



, 343-line tour of CUDA Prime-Okay retrieval. This kernel, CPU oracle, and benchmark suite show that the usual Agentic RAG round-trip—bouncing queries throughout the PCIe bus—is the silent killer of your pipeline. By holding similarity search resident on machine reminiscence, this structure achieves an 8.6x speedup over optimized CPU baselines even on a 7-year-old GTX 1080.
That is Half 3 of the “Manufacturing-Grade Agentic Inference” sequence. Every half removes one type of redundant work from an agentic LLM pipeline. Half 1 killed redundant prefill. Half 2 killed redundant ready — how a number of micro-agents share one GPU by way of time-slicing. Half 3 (this publish) retains RAG retrieval on the GPU with a customized CUDA Prime-Okay kernel. Half 4 persists agent state throughout hand-offs so the subsequent agent by no means has the cold-start drawback.
Key Takeaways
The issue: in agentic RAG, each instrument name that wants context fires a similarity search. A default pipeline ships the question embedding from the GPU to Python, lets the CPU rating N corpus rows and choose the perfect Okay, then ships the reply again. That round-trip is the silent tax. The compute is ok; the journey is the invoice. Everyone knows, journey isn’t low-cost, regardless of the place you wish to go (pun supposed!)
The simple repair: add the corpus to VRAM as soon as, then maintain the similarity scoring, the Prime-Okay choice, and the merge step on the machine. Solely the tiny per-query embedding (D floats) and the Okay outcomes journey throughout PCIe.
The receipts: on the identical 7-year-old GTX 1080 utilized in Components 1 and a pair of, the GPU-resident path runs the retrieval hop as much as 8.57× quicker than a CPU brute-force baseline. At Okay=8 it wins on all 15 sweep configurations (N ∈ {10k, 50k, 100k, 500k, 1M}, D ∈ {384, 768, 1024}) with speedups from 2.43× to eight.57×. At Okay=32 it wins on 13 of 15 configs, peaking at 7.76×. At Okay=100 — the place the V1 selector deliberately stays easy — the CPU wins on 14 of 15 configs. That final sentence is the sincere half (Properly, even when I had lied, you could possibly have simply caught it).
The kicker: the wins are usually not “magic kernel” wins. They’re “we stopped transport the corpus again to host RAM for no cause” wins. It is usually precisely the type of “measure many candidates, report solely the perfect Okay again to the buyer” choice a 5G base station and your telephone have been making each few milliseconds since CSI suggestions grew to become a factor.
TL;DR: Default agentic RAG treats the GPU as a serving field and the retrieval as a Python concern. Each instrument name ships the question embedding D→H, lets the CPU compute N dot merchandise, type the candidates, choose the highest Okay, and ship indices and scores H→D. For an agent that calls a vector retailer ten occasions per reasoning step, that round-trip is the dominant price — not the mannequin, not the embedding, it’s the journey. CUDA-TopK-Retrieval retains the corpus resident on the machine, runs scoring + per-block partial Prime-Okay + a multi-way merge totally on the GPU, and exposes a tiny C++ orchestrator API (upload_corpus_rowmajor as soon as, search_resident per question). The host-touching bytes per question collapse to at least one D-length embedding up and 2K outcomes down. On a GTX 1080, throughout a 45-config sweep, the GPU-resident path beats the CPU-round-trip baseline on all 15 Okay=8 configs (2.43× to eight.57×, peaking at N=1M, D=1024) and on 13 of 15 Okay=32 configs (the 2 losses are each on the smallest N=10k for D=384 and D=768, the place the round-trip itself is already low-cost; big-N Okay=32 wins climb to 7.76×). At Okay=100 the V1 kernel intentionally stays easy — single-lane-per-block bubble type with a serial merge — and the CPU wins on 14 of 15 configs; that ceiling is the article’s sincere punchline and a clear setup for Half 4.
GitHub Repo: https://github.com/AnubhabBanerjee/cuda-topk-retrieval
(Fast confession earlier than we begin: I got here at this from a 5G/6G RAN engineering background. Beam choice at a base station seems shockingly near RAG Prime-Okay — the UE scores a codebook of candidate beams by obtained energy and studies the perfect handful again over the air. There’s a complete part on that beneath — part 8 — however additionally it is why this kernel exists within the form it does.)
Structure psychological mannequin — maintain this open when you learn.
agent.embed(question) → cudaMemcpy H→D (D floats) → row_dot_scores_kernel → partial_topk_block_kernel (P blocks) → merge_partial_topk_kernel → cudaMemcpy D→H (Okay indices + Okay scores)
All the pieces beneath is simply commentary on one a part of that line.

1. A confession: each RAG step in your agent is a tiny PCIe highway journey
In Half 2 of this sequence, we efficiently remoted our LLM agent’s inference loop, holding token technology operating scorching and quick on the machine. We designed a system which avoids stalling. However the second we give that agent a instrument to go looking an exterior data base—the core of any multi-hop Retrieval-Augmented Technology (RAG) pipeline—we silently destroy all that hard-won efficiency and we hit the wall. When you’ve got ever wired an “agentic” pipeline to a vector retailer by way of a Python retriever, here’s what actually occurs on every instrument name (with slightly intentional dramatization):
You: “Agent, discover me the 5 chunks most related to ‘how do I declare deduction below part 80C?’“
Agent: “Certain. Embedding the question on the GPU. ✅”
Agent: “Now bouncing the question embedding again to host.”
(cudaMemcpy D→H, ~1,024 floats) Python retriever: “Acquired it. NumPy loop. Dot product N occasions. argpartition. Prime-5.”
(CPU scores half 1,000,000 corpus rows, one row at a time, whereas a 9 TFLOP GPU watches) Python retriever: “Accomplished. Listed below are the indices and scores.”
Agent: “Cool. Bouncing them again to the GPU now.”
(cudaMemcpy H→D, 10 numbers) Agent: “Prepared. What was the query once more?”
The agent has a wonderfully good GPU. The corpus is sitting in 4 GB of the VRAM. The question embedding was already on the GPU — we simply generated it there. After which, on each single retrieval hop, we ship the question again to the host, do brute-force similarity in NumPy / FAISS-on-CPU / a hand-rolled loop, and ship the reply again.
Your GPU’s utility meter: spends many of the retrieval step idle. Your PCIe bus: will get a exercise it didn’t join. Your agent’s tool-call latency: dominated by one thing that’s neither the mannequin nor the embedding. That’s the joke.
That can be the soiled secret of each agentic RAG demo that scales previous the toy “ten chunks in reminiscence” stage. The retrieval hop bounces off the GPU and again, each time, and the larger the corpus, the more serious the tax. At 1,000,000 rows of 1024-dim embeddings, the round-trip alone — not even the scoring, sure, simply the round-trip — eats many of the funds of the retrieval step itself.
CUDA-TopK-Retrieval is what occurs if you determine the round-trip is optionally available and you’d slightly write 343 strains of CUDA than let the agent trip by way of host RAM each time it desires a neighbor.
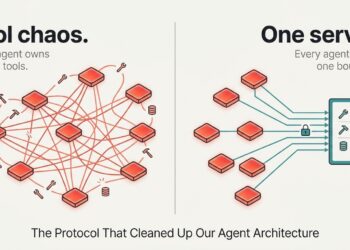
Now think about the actual workload behind this. It’s not “5 chunks for one query.” It’s a number of specialised micro-agents — each operating its personal RAG hops, each needing Prime-Okay in opposition to the identical corpus, each at present paying its personal PCIe invoice on each instrument name. Half 1 of this sequence killed the prefill round-trip. Half 2 made the GPU shareable throughout these a number of brokers. Half 3 says: now that they’re sharing the cardboard pretty, cease making every certainly one of them drive again to the host to search for a neighbor.
2. Why does Prime-Okay retrieval exist? (a one-minute crash course)
Skip this if you have already got a background on this. For everybody else, who’re new to this area, here’s a brief, newbie rationalization.
A contemporary agent doesn’t stuff the entire data base into the immediate. It retrieves. For each reasoning step that wants grounded context, it embeds the question right into a fixed-dimensional vector (D floats — sometimes 384, 768, or 1024), scores that vector in opposition to each row of a corpus of pre-embedded chunks (N rows, additionally D floats every), and returns the Okay corpus rows with the very best similarity. That’s it. That’s Prime-Okay vector search. Retrieval-Augmented Technology is only a well mannered approach of claiming “Prime-Okay plus a immediate template.”
Two flavors of similarity present up in all places. Dot product is a budget one: a single fused multiply-add per dimension, N×D work in complete. Cosine is dot product divided by the product of L2 norms, which turns into a free dot product should you pre-normalize the corpus as soon as at ingest. Most manufacturing vector shops do the pre-normalization trick and name it “cosine” whereas operating uncooked dot-product math at question time. The CUDA-TopK-Retrieval kernel helps each — it simply multiplies by a precomputed per-row norm pointer when cosine mode is on.
Mainstream instruments (FAISS, hnswlib, the Python aspect of cuVS, your favourite SaaS vector DB) all do that scoring + Prime-Okay work. Most of them do it properly. The issue is the place they do it. Virtually each agent framework on the planet calls into the retriever from Python, and the second Python is on the recent path, the retrieval step is now not a GPU operation — it’s a PCIe operation with a GPU on one finish.
The repair shouldn’t be “a greater algorithm.” It’s “a a lot shorter highway journey.”
3. The “simply maintain the corpus on the GPU” lightbulb (and why it’s tougher than it sounds)
The pitch is straightforward
- Add the corpus to VRAM as soon as at ingest.
- For each incoming question,
cudaMemcpya tinyD-dimensional float embedding to the machine. - Launch a scoring kernel the place one CUDA thread per corpus row computes the dot product.
- Launch a partial Prime-Okay kernel the place every block scans a disjoint row vary to emit its personal native high candidates.
- Lastly, launch a merge kernel to stroll the per-block heads and emit the worldwide Prime-Okay in best-first order.
You cudaMemcpy precisely 2K numbers again to the host: Okay indices, and Okay scores.
That is the “deal with reminiscence retrieval as a {hardware} primitive, not a software program API name” paradigm. The one cause this takes greater than a 30-line PyTorch script to attain is that three tedious edge instances will instantly break the naive method.
Downside A: Prime-Okay on a GPU is structurally awkward
Scoring the vectors is the simple half. It’s simply matrix multiplication, and your GPU was actually born to try this—it’s the {hardware}’s love language. Choice, nevertheless, is the place the romance dies. Asking a GPU to do a full O(N log N) type simply to seize the highest Okay outcomes is computationally offensive; it’s like alphabetizing your complete recycling bin simply to discover a single receipt. You can strive an O(N) argpartition, however that requires a tree-walk, which shatters GPU reminiscence coalescing into 1,000,000 unaligned reads. Event choice is quick, assuming you wish to spend your weekend debugging edge instances. And the second you cave and attain for a thrust or cub sorting primitive, congratulations: you’ve got simply contaminated your light-weight, standalone C++ pipeline with an enormous construct dependency.
The structure picks the boring reply on objective. It depends on a tiny per-block O(Okay2) bubble type over a disjoint row vary, pushed by a single thread per block, and capped off with a serial multi-way merge. On paper, this sounds horrible. In observe, it really works fantastically, for the precise cause said truthfully within the kernel’s feedback:
// Single-threaded per-block scan that materializes an area Prime-Okay record for its row partition.
// This isn't the quickest world choice, however it's straightforward to cause about and matches the CPU ordering rule precisely.
__device__ void bubble_downward(float* const s, int* const ids, const int n) {
// Tiny O(Okay^2) type acceptable as a result of Okay is capped (kMaxSupportedK) and this runs on a single lane per block.
for (int i = 0; i < n - 1; ++i) {
for (int j = 0; j < n - 1 - i; ++j) {
if (device_is_better(s[j + 1], ids[j + 1], s[j], ids[j])) {
const float ts = s[j];
s[j] = s[j + 1];
s[j + 1] = ts;
const int ti = ids[j];
ids[j] = ids[j + 1];
ids[j + 1] = ti;
}
}
}
}That is the design contract: V1 picks auditability over cleverness. The entire kernel is sufficiently small {that a} reviewer can learn it end-to-end in a espresso break, line it up in opposition to the CPU oracle, and persuade themselves the GPU output is bitwise right. The day somebody desires a 2× kernel, this will get changed with a warp-specialized event selector — the article’s part 9 guarantees that explicitly. For Okay ≤ 32, the single-lane bubble type is genuinely wonderful. For Okay=100, it falls off a cliff. That cliff is documented and benchmarked. (Part 9 once more.)
Downside B: GPU and CPU should agree, bit-for-bit, on the tiebreak
Properly, like all World Cup Soccer group league match, ties occur greater than usually. Two corpus rows have the identical rating all the way down to fp32 precision. Which one wins?
If the CPU oracle and the GPU kernel disagree on the tiebreak, you may by no means belief a benchmark, as a result of each “mismatch” alarm is now ambiguous: did the GPU rating a row mistaken, or did the GPU simply break ties in a different way? You’ll spend per week in a 3 AM Slack channel.
The repair is to outline the comparator in a single sentence and implement it in two locations — as soon as on the host, as soon as on the machine — and make these two implementations actually the identical expression.
On the host aspect it seems like:
// Lexicographic "higher" relation for (rating, index) pairs below float equality semantics.
// We use strict weak ordering for std::partial_sort: larger rating wins; on actual tie, smaller index wins.
bool is_better_score_pair(const float32_t score_lhs, const index_t idx_lhs, const float32_t score_rhs,
const index_t idx_rhs) {
// Main key: similarity rating (larger is healthier for retrieval).
if (score_lhs != score_rhs) {
return score_lhs > score_rhs;
}
// Deterministic tie floor: choose the smaller corpus row id to reflect steady DB major keys.
return idx_lhs < idx_rhs;
}On the machine aspect it seems like:
// System-side reproduction of the host comparator to keep away from cross-TU linkage points for __device__ code paths.
__device__ bool device_is_better(const float score_lhs, const int idx_lhs, const float score_rhs, const int idx_rhs) {
// Similar ordering semantics as topk::is_better_score_pair for bitwise-identical tie surfaces.
if (score_lhs != score_rhs) {
return score_lhs > score_rhs;
}
return idx_lhs < idx_rhs;
}That’s the complete tiebreak coverage in 5 strains, twice. Greater rating wins; on actual tie, smaller corpus row index wins. The CPU oracle makes use of it in std::partial_sort, the GPU makes use of it within the bubble type and within the multi-way merge, and the benchmark harness is not going to begin timing till the GPU output matches the CPU output precisely — similar indices in the identical order, scores inside a small fp32 tolerance.
That single comparator is the explanation the article can quote a speedup in any respect. With out it, “the GPU is 8× quicker” is simply “the GPU is 8× quicker at being mistaken in a different way.”
Downside C: VRAM is treasured, and the worst place to do malloc is the recent path
Allocating GPU reminiscence per-query is like signing a brand new automobile lease each time it is advisable to drive to the grocery retailer. It’s the best method to flip a 1-millisecond search right into a 50-millisecond visitors jam.
As a substitute, GpuTopkEngine::initialize buys the automobile upfront. It runs all of the cudaMalloc calls throughout engine startup, sizing the buffers for the worst doable configuration. As soon as the engine is actively serving queries, the recent path is totally freed from reminiscence administration. It’s simply quick kernel launches and tiny information copies. No fragmentation, no negotiating with the allocator, and cudaMalloc is completely banned from exhibiting up in your efficiency traces.
4. The four-stage pipeline (the actually-cool half)
Step 0: Engine init — eight cudaMallocs sized for (max_n, max_d, max_k) (GpuTopkEngine::initialize)
Step 1: Add corpus as soon as into VRAM (upload_corpus_rowmajor)
Step 2: Per question — H→D the embedding (search_resident, first line)
Step 3: Rating N rows on machine (row_dot_scores_kernel)
Step 4: Per-block partial Prime-Okay (partial_topk_block_kernel)
Step 5: Multi-way merge into world Prime-Okay (merge_partial_topk_kernel)
Step 6: D→H the Okay indices + Okay scores (search_resident, final strains)Let’s stroll by way of each with the actual code. The snippets are even shorter than the tiny supply recordsdata.
Step 1 — Add the corpus as soon as
That is the boring step that makes the remainder of the article doable. The corpus goes up precisely one time per ingest, and stays there for the lifetime of the engine:
cudaError_t GpuTopkEngine::upload_corpus_rowmajor(const float32_t* const host_corpus_rowmajor, const index_t N,
const index_t D) {
if (N > max_n_ || D > max_d_) {
return cudaErrorInvalidValue;
}
const std::size_t corpus_bytes = sizeof(float) * static_cast<:size_t>(N) * static_cast<:size_t>(D);
const cudaError_t st = cudaMemcpy(d_corpus_, host_corpus_rowmajor, corpus_bytes, cudaMemcpyHostToDevice);
if (st != cudaSuccess) {
return st;
}
resident_n_ = N;
resident_d_ = D;
return cudaSuccess;
}And that’s the complete ingest API. At 1024 dimensions, a million vectors is precisely 4 GB of float32 information, sliding completely into the 8 GB VRAM of a classic GTX 1080. What occurs when your corpus hits 10 million vectors? That turns into a distributed techniques drawback, not a kernel drawback. In case your information exceeds VRAM, you want a sharding technique, which we cowl in Part 9. However for now, we’re right here to unravel the compute bottleneck, to not invent a brand new database.
Step 2 — Rating N rows on the machine
One CUDA thread per corpus row. 256 threads per block. Every thread accumulates the dot product throughout D dimensions and writes one float into the dense scores[N] buffer:
// Row-major dot-product with optionally available cosine normalization; coalesced reads alongside D are sacrificed for readability in v1.
// Microarchitectural word: one thread per row is straightforward; a follow-up can tile D throughout warps to lift arithmetic depth.
__global__ void row_dot_scores_kernel(const float* const corpus, const float* const question, const float* const row_l2,
const float query_l2, const int N, const int D, const int cosine_enabled,
float* const scores) {
// Map every CUDA thread to precisely one corpus row to maintain the discount logic straightforward to audit in opposition to the CPU reference.
const int row = static_cast(blockIdx.x) * static_cast(blockDim.x) + static_cast(threadIdx.x);
if (row >= N) {
return;
}
float acc = 0.0F;
const int base = row * D;
for (int col = 0; col < D; ++col) {
acc += corpus[static_cast<:size_t>(base + col)] * question[static_cast<:size_t>(col)];
}
if (cosine_enabled != 0) {
const float denom = query_l2 * row_l2_fetch(row_l2, row);
scores[static_cast<:size_t>(row)] =
denom > 0.0F ? (acc / denom) : -std::numeric_limits::infinity();
} else {
scores[static_cast<:size_t>(row)] = acc;
}
} One thread per row is the only doable mapping. The code remark is sincere about it: a follow-up can tile D throughout warps to lift the arithmetic depth. For V1, this offers the auditor a one-to-one correspondence with the CPU loop and lets them sleep peacefully at night time.
Step 3 — Every block builds its personal native Prime-Okay
Now comes probably the most awkward half. Selecting the highest Okay out of N is conceptually “type and slice,” however a full type wastes many of the work. We break up the row vary throughout P blocks (capped at 128), every block walks its disjoint slice with the tiny bubble type from Part 3, and writes its personal native top-Okay record out:
const int P = std::min(kMaxPartialBlocks, std::max(1, (static_cast(N) + 4095) / 4096));
partial_topk_block_kernel<<>>(d_scores_, static_cast(N), static_cast(Okay), P, d_partial_scores_,
d_partial_indices_);
One thread per block. Sure, that’s wasteful on paper. It is usually why a human can audit this kernel in twenty minutes — the coverage if (threadIdx.x != 0 || blockIdx.x >= P) return; collapses the entire intra-block reasoning all the way down to “this block’s lane 0 owns rows [start, end).” Every block’s s[] and ids[] arrays stay in registers / native reminiscence, sized by the compile-time kMaxSupportedK = 256 cap.
Step 4 — Merge the partials into the worldwide Prime-Okay
Lastly, one thread on one block walks P cursors over the per-block lists. Every record is already best-first. Choose the perfect head; emit; advance that one cursor; repeat Okay occasions:
for (int out = 0; out < Okay; ++out) {
int best_p = -1;
float best_s = -std::numeric_limits::infinity();
int best_i = std::numeric_limits::max();
for (int p = 0; p < P; ++p) {
if (heads[p] >= Okay) {
proceed;
}
const float s = partial_scores[static_cast<:size_t>(p * K + heads[p])];
const int idx = partial_indices[static_cast<:size_t>(p * K + heads[p])];
if (best_p < 0 || device_is_better(s, idx, best_s, best_i)) {
best_p = p;
best_s = s;
best_i = idx;
}
}
out_scores[static_cast<:size_t>(out)] = best_s;
out_indices[static_cast<:size_t>(out)] = best_i;
heads[best_p] += 1;
} The merge is ruthlessly environment friendly: at most P * Okay reads and precisely Okay writes, executed by a single thread. To stop floating-point chaos, the device_is_better comparator enforces strict determinism—if two heads tie on rating, the decrease corpus row index wins, mirroring the CPU oracle completely. Lastly, two microscopic cudaMemcpy calls shuttle the Okay profitable indices and scores again to the host. The agent ingests them, and the RAG loop fires once more.
That’s the complete scorching path: one H -> D embedding switch, three kernel launches, and two tiny D -> H consequence copies. No Python host loops, no framework overhead, and completely no PCIe holidays.
5. The receipts (i.e., the numbers)
Let’s now consider it in opposition to the baseline, and see if it was well worth the bother.
A fast word on methodology, earlier than the benchmarking police arrives: each comparability beneath runs on the similar GPU as Half 1 and Half 2 (NVIDIA GeForce GTX 1080, Pascal sm_61, 8 GB), driver 535.309.01, CUDA 12.2, host CPU Intel Core i7-8700K, compiler flags -O3 -march=native --expt-relaxed-constexpr. Three trials, one warmup, seed 1, fastened RNG (std::mt19937 with std::normal_distribution), Gaussian embeddings, L2-normalized in dot-product mode. The total sweep is N ∈ {10k, 50k, 100k, 500k, 1M} × D ∈ {384, 768, 1024} × Okay ∈ {8, 32, 100} → 45 configurations, all measured by way of cudaEventElapsedTime with cudaDeviceSynchronize bracketing each interval. Code in src/host/bench_main.cpp; uncooked numbers in examples/example-run-results/benchmark_run_results.csv.
The 2 paths timed:
- GPU-resident (remedy). Corpus is already on the machine. Every timed iteration: cudaMemcpy question H→D (D floats) + rating kernel + per-block partial Prime-Okay + merge + cudaMemcpy Okay scores D→H + cudaMemcpy Okay indices D→H. Finish to finish.
- CPU round-trip (baseline). Fashions the default agent move: cudaMemcpy question D→H + CPU brute-force scoring +
std::partial_sortwith the identical comparator + cudaMemcpy indices H→D + cudaMemcpy scores H→D. Finish to finish.
Each paths run inside the identical course of, use the identical question bytes and the identical comparator. The one distinction is the place the work occurs. When you’ve got ever held the place “PCIe is ok, we benchmark the kernels in isolation,” that is what it prices you if you cease pretending the round-trip is free.
Headline (GTX 1080, three trials, imply ms, ratios computed from per-trial means):
| Config (N × D, Okay) | Baseline imply (ms) | GPU imply (ms) | Velocity-up |
|---|---|---|---|
| 10,000 × 1024, Okay=8 | 9.56 | 1.35 | 7.10× |
| 100,000 × 768, Okay=8 | 70.66 | 25.70 | 2.75× |
| 500,000 × 1024, Okay=8 | 483.90 | 69.79 | 6.93× |
| 1,000,000 × 1024, Okay=8 | 977.80 | 114.12 | 8.57× |
| 1,000,000 × 1024, Okay=32 | 973.89 | 125.46 | 7.76× |
| 10,000 × 384, Okay=100 | 3.37 | 155.25 | GPU is 46× slower |
| 1,000,000 × 384, Okay=100 | 329.49 | 682.38 | GPU is 2.07× slower |

Sure, you might be studying the numbers proper.
The primary 5 rows are the article’s level: at Okay=8, the GPU-resident path wins on each single configuration within the sweep (all 15 of them), by ratios starting from a well mannered 2.43× at N=50k, D=384 to a loud 8.57× at N=1M, D=1024. At Okay=32 it wins on 13 of 15 — the 2 losses are each on the smallest N (10k), for D=384 and D=768, the place the round-trip itself solely prices ~3–7 ms and the GPU’s three kernel launches barely have room to amortize. By the point you attain reasonable agentic-corpus sizes (N ≥ 50k), Okay=32 additionally wins comfortably, peaking at 7.76×. The large speedups are usually not “magic kernel” speedups — they’re “we stopped transport the corpus again to host RAM for no cause” speedups. The GPU was all the time going to win this race; the one cause it ever misplaced was that we stored making it commute unnecessarily.
The final two rows are the place this text earns its proper to name itself sincere. At Okay=100, the single-lane bubble type per block turns into O(K²) = O(10,000) sequential comparisons per block, and the serial merge walks P × Okay head positions. The CPU’s std::partial_sort is heap-based, vectorized by the compiler, and successfully O(N log Okay) — a lot friendlier to Okay=100. So the GPU loses on 14 of 15 Okay=100 configs, generally by 2×, generally by 46×. (There’s precisely one Okay=100 config the place the GPU nonetheless wins — N=1M, D=1024, 1.44× — as a result of by then there’s sufficient scoring work to dominate the choice ceiling. One row out of fifteen shouldn’t be a save; it’s a curiosity.) That’s not a bug; it’s the V1 design assertion (“auditability over cleverness”) assembly its first concrete consequence. The repair is in Part 9, and it’s a warp-specialized event selector — not a frantic refactor.
Another sincere caveat within the numbers above: on this dedicated snapshot, the GPU clocks had been not locked. Which means absolute milliseconds transfer barely with thermals and DVFS; the ratios keep steady. The repo ships scripts/lock_gpu_clocks.sh for anybody who desires to breed the desk with locked clocks on a GTX 1080. Unnecessary to say, the structural discovering doesn’t change.
6. “OK, however how is that this completely different from FAISS / cuVS / hnswlib?”
A really cheap query, and value answering straight, as a result of the vector-search world has plenty of overlapping primitives and an HPC reader will ask this within the first remark.
- FAISS (CPU index). The default in most agent frameworks. Wonderful library. Lives on the CPU. Each question an agent makes pays the PCIe round-trip this text exists to delete. In the event you’re already on
IndexFlatIPand also you’re CPU-bound on retrieval, you’re the audience. - FAISS (GPU index). Solves the GPU residency drawback, with a way more mature kernel suite than this repo. The purpose of CUDA-TopK-Retrieval shouldn’t be “I out-engineered FAISS-GPU” — it by no means was and neither does it attempt to be. The purpose is to point out, in 343 strains, what the actually-cool retrieval primitive seems like and why agentic pipelines really feel gradual when it isn’t there. In the event you want a manufacturing index right this moment, use FAISS-GPU. If you wish to perceive the small scorching path that makes the distinction — one tiny H→D copy, three kernel launches, two small D→H copies — learn this kernel.
- NVIDIA cuVS / RAFT. The intense, production-grade in-GPU vector-search stack. Larger, quicker, extra algorithms, extra dependencies. Similar caveat as FAISS-GPU: this kernel is the pedagogical / single-binary model, not a competitor.
- hnswlib and pals (approximate nearest neighbor). Completely different form of trade-off totally — they commerce exactness for sublinear question time on enormous corpora. CUDA-TopK-Retrieval is actual brute-force scoring + choice; the speedup story is only about residency, not about skipping work.
The purpose of this repo shouldn’t be “construct your manufacturing vector DB on it.” The purpose is: the agent’s retrieval hop desires to remain on the GPU, and when you settle for that, even a tiny hand-written kernel beats a hosted-on-CPU brute pressure throughout most reasonable Okay values on a 7-year-old card.
7. So… how do I really strive it?
Clone the repo, then construct with CMake (the -DGGML_CUDA=ON flag mirrors the llama.cpp construct ergonomics from earlier elements of the sequence):
cmake -S . -B construct -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Launch
cmake --build construct -j
cd construct && ctest --output-on-failureThen run the demo and the benchmark precisely because the README does:
./construct/topk_demo # tiny smoke story (GPU required)
./construct/topk_bench --n 20000 --d 384 --k 32 --trials 3 --warmup 1 --seed 1 --metric 0topk_demo is the tiny smoke story — 4,096 corpus rows, 128 dims, Okay=8, prints the neighbor IDs. topk_bench is the harness that emits the TOPK_BENCH_JSON line the Python marketing campaign script consumes. For the total 45-config sweep on canonical {hardware}:
python3 scripts/benchmark_campaign.py.instance # full sweep (GPU required; writes below examples/benchmark-campaign-runs/run-*)Earlier than publishing-grade runs, lock the GPU clocks (the repo gives the script):
sudo bash scripts/lock_gpu_clocks.shNecessities: Linux, CUDA toolkit, an NVIDIA GPU (Pascal or newer), and the persistence to learn a CMake file as soon as. Artifacts land below examples/example-run-results/ for the fast path or examples/benchmark-campaign-runs/run- for the total sweep, and the README is specific that committing .nsys-rep databases is forbidden — PNG timelines solely.
8. Plot twist — that is simply 5G beam choice in a CUDA costume
I ought to most likely confess at this level: I’m nonetheless not a “GPU particular person” by coaching. I got here up by way of telecom — 5G NR with a foot creeping firmly into 6G analysis — and I maintain noticing that each infrastructure drawback in agentic AI is an issue which was already solved on the radio layer, possibly round twenty years in the past.
For readers with out a 3GPP background: in a contemporary 5G base station, the antenna doesn’t radiate equally in each route. It varieties a codebook of directional beams — slim lobes of radio vitality — and at any given second your telephone is being served by the one beam (or the small handful of beams) whose obtained energy is highest in your machine. Choosing the proper beam, quick, is likely one of the most-studied retrieval issues in wi-fi. The UE measures L1-RSRP (a per-beam received-power rating) throughout the candidate beams the gNB (5G base station) has informed it to measure, then studies again the perfect handful by way of the CSI suggestions channel. The gNB makes use of these studies to determine which beams to schedule (Properly, this was so simple as I may make it, the actual story is basically ugly!).
That’s Prime-Okay vector search, in radio costume. The candidate beams are the corpus. The instantaneous channel measurement is the question. The rating is obtained energy. Okay is the variety of finest beams the report carries again. The UE does the scoring down on the baseband DSP layer — it doesn’t ship the I/Q samples again to a central CPU farm and ask a Python script which beam is finest, as a result of doing so on a per-millisecond loop would soften the air interface.
Take a look at this side-by-side and inform me with a straight face these are completely different issues:
| 5G NR beam choice (on the UE / baseband) | CUDA-TopK-Retrieval (on the GPU) |
|---|---|
| Codebook of candidate beams (fastened at config) | Corpus of pre-embedded chunks (uploaded as soon as) |
| Instantaneous channel measurement | Question embedding for this hop |
| L1-RSRP per candidate beam | Cosine / dot-product rating per corpus row |
| Prime finest beams reported again to gNB | Prime-Okay row indices returned to the agent |
| Per-beam rating lives in baseband DSP, not in a number CPU | Per-row rating lives in VRAM, not in host RAM |
| Doing this on a CPU round-trip would soften the air interface | Doing this on a CPU round-trip melts the agent’s throughput |
A fast apart to 2 very completely different audiences
To my HPC and CUDA-first pals studying this: I hear you. Not one of the mathematical primitives listed below are novel. Everyone knows cuBLAS runs matmuls quicker, cuVS handles Prime-Okay at datacenter scale, and a extremely tuned event choice will crush this per-block bubble type. However the objective right here isn’t to reinvent NVIDIA’s enterprise libraries. The worth is the zero-dependency packaging. It is a 343-line architectural proof—full with a strict CPU oracle and a 45-config benchmark sweep—designed to run totally on a classic 8 GB shopper GPU. It’s the type of end-to-end engineering artifact you construct to show you really perceive {hardware} reminiscence bottlenecks, slightly than simply understanding methods to name a framework API.
To my telecom pals: if “Prime-Okay vector search” seemed like a overseas language till ten minutes in the past, you aren’t behind — you might be early. For twenty years our world was FPGAs, ASICs, PRBs, and constellation diagrams. We optimized spectrum, not silicon. Then AI-RAN, NWDAF, NVIDIA Aerial, and the 3GPP Rel-20 research gadgets all occurred too quick inside a number of months, and the subsequent decade of telecom careers now calls for being bilingual between spectrum-world and GPU-world. The instinct interprets cleanly. You might have been doing receiver-side Prime-Okay below arduous real-time constraints because the first MIMO codebook. Similar animal, simply in a brand new zoo.
9. Sincere caveats (as a result of the feedback are coming)
In the event you got here right here to seek out what’s mistaken with this challenge — congratulations, you might be this text’s first cautious reader. Straight from the README’s LIMITATIONS part and the inline code feedback:
- Okay=100 is the place V1 loses. The partial Prime-Okay path makes use of single-lane-per-block choice for auditability; it isn’t but a warp-specialized tournament-selection kernel. At Okay=100 the O(K²) bubble type dominates, and on the CSV the CPU pulls forward on 14 of 15 Okay=100 rows (generally by 2×, generally by 46×). The lone GPU win at Okay=100 — N=1M, D=1024, 1.44× — is the scoring work lastly being sufficiently big to swamp the choice ceiling, not the selector getting any higher. That is documented; the repair is a identified follow-up.
- GPU clocks are usually not locked within the dedicated receipt. The dedicated
surroundings.jsonstudiesgpu_clocks_locked: false. Absolute milliseconds shift with thermals on a shopper card; the ratios within the headline desk are sturdy. The repo shipsscripts/lock_gpu_clocks.sh(persistence mode + lock to 1607 MHz utility clocks for a inventory GTX 1080) for anybody who wants publication-grade numbers. - Numeric tolerance, not actual float equality. GPU vs CPU rating comparisons use a small fp32 tolerance per rating; ties are nonetheless resolved deterministically by index. It is a real-world necessity — fp32 reductions affiliate in a different way on a GPU than on a CPU — and the harness is not going to begin timing till indices match precisely.
- Artificial embeddings. The benchmark makes use of Gaussian-random vectors (
std::normal_distribution, seed 1) to isolate the residency-vs-round-trip sign from content material results and maintain trials reproducible bit-for-bit. Actual embeddings will produce noisier per-trial absolute timings; the structural ratio between PCIe-vacation and on-device math doesn’t transfer. - One CUDA structure class. All numbers come from one Pascal-class GTX 1080. On Ada / Hopper absolutely the milliseconds will shrink for each paths; the structural discovering (PCIe round-trip price dominates a CPU-side retrieval) turns into extra necessary on quicker GPUs, not much less, as a result of the kernel time shrinks quicker than the round-trip does.
- RAG slice, not a full vector DB. It is a similarity + Prime-Okay slice. No compression (PQ, OPQ), no filtering, no multi-GPU sharding, no concurrency between queries inside one engine occasion. It’s the retrieval-hop primitive an agent calls — not a alternative for FAISS-GPU or cuVS.
All the pieces on this record is on the roadmap. None of it modifications the headline consequence. The purpose of placing it in writing is that you shouldn’t should dig for it — and the second a benchmark weblog publish hides its caveats is the second its numbers cease being reliable.
10. Wrap (and the setup for the ultimate half)
In the event you construct agentic pipelines for a dwelling: please go and take a look at your retriever. Open no matter profiler you belief. Time one instrument name end-to-end. In case your GPU utilization drops to zero whereas a Python host course of grinds by way of a similarity search, you’ve got already gained the diagnostic battle. The repair is on GitHub.
In the event you write CUDA for a dwelling: Sure, the O(Okay2) bubble type is intentional. A warp-specialized event selector is on the roadmap.
In the event you construct telecom infrastructure for a dwelling: Sure, you caught me. That is the very same baseband retrieval primitive you’ve got been writing in DSP code for twenty years. The AI trade simply modified the vocabulary; the maths hasn’t budged.
Arising subsequent: The best way to Cease Your Brokers from Trauma-Dumping on Every Different

CUDA-TopK-Retrieval proves you may cease bouncing each retrieval hop off the GPU. However should you reread caveat #1 plus the Okay=100 rows in Part 5, you’ve got already noticed the subsequent ceiling: the per-query work is unbiased throughout queries.
Each retrieval hop begins chilly. The corpus is on the machine, positive. However the agent’s state — the embeddings of its earlier selections, the keys and values that it might naturally attend again over — will get dropped and rebuilt on each hand-off. The GPU stays heat; the agent’s reminiscence stays chilly.
That’s wonderful for a one-shot RAG step. It falls aside the second you run the workload this sequence was constructed for: multi-hop reasoning throughout a swarm of specialised brokers. At that scale you cease caring about “did we maintain the retrieval on the GPU” and begin caring about questions a single-shot kernel can’t reply:
- When agent A palms off to agent B, can B resume with A’s collected context as a substitute of cold-starting?
- How small can the per-hop persistent state be, and nonetheless be helpful?
- What’s the latency price of restoring that state on the subsequent agent’s GPU?
- How will we make hand-offs not lose data?
To get the reply of those questions, you’ll have to do precisely what your CPU does throughout a cudaMemcpy: sit there patiently and anticipate the subsequent half.
See you in Half 4, the ultimate one.
Disclaimer: The illustrations on this article had been generated utilizing AI (Claude Opus 4.8). They’re illustrative, not photographic, and any labels seen inside the photographs are stylized slightly than authoritative — check with the article physique and the code itself for exact perform names, metric values, and structure particulars.















{kind=link}