


On this article, you’ll find out how logits, temperature, and top-p sampling work collectively to manage next-token prediction in massive language fashions.
Subjects we are going to cowl embrace:
- What logits are and the way they’re produced by a transformer’s closing linear layer.
- How temperature and top-p (nucleus sampling) form the likelihood distribution used for token choice.
- How these three elements match right into a sequential pipeline that governs LLM output technology.
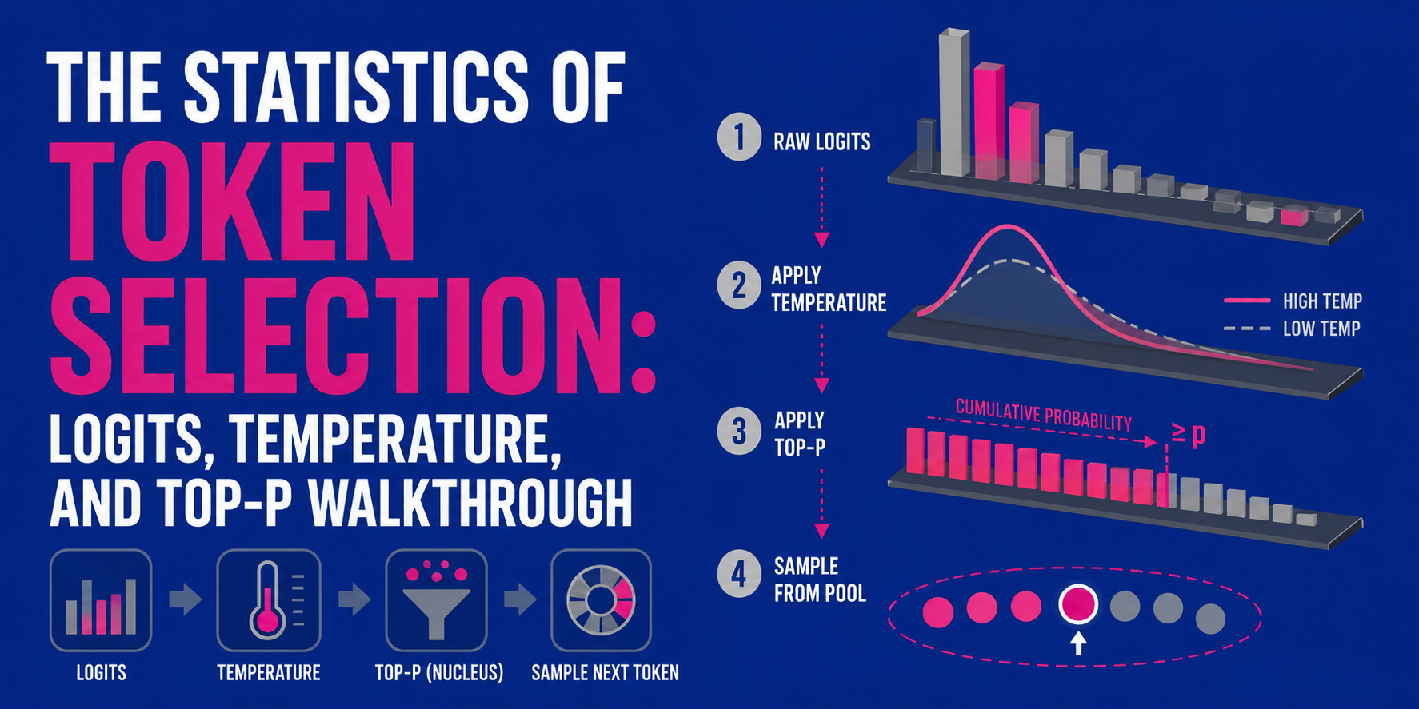
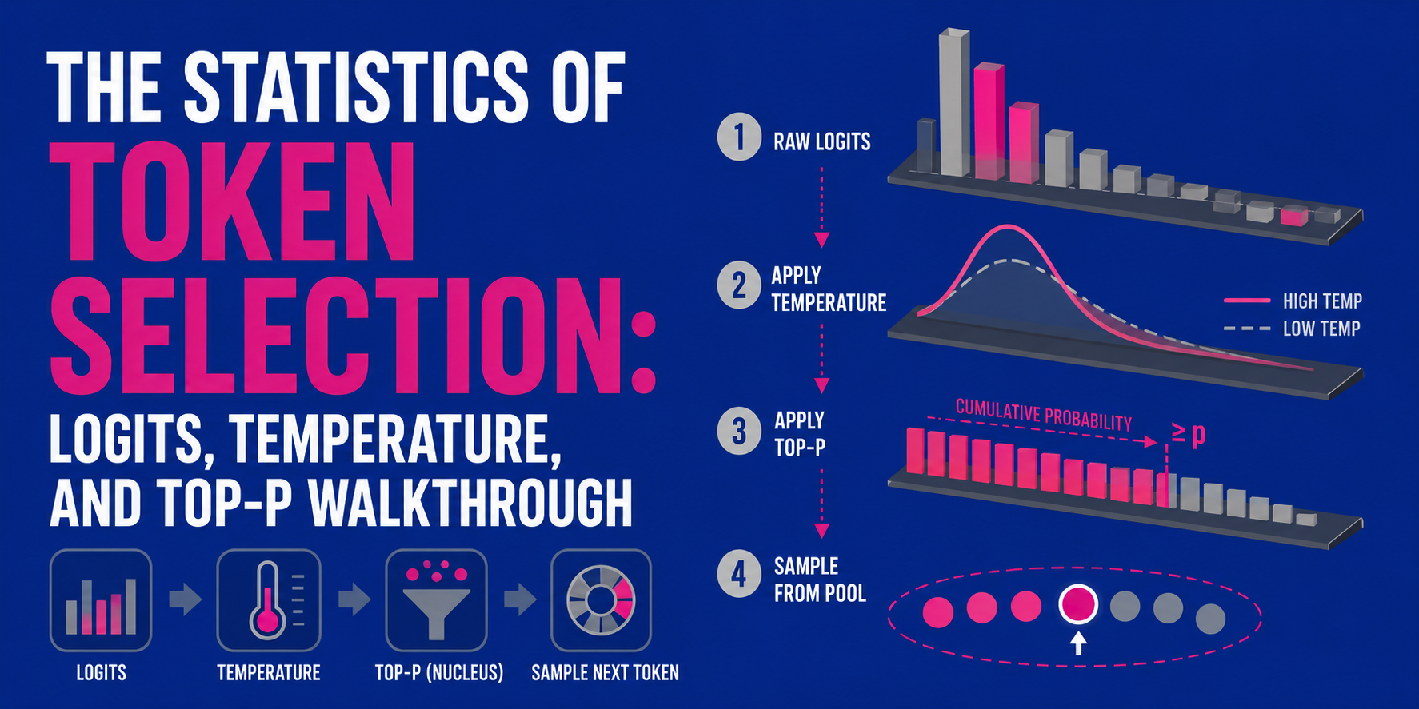
The Statistics of Token Choice: Logits, Temperature, and Prime-P Walkthrough
Introduction
When massive language fashions, or LLMs for brief, produce outputs, a number of standards are at stake, together with not solely general response relevance but in addition coherence and creativity. Since deep contained in the fashions function by constructing their response phrase by phrase — or extra exactly, token by token — capturing these fascinating properties is a matter of mathematically adjusting the output likelihood distributions that govern the next-token prediction course of.
This text introduces the mechanics behind LLM decoding methods from a statistical vantage level. Particularly, we are going to discover how uncooked mannequin scores, often called logits, work together with two different mannequin settings — temperature and top-p — that are three key parameters utilized to manage the token choice course of.
Whereas we are going to deal with exploring what occurs contained in the very closing phases of the LLMs’ underlying structure, a.ok.a. the transformer, you may test this text for those who want a concise overview of the entire course of and journey made by tokens from starting to finish.
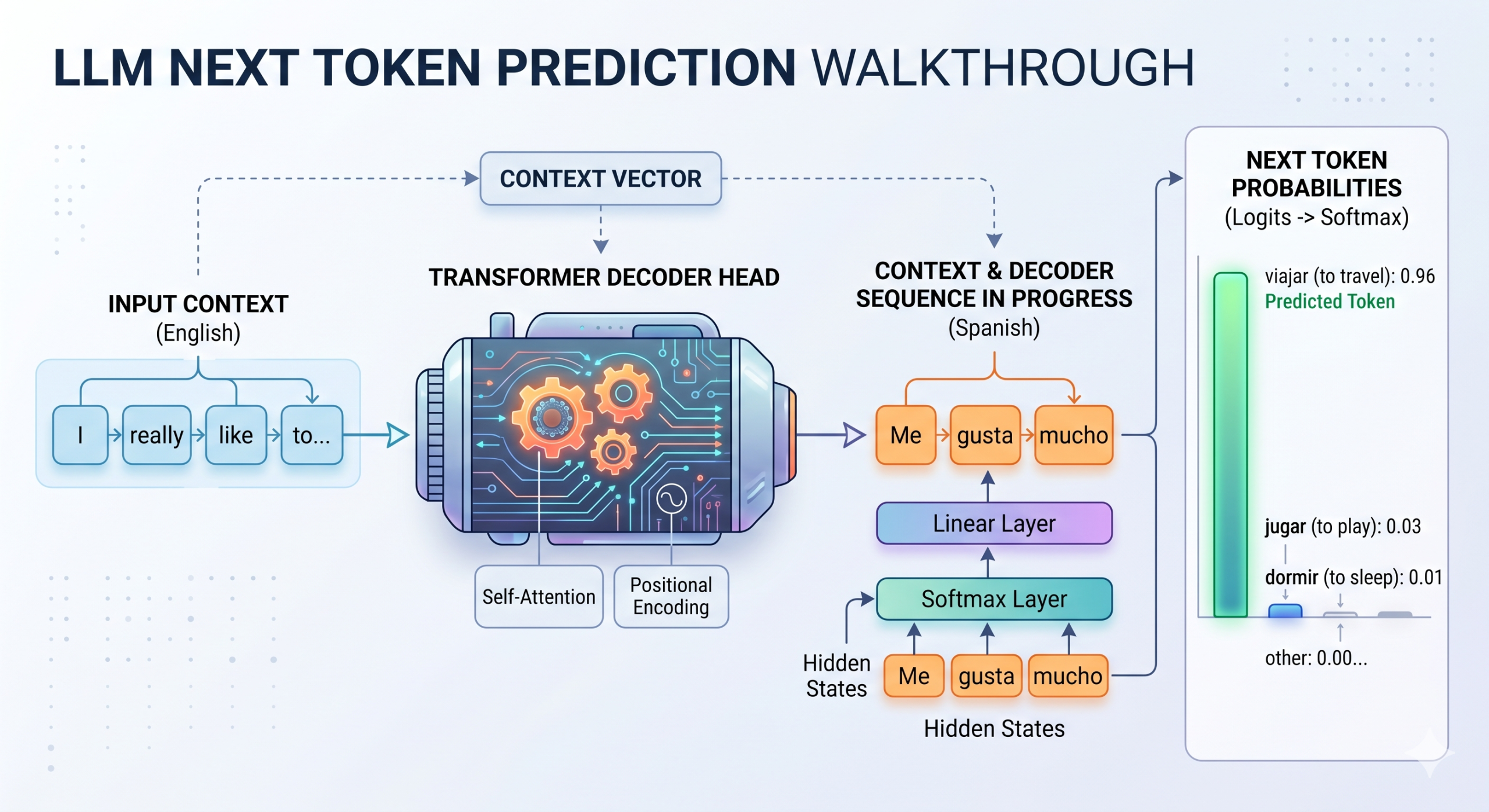
Token choice course of in LLMs
What Are Logits?
In neural networks, the uncooked, unnormalized scores produced (sometimes at closing linear layers) earlier than changing them into chances of potential outcomes (e.g. lessons) are often called logits. Whereas logits have been used for the reason that period of classical machine studying classification fashions like softmax regression, the identical precept nonetheless applies to the ultimate linear layer of transformer fashions. This closing layer processes hidden states — which include regularly gathered linguistic information in regards to the enter textual content gathered all through the transformer — and outputs a vector of logits. What number of? As many because the mannequin’s vocabulary dimension, i.e. the variety of potential tokens the mannequin can generate.
See the diagram on the high, as an illustration. If an LLM skilled for English-to-Spanish translation is predicting the subsequent phrase after the generated sequence “me gusta mucho” (the interpretation of “I actually wish to”), it would output a uncooked logit rating of 12.5 for “viajar” (journey), 8.2 for “jugar” (play), and -3.1 for “dormir” (sleep). These uncooked values are unbounded, making them troublesome to interpret immediately; therefore, a softmax operate is utilized on high of the ultimate linear layer to remodel these logits into a normal, interpretable likelihood distribution over vocabulary tokens, such that each one values sum to 1.
What Are Temperature and Prime-p?
As soon as now we have a likelihood distribution over the goal vocabulary, do LLMs merely select the token with the very best likelihood as the subsequent one to generate? Not precisely, however the true course of intently resembles that state of affairs. The following token is sampled from the distribution, and the way this sampling works relies on a number of decoding parameters, two of a very powerful being temperature and top-p.
- Temperature is a scaling issue utilized to the logits earlier than the softmax step. A excessive temperature (e.g. above 1) flattens the ensuing chances, making them extra uniform. Consequently, uncertainty and unpredictability improve, and the mannequin behaves extra creatively. A low temperature (e.g. nicely beneath 1) sharpens the variations between high- and low-probability tokens, rising certainty and strongly favoring the almost certainly tokens within the unique distribution. Extra about temperature could be discovered on this associated article.
- Prime-p, additionally referred to as nucleus sampling, is one other strategy to controlling the randomness of next-token choice. Somewhat than scaling chances, it limits the pool of candidates to pattern from. Whereas comparable methods like top-k take into account solely the ok highest-probability tokens, top-p identifies the smallest set of tokens whose cumulative likelihood meets or exceeds a threshold p, making it extra adaptive and versatile. In different phrases, if we set p=0.9, top-p kinds tokens by likelihood and retains including them to a candidate pool till their cumulative likelihood reaches 0.9.
The Full Walkthrough: How Do These Ideas Relate to Every Different?
Logit-to-probability calculation, temperature, and top-p could be mixed right into a sequential multi-step pipeline for producing LLM outputs, i.e. next-token predictions.
First, the mannequin generates uncooked logits for all potential tokens, as described above. Temperature then enters the image by scaling these uncooked logits — observe that this occurs earlier than the softmax operate converts them into chances. Relying on the temperature worth, the ensuing distribution will look extra uniform (excessive temperature, extra uncertainty) or sharper (low temperature, greater certainty).
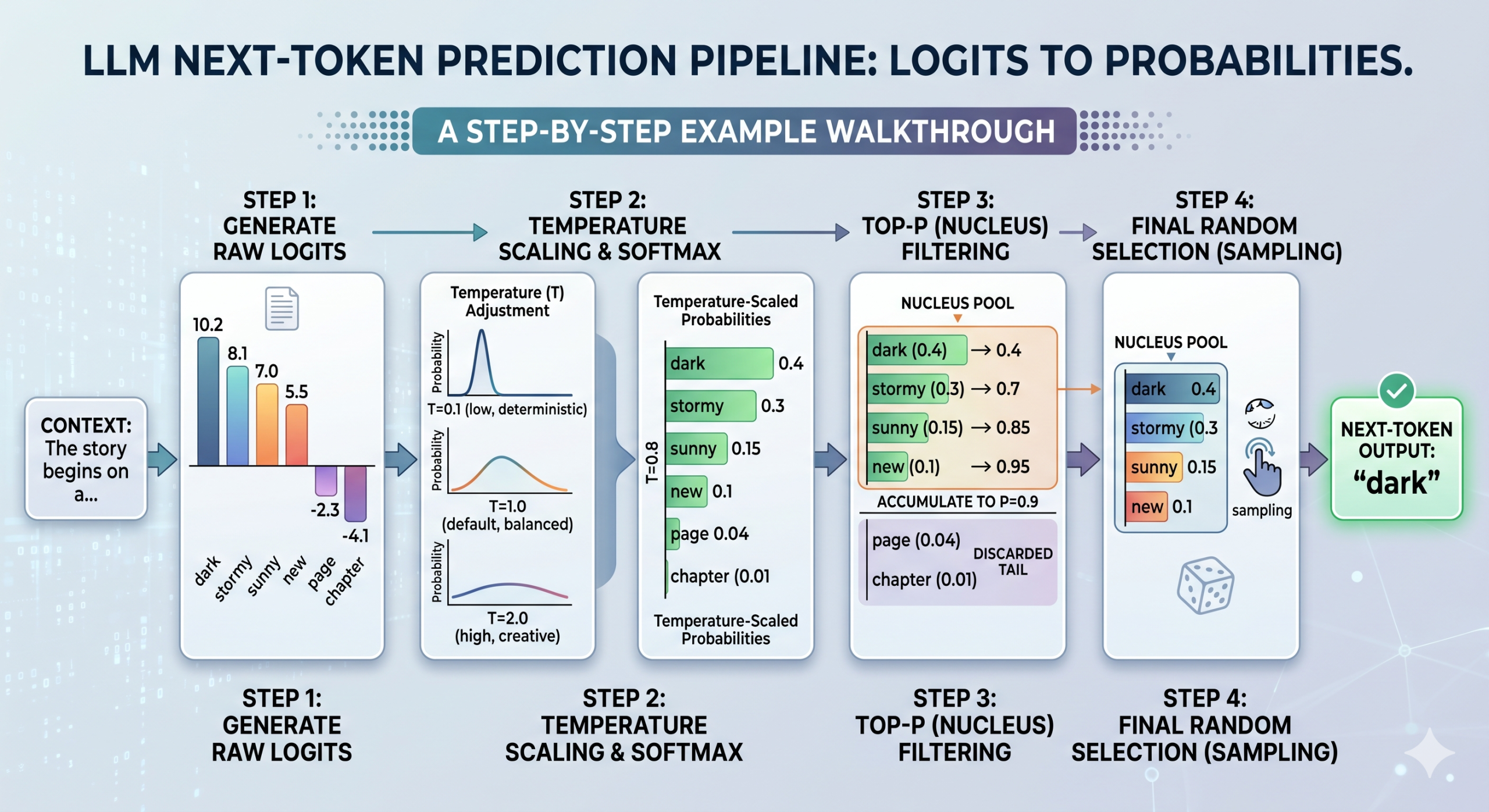
Token choice walkthrough based mostly on logits, temperature, and top-p
As soon as the scaled logits are transformed into chances, top-p is utilized to filter the ensuing distribution, calculating cumulative chances to retain solely a core “nucleus pool” of the almost certainly tokens (see step 3 within the picture above). Lastly, the mannequin samples randomly from inside that pool to pick the subsequent token.
Closing Remarks
Now that now we have demystified the statistical course of behind token choice in LLMs, it’s helpful to contemplate how to decide on values for temperature and top-p in follow. As a developer, it would be best to outline the proper steadiness between predictability and creativity in your use case. For factual, high-stakes eventualities like coding or authorized evaluation, a low temperature and a stricter top-p are advisable — e.g. t=0.1 and p=0.5 — which yields extremely deterministic mannequin responses. For inventive domains like poetry technology or brainstorming, a better temperature and top-p, equivalent to t=0.8 and p=0.95, enable for a richer number of candidate tokens within the choice pool.
On this article, you’ll find out how logits, temperature, and top-p sampling work collectively to manage next-token prediction in massive language fashions.
Subjects we are going to cowl embrace:
- What logits are and the way they’re produced by a transformer’s closing linear layer.
- How temperature and top-p (nucleus sampling) form the likelihood distribution used for token choice.
- How these three elements match right into a sequential pipeline that governs LLM output technology.
The Statistics of Token Choice: Logits, Temperature, and Prime-P Walkthrough
Introduction
When massive language fashions, or LLMs for brief, produce outputs, a number of standards are at stake, together with not solely general response relevance but in addition coherence and creativity. Since deep contained in the fashions function by constructing their response phrase by phrase — or extra exactly, token by token — capturing these fascinating properties is a matter of mathematically adjusting the output likelihood distributions that govern the next-token prediction course of.
This text introduces the mechanics behind LLM decoding methods from a statistical vantage level. Particularly, we are going to discover how uncooked mannequin scores, often called logits, work together with two different mannequin settings — temperature and top-p — that are three key parameters utilized to manage the token choice course of.
Whereas we are going to deal with exploring what occurs contained in the very closing phases of the LLMs’ underlying structure, a.ok.a. the transformer, you may test this text for those who want a concise overview of the entire course of and journey made by tokens from starting to finish.
Token choice course of in LLMs
What Are Logits?
In neural networks, the uncooked, unnormalized scores produced (sometimes at closing linear layers) earlier than changing them into chances of potential outcomes (e.g. lessons) are often called logits. Whereas logits have been used for the reason that period of classical machine studying classification fashions like softmax regression, the identical precept nonetheless applies to the ultimate linear layer of transformer fashions. This closing layer processes hidden states — which include regularly gathered linguistic information in regards to the enter textual content gathered all through the transformer — and outputs a vector of logits. What number of? As many because the mannequin’s vocabulary dimension, i.e. the variety of potential tokens the mannequin can generate.
See the diagram on the high, as an illustration. If an LLM skilled for English-to-Spanish translation is predicting the subsequent phrase after the generated sequence “me gusta mucho” (the interpretation of “I actually wish to”), it would output a uncooked logit rating of 12.5 for “viajar” (journey), 8.2 for “jugar” (play), and -3.1 for “dormir” (sleep). These uncooked values are unbounded, making them troublesome to interpret immediately; therefore, a softmax operate is utilized on high of the ultimate linear layer to remodel these logits into a normal, interpretable likelihood distribution over vocabulary tokens, such that each one values sum to 1.
What Are Temperature and Prime-p?
As soon as now we have a likelihood distribution over the goal vocabulary, do LLMs merely select the token with the very best likelihood as the subsequent one to generate? Not precisely, however the true course of intently resembles that state of affairs. The following token is sampled from the distribution, and the way this sampling works relies on a number of decoding parameters, two of a very powerful being temperature and top-p.
- Temperature is a scaling issue utilized to the logits earlier than the softmax step. A excessive temperature (e.g. above 1) flattens the ensuing chances, making them extra uniform. Consequently, uncertainty and unpredictability improve, and the mannequin behaves extra creatively. A low temperature (e.g. nicely beneath 1) sharpens the variations between high- and low-probability tokens, rising certainty and strongly favoring the almost certainly tokens within the unique distribution. Extra about temperature could be discovered on this associated article.
- Prime-p, additionally referred to as nucleus sampling, is one other strategy to controlling the randomness of next-token choice. Somewhat than scaling chances, it limits the pool of candidates to pattern from. Whereas comparable methods like top-k take into account solely the ok highest-probability tokens, top-p identifies the smallest set of tokens whose cumulative likelihood meets or exceeds a threshold p, making it extra adaptive and versatile. In different phrases, if we set p=0.9, top-p kinds tokens by likelihood and retains including them to a candidate pool till their cumulative likelihood reaches 0.9.
The Full Walkthrough: How Do These Ideas Relate to Every Different?
Logit-to-probability calculation, temperature, and top-p could be mixed right into a sequential multi-step pipeline for producing LLM outputs, i.e. next-token predictions.
First, the mannequin generates uncooked logits for all potential tokens, as described above. Temperature then enters the image by scaling these uncooked logits — observe that this occurs earlier than the softmax operate converts them into chances. Relying on the temperature worth, the ensuing distribution will look extra uniform (excessive temperature, extra uncertainty) or sharper (low temperature, greater certainty).
Token choice walkthrough based mostly on logits, temperature, and top-p
As soon as the scaled logits are transformed into chances, top-p is utilized to filter the ensuing distribution, calculating cumulative chances to retain solely a core “nucleus pool” of the almost certainly tokens (see step 3 within the picture above). Lastly, the mannequin samples randomly from inside that pool to pick the subsequent token.
Closing Remarks
Now that now we have demystified the statistical course of behind token choice in LLMs, it’s helpful to contemplate how to decide on values for temperature and top-p in follow. As a developer, it would be best to outline the proper steadiness between predictability and creativity in your use case. For factual, high-stakes eventualities like coding or authorized evaluation, a low temperature and a stricter top-p are advisable — e.g. t=0.1 and p=0.5 — which yields extremely deterministic mannequin responses. For inventive domains like poetry technology or brainstorming, a better temperature and top-p, equivalent to t=0.8 and p=0.95, enable for a richer number of candidate tokens within the choice pool.














{kind=link}