


Introduction & Context
a well-funded AI staff demo their multi-agent monetary assistant to the chief committee. The system was spectacular — routing queries intelligently, pulling related paperwork, producing articulate responses. Heads nodded. Budgets have been authorised. Then somebody requested: “How do we all know it’s prepared for manufacturing?” The room went quiet.
This scene performs out regularly throughout the trade. We’ve change into remarkably good at constructing refined agent programs, however we haven’t developed the identical rigor round proving they work. Once I ask groups how they validate their brokers earlier than deployment, I sometimes hear some mixture of “we examined it manually,” “the demo went effectively,” and “we’ll monitor it in manufacturing.” None of those are flawed, however none of them represent a top quality gate that governance can log off on or that engineering can automate.
The Drawback: Evaluating Non-deterministic Multi-Agent Methods
The problem isn’t that groups don’t care about high quality — they do. The problem is that evaluating LLM-based programs is genuinely arduous, and multi-agent architectures make it more durable.
Conventional software program testing assumes determinism. Given enter X, we anticipate output Y, and we write an assertion to validate. But when we ask an LLM the identical query twice and we’ll get totally different phrasings, totally different buildings, typically totally different emphasis. Each responses is perhaps appropriate. Or one is perhaps subtly flawed in ways in which aren’t apparent with out area experience. The assertion-based psychological mannequin breaks down.
Now multiply this complexity throughout a multi-agent system. A router agent decides which specialist handles the question. That specialist may retrieve paperwork from a data base. The retrieved context shapes the generated response. A failure wherever on this chain degrades the output, however diagnosing the place issues went flawed requires evaluating every part.
I’ve noticed that groups want solutions to a few distinct questions earlier than they’ll confidently deploy:
- Is the router doing its job? When a person asks a easy query, does it go to the quick, low-cost agent? Once they ask one thing complicated, does it path to the agent with deeper capabilities? Getting this flawed has actual penalties — both you’re losing time and cash on over-engineered responses, otherwise you’re giving customers shallow solutions to questions that deserve depth.
- Are the responses really good? This sounds apparent, however “good” has a number of dimensions. Is the data correct? If the agent is doing evaluation, is the reasoning sound? If it’s producing a report, is it full? Totally different question sorts want totally different high quality standards.
- For brokers utilizing retrieval, is the RAG pipeline working? Did we pull the correct paperwork? Did the agent really use them, or did it hallucinate data that sounds believable however isn’t grounded within the retrieved context?
Offline vs On-line: A Transient Distinction
Earlier than diving into the framework, I wish to make clear what I imply by “offline analysis” as a result of the terminology may be complicated.
Offline analysis occurs earlier than deployment, towards a curated dataset the place you realize the anticipated outcomes. You’re testing in a managed setting with no person affect. That is your high quality gate — the checkpoint that determines whether or not a mannequin model is prepared for manufacturing.
On-line analysis occurs after deployment, towards reside site visitors. You’re monitoring actual person interactions, sampling responses for high quality checks, detecting drift. That is your security internet — the continued assurance that manufacturing habits matches expectations.
Each matter, however they serve totally different functions. This text focuses on offline analysis as a result of that’s the place I see the most important hole in present follow. Groups typically bounce straight to “we’ll monitor it in manufacturing” with out establishing what “good” appears like beforehand. That’s backwards. You want offline analysis to outline your high quality baseline earlier than on-line analysis can let you know whether or not you’re sustaining it.
Article Roadmap
Right here, I current a framework I’ve developed and refined throughout a number of agent deployments. I’ll stroll by means of a reference structure that illustrates widespread analysis challenges, then introduce what I name the Three Pillars of offline analysis — routing, LLM-as-judge, and RAG analysis. For every pillar, I’ll clarify not simply what to measure however why it issues and how one can interpret the outcomes. Lastly, I’ll cowl how one can operationalize with automation (CI/CD) and join it to governance necessities.
The System underneath Analysis
Reference Structure
To make this concrete, I’ll take an instance that’s changing into extra widespread within the present setting. A monetary providers firm is modernizing its instruments and providers supporting its advisors who serve finish prospects. One of many functions is a monetary analysis assistant with capabilities to lookup monetary devices, do varied evaluation and conduct detailed analysis.

That is architected as a multi agent system with totally different brokers utilizing totally different fashions primarily based on process want and complexity. The router agent sits on the entrance, classifying incoming queries by complexity and directing them appropriately. Completed effectively, this optimizes each value and person expertise. Completed poorly, it creates irritating mismatches — customers ready for easy solutions, or getting superficial responses to complicated questions.
Analysis Challenges
This structure is elegant in idea however creates analysis challenges in follow. Totally different brokers want totally different analysis standards, and this isn’t all the time apparent upfront.
- The easy agent must be quick and factually correct, however no person expects it to supply deep reasoning.
- The evaluation agent must exhibit sound logic, not simply correct information.
- The analysis agent must be complete — lacking a significant danger think about an funding evaluation is a failure even when every thing else is appropriate.
- Then there’s the RAG dimension. For the brokers that retrieve paperwork, you’ve gotten an entire separate set of questions. Did we retrieve the correct paperwork? Did the agent really use them? Or did it ignore the retrieved context and generate one thing plausible-sounding however ungrounded?
Evaluating this method requires evaluating a number of elements with totally different standards. Let’s see how we strategy this.
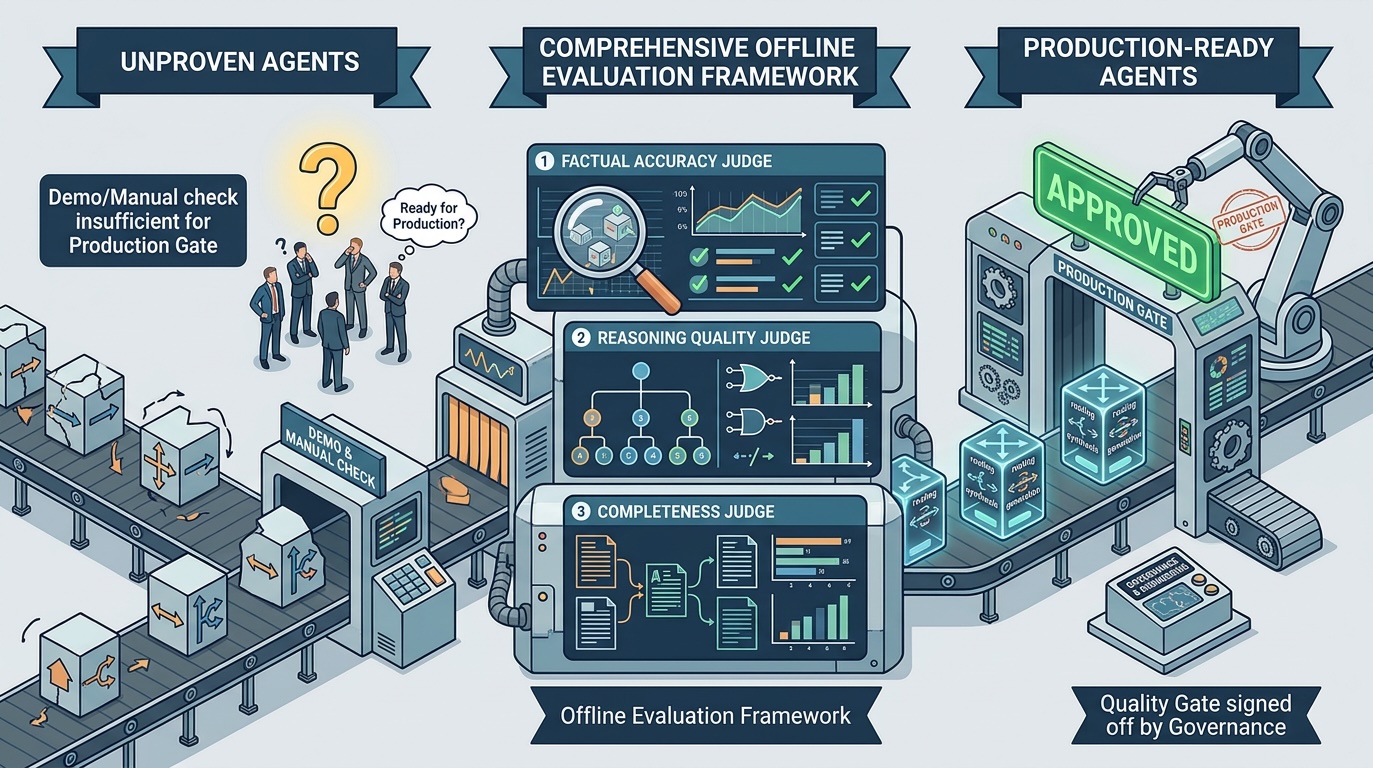
Three Pillars of Offline Analysis
Framework Overview
Over the previous two years, working throughout varied agent implementations, I’ve converged on a framework with three analysis pillars. Every addresses a definite failure mode, and collectively they supply cheap protection of what can go flawed.

The pillars aren’t unbiased. Routing impacts which agent handles the question, which impacts whether or not RAG is concerned, which impacts what analysis standards apply. However separating them analytically helps you diagnose the place issues originate fairly than simply observing that one thing went flawed.
One necessary precept: not each analysis runs on each question. Operating complete RAG analysis on a easy worth lookup is wasteful — there’s no RAG to judge. Operating solely factual accuracy checks on a posh analysis report misses whether or not the reasoning was sound or the protection was full.
Pillar 1: Routing Analysis
Routing analysis solutions what looks as if a easy query: did the router choose the correct agent? In follow, getting this proper is trickier than it seems, and getting it flawed has cascading penalties.
I take into consideration routing failures in two classes. Below-routing occurs when a posh question goes to a easy agent. The person asks for a comparative evaluation and will get again a superficial response that doesn’t handle the nuances of their query. They’re annoyed, and rightfully so — the system had the aptitude to assist them however didn’t deploy it.
Over-routing is the alternative: easy queries going to complicated brokers. The person asks for a inventory worth and waits fifteen seconds whereas the analysis agent spins up, retrieves paperwork it doesn’t want, and generates an elaborate response to a query that deserved three phrases. The reply might be effective, however you’ve wasted compute, cash, and the person’s time.
In a single engagement, we found that the router was over-routing about 40% of easy queries. The responses have been good, so no person had complained, however the system was spending 5 instances what it ought to have on these queries. Fixing the router’s classification logic minimize prices considerably with none degradation in user-perceived high quality.

For analysis, I take advantage of two approaches relying on the state of affairs. Deterministic analysis: Create a check dataset the place every question is labeled with the anticipated agent, measure what share the router will get proper. That is quick, low-cost, and offers a transparent accuracy quantity.
LLM-based analysis: provides nuance for ambiguous instances. Some queries genuinely may go both method — “Inform me about Microsoft’s enterprise” may very well be a easy overview or a deep evaluation relying on what the person really needs. When the router’s alternative differs out of your label, an LLM decide can assess whether or not the selection was cheap even when it wasn’t what you anticipated. That is dearer however helps you distinguish true errors from judgment calls.
The metrics I monitor embrace general routing accuracy, which is the headline quantity, but additionally a confusion matrix exhibiting which brokers get confused with which. If the router persistently sends evaluation queries to the analysis agent, that’s a selected calibration challenge you may handle. I additionally monitor over-routing and under-routing charges individually as a result of they’ve totally different enterprise impacts and totally different fixes.
Pillar 2: LLM-as-Decide Analysis
The problem with evaluating LLM outputs is that they don’t seem to be deterministic, in order that they can’t be matched towards an anticipated reply. Legitimate responses fluctuate in phrasing, construction, and emphasis. You want analysis that understands semantic equivalence, assesses reasoning high quality, and catches refined factual errors. Human analysis does this effectively however doesn’t scale. It isn’t possible to have somebody manually assessment hundreds of check instances on each deployment.
LLM-as-judge addresses this through the use of a succesful language mannequin to judge different fashions’ outputs. You present the decide with the question, the response, your analysis standards, and any floor fact you’ve gotten, and it returns a structured evaluation. The strategy has been validated in analysis exhibiting robust correlation with human judgments when the analysis standards are well-specified.
A number of sensible notes earlier than diving into the size. Your decide mannequin must be not less than as succesful because the fashions you’re evaluating — I sometimes use Claude Sonnet or GPT-4 for judging. Utilizing a weaker mannequin as decide results in unreliable assessments. Additionally, decide prompts should be particular and structured. Imprecise directions like “price the standard” produce inconsistent outcomes. Detailed rubrics with clear scoring standards produce usable evaluations.
I consider three dimensions, utilized selectively primarily based on question complexity.

Factual accuracy is foundational. The decide extracts factual claims from the response and verifies every towards your floor fact. For a monetary question, this may imply checking that the P/E ratio cited is appropriate, that the income determine is correct, that the expansion price matches actuality. The output is an accuracy rating plus a breakdown of which information have been appropriate, incorrect, or lacking.
This is applicable to all queries no matter complexity. Even easy lookups want factual verification — arguably particularly easy lookups, since customers belief easy factual responses and errors undermine that belief.
Reasoning high quality issues for analytical responses. When the agent is evaluating funding choices or assessing danger, you might want to consider not simply whether or not the information are proper however whether or not the logic is sound. Does the conclusion comply with from the premises? Are claims supported by proof? Are assumptions made express? Does the response acknowledge uncertainty appropriately?
I solely run reasoning analysis on medium and excessive complexity queries. Easy factual lookups don’t contain reasoning — there’s nothing to judge. However for something analytical, reasoning high quality is commonly extra necessary than factual accuracy. A response can cite appropriate numbers however draw invalid conclusions from them, and that’s a severe failure.
Completeness applies to complete outputs like analysis stories. When a person asks for an funding evaluation, they anticipate protection of sure parts: monetary efficiency, aggressive place, danger components, development catalysts. Lacking a significant ingredient is a failure even when every thing included is correct and well-reasoned.

I run completeness analysis solely on excessive complexity queries the place complete protection is anticipated. For easier queries, completeness isn’t significant — you don’t anticipate a inventory worth lookup to cowl danger components.
The decide immediate construction issues greater than individuals understand. I all the time embrace the unique question (so the decide understands context), the response being evaluated, the bottom fact or analysis standards, a selected rubric explaining how one can rating every dimension, and a required output format (I take advantage of JSON for parseability). Investing time in immediate engineering in your judges pays off in analysis reliability.
Pillar 3: RAG Analysis
RAG analysis addresses a failure mode that’s invisible should you solely take a look at closing outputs: the system producing plausible-sounding responses that aren’t really grounded in retrieved data.
The RAG pipeline has two levels, and both can fail. Retrieval failure means the system didn’t pull the correct paperwork — both it retrieved irrelevant content material or it missed paperwork that have been related. Era failure means the system retrieved good paperwork however didn’t use them correctly, both ignoring them totally or hallucinating data not current within the context.
Normal response analysis conflates these failures. If the ultimate reply is flawed, you don’t know whether or not retrieval failed or technology failed. RAG-specific analysis separates the issues so you may diagnose and repair the precise downside.
I take advantage of the RAGAS (Retrieval Augmented Era Evaluation) framework for this, which offers standardized metrics which have change into trade normal. The metrics fall into two teams.

Retrieval high quality metrics assess whether or not the correct paperwork have been retrieved. Context precision measures what fraction of retrieved paperwork have been really related — should you retrieved 4 paperwork and solely two have been helpful, that’s 50% precision. You’re pulling noise. Context recall measures what fraction of related paperwork have been retrieved — if three paperwork have been related and also you solely bought two, that’s 67% recall. You’re lacking data.
Era high quality metrics assess whether or not retrieved context was used correctly. Faithfulness is the important one: it measures whether or not claims within the response are supported by the retrieved context. If the response makes 5 claims and 4 are grounded within the retrieved paperwork, that’s 80% faithfulness. The fifth declare is both from the mannequin’s parametric data or hallucinated — both method, it’s not grounded in your retrieval, which is an issue should you’re counting on RAG for accuracy.

I wish to emphasize faithfulness as a result of it’s the metric most instantly tied to hallucination danger in RAG programs. A response can sound authoritative and be fully fabricated. Faithfulness analysis catches this by checking whether or not every declare traces again to retrieved content material.
In a single mission, we discovered that faithfulness scores different dramatically by question sort. For easy factual queries, faithfulness was above 90%. For complicated analytical queries, it dropped to round 60% — the mannequin was doing extra “reasoning” that went past the retrieved context. That’s not essentially flawed, nevertheless it meant customers couldn’t belief that analytical conclusions have been grounded within the supply paperwork. We ended up adjusting the prompts to extra explicitly constrain the mannequin to retrieved data for sure question sorts.
Implementation & Integration
Pipeline Structure
The analysis pipeline has 4 levels: load the dataset, execute the agent on every pattern, run the suitable evaluations, and mixture right into a report.

We begin with the pattern dataset to be evaluated. Every pattern wants the question itself, metadata indicating complexity stage and anticipated agent, floor fact information for accuracy analysis, and for RAG queries, the related paperwork that must be retrieved. Constructing this dataset is tedius work, however the high quality of your analysis relies upon totally on the standard of your floor fact. See instance beneath (Python code):
{
"id": "eval_001",
"question": "Examine Microsoft and Google's P/E ratios",
"class": "comparability",
"complexity": "medium",
"expected_agent": "analysis_agent",
"ground_truth_facts": [
"Microsoft P/E is approximately 35",
"Google P/E is approximately 25"
],
"ground_truth_answer": "Microsoft trades at larger P/E (~35) than Google (~25)...",
"relevant_documents": ["MSFT_10K_2024", "GOOGL_10K_2024"]
}I like to recommend beginning with not less than 50 samples per complexity stage, so 150 minimal for a three-tier system. Extra is best — 400 whole offers you higher statistical confidence within the metrics. Stratify throughout question classes so that you’re not unintentionally over-indexing on one sort.
For observability, I take advantage of Langfuse, which offers hint storage, rating attachment, and dataset run monitoring. Every analysis pattern creates a hint, and every analysis metric attaches as a rating to that hint. Over time, you construct a historical past of analysis runs that you would be able to evaluate throughout mannequin variations, immediate adjustments, or structure modifications. The flexibility to drill into particular failures and see the total hint could be very useful for troubleshooting.
Automated (CI/CD) High quality Gates
Analysis turns into very highly effective when it’s automated and blocking. Scheduled execution of analysis towards a consultant dataset subset is an efficient begin. The run produces metrics. If metrics fall beneath outlined thresholds, the downstream governance mechanism kicks in whether or not high quality evaluations, failed gate checks and so on.
The thresholds should be calibrated to your use case and danger tolerance. For a monetary software the place accuracy is important, I would set factual accuracy at 90% and faithfulness at 85%. For an inner productiveness device with decrease stakes, 80% and 75% is perhaps acceptable. The secret is aligning the thresholds with governance and high quality groups and making use of them in a normal repeatable method.
I additionally suggest scheduled operating of the analysis towards the total dataset, not simply the subset used for PR checks. This catches drift in exterior dependencies — API adjustments, mannequin updates, data base modifications — which may not floor within the smaller PR dataset.
When analysis fails, the pipeline ought to generate a failure report figuring out which metrics missed threshold and which particular samples failed. This offers the mandatory alerts to the groups to resolve the failures
Governance & Compliance
For enterprise deployments, analysis encompasses engineering high quality and organizational accountability. Governance groups want proof that AI programs meet outlined requirements. Compliance groups want audit trails. Threat groups want visibility into failure modes.
Offline analysis offers this proof. Each run creates a file: which mannequin model was evaluated, which dataset was used, what scores have been achieved, whether or not thresholds have been met. These information accumulate into an audit path demonstrating systematic high quality assurance over time.
I like to recommend defining acceptance standards collaboratively with governance stakeholders earlier than the primary analysis run. What factual accuracy threshold is appropriate in your use case? What faithfulness stage is required? Getting alignment upfront prevents confusion and battle on deciphering outcomes.

The factors ought to mirror precise danger. A system offering medical data wants larger accuracy thresholds than one summarizing assembly notes. A system making monetary suggestions wants larger faithfulness thresholds than one drafting advertising and marketing copy. One measurement doesn’t match all, and governance groups perceive this while you body it when it comes to danger.
Lastly, take into consideration reporting for various audiences. Engineering needs detailed breakdowns by metric and question sort. Governance needs abstract cross/fail standing with pattern strains. Executives desire a dashboard exhibiting inexperienced/yellow/purple standing throughout programs. Langfuse and comparable instruments assist these totally different views, however you might want to configure them deliberately.
Conclusion
The hole between spectacular demos and production-ready programs is bridged by means of rigorous, systematic analysis. The framework offered right here offers the construction to construct governance tailor-made to your particular brokers, use instances, and danger tolerance.
Key Takeaways
- Analysis Necessities — Necessities fluctuate relying on the applying use case. A easy lookup wants factual accuracy checks. A posh evaluation wants reasoning analysis. A RAG-enabled response wants faithfulness verification. Making use of the correct evaluations to the correct queries offers you sign with out noise.
- Automation- Handbook analysis doesn’t scale and doesn’t catch regressions. Integrating analysis into CI/CD pipelines, with express thresholds that block deployment, turns high quality assurance from an advert hoc motion right into a repeatable follow.
- Governance — Analysis information present the audit path that compliance wants and the proof that management must approve manufacturing deployment. Constructing this connection early makes AI governance a partnership fairly than an impediment.
The place to Begin
Should you’re not doing systematic offline analysis in the present day, don’t attempt to implement every thing without delay.
- Begin with routing accuracy and factual accuracy — these are the highest-signal metrics and the simplest to implement. Construct a small analysis dataset, possibly 50–100 samples. Run it manually a number of instances to calibrate your expectations.
- Add reasoning analysis for complicated queries and RAG metrics for retrieval-enabled brokers.
- Combine into CI/CD. Outline thresholds together with your governance companions. Construct, Check, Iterate.
The objective is to start out laying the muse and constructing processes to supply proof of high quality throughout outlined standards. That’s the muse for manufacturing readiness, stakeholder confidence, and accountable AI deployment.
This text turned out to be prolonged one, thanks a lot for sticking until the tip. I hope you discovered this convenient and would strive these ideas. All one of the best and completely satisfied constructing 🙂

















{kind=link}