


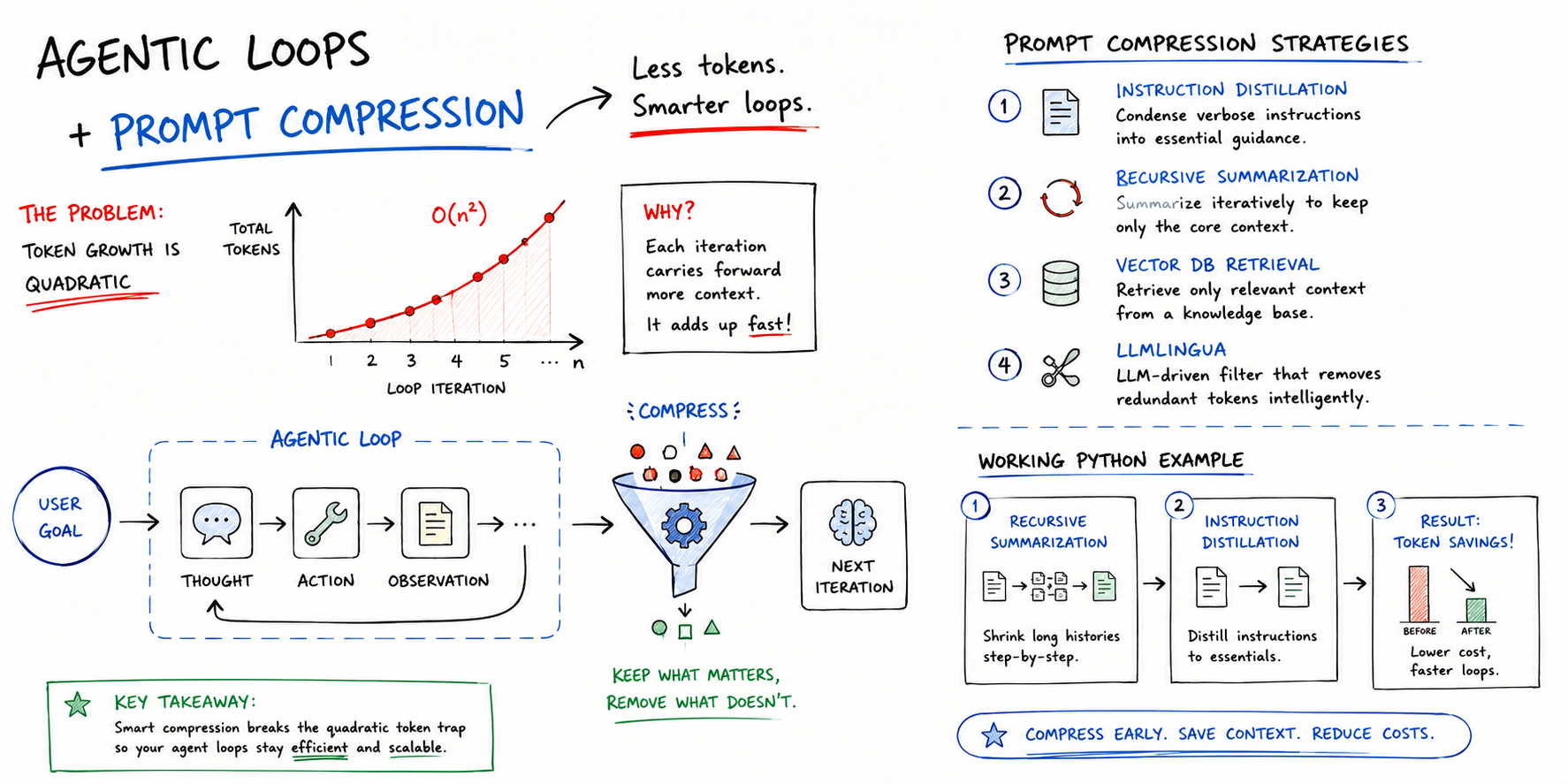
On this article, you’ll be taught what immediate compression is, why it issues for agentic AI loops, and implement it virtually utilizing summarization and instruction distillation.
Subjects we’ll cowl embrace:
- Why agentic loops accumulate token prices quadratically, and the way immediate compression addresses this.
- A overview of the principle immediate compression methods, together with instruction distillation, recursive summarization, vector database retrieval, and LLMLingua.
- A working Python instance that mixes recursive summarization and instruction distillation to attain significant token financial savings.
Introduction
Agentic loops in manufacturing will be synonymous with excessive prices, particularly relating to each LLM and exterior utility utilization through APIs, the place billing is commonly carefully associated to token utilization.
The excellent news: immediate compression is without doubt one of the handiest methods you possibly can implement to navigate the excessive prices of agentic loops. This text introduces and discusses how various immediate compression strategies may help alleviate monetary points when utilizing agentic loops.
Immediate Compression: Motivation and Frequent Methods
Quite a few agentic frameworks, corresponding to LangGraph and AutoGPT, implement that the agent retains a context of what it has executed in earlier steps. Suppose your agent must take 10 to twenty steps to resolve an issue. To conduct step 1, it sends 500 tokens. For step 2, it should ship these prior 500 tokens plus new info inherent to this step — say about 1,000 tokens in complete. This will develop to about 1,500 tokens in step 3, and so forth. By the point we attain the twentieth step, we’ve got been “paying” for sending largely the identical info again and again.
Within the instance above, it could look like the variety of tokens despatched per step (full immediate dimension) grows linearly. Actually, nonetheless, the cumulative prices of your complete agent loop change into quadratic, not linear, main to a price explosion for long-lasting loops. That is the place immediate compression strategies come to assist, with methods like selective context, summarization, and others, as we’ll talk about shortly.
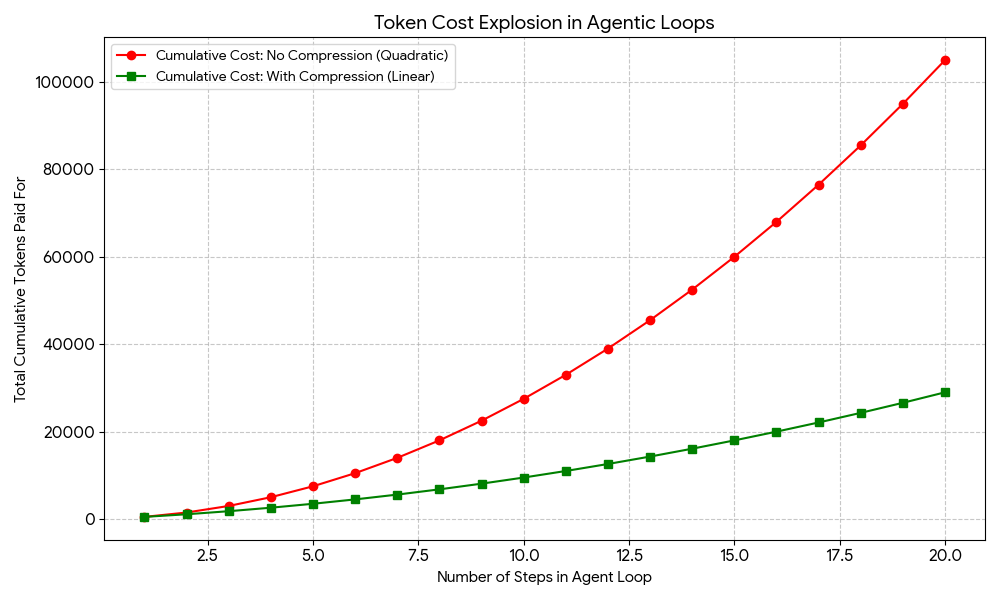
Instance price curve of agentic loops with out vs. with immediate compression
The problem isn’t just monetary: there’s one other hidden price associated to latency, as longer prompts take longer to course of, and never all customers are prepared to attend 30 seconds per interplay. Compressed prompts additionally allow quicker inference and scale back compute overhead.
To place this in perspective, a 500K token context might theoretically be diminished to a 32K token compressed window that retains all related info, whereas components like repetitive JSON buildings, cease phrases, and low-value conversational components are eliminated. Listed here are some cost-effective options and frameworks that may be thought-about for implementing your personal immediate compression technique:
- Instruction distillation: this consists of making a “compressed” model of an extended system immediate that could be despatched repeatedly, containing symbols or shorthand that the mannequin will perceive and interpret.
- Recursive summarization: each few steps in a loop, use the agent or a smaller, cheaper mannequin like Llama 3 or GPT-4o-mini to summarize the earlier steps’ context right into a extra succinct paragraph outlining the present state of the duty.
- Vector database (RAG) for historical past retrieval: this replaces sending the total historical past repeatedly by storing it in a free, native vector database like FAISS or Chroma. For any given immediate, solely essentially the most related actions are retrieved as a part of its context.
- LLMLingua: an open-source framework that’s gaining recognition, targeted on detecting and eliminating “non-critical” tokens in a immediate earlier than it’s despatched to a bigger, dearer language mannequin.
A Sensible Instance: Summarizing Agent
Under is an instance of a cost-friendly immediate compression technique that mixes recursive summarization and instruction distillation utilizing Python. The code is meant to function a template of what such immediate compression logic ought to appear to be when translated into an actual, large-scale state of affairs. It reveals a simplified simulation of an agentic loop, emphasizing the summarization and distillation steps:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import tiktoken
def count_tokens(textual content, mannequin=“gpt-4o”): encoding = tiktoken.encoding_for_model(mannequin) return len(encoding.encode(textual content))
def compress_history(history_list): “”“ A operate that simulates ‘Summarization’. In an actual app, it entails sending the enter to a small language mannequin (like gpt-4o-mini) to condense it. ““”
print(“— Compressing Historical past —“)
# In manufacturing, cross ‘mixed’ to a summarization mannequin mixed = ” “.be part of(history_list)
# Distillation: Shorthand model of the occasions abstract = f“Abstract of {len(history_list)} steps: Duties A & B accomplished. End result: Success.” return abstract
# 1. Distilled System Immediate (makes use of shorthand as an alternative of prose) system_prompt = “Act: ResearchBot. Activity: Discover X. Output: JSON solely. Constraints: No fluff.”
# 2. The Agentic Loop historical past = [] raw_token_total = 0
for step in vary(1, 6): motion = f“Step {step}: Agent carried out a really long-winded seek for information level {step}…” historical past.append(motion)
# Calculating what the immediate WOULD appear to be with out compression current_full_context = system_prompt + ” “.be part of(historical past) raw_tokens = count_tokens(current_full_context)
print(f“Loop {step} | Full Context Tokens: {raw_tokens}”)
# 3. Making use of Compression compressed_context = system_prompt + compress_history(historical past) compressed_tokens = count_tokens(compressed_context)
print(f“nFinal Uncompressed Tokens: {raw_tokens}”) print(f“Closing Compressed Tokens: {compressed_tokens}”) print(f“Financial savings: {((raw_tokens – compressed_tokens) / raw_tokens) * 100:.1f}%”) |
This code reveals periodically change the cumulative checklist of actions with a abstract that spans a single string, serving to keep away from the added prices of paying for a similar context tokens in each loop iteration. Attempt utilizing a small, low cost mannequin or an area one like Llama 3 to carry out the summarization step.
Concerning distillation, this instance illustrates what it really does:
A normal 42-token immediate that reads “You’re a useful analysis assistant. Your objective is to seek out details about X. Please present your output in a legitimate JSON format and don’t embrace any conversational filler.” will be distilled into this 12-token immediate: “Act: ResearchBot. Activity: Discover X. Output: JSON. No fluff.” The mannequin will perceive it in a virtually similar trend. Think about a 100-step loop: this 30-token distinction alone can save about 3,000 tokens simply on the system immediate.
Output:
|
Loop 1 | Full Context Tokens: 37 Loop 2 | Full Context Tokens: 55 Loop 3 | Full Context Tokens: 73 Loop 4 | Full Context Tokens: 91 Loop 5 | Full Context Tokens: 109 —– Compressing Historical past —–
Closing Uncompressed Tokens: 109 Closing Compressed Tokens: 36 Financial savings: 67.0% |
Wrapping Up
Immediate compression is just not a minor optimization; it’s a sensible necessity for any agentic system that runs greater than a handful of steps. The methods coated right here, from instruction distillation and recursive summarization to RAG-based historical past retrieval and LLMLingua, every tackle the quadratic price downside from a distinct angle, and they are often mixed for even larger financial savings. As a place to begin, recursive summarization paired with a distilled system immediate requires no further infrastructure and might already minimize token utilization dramatically, as the instance above demonstrates.
On this article, you’ll be taught what immediate compression is, why it issues for agentic AI loops, and implement it virtually utilizing summarization and instruction distillation.
Subjects we’ll cowl embrace:
- Why agentic loops accumulate token prices quadratically, and the way immediate compression addresses this.
- A overview of the principle immediate compression methods, together with instruction distillation, recursive summarization, vector database retrieval, and LLMLingua.
- A working Python instance that mixes recursive summarization and instruction distillation to attain significant token financial savings.
Introduction
Agentic loops in manufacturing will be synonymous with excessive prices, particularly relating to each LLM and exterior utility utilization through APIs, the place billing is commonly carefully associated to token utilization.
The excellent news: immediate compression is without doubt one of the handiest methods you possibly can implement to navigate the excessive prices of agentic loops. This text introduces and discusses how various immediate compression strategies may help alleviate monetary points when utilizing agentic loops.
Immediate Compression: Motivation and Frequent Methods
Quite a few agentic frameworks, corresponding to LangGraph and AutoGPT, implement that the agent retains a context of what it has executed in earlier steps. Suppose your agent must take 10 to twenty steps to resolve an issue. To conduct step 1, it sends 500 tokens. For step 2, it should ship these prior 500 tokens plus new info inherent to this step — say about 1,000 tokens in complete. This will develop to about 1,500 tokens in step 3, and so forth. By the point we attain the twentieth step, we’ve got been “paying” for sending largely the identical info again and again.
Within the instance above, it could look like the variety of tokens despatched per step (full immediate dimension) grows linearly. Actually, nonetheless, the cumulative prices of your complete agent loop change into quadratic, not linear, main to a price explosion for long-lasting loops. That is the place immediate compression strategies come to assist, with methods like selective context, summarization, and others, as we’ll talk about shortly.
Instance price curve of agentic loops with out vs. with immediate compression
The problem isn’t just monetary: there’s one other hidden price associated to latency, as longer prompts take longer to course of, and never all customers are prepared to attend 30 seconds per interplay. Compressed prompts additionally allow quicker inference and scale back compute overhead.
To place this in perspective, a 500K token context might theoretically be diminished to a 32K token compressed window that retains all related info, whereas components like repetitive JSON buildings, cease phrases, and low-value conversational components are eliminated. Listed here are some cost-effective options and frameworks that may be thought-about for implementing your personal immediate compression technique:
- Instruction distillation: this consists of making a “compressed” model of an extended system immediate that could be despatched repeatedly, containing symbols or shorthand that the mannequin will perceive and interpret.
- Recursive summarization: each few steps in a loop, use the agent or a smaller, cheaper mannequin like Llama 3 or GPT-4o-mini to summarize the earlier steps’ context right into a extra succinct paragraph outlining the present state of the duty.
- Vector database (RAG) for historical past retrieval: this replaces sending the total historical past repeatedly by storing it in a free, native vector database like FAISS or Chroma. For any given immediate, solely essentially the most related actions are retrieved as a part of its context.
- LLMLingua: an open-source framework that’s gaining recognition, targeted on detecting and eliminating “non-critical” tokens in a immediate earlier than it’s despatched to a bigger, dearer language mannequin.
A Sensible Instance: Summarizing Agent
Under is an instance of a cost-friendly immediate compression technique that mixes recursive summarization and instruction distillation utilizing Python. The code is meant to function a template of what such immediate compression logic ought to appear to be when translated into an actual, large-scale state of affairs. It reveals a simplified simulation of an agentic loop, emphasizing the summarization and distillation steps:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import tiktoken
def count_tokens(textual content, mannequin=“gpt-4o”): encoding = tiktoken.encoding_for_model(mannequin) return len(encoding.encode(textual content))
def compress_history(history_list): “”“ A operate that simulates ‘Summarization’. In an actual app, it entails sending the enter to a small language mannequin (like gpt-4o-mini) to condense it. ““”
print(“— Compressing Historical past —“)
# In manufacturing, cross ‘mixed’ to a summarization mannequin mixed = ” “.be part of(history_list)
# Distillation: Shorthand model of the occasions abstract = f“Abstract of {len(history_list)} steps: Duties A & B accomplished. End result: Success.” return abstract
# 1. Distilled System Immediate (makes use of shorthand as an alternative of prose) system_prompt = “Act: ResearchBot. Activity: Discover X. Output: JSON solely. Constraints: No fluff.”
# 2. The Agentic Loop historical past = [] raw_token_total = 0
for step in vary(1, 6): motion = f“Step {step}: Agent carried out a really long-winded seek for information level {step}…” historical past.append(motion)
# Calculating what the immediate WOULD appear to be with out compression current_full_context = system_prompt + ” “.be part of(historical past) raw_tokens = count_tokens(current_full_context)
print(f“Loop {step} | Full Context Tokens: {raw_tokens}”)
# 3. Making use of Compression compressed_context = system_prompt + compress_history(historical past) compressed_tokens = count_tokens(compressed_context)
print(f“nFinal Uncompressed Tokens: {raw_tokens}”) print(f“Closing Compressed Tokens: {compressed_tokens}”) print(f“Financial savings: {((raw_tokens – compressed_tokens) / raw_tokens) * 100:.1f}%”) |
This code reveals periodically change the cumulative checklist of actions with a abstract that spans a single string, serving to keep away from the added prices of paying for a similar context tokens in each loop iteration. Attempt utilizing a small, low cost mannequin or an area one like Llama 3 to carry out the summarization step.
Concerning distillation, this instance illustrates what it really does:
A normal 42-token immediate that reads “You’re a useful analysis assistant. Your objective is to seek out details about X. Please present your output in a legitimate JSON format and don’t embrace any conversational filler.” will be distilled into this 12-token immediate: “Act: ResearchBot. Activity: Discover X. Output: JSON. No fluff.” The mannequin will perceive it in a virtually similar trend. Think about a 100-step loop: this 30-token distinction alone can save about 3,000 tokens simply on the system immediate.
Output:
|
Loop 1 | Full Context Tokens: 37 Loop 2 | Full Context Tokens: 55 Loop 3 | Full Context Tokens: 73 Loop 4 | Full Context Tokens: 91 Loop 5 | Full Context Tokens: 109 —– Compressing Historical past —–
Closing Uncompressed Tokens: 109 Closing Compressed Tokens: 36 Financial savings: 67.0% |
Wrapping Up
Immediate compression is just not a minor optimization; it’s a sensible necessity for any agentic system that runs greater than a handful of steps. The methods coated right here, from instruction distillation and recursive summarization to RAG-based historical past retrieval and LLMLingua, every tackle the quadratic price downside from a distinct angle, and they are often mixed for even larger financial savings. As a place to begin, recursive summarization paired with a distilled system immediate requires no further infrastructure and might already minimize token utilization dramatically, as the instance above demonstrates.
















{kind=link}