


that working with AI in manufacturing is fairly costly. Everyone knows this and we all know most distributors are working fairly exhausting to determine how you can make brokers cheaper.
This is the reason I believed it was a good suggestion to undergo just a few design ideas to remember if you’re constructing, which will help you perceive the place you may seize some financial savings.
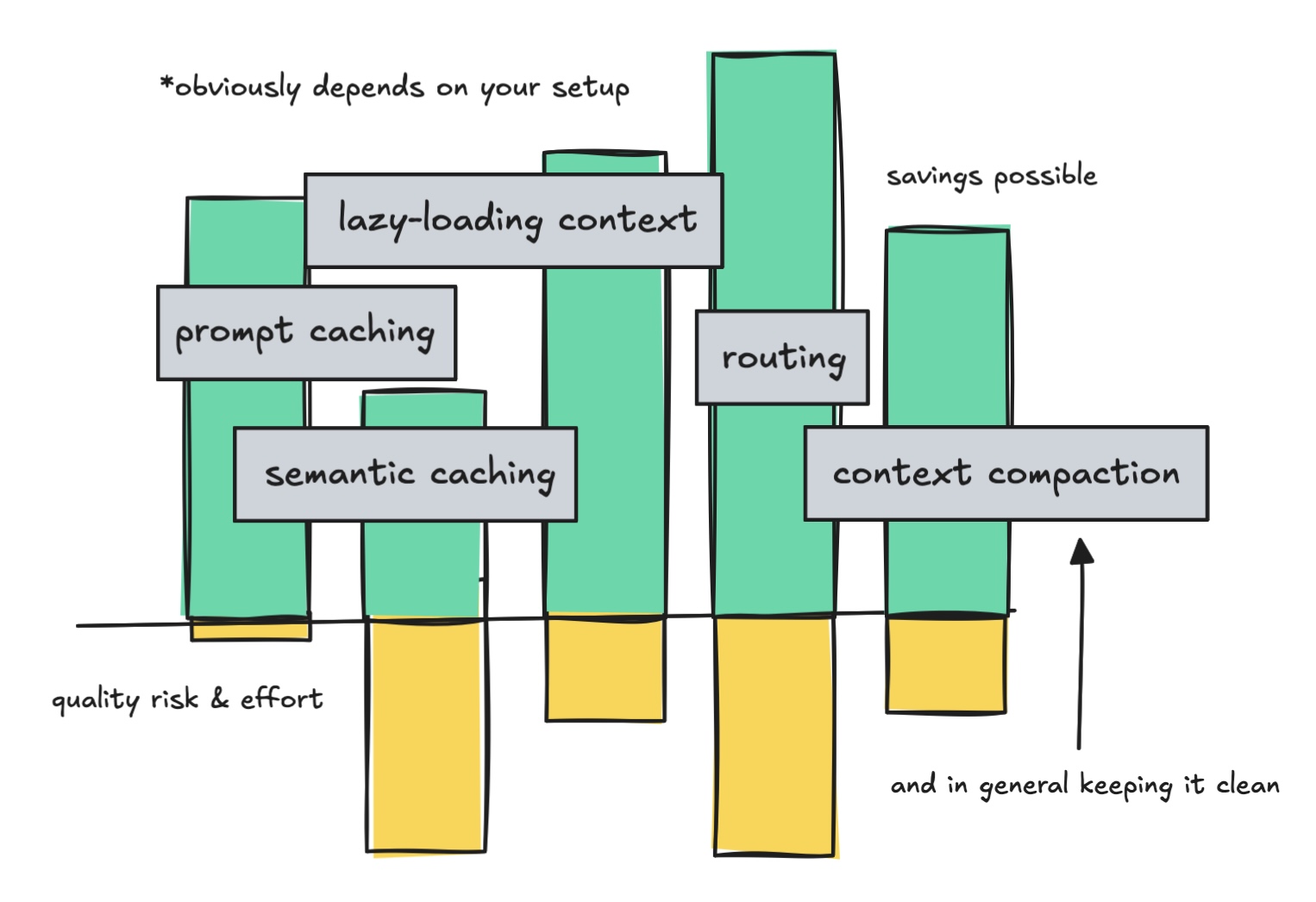
We’ll undergo how immediate caching works and why it’s a fast win, semantic caching, lazy-loading instruments and MCPs, routing and cascading, delegating to subagents, and a bit on maintaining the context clear.
I’m together with interactive graphs all through this text — that helps you visualize the fee financial savings every precept can get you based mostly on the quantity of tokens you might be utilizing.
Sure, I’m clearly staying actual all through, each saving comes with trade-offs.
Brokers get costly because the context grows
Your first agent would possibly ship with a 500-token system immediate and two instruments, however as soon as it grows up, these numbers balloon quick.
Simply for instance, the leaked Claude system immediate ran round 24,000 tokens, GPT-5’s round 15,000. Folks have complained {that a} easy “hello” in Claude Code with an empty folder consumed roughly 31,000 tokens. OpenClaw customers have reported greater than 150,000 enter tokens despatched to Gemini 3.1 Professional for 29 tokens of output on the primary flip.
Add in instruments and MCP servers and the numbers get genuinely ridiculous. Instrument definitions alone can run into the tens of 1000’s of tokens. Skip cleansing up software outputs and previous dialog exhaust and also you’re paying for that junk on each flip too.
With out optimization, 100 messages a day at 166K enter tokens runs round $996 a month on Gemini 3.1 Professional and roughly $2,490 on Claude Opus 4.6.
There are methods to maintain these prices down, although loads of manufacturing setups fail to make use of them accurately so let’s undergo all of them intimately.
4 design ideas to maintain in thoughts
On this article we’ll undergo 4 totally different ideas with 4 totally different interactive calculators.

First, we’ll be taking a look at how you can reuse tokens when potential, taking a look at immediate caching and semantic caching. Then we’ll have a look at how you can decrease the secure and all the time added tokens like reminiscence and software definitions.
It’s going to additionally undergo how you can path to smaller fashions, or escalate to a bigger mannequin, trying on the high quality dangers and the financial savings thereof.
The final part will discuss maintaining the context clear for efficiency and financial causes, whereas briefly mentioning compaction.
Reuse tokens when potential
LLM value doesn’t simply come from calling the mannequin too usually. It additionally comes from repeatedly paying to course of the identical tokens time and again.
So for this part we’ll cowl Okay/V caching, the mechanism beneath immediate caching, and semantic caching, that are two very various things. We’ll undergo what they’re, what they do, what it can save you.
Immediate caching is a fast win for lengthy system prompts, whereas semantic caching is a little more work and comes with a bit extra threat.
Okay/V caching & prefix caching
Earlier than a mannequin can generate something, it first has to course of the immediate. This step is named prefill. Prefill prices compute, which implies latency and cash. So, to be environment friendly, we shouldn’t preserve re-processing the identical content material.
Once you use a big language mannequin, the immediate first will get tokenized, then these tokens flip into vectors, after which inside every consideration layer these vectors get projected into Okay/V tensors.

The inference engine has to cache the Okay/V tensors throughout era, in any other case the mathematics doesn’t work at any affordable pace. After it has completed it throws that cache away.
However as a substitute of throwing the cache away when the response ends, we are able to retailer it, tagged in a method that lets us discover it once more.
Subsequent time a request is available in, we’d verify whether or not that very same a part of the immediate matches one thing we have already got tensors for. If sure, we load these tensors and skip re-processing it.

To get a way of why this issues economically: let’s say it takes one second to course of 2,000 tokens, and you’ve got a system immediate of 10,000 tokens.
That’s 5 seconds saved on each single LLM name, simply by not recomputing that very same begin of the immediate by the mannequin again and again (although prefill throughput varies lots based mostly on the setup).
It’s vital to notice that we now have to match the textual content precisely to the saved Okay/V cache.
If the tokens change, we don’t have precomputed Okay/V tensors for that precise a part of the immediate anymore, so it needs to be processed once more. That is the place individuals preserve stumbling: a brand new area added, a reordered software definition, a timestamp within the improper place.
So, storing the cache has actual worth when it comes to dashing up the request, and in flip making the request cheaper.
Notice that storing these tensors is just not free. Cached Okay/V takes up reminiscence on the serving facet.
Now, we don’t must construct this ourselves, this was simply to assume by the mechanics. There are frameworks that assist with this, and the API suppliers have their very own prompt-caching guidelines, and we’ll undergo each.
Prefix caching for self-hosted inference
If you’re internet hosting an open supply mannequin, you’d ideally use an LLM serving framework, like vLLM. Although there are different frameworks that can assist with the caching layer, vLLM has an add-on function we are able to run by.
To assist with this, vLLM chops up the immediate into blocks, hashes every block based mostly on its tokens (plus the tokens earlier than it), and retailer the Okay/V tensors towards these hashes.
Like most setups the static half that ought to be cached ought to go within the first a part of the immediate.
To allow caching in vLLM use the flag --enable-prefix-caching
Different flags allow you to alter the --block-size after which I feel it permits you to explicitly set KV cache measurement per GPU with one thing like --kv-cache-memory-bytes
Block sizes means tokens per block. If block measurement is 16 then you have got 16 tokens per block earlier than it cuts off and begins one other. 
The extra reminiscence you give it, the longer it will possibly maintain on to cached blocks. However if in case you have numerous totally different lengthy requests taking place on the similar time, that reminiscence fills up sooner, so previous blocks get eliminated sooner.
There are different options on the market, however you get the thought. It’s the identical mechanics we spoke about for the earlier part.
You can too take a look at SGLang and RadixAttention for prefix caching, in addition to LMCache that ought to plug into serving engines.
Most individuals although use the API suppliers they usually have their very own insurance policies on how you can use immediate caching so let’s stroll by these.
Immediate caching through API suppliers
Utilizing the API suppliers you want to be certain to construction your prompts in order that they hit the cache. There are issues you want to observe for this to be finished accurately.
I’ll use OpenAI first right here for instance.
For OpenAI, they’re express, to cache a part of the immediate they require an actual prefix match. I.e. the identical static enter firstly of the immediate.

This implies you all the time put secure directions, examples, and instruments first, and variable content material later.

You can too ship in prompt-cache-key which will help route related requests collectively and enhance cache hit charges.
There are extra specifics round this too. Caching is enabled robotically for prompts which might be 1,024 tokens or longer, however they use the primary 256 tokens to route requests again to the identical cache. So, that static a part of the immediate must be greater than 256 tokens.
For Anthropic it’s important to allow caching with the cache-control parameter.
Price mentioning too that sometimes the evictions (TTL) happen round 5–10 minutes of inactivity however will be prolonged. It’s the identical for Anthropic however you may push it to at least one hour (however it might value you extra at 2x).
Earlier I talked concerning the time you save, and in the event you’re self-hosting, this additionally saves cash. With API suppliers, the financial savings present up as cheaper cached enter tokens.
With OpenAI cached enter is as much as 90% off the bottom enter.
Anthropic offers you an identical low cost on cached inputs, however you additionally pay to retailer that cache. So, in the event you’re not utilizing it accurately, Anthropic will likely be costlier.
Normally although, if in case you have 90% of your immediate being static, it can save you as much as 80% on heat calls.

I made a decision to create an interactive graph for this with Claude right here, so you may mess around with it.
So, immediate caching is a fairly good win for everybody in the event you’re utilizing longer system prompts that keep the identical and one thing to think about to avoid wasting on tokens.
Let’s transfer onto semantic caching, which is one thing else totally.
Semantic caching
Semantic caching matches on that means, i.e. if it’s a related sufficient request, return the cached consequence. Though it sounds simple sufficient, there are clear pitfalls to be careful for.
To semantically match texts, we use embeddings. You are able to do some analysis right here if the phrase is new to you. I wrote about it just a few years in the past.
In essence, embeddings are vectors that we are able to examine towards one another utilizing cosine similarity. If similarity is excessive, the that means ought to be related, although it is determined by the mannequin.

What semantic caching is proposing is then to match related requests to solutions that exist already. Asking for “What’s the capital of France?” and “Fast, give me the capital of France” ought to then path to the identical reply.
No want to make use of an LLM to reply the identical factor again and again.
This works tremendous if many individuals ask near-identical generic questions and the info isn’t going stale too quick.
So why not do it for each case? There are a ton of pitfalls right here.
Simply on the prime of my head, you want to think about what threshold to make use of for similarity, how lengthy the reply ought to keep legitimate, what occurs on multi-turn questions, what really will get saved, whether or not there ought to be a router carried out too, how you can separate customers, and what occurs if the improper reply is cached.
You additionally want to think about (Time to Reside — TTL), as in when info turns stale and for which questions.
So despite the fact that the mechanics are fairly easy, you continue to want metadata filters and tags, corresponding to person, workspace, corpus model, persona, session/person scoping, sensible TTL, and a few rule for “is the return sufficient?”
This then turns right into a little bit of a challenge.
So, if you wish to do it, maybe use the semantic index to discover a earlier query. Totally different questions can level to the identical saved reply, which implies much less storage blowup. Be sensible about TTL by utilization, if one thing is reused usually, retain it longer, in any other case, take away it.
I might additionally counsel you do it after you see repetition within the logs slightly than firstly. It might be that the use case is simply not good for it.
As for how you can do it, many databases can do that for you. However there are additionally libraries like semanticcache, prompt-cache, GPTCache, vCache, Upstash semantic-cache, Redis + LangCache, that assist with plumbing.
There are clearly financial savings right here to be made. Redis claims as much as 68.8% fewer API calls and 40–50% latency enchancment, although bear in mind it is a bit of selling as they’re utilizing a transparent Q&A use instances right here.
So it utterly is determined by your setup. In case you have a Q/A agent with numerous redundant calls, then it can save you extra. In case you have a coding bot with distinctive calls, then you definitely’ll save much less.
Immediate caching does properly when the altering query sits inside a big static immediate. Semantic caching does properly when individuals preserve asking the identical factor in numerous phrases.
You’ll be able to mess around with this interactive software to see the fee financial savings with each.
Earlier than we transfer on from this part, I might simply level out that there are numerous financial savings to be constructed from normal caching too.
Bear in mind to cache the costly deterministic stuff like SQL question outcomes, software outputs, and retrieval outcomes. By no means run these items extra occasions than you want to.
I do that for one in all my instruments. It gathers key phrase knowledge to summarize, then caches it till that knowledge is stale. Whether it is stale, it reruns it when that route is hit.
So, semantic caching is an fascinating thought and will prevent tokens for sure use instances but it surely takes engineering to do it properly.
Don’t preload dormant tokens
This half is about what occurs when your system immediate begins rising due to issues like cumbersome instruments or rising reminiscence.
For smaller brokers, this isn’t actually a problem, however in case you are working with agent specs that continue to grow, there are methods to slim it down and fetch info on-demand (or not less than attempt to).
Hold context slim and fetch particulars on-demand
As soon as your agent immediate grows past a sure level, it may be good to maintain the always-loaded layer as small and secure as potential, and continue to grow particulars separate.
This issues as a result of as soon as these layers begin to develop, corresponding to if you load just a few hundred instruments or ship full MCP server descriptions that preserve altering, it will get noisy.

The issue is clearly not simply value, but in addition efficiency. And if one in all these layers retains altering, immediate caching turns into a lot more durable to hit correctly.
So, the thought is to maintain the highest layer as compact and secure as you may. The highest layer ought to assist the mannequin perceive the place it’s and the place to go subsequent, but it surely doesn’t want to hold the entire world up entrance.

When you’ve seemed by the supply code for Claude Code, you’ve seen that they use one thing like this for his or her reminiscence system.
They’ve an always-loaded index file that shouldn’t develop past 200 strains, with detailed subject information elsewhere. Although what the agent does in apply versus what the system needs is a subject for an additional time.
You’ll be able to see the identical thought pop up elsewhere too, corresponding to in Claude’s superior software setup, Claude Expertise’ layered setup, and makes an attempt to lazy-load MCP instruments as a substitute of dumping each server definition into the immediate up entrance.
The place that is finished and if it works
The thought is sound. When context grows, it will get more durable for an LLM to choose the suitable motion. However this area continues to be early, so we’ll undergo a software for instance to see how this could work.
Just a few months in the past, Anthropic launched one thing referred to as superior Instrument Search. This goes into the area of how you can preserve context slim whereas nonetheless giving the mannequin entry to tons of of instruments.
Anthropic says they’ve seen 55K to 134K tokens of software definitions earlier than optimization, and that improper software choice is a standard failure mode when the context grows this huge.

So, a search software would then optimize the context by having the LLM use it to search out instruments, slightly than outline all of them up entrance.
instruments=[
{
"type": "tool_search_tool_bm25_20251119",
"name": "tool_search"
},
{
"name": "search_contacts",
"description": "Find a contact by name or email.",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
},
{
"identify": "send_email",
"description": "Ship an electronic mail to a number of recipients.",
"input_schema": {
"sort": "object",
"properties": {
"to": {"sort": "string"},
"topic": {"sort": "string"},
"physique": {"sort": "string"}
},
"required": ["to", "subject", "body"]
},
"defer_loading": True
}
]What you see above is that we outline one software referred to as tool_search. You’ll be able to choose one of many out-of-the-box choices, BM25 or Regex, or construct your individual customized one. Then we set one software as deferred for instance.
You’ll solely do that in the event you had 10+ instruments although.
Anthropic does the looking for you, so that you don’t see the way it provides this software schema into the system immediate, nor do you see how the search occurs beneath the hood.
They do say that when there’s a software match, its definition is appended inline as a tool_reference block within the dialog for the LLM.

The thought is neat: smaller preliminary context, however you’re nonetheless including one further search step. Folks have additionally examined this software with considerably lackluster outcomes, however that was with 4,000 instruments, so there’s extra room for testing.
It’s additionally on us to outline the instruments properly sufficient that they are often searched. But it surely turns into more durable to debug what is occurring when you may’t see the intermediate step.
This concept pops up elsewhere too, however individuals typically simply name it good AI engineering. Don’t expose the agent to large messy context. As a substitute, give it a approach to slender issues down, and solely then let it examine or load the software when wanted.
For this half, there are critical financial savings to be made as properly, although it is determined by what number of tokens you might be sending within the first place.
We created this further calculator that compares software search and immediate caching.

What we see is that each immediate caching and lazy-loading context provide you with financial savings, however collectively it’s not an enormous change. Instrument search like this isn’t nearly financial savings although because it helps preserve the context clear efficiency clever.
However in the event you’re simply searching for financial savings, the most important win is to choose not less than one.
Use low cost fashions for reasonable work
This part is about routing prompts to totally different fashions, together with utilizing subagents with cheaper fashions for sure duties, and the way this could lower token prices but in addition threat high quality.
This area is fascinating as a result of most individuals argue that 60% or extra of incoming questions are simple duties, and thus don’t want the strongest mannequin, particularly not a pondering one.
ChatGPT does this utilizing indicators like dialog sort, complexity, software wants, and express intent (“assume exhausting”). Claude makes use of description-based delegation and built-in subagents like Discover.
The thought is easy to know, however having the ability to do it proper with out risking an excessive amount of high quality is the exhausting half.
So, let’s undergo each predictive routing and output-checked approaches like cascades and subagents, so you may get a really feel for what you may check by yourself.
The financial savings that may be made listed here are very actual. I created one other interactive graph for this half that you’ll find right here. Bear in mind it’s vibe-coded, so extra of a sort-of-right-please-double-check form of factor.
Path to fashions based mostly on job issue
Request-level routing means attempting to estimate issue and intent earlier than seeing any output. The upside is excessive, however a foul alternative can poison the entire session, so there are some high quality drawbacks to remember.
To do that, you want some form of router mannequin that decides the place to route the request.

We don’t know precisely what OpenAI makes use of as indicators to path to totally different fashions, however I don’t find out about you, I continuously really feel like I’m being delegated to a much less competent mannequin at occasions and it may be infuriating.
There are methods for us to nonetheless collect intel although, trying on the open supply group. We will have a look at RouteLLM from LMSYS, the Berkeley group behind Chatbot Area. This answer learns from actual desire knowledge from Chatbot Area.
RouteLLM makes use of normal embeddings after which a tiny router head, so internet hosting this shouldn’t be that costly.
I’ve not examined RouteLLM myself, however they report massive value reductions whereas maintaining most of GPT-4’s efficiency.
I did, although, dig into the LLMRouterBench paper, which just about stated that many realized routers barely beat easy baselines, corresponding to key phrase/heuristic routing, embedding nearest-neighbor, or kNN-style routing.

Which means that the flamboyant routers round could not provide you with that a lot of a lift in comparison with simply utilizing one thing easy.
As for utilizing a bigger LLM as a router, like Haiku, that can simply eat into your financial savings, so it appears pointless. A small fine-tuned classifier carries internet hosting prices, and a hand-built router, like the instance above, continues to be brittle.
Folks haven’t deserted routing due to this, however individuals are nonetheless tinkering with it, so it’s not a slam dunk when it comes to financial savings if the standard of the solutions can’t sustain.
Now, there are additionally out-of-the-box options on this area, corresponding to OpenRouter Auto and Switchpoint. Nevertheless, there’s nothing public on their routing internals or public accuracy numbers in the way in which I needed.
However for this part, additionally take a look at the calculator we did for LLMRouter, heuristics, self-hosted classifier, LLM-as-router, RouteLLM, OpenRouter Auto.
As for high quality and the way this works for real-world initiatives, I can’t say earlier than doing higher testing by myself first, so this area actually deserves its personal article sooner or later.
We also needs to briefly cowl cascading after which subagents earlier than transferring on.
Begin with low cost and cascade on low confidence
As a substitute of guessing from the immediate whether or not a request is “simple” or “exhausting,” we are able to additionally let a budget mannequin strive first, then resolve whether or not to maintain that reply or escalate.
Google’s “Speculative Cascades” write-up frames this tradeoff: use smaller fashions first for value and pace, and defer to bigger fashions solely when wanted.
To do that, you have got a budget mannequin generate first, then use a light-weight checker that appears at issues like logprobs/token chances, entropy or margin-style uncertainty, and/or semantic alignment.

This concept is fairly engaging, as immediate issue is usually exhausting to foretell and most routers don’t do completely. Moreover, high quality is simpler to evaluate after you have got a solution.
It additionally solely is sensible in the event you assume most questions will be answered by an easier mannequin, as you want to pay for 2 requires those being escalated.
However from the individuals implementing this, I’ve heard it’s a sexy alternative as validation latency between calls can keep beneath 20ms.
I did look into some open-source implementations like CascadeFlow, which claims 69% financial savings and 96% high quality retention vs GPT-5. But it surely’s good to notice that the prompts they examined had verifiable floor fact, corresponding to math solutions and a number of alternative.
A foremost concern to think about is that small fashions are sometimes “confidently improper,” so it would make sense to begin with conservative thresholds and escalate extra usually. That can inevitably convey prices up.
I additionally added in Cascade (cheap-first) into the interactive graph, so you may examine the financial savings with the opposite selections. If true, it could slash prices by 50% utilizing this system, in the event you want bigger fashions for sure requests in any respect, that’s.
Delegate work to subagents
Subagents are about delegating work to remoted brokers. Generally these use smaller fashions, so we are able to say it’s a type of routing as properly. The financial savings aren’t as steep right here, but it surely’s value mentioning.
Delegating to subagents is not only about value. It’s additionally about maintaining the context clear so every agent can totally deal with the duty it ought to full.
Anthropic ships Claude Code with built-in subagents, as many have seen. The Discover subagent is explicitly a Haiku employee for codebase search and exploration. So, the design precept is there: use smaller fashions for cheaper duties.
The principle Claude session additionally delegates through description matching, however we don’t see it. We simply get cheaper mixture value.
However as a result of the orchestrator usually nonetheless stays within the loop for planning, synthesis, and retries, you don’t save as a lot as we noticed with routing.

You’ll be able to have a look at the graphs we created above and see that subagents could shave off round 11% from the “no routing” choice by our calculations, so it isn’t the primary factor to go for in the event you’re simply trying to reduce prices.
My subsequent article will dig into subagents, however extra as a approach to delegate work and isolate duties when working with deepagents.
Let’s undergo the final part earlier than rounding off.
Hold your context clear
Good context engineering is often about efficiency, but it surely can be about value effectivity. So, let’s undergo context compaction and discuss how maintaining the context clear can save tokens.
The difficulty is that brokers preserve accumulating junk: software outputs, logs, repeated observations, previous plans, stale makes an attempt, and duplicated state.
That is very true for individuals constructing brokers for the primary time, the place they preserve dumping outcomes into the working state for the primary agent.
Dangerous energetic context
[system rules]
[project rules]
[user task]
grep output: 2,000 strains
file learn: 900 strains
check logs: 1,300 strains
retry logs
duplicate reads
previous dead-end reasoning
extra logs
extra logs
extra logsI’ve naturally finished this myself too, particularly with a draft agent, to see “the way it does” first.
However I’ve additionally seen individuals complain about OpenClaw context build-up, so it occurs all over the place. Folks complain about it in Claude Code too, as a result of generally, it’s simpler to simply have it add stuff to it than to work on cleansing it up.
Let’s briefly discuss this with out going an excessive amount of into the efficiency facet, which can be why you must do it.
The exhausting half is constructing a state pipeline
It is a two-tier drawback. Not solely are you “compressing the chat,” however you additionally have to preserve issues clear as you add them to the working state, and this turns into tedious engineering work.
First, to maintain the context clear, we don’t need this type of consequence to begin consuming up the context.
unhealthy state:
agent does work
→ dumps software output into context
→ reads information
→ dumps information into context
→ runs assessments
→ dumps logs into context
→ retries
→ retains all the piecesSo, the true job is first to protect the suitable state whereas deleting exhaust as you go alongside.
Uncooked output like this could go into an archive, and solely what is required goes into energetic context. Normally, the enemy might be tool-output bloat right here, so the work is to make instruments much less noisy by default.
Good energetic context
[system rules]
[project rules]
[user task]
[current working state]
Hold:
+ auth circulation lives in auth.ts + session.ts
+ bug solely occurs on refresh path
+ failing check: session_refresh_keeps_user
+ possible overwrite throughout refresh
+ information in scope: auth.ts, session.ts, auth.check.ts
Drop:
- uncooked grep outcomes
- full check logs
- duplicate file dumps
- dead-end retriesI’m additionally pondering sure items of context can have a lifecycle or a set expiry.
Then, when you attain the purpose the place you want to compress it, will probably be simpler to know what is beneficial for the LLM.
If we do some Anthropic studying on long-horizon duties, they notice that you want to work out a approach to protect architectural choices, unresolved bugs, and implementation particulars for compression as soon as it will get to that time as properly.
For LangChain’s autonomous compression, they’ve the agent resolve when to compact, as a substitute of solely doing it after the context is already bloated, as I feel is the case with Anthropic.
It’s fascinating that groups are beginning to consider compression as a methods drawback too, with benchmarks and agent-specific insurance policies, not as a generic summarization trick.
We will have a look at a current paper right here too to get an thought of the outcomes we are able to get. This one by Jia et al. argued that at 6x compression, it gave a 51.8–71.3% token-budget discount, whereas reaching a 5.0–9.2% enchancment in concern decision charges on SWE-bench Verified.
So, this isn’t nearly value, but in addition about efficiency generally.
As for prices, there’s clearly numerous work in constructing good context itself, however eradicating junk can most likely clear up 30–70% of your context, which then saves simply as a lot in {dollars}.
For example, for a 10k context window, in the event you clear up 30% to 50% at 100k runs, you would possibly save as much as $1,500. At a 40k context window, that quantity goes as much as $6,000.
We did a calculation for this right here as properly so you may visualize it. It’s good to notice that compressing brokers which might be utilizing very small low cost fashions could become costlier.
However, what’s good about attempting to maintain the context clear is that you simply’re not sacrificing high quality, as can occur with semantic caching or routing, so if finished properly, it’s a transparent acquire.
The difficulty is clearly the work to take action.
Rounding up the dialog
It is a very lengthy article that serves up 4 other ways you may reduce token prices when constructing brokers.
It very a lot is determined by your use case, use immediate caching when coping with massive system prompts that keep unchanged as you loop LLM calls, use semantic caching in case you are coping with a generic Q/A bot that should keep low cost.
Take a look at routing in the event you want to have the ability to reply each simple and exhausting questions, and if you wish to be sure you don’t ship pointless tokens preserve the context as clear as potential.

It might be value it sooner or later to make a shorter, extra economics centered article to deal with sure setups.
However I hope it was informational, join with me at LinkedIn, Medium or through my web site, if you wish to work collectively on brokers, otherwise you simply wish to learn extra of the identical stuff.
















{kind=link}