


[3], a web-based vector quantization methodology, drew extensive public consideration at ICLR 2026. For me, it appeared very acquainted: it overlaps closely with EDEN, a quantization methodology first launched because the 1-bit methodology DRIVE at NeurIPS 2021 [1] and generalized to arbitrary bit-widths at ICML 2022 [2]. Co-authored on my own, with Ran Ben-Basat, Yaniv Ben-Itzhak, Gal Mendelson, Michael Mitzenmacher, and Shay Vargaftik.
The TurboQuant paper presents two variants: TurboQuant-mse and TurboQuant-prod. In an in depth new comparability [5] we present that TurboQuant-mse is a degenerate case of EDEN, and that the EDEN variants persistently outperform their counterparts.
How EDEN quantizes a vector
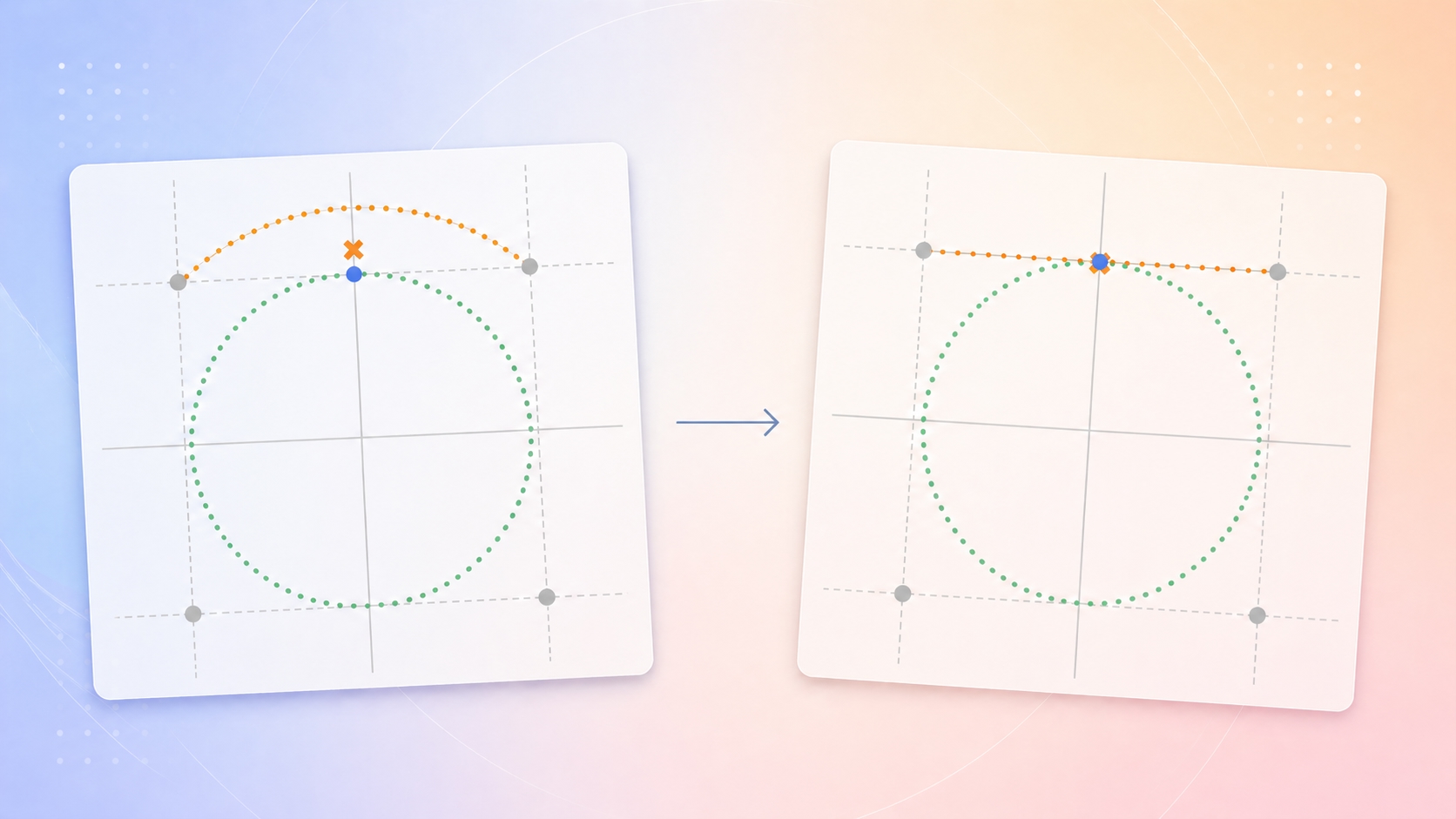
Suppose you could compress a -dimensional vector (a gradient replace, an embedding, a KV-cache entry) down to some bits per coordinate. EDEN proceeds in 4 steps:
- Random rotation — Multiply by a random orthogonal matrix . After rotation the coordinates are identically distributed and, for giant , roughly Gaussian.
- Scalar quantization — Spherical every rotated coordinate to one in all ranges from a Lloyd–Max codebook educated on the recognized rotated coordinate distribution ( is the goal variety of bits per coordinate).
- Scale — Multiply by a scale issue .
- Inverse rotation — Apply to recuperate an approximation of the unique vector.
Whereas earlier works (e.g., Suresh et al. (2017) [6]) used rotation primarily to shrink the coordinates’ dynamic vary (the hole between the most important and smallest coordinate worth), EDEN [1] was, to the very best of our information, the primary quantization scheme to take advantage of a stronger reality about random rotation: the post-rotation coordinates comply with a recognized distribution, which lets us use a deterministic quantizer paired with a closed-form scale that, relying on the appliance, both minimizes MSE or makes the estimate unbiased. Each scales are derived analytically, and the development yields an asymptotic MSE discount over the earlier strategy.
Concretely, EDEN’s two variants differ solely within the alternative of :
- EDEN-biased — units to the closed-form worth that minimizes the reconstruction MSE.
- EDEN-unbiased — chooses so the decompressed output is right on common (), which issues notably everytime you common many quantized vectors (e.g., distributed coaching, consideration).
Lined up in opposition to EDEN, TurboQuant-mse matches at each step besides one: the place EDEN derives the size analytically, TurboQuant-mse, though it targets MSE minimization, skips the optimized scaling.
The pseudocode beneath reveals the three aspect by aspect.

Why the optimum scale is price it
The worth of making use of correct scale grows with bit-width. At bit, the hole is marginal. At and bits, EDEN-biased reduces MSE by 2.25% over TurboQuant-mse, and these are the bit-widths practitioners really use for embeddings and KV caches.
Throughout dimensions 16 to 4096 and all examined bit-widths , EDEN-biased vNMSE (vector-normalized MSE, ) falls beneath TurboQuant-mse’s in each case (Determine 2). As dimension grows very massive, the optimum approaches 1 and the 2 algorithms converge, however at sensible dimensions (128–1024), the hole persists.

Unbiased compression: saving greater than a full bit
The outcomes above concern the biased (MSE-minimizing) variants. Now take into account the unbiased case, the place purposes corresponding to distributed coaching, approximate consideration, or inner-product retrieval want as a result of they common many quantized vectors.
EDEN-unbiased makes use of the identical single-pass algorithm as EDEN-biased, simply with chosen for bias correction. TurboQuant’s unbiased variant, TurboQuant-prod, takes a distinct route: it spends bits on the biased TurboQuant-mse step and reserves 1 bit for a QJL (Quantized Johnson–Lindenstrauss) [4] correction on the residual (QJL is much like EDEN at , however with larger variance).
EDEN-unbiased outperforms TurboQuant-prod in each examined configuration, and by a considerable margin. The hole traces to a few structural benefits of EDEN’s single-pass design:
- EDEN optimizes the size. TurboQuant-prod inherits TurboQuant-mse’s first stage, so it carries the identical MSE penalty.
- EDEN’s 1-bit development has decrease variance than QJL. In massive dimensions, EDEN’s 1-bit vNMSE converges to [1], whereas QJL’s converges to [4], roughly 2.75× larger.
- EDEN spends the total bit finances on a single unbiased quantizer. TurboQuant-prod splits the finances into biased bits plus 1 residual bit, which empirically underperforms spending all bits on a single unbiased quantizer [5].
These results compound. The consequence: 1-bit, 2-bit, and 3-bit EDEN-unbiased are every extra correct than 2-bit, 3-bit, and 4-bit TurboQuant-prod, respectively (Determine 3). By swapping in EDEN you possibly can drop a bit per coordinate and nonetheless match TurboQuant-prod’s accuracy.

On TurboQuant’s personal benchmarks
The identical image holds on the usual ANN benchmarks TurboQuant evaluates on, Stanford’s GloVe pre-trained phrase vectors (Open Knowledge Commons Public Area Dedication and License v1.0) and Qdrant’s dbpedia-entities-openai3-text-embedding-3-large embeddings (Apache 2.0), utilizing TurboQuant’s revealed analysis code:
EDEN-biased achieves decrease MSE than TurboQuant-mse, EDEN-unbiased achieves markedly decrease inner-product error than TurboQuant-prod, and nearest-neighbor recall on each datasets favors EDEN (Determine 4).

Takeaway: use EDEN; optimum scaling issues
EDEN’s scale connects the recognized post-rotation distribution to an analytically optimum quantizer. TurboQuant-mse retains EDEN’s rotation and the codebook however pins , which is what makes it a strictly weaker particular case. TurboQuant-prod provides a 1-bit QJL stage on high of that, the place EDEN-unbiased will get the identical property, with higher accuracy, by simply selecting a bias-correcting scale.
- For MSE-targeted compression (mannequin weight quantization, nearest-neighbor search, KV cache): EDEN-biased computes the optimum scale and persistently beats TurboQuant-mse (which is EDEN with mounted).
- For unbiased estimation (distributed imply estimation, approximate consideration, inner-product retrieval): EDEN-unbiased considerably outperforms TurboQuant-prod’s bit-splitting technique, by margins price greater than a full bit per coordinate.
EDEN was initially developed for distributed imply estimation in federated and distributed coaching. Subsequent work has, for instance, utilized it to embedding compression for doc re-ranking (SDR, 2022 [8]), tailored it for NVFP4 LLM coaching (MS-EDEN in Quartet II, 2026 [10]), generalized it to vector quantization for data-free LLM weight compression (HIGGS, 2025 [9]), which was then used for KV-cache compression (AQUA-KV, 2025 [11]).
EDEN implementations can be found: in PyTorch and TensorFlow, in Intel’s OpenFL [7], and its 1-bit variant in Google’s FedJax, TensorFlow Federated, and TensorFlow Mannequin Optimization.
For the total technical comparability evaluation with TurboQuant (all figures, detailed experimental methodology), see our observe [5].
For the unique derivations, proofs, and additional extensions, see our unique papers [1] [2].
References
- S. Vargaftik, R. Ben-Basat, A. Portnoy, G. Mendelson, Y. Ben-Itzhak, M. Mitzenmacher, DRIVE: One-bit Distributed Imply Estimation (2021), NeurIPS 2021.
- S. Vargaftik, R. Ben-Basat, A. Portnoy, G. Mendelson, Y. Ben-Itzhak, M. Mitzenmacher, EDEN: Communication-Environment friendly and Strong Distributed Imply Estimation for Federated Studying (2022), ICML 2022.
- A. Zandieh, M. Daliri, A. Hadian, V. Mirrokni, TurboQuant: On-line Vector Quantization with Close to-optimal Distortion Fee (2026), ICLR 2026.
- A. Zandieh, M. Daliri, I. Han, QJL: 1-Bit Quantized JL Rework for KV Cache Quantization with Zero Overhead (2024), arXiv:2406.03482.
- R. Ben-Basat, Y. Ben-Itzhak, G. Mendelson, M. Mitzenmacher, A. Portnoy, S. Vargaftik, A Word on TurboQuant and the Earlier DRIVE/EDEN Line of Work (2026), arXiv:2604.18555.
- A. T. Suresh, F. X. Yu, S. Kumar, H. B. McMahan, Distributed Imply Estimation with Restricted Communication (2017), ICML 2017.
- VMware Open Supply Weblog, VMware Analysis Group’s EDEN Turns into A part of OpenFL (November 2022).
- N. Cohen, A. Portnoy, B. Fetahu, A. Ingber, SDR: Environment friendly Neural Re-ranking utilizing Succinct Doc Illustration (2022), ACL 2022.
- V. Malinovskii, A. Panferov, I. Ilin, H. Guo, P. Richtárik, D. Alistarh, HIGGS: Pushing the Limits of Giant Language Mannequin Quantization through the Linearity Theorem (2025), NAACL 2025.
- A. Panferov, E. Schultheis, S. Tabesh, D. Alistarh, Quartet II: Correct LLM Pre-Coaching in NVFP4 by Improved Unbiased Gradient Estimation (2026), arXiv:2601.22813.
- A. Shutova, V. Malinovskii, V. Egiazarian, D. Kuznedelev, D. Mazur, N. Surkov, I. Ermakov, D. Alistarh, Cache Me If You Should: Adaptive Key-Worth Quantization for Giant Language Fashions (2025), ICML 2025.
















{kind=link}