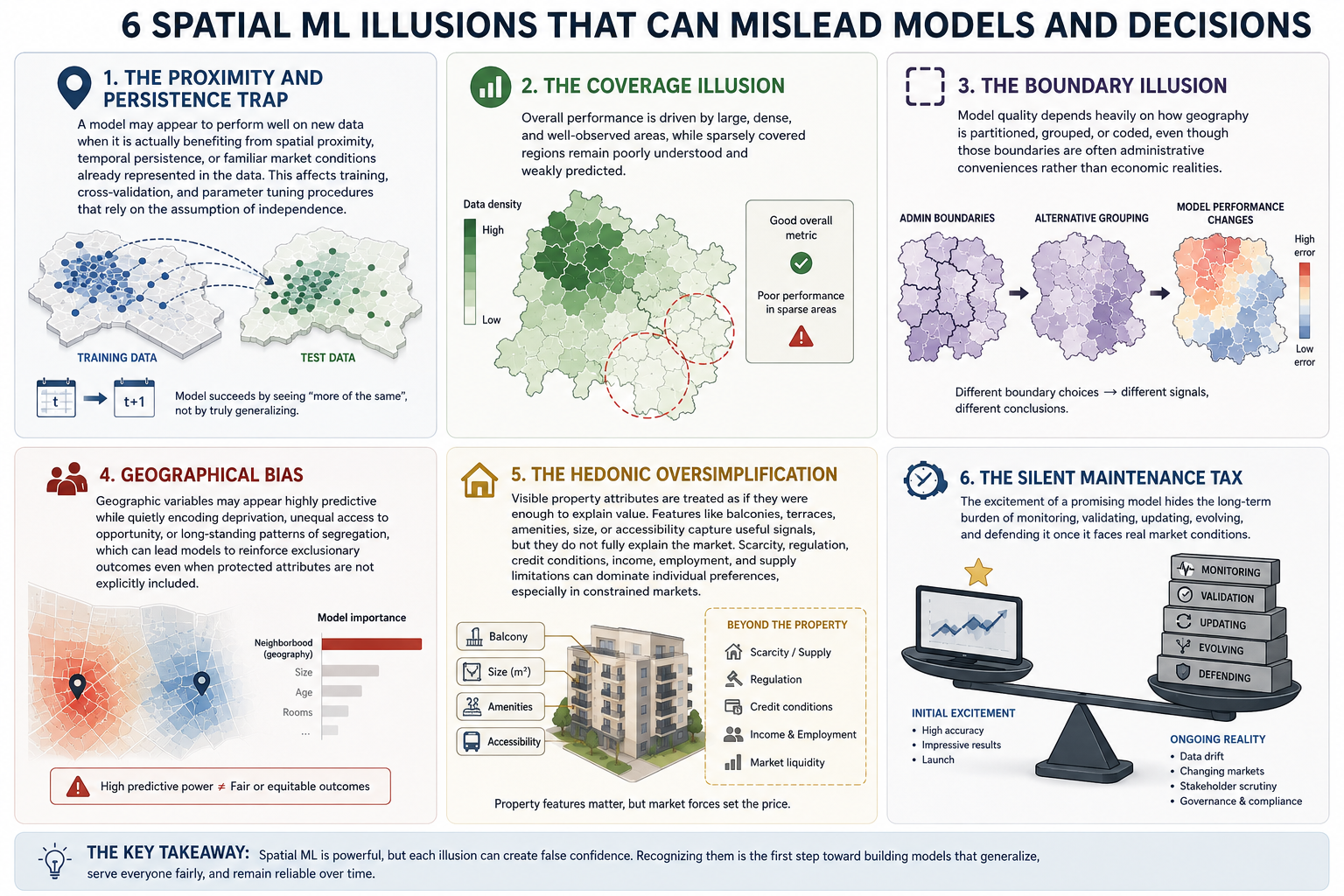
The Spatial Traps
In abstract, the purpose of this text is to supply sensible steerage on the commonest methodological issues that make fashions seem extra generalizable than they are surely:
- The Proximity and Persistence Entice: a mannequin could seem to carry out properly on new knowledge when it’s really benefiting from spatial proximity, temporal persistence, or acquainted market circumstances already offered within the knowledge. This have an effect on coaching, cross-validation, and parameter tuning procedures that depend on the belief of independence.
- The Protection Phantasm: when general efficiency is pushed by massive, dense, and well-observed areas, whereas sparsely lined areas stay poorly understood and weakly predicted.
- The Boundary Phantasm: when mannequin high quality relies upon closely on how geography is partitioned, grouped, or coded, though these boundaries are sometimes administrative conveniences slightly than financial realities.
- Geographical bias: spatial variables could seem extremely predictive whereas quietly encoding deprivation, unequal entry to alternative, or long-standing patterns of segregation, which might lead fashions to bolster exclusionary outcomes even when protected attributes will not be explicitly included.
- The Hedonic Oversimplification: when seen property attributes are handled as in the event that they have been sufficient to elucidate worth. In housing valuation, options similar to balconies, terraces, facilities, measurement, or accessibility could seize helpful value alerts, however they don’t absolutely clarify the market. Shortage, regulation, credit score circumstances, revenue, employment, and provide limitations can dominate particular person preferences, particularly in constrained markets.
- The Silent Upkeep Tax: when the thrill of a promising mannequin hides the long-term burden of monitoring, validating, updating, evolving, and defending it as soon as it faces actual market circumstances.
As spatial knowledge turns into more and more useful in lots of functions, this text goals to listing a number of the issues that may come up in the sort of setting. This isn’t supposed to be an exhaustive listing. For a extra complete evaluation of ML pitfalls throughout completely different drawback settings, see [5]; for a broader dialogue of associated modeling points past this particular context, see a earlier article [1].
Proximity and persistence lure
mannequin shouldn’t solely carry out properly; it ought to enhance on the construction that’s already current within the knowledge. In different phrases, it ought to beat the best baseline. In spatial issues, because of this a significant baseline ought to seize at the least two fundamental mechanisms already prompt by Tobler’s argument: persistence, the place the long run tends to resemble the previous, and spatial autocorrelation, the place close by locations are inclined to behave extra equally than distant ones.
For actual property, hire, or capital acquire prediction, because of this a mannequin can seem sturdy just because costly areas have a tendency to stay costly, dense markets stay dense, and close by property share related financial and spatial circumstances.
On this case, a weak baseline, similar to predicting the worldwide imply, could make a mannequin look spectacular even when it’s only exploiting fundamental spatial reminiscence. Extra significant baselines ought to seize what is out there, such because the earlier worth of the identical space, the historic common of a neighborhood, the typical worth of close by properties, a seasonal naive forecast, a easy hedonic regression, or a fundamental spatial interpolation methodology. These baselines are supposed to symbolize the minimal construction that any critical spatial mannequin ought to enhance upon.
In the identical approach just like the chosen baseline has to absorb consideration the construction of the information, the validation ought to make this as properly. If the practice and check units are cut up randomly, close by observations or repeated geographic items could seem on either side of the cut up. The mannequin is then evaluated on locations that aren’t really unbiased from the information used to coach it. The result’s an error estimate that appears rigorous however is systematically too optimistic. Spatial, temporal, grouped, or blocked validation schemes are sometimes wanted to check whether or not the mannequin can generalize past acquainted areas, acquainted durations, or repeated spatial entities.
Instance:
To make this concept extra concrete, we experiment with the London Home Worth Prediction dataset from Kaggle [6]. The purpose is to not construct the very best home value mannequin, however to point out how the interpretation of efficiency modifications when the validation technique and the baseline change. The goal is the next-month median log value inside the similar area_id + property_type panel.
Desk 1 compares two validation settings. Panel A studies a random cut up, probably the most leakage-prone setting in spatial-temporal prediction issues, as a result of related observations from the identical areas can seem on either side of the cut up. Panel B studies a temporal-spatial holdout, the place the mannequin is skilled on earlier observations from noticed spatial items and examined on future observations from spatial items that weren’t seen throughout coaching. This second setting is deliberately tougher: the mannequin should generalize not solely ahead in time, but in addition to unfamiliar geographies.
To maintain the comparability centered, we use the persistence (time) benchmark as the primary reference level. This benchmark carries ahead the earlier noticed worth and represents a easy however sturdy temporal baseline. We then examine it with a spatiotemporal KNN imply baseline, which makes use of close by historic observations to seize native spatial-temporal construction, and with two predictive fashions: CatBoost, as a powerful non-spatial machine studying mannequin, and GPBoost, as a spatially knowledgeable mannequin that may account for area-level construction. The purpose is to not construct an exhaustive mannequin leaderboard, however to point out how the interpretation of mannequin efficiency modifications when analysis strikes from acquainted observations to unseen geographies.
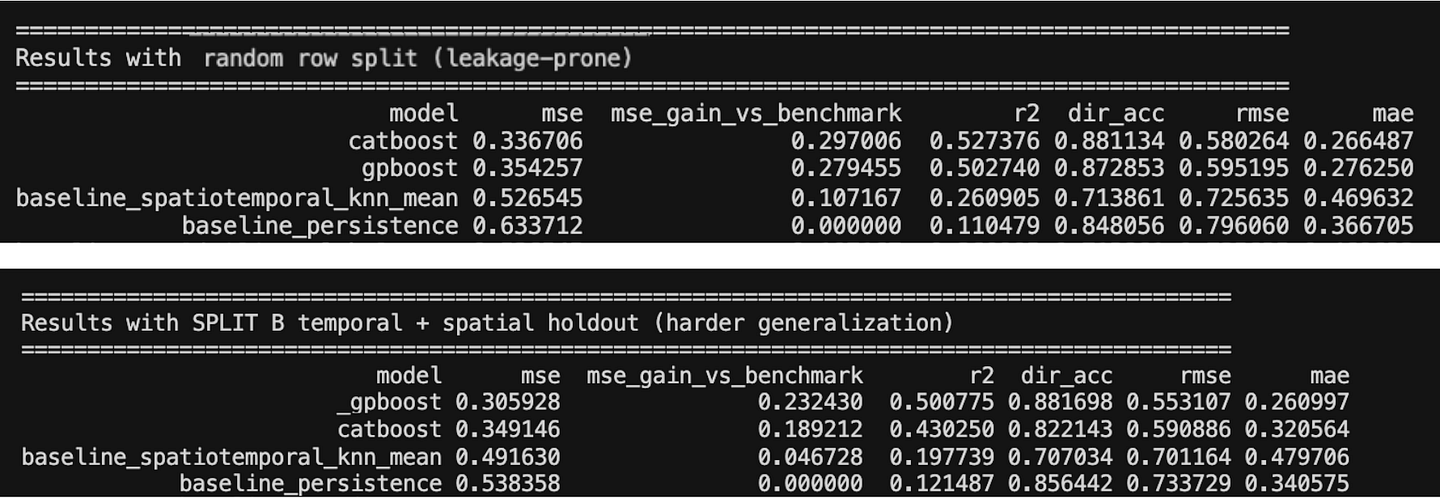
The leads to Desk 1 ought to be learn relative to the persistence benchmark. The metric mse_gain_vs_benchmark is calculated because the MSE of the persistence baseline minus the MSE of every methodology. A constructive worth signifies that the tactic improves over merely carrying ahead the earlier noticed worth, whereas the persistence benchmark itself has a acquire of zero by definition.
This benchmark is essential as a result of the experiment isn’t asking whether or not a posh mannequin can beat a weak international common. It asks whether or not a mannequin can enhance on a easy temporal construction that’s already current within the knowledge. In actual property panels, yesterday’s costly areas usually stay costly tomorrow, so persistence is a significant first hurdle. Nevertheless, persistence primarily captures temporal dependence inside the similar area_id + property_type panel; it doesn’t explicitly mannequin proximity between completely different areas.
For that purpose, the spatiotemporal KNN baseline performs a distinct function. It makes use of close by historic observations to seize native spatial-temporal construction. Collectively, these two baselines assist separate two questions: can the mannequin beat the earlier worth of the identical panel, and may it add worth past a easy rule based mostly on close by historic observations?
Beneath the random cut up, CatBoost achieves the strongest efficiency. Nevertheless, this setting can be probably the most susceptible to the proximity and persistence lure: observations from acquainted areas, market circumstances, or close by areas can seem on either side of the cut up. On this case, sturdy efficiency could replicate the mannequin’s capability to use repeated native construction slightly than its capability to generalize to genuinely new geographies.
The temporal-spatial holdout modifications what’s being examined. Right here, the mannequin is evaluated on future observations from spatial items that weren’t seen throughout coaching. On this setting, the spatio-temporal KNN baseline stays helpful as a result of close by historic areas nonetheless carry sign, however the strongest efficiency comes from GPBoost. This means that explicitly modelling spatial construction could be extra sturdy when the duty requires switch to unseen areas.
The primary takeaway is the proximity and persistence lure: a mannequin can look sturdy when random validation permits it to learn from acquainted temporal and spatial construction already current within the coaching knowledge. The related query is subsequently not solely whether or not the mannequin beats persistence, however whether or not it nonetheless provides worth when acquainted geographies are faraway from the check setting. Random validation could make the mannequin look good for the mistaken purpose; temporal-spatial holdout exams the tougher and extra operationally related query.
Extra to contemplate:
In spatial settings, cross-validation usually fails as a result of observations are linked throughout each area and time. Consequently, typical folds can create two distortions. Throughout mannequin choice, the hyperparameter tuning course of could favor fashions that exploit residual spatial construction or spatial proxies, as an alternative of fashions that switch robustly to unseen geographies. Throughout mannequin evaluation, spatial proximity between practice and check offers the predictor an unauthorized view of the check setting, making error estimates look higher than they are surely.
For these causes, spatial and spatio-temporal issues require validation methods that separate observations in keeping with geography, time, or each. Strategies similar to Spatial+ cross-validation [7] and spatio-temporal resampling [8] are designed to make this separation express, each when estimating last efficiency and when tuning mannequin hyperparameters [9].
The Protection Phantasm
In real-world functions, observations will not be evenly distributed throughout time/area. Some areas are densely represented as a result of they’ve many transactions, many information, or extra frequent knowledge assortment, whereas different areas seem solely sometimes or are nearly absent from the pattern.
This issues as a result of combination error metrics can disguise the place the mannequin is definitely failing. A mannequin could report a low general error just because many of the check set comes from well-covered, high-density areas. In these areas, the mannequin has seen many related examples earlier than, so prediction is less complicated. However this doesn’t imply the mannequin generalizes properly in all places. It might nonetheless carry out poorly in sparse or underrepresented areas, the place the native market construction is much less seen within the knowledge.
On this sense, good common efficiency can create a false sense of reliability. The mannequin seems to be steady as a result of it’s being evaluated largely the place the information is considerable. The true weak spot solely seems when efficiency is damaged down geographically: some areas are properly realized, whereas others stay nearly invisible to the mannequin.
For instance, dangerous modeling choices like eradicating observations with lacking future targets, excluding low-transaction areas, computing spatial aggregates utilizing future data, or choosing solely areas with enough historic information can systematically scale back the illustration of sparse areas. These choices usually enhance the obvious high quality of the dataset whereas concurrently making the prediction activity simpler. Consequently, reported efficiency could replicate a progressively curated subset of well-covered areas slightly than the true geographic range of the issue. Protection ought to subsequently be monitored all through your complete machine studying pipeline, since each processing step has the potential to change the spatial distribution of the information and introduce hidden optimism into the ultimate analysis.
The Boundary Phantasm
What seems to be like a dependable geographical sign could partly be a product of the boundaries chosen for the evaluation. Take into account actual property costs. A mannequin could use the typical value of a district as a geographic function, assuming that properties inside the identical district share the same market context. However this assumption could be deceptive. Two streets inside the similar administrative district could behave very in a different way if one is shut to move, faculties, parks, business exercise, or high-demand housing inventory, whereas the opposite is uncovered to poor connectivity, decrease liquidity, or weaker purchaser demand. Nevertheless, when the information is aggregated on the metropolis stage, these native variations are averaged out. Town could seem extra steady and homogeneous than it truly is. On the regional stage, the smoothing impact turns into even stronger, doubtlessly creating the phantasm if uniformity throughout the entire area.
That is the place the Boundary Phantasm turns into essential. The geographical boundaries used within the evaluation (postcode, metropolis, area, and so forth.) could look pure or goal, however they’re usually administrative decisions.
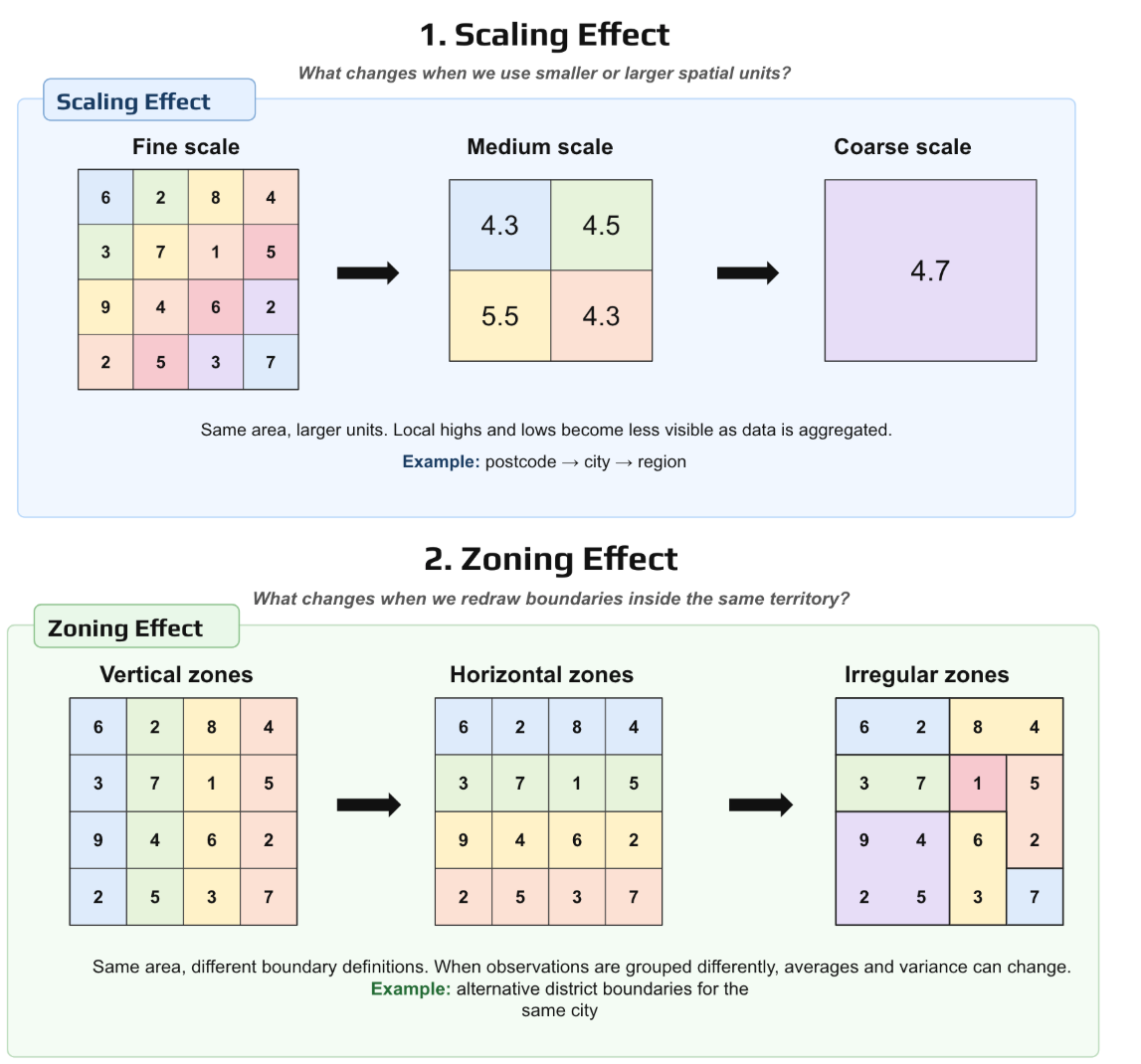
The Determine 2 helps to illustrates this, the highest a part of the determine exhibits the scaling impact. The underlying values are the identical, however they’re aggregated into more and more bigger spatial items: from a fantastic scale to a medium scale after which to a rough scale. Because the items turn into bigger, native highs and lows are smoothed out. The common could stay related, however essential spatial element disappears. In a housing or banking instance, because of this a dangerous pocket seen at postcode stage could disappear as soon as the information is averaged at metropolis or regional stage.
The underside a part of the determine exhibits the zoning impact. Right here, the general space and tough scale keep related, however the boundaries are redrawn in several methods: vertical, horizontal, or irregular zones. The observations are the identical, but the averages and variances change as a result of completely different households, properties, or debtors are being grouped collectively. A mannequin constructed on these aggregated options could subsequently change not as a result of actuality modified, however as a result of the analyst selected a distinct method to partition area.
The sensible implication is {that a} sturdy pipeline ought to check the identical variables and fashions at a number of spatial scales and, when potential, underneath different zoning techniques, to examine whether or not the conclusions stay steady.
Geographical bias
A extra refined drawback seems when geography isn’t solely a supply of dependence, but in addition a proxy for social construction. In lots of real-world datasets, location variables similar to ZIP code, neighborhood, census space, department territory, or regional market will not be impartial coordinates. They usually encode variations in revenue and demographic composition.
This creates what we will name the Geographic Proxy Entice: a mannequin could not use a protected attribute (like etnicity) straight, but nonetheless reproduce unequal therapy as a result of spatial options are correlated with that attribute. On this state of affairs, the mannequin can seem technically legitimate whereas producing systematically completely different error charges throughout teams.
For instance, in a insurance coverage fraud referral mannequin, the mannequin could study that claims coming from sure ZIP codes usually tend to be suspicious as a result of these areas have traditionally been related to greater investigation charges, denser reporting, or completely different declare patterns. Even when ethnicity is rarely included as a function, ZIP-level demographics could make location behave as an oblique proxy. The consequence isn’t essentially seen in international accuracy, AUC, or raise. It seems once we examine mannequin errors throughout teams: false constructive charges, false unfavorable charges, residuals, or misclassification chances.
Almajed et. al. (2025)[11] present a helpful instance of how equity points can come up on home value prediction. Since particular person race or ethnicity isn’t normally obtainable in this type of dataset, the authors outline protected-group comparisons utilizing census tract composition, distinguishing properties situated in majority White, majority non-Hispanic, and majority non-Hispanic White areas. Their outcomes present:
- home value prediction fashions can show completely different ranges of racial and ethnic bias, even when protected attributes will not be straight included as predictors;
- some algorithms are extra delicate to bias than others; on this case, Random Forest confirmed the very best bias when race and ethnicity have been thought of collectively;
- in-processing mitigation (add equity penalties and constraints throughout coaching to cut back bias), was more practical than pre-processing on this setting.
The significance of the research is that it exhibits how census-tract-level options, when used, can enhance predictive accuracy whereas additionally carrying racial, ethnic, and socioeconomic construction. This makes equity analysis mandatory even in apparently impartial regression issues similar to actual property valuation.
The Hedonic Oversimplification
A hedonic mannequin treats the value of a property as a operate of its attributes and surrounding context. These attributes could embrace measurement, variety of rooms, age, flooring stage, terrace, storage, distance to the town middle, entry to move, college high quality, inexperienced area, neighborhood revenue, or different native socioeconomic circumstances.
This strategy is helpful as a result of it makes the pricing drawback interpretable. As an alternative of treating value as a black field, a hedonic mannequin permits us to ask how completely different traits are related to worth. For instance, it may assist estimate whether or not properties with a terrace are usually dearer, whether or not proximity to public transport issues, or whether or not neighborhood traits are associated to greater costs.
The issue isn’t the hedonic thought itself. The issue is the oversimplification that may include it. Housing costs will not be shaped solely by a hard and fast listing of observable variables. Consumers consider properties as bundles of traits embedded in an area context: mild, noise, perceived security, constructing situation, road high quality, neighborhood status, shortage, future expectations, and plenty of different economical elements that is probably not absolutely captured within the knowledge.
Even when an attribute is noticed, its which means could change throughout area. A terrace could also be extremely valued in dense central neighborhoods, however much less distinctive in suburban areas the place outside area is already frequent. Being near the town middle could enhance worth in a single market, whereas in one other it might be related to congestion, noise, or older housing inventory. The similar variable doesn’t at all times carry the identical financial which means in all places.
This is the reason spatial fashions matter. Spatial hedonic fashions and Geographically Weighted Regression don’t clear up the total complexity of housing markets, however they make one essential limitation seen: relationships between attributes and costs can fluctuate throughout geography. A world mannequin assumes that every variable has one common impact throughout the entire research space. A neighborhood spatial mannequin exhibits that these results could also be stronger, weaker, and even completely different relying on the situation.
The hedonic oversimplification, subsequently, isn’t using housing attributes to elucidate value. It’s the assumption {that a} fastened set of noticed attributes can absolutely clarify property values with steady meanings throughout area. Hedonic fashions could be helpful and interpretable, however their interpretability shouldn’t be mistaken for completeness.
The Silent Upkeep Tax
A mannequin doesn’t turn into helpful just because it performs properly in growth. As soon as it’s uncovered to actual market circumstances, it turns into a residing system. The true problem, then, isn’t solely to construct a mannequin that predicts properly as soon as. It’s to construct a mannequin that may survive contact with actuality: one that may be monitored when the information modifications, up to date when the market shifts, interpreted when customers problem it, and defended when its outputs affect financial choices.
That is particularly essential in actual property and different spatial-economic issues. A mannequin is at all times an estimate, not a direct statement of the market. It combines measured attributes with imperfect proxies for location, liquidity, demand, provide constraints, credit score circumstances, regulation, and native expectations. These proxies could be helpful as a result of they assist detect modifications rapidly, however they’ll additionally turn into fragile when the underlying market modifications. A function that after captured a steady native sample could later turn into outdated, biased, or deceptive.
For that purpose, the best operational query isn’t whether or not the mannequin can substitute discipline information. It can not. The higher query is how the mannequin and discipline intelligence ought to work collectively. Mannequin outputs can spotlight the place costs, demand, or threat look like altering sooner than anticipated, whereas native specialists can validate whether or not these modifications replicate actual market dynamics, knowledge artifacts, one-off transactions, or lacking context. On this sense, the mannequin isn’t the ultimate authority; it’s an early-warning system that helps focus consideration.
That is the place interpretability turns into greater than a technical add-on. It’s a part of mannequin accountability. Function attribution, segment-level diagnostics, spatial error maps, uncertainty estimates, drift monitoring, and knowledgeable evaluation assist decide whether or not the mannequin is studying a transferable financial sign or exploiting fragile construction within the knowledge. A mannequin that performs properly however can’t be defined, monitored, or challenged could also be spectacular as an experiment, however weak as a call system.

Conclusion
The traps mentioned right here will not be uncommon or unique. Beneath strain to ship rapidly, even skilled practitioners can miss them. Typically probably the most harmful errors will not be apparent bugs, however reasonable-looking modeling decisions that make the modeling course of simpler whereas lacking the true purpose: generalization.
These points are sometimes discovered when auditing fashions or reviewing experiments, and they’re more and more being offered within the literature [3, 12] as recurring traps to keep away from: knowledge leakage, weak baselines, uneven regional protection hidden behind combination metrics, and options that encode spatial proxies that would have reputational penalties when the mannequin is run in manufacturing.
This isn’t an exhaustive listing. It’s a sensible set of points value retaining in thoughts throughout evaluation.
References
References so as of look:
[1] Gomes-Gonçalves, E. (2026, Might 1). Why highly effective machine studying is deceptively simple. In the direction of Information Science. Hyperlink
[2] Tobler, W. R. (1970). A pc film simulating city progress within the Detroit area. Financial Geography, 46 (Complement), 234–240.
[3] Trirat, P., Jeong, W., & Hwang, S. J. (2024). Automl-agent: A multi-agent llm framework for full-pipeline automl. arXiv preprint arXiv:2410.02958.
[4] Abhyankar, N., Shojaee, P., & Reddy, C. Ok. (2025). Llm-fe: Automated function engineering for tabular knowledge with llms as evolutionary optimizers. arXiv preprint arXiv:2503.14434.
[5] Lones, M. A. (2024). Avoiding frequent machine studying pitfalls. Patterns, 5(10), 101046. https://doi.org/10.1016/j.patter.2024.101046
[6] Wright, J. (2024). London Home Worth Prediction: Superior Methods [Competition dataset]. Kaggle. https://www.kaggle.com/competitions/london-house-price-prediction-advanced-techniques
[7] Wang, Y., Khodadadzadeh, M., & Zurita-Milla, R. (2023). Spatial+: A brand new cross-validation methodology to guage geospatial machine studying fashions. Worldwide Journal of Utilized Earth Commentary and Geoinformation, 121, 103364. https://www.sciencedirect.com/science/article/pii/S1569843223001887
[8] Schratz, P., Becker, M., Lang, M., & Brenning, A. (2024). Mlr3spatiotempcv: Spatiotemporal resampling strategies for machine studying in R. Journal of Statistical Software program, 111, 1–36. https://www.jstatsoft.org/article/view/v111i07
[9] Schratz, P., Muenchow, J., Iturritxa, E., Richter, J., & Brenning, A. (2018). Efficiency analysis and hyperparameter tuning of statistical and machine-learning fashions utilizing spatial knowledge. arXiv preprint arXiv:1803.11266. https://arxiv.org/abs/1803.11266
[10] Gopal, S., & Pitts, J. (2025). The FinTech revolution: Bridging geospatial knowledge science, AI, and sustainability. Springer Cham. https://doi.org/10.1007/978-3-031-74418-1
[11] Almajed, A., Tabar, M., & Najafirad, P. (2025, July). Machine Studying Equity in Home Worth Prediction: A Case Examine of America’s Increasing Metropolises. In Proceedings of the ACM SIGCAS/SIGCHI Convention on Computing and Sustainable Societies (pp. 473–480).
[12] Kapoor, S., & Narayanan, A. (2023). Leakage and the reproducibility disaster in machinelearning-based science. Patterns. 2023; 4 (9): 100804. Hyperlink.
















{kind=link}