



a preview model of its newest embedding mannequin. This mannequin is notable for one major purpose. It could embed textual content, PDFs, pictures, audio, and video, making it a one-stop store for embedding absolutely anything you’d care to throw at it.
If you happen to’re new to embedding, you may surprise what all of the fuss is about, but it surely seems that embedding is likely one of the cornerstones of retrieval augmented era or RAG, because it’s identified. In flip, RAG is likely one of the most basic functions of recent synthetic intelligence processing.
A fast recap of RAG and Embedding
RAG is a technique of chunking, encoding and storing data that may then be searched utilizing similarity capabilities that match search phrases to the embedded data. The encoding half turns no matter you’re looking right into a collection of numbers known as vectors — that is what embedding does. The vectors (embeddings) are then usually saved in a vector database.
When a person enters a search time period, additionally it is encoded as embeddings, and the ensuing vectors are in contrast with the contents of the vector database, often utilizing a course of known as cosine similarity. The nearer the search time period vectors are to components of the data within the vector retailer, the extra related the search phrases are to these components of the saved information. Giant language fashions can interpret all this and retrieve and show essentially the most related components to the person.
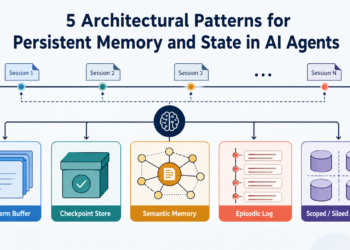
There’s an entire bunch of different stuff that surrounds this, like how the enter information needs to be cut up up or chunked, however the embedding, storing, and retrieval are the primary options of RAG processing. That will help you visualise, right here’s a simplified schematic of a RAG course of.

So, what’s particular about Gemini Embedding?
Okay, so now that we all know how essential embedding is for RAG, why is Google’s new Gemini embedding mannequin such a giant deal? Merely this. Conventional embedding fashions — with a number of exceptions — have been restricted to textual content, PDFs, and different doc varieties, and perhaps pictures at a push.
What Gemini now presents is true multi-modal enter for embeddings. Meaning textual content, PDF’s and docs, pictures, audio and video. Being a preview embedding mannequin, there are particular dimension limitations on the inputs proper now, however hopefully you possibly can see the path of journey and the way probably helpful this might be.
Enter limitations
I discussed that there are limitations on what we will enter to the brand new Gemini embedding mannequin. They’re:
- Textual content: As much as 8192 enter tokens, which is about 6000 phrases
- Pictures: As much as 6 pictures per request, supporting PNG and JPEG codecs
- Movies: A most of two minutes of video in MP4 and MOV codecs
- Audio: A most length of 80 seconds, helps MP3, WAV.
- Paperwork: As much as 6 pages lengthy
Okay, time to see the brand new embedding mannequin in apply with some Python coding examples.
Establishing a improvement setting
To start, let’s arrange a regular improvement setting to maintain our tasks separate. I’ll be utilizing the UV device for this, however be happy to make use of whichever strategies you’re used to.
$ uv init embed-test --python 3.13
$ cd embed-test
$ uv venv
$ supply embed-test/bin/activate
$ uv add google-genai jupyter numpy scikit-learn audioop-lts
# To run the pocket book, kind this in
$ uv run jupyter pocket bookYou’ll additionally want a Gemini API key, which you may get from Google’s AI Studio residence web page.
Search for a Get API Key hyperlink close to the underside left of the display after you’ve logged in. Be aware of it as you’ll want it later.
Please word, apart from being a person of their merchandise, I’ve no affiliation or affiliation with Google or any of its subsidiaries.
Setup Code
I received’t speak a lot about embedding textual content or PDF paperwork, as these are comparatively simple and are lined extensively elsewhere. As a substitute, we’ll have a look at embedding pictures and audio, that are much less widespread.
That is the setup code, which is widespread to all our examples.
import os
import numpy as np
from pydub import AudioSegment
from google import genai
from google.genai import varieties
from sklearn.metrics.pairwise import cosine_similarity
from IPython.show import show, Picture as IPImage, Audio as IPAudio, Markdown
shopper = genai.Consumer(api_key='YOUR_API_KEY')
MODEL_ID = "gemini-embedding-2-preview"Instance 1 — Embedding pictures
For this instance, we’ll embed 3 pictures: one among a ginger cat, one among a Labrador, and one among a yellow dolphin. We’ll then arrange a collection of questions or phrases, every yet one more particular to or associated to one of many pictures, and see if the mannequin can pick essentially the most applicable picture for every query. It does this by computing a similarity rating between the query and every picture. The upper this rating, the extra pertinent the query to the picture.
Listed here are the photographs I’m utilizing.

So, I’ve two questions and two phrases.
- Which animal is yellow
- Which is probably known as Rover
- There’s one thing fishy happening right here
- A purrrfect picture
# Some helper perform
#
# embed textual content
def embed_text(textual content: str) -> np.ndarray:
"""Encode a textual content string into an embedding vector.
Merely go the string on to embed_content.
"""
outcome = shopper.fashions.embed_content(
mannequin=MODEL_ID,
contents=[text],
)
return np.array(outcome.embeddings[0].values)
# Embed a picture
def embed_image(image_path: str) -> np.ndarray:
# Decide MIME kind from extension
ext = image_path.decrease().rsplit('.', 1)[-1]
mime_map = {'png': 'picture/png', 'jpg': 'picture/jpeg', 'jpeg': 'picture/jpeg'}
mime_type = mime_map.get(ext, 'picture/png')
with open(image_path, 'rb') as f:
image_bytes = f.learn()
outcome = shopper.fashions.embed_content(
mannequin=MODEL_ID,
contents=[
types.Part.from_bytes(data=image_bytes, mime_type=mime_type),
],
)
return np.array(outcome.embeddings[0].values)
# --- Outline picture information ---
image_files = ["dog.png", "cat.png", "dolphin.png"]
image_labels = ["dog","cat","dolphin"]
# Our questions
text_descriptions = [
"Which animal is yellow",
"Which is most likely called Rover",
"There's something fishy going on here",
"A purrrfect image"
]
# --- Compute embeddings ---
print("Embedding texts...")
text_embeddings = np.array([embed_text(t) for t in text_descriptions])
print("Embedding pictures...")
image_embeddings = np.array([embed_image(f) for f in image_files])
# Use cosine similarity for matches
text_image_sim = cosine_similarity(text_embeddings, image_embeddings)
# Print greatest matches for every textual content
print("nBest picture match for every textual content:")
for i, textual content in enumerate(text_descriptions):
# np.argmax seems to be throughout the row (i) to search out the very best rating among the many columns
best_idx = np.argmax(text_image_sim[i, :])
best_image = image_labels[best_idx]
best_score = text_image_sim[i, best_idx]
print(f" "{textual content}" => {best_image} (rating: {best_score:.3f})")Right here’s the output.
Embedding texts...
Embedding pictures...
Finest picture match for every textual content:
"Which animal is yellow" => dolphin (rating: 0.399)
"Which is probably known as Rover" => canine (rating: 0.357)
"There's one thing fishy happening right here" => dolphin (rating: 0.302)
"A purrrfect picture" => cat (rating: 0.368)Not too shabby. The mannequin got here up with the identical solutions I’d have given. How about you?
Instance 2 — Embedding audio
For the audio, I used a person’s voice describing a fishing journey by which he sees a shiny yellow dolphin. Click on beneath to listen to the total audio. It’s about 37 seconds lengthy.
If you happen to don’t wish to hear, right here is the total transcript.
Hello, my identify is Glen, and I wish to let you know about an interesting sight I witnessed final Tuesday afternoon whereas out ocean fishing with some pals. It was a heat day with a yellow solar within the sky. We had been fishing for Tuna and had no luck catching something. Boy, we will need to have spent the very best a part of 5 hours on the market. So, we had been fairly glum as we headed again to dry land. However then, abruptly, and I swear that is no lie, we noticed a college of dolphins. Not solely that, however one among them was shiny yellow in color. We by no means noticed something prefer it in our lives, however I can let you know all ideas of a foul fishing day went out the window. It was mesmerising.
Now, let’s see if we will slim down the place the speaker talks about seeing a yellow dolphin.
Usually, when coping with embeddings, we’re solely generally properties, concepts, and ideas contained within the supply data. If we wish to slim down particular properties, reminiscent of the place in an audio file a specific phrase happens or the place in a video a specific motion or occasion happens, this can be a barely extra complicated process. To do this in our instance, we first need to chunk the audio into smaller items earlier than embedding every chunk. We then carry out a similarity search on every embedded chunk earlier than producing our closing reply.
# --- HELPER FUNCTIONS ---
def embed_text(textual content: str) -> np.ndarray:
outcome = shopper.fashions.embed_content(mannequin=MODEL_ID, contents=[text])
return np.array(outcome.embeddings[0].values)
def embed_audio(audio_path: str) -> np.ndarray:
ext = audio_path.decrease().rsplit('.', 1)[-1]
mime_map = {'wav': 'audio/wav', 'mp3': 'audio/mp3'}
mime_type = mime_map.get(ext, 'audio/wav')
with open(audio_path, 'rb') as f:
audio_bytes = f.learn()
outcome = shopper.fashions.embed_content(
mannequin=MODEL_ID,
contents=[types.Part.from_bytes(data=audio_bytes, mime_type=mime_type)],
)
return np.array(outcome.embeddings[0].values)
# --- MAIN SEARCH SCRIPT ---
def search_audio_with_embeddings(audio_file_path: str, search_phrase: str, chunk_seconds: int = 5):
print(f"Loading {audio_file_path}...")
audio = AudioSegment.from_file(audio_file_path)
# pydub works in milliseconds, so 5 seconds = 5000 ms
chunk_length_ms = chunk_seconds * 1000
audio_embeddings = []
temp_files = []
print(f"Slicing audio into {chunk_seconds}-second items...")
# 2. Chop the audio into items
# We use a loop to leap ahead by chunk_length_ms every time
for i, start_ms in enumerate(vary(0, len(audio), chunk_length_ms)):
# Extract the slice
chunk = audio[start_ms:start_ms + chunk_length_ms]
# Put it aside quickly to your folder so the Gemini API can learn it
chunk_name = f"temp_chunk_{i}.wav"
chunk.export(chunk_name, format="wav")
temp_files.append(chunk_name)
# 3. Embed this particular chunk
print(f" Embedding chunk {i + 1}...")
emb = embed_audio(chunk_name)
audio_embeddings.append(emb)
audio_embeddings = np.array(audio_embeddings)
# 4. Embed the search textual content
print(f"nEmbedding your search: '{search_phrase}'...")
text_emb = np.array([embed_text(search_phrase)])
# 5. Evaluate the textual content in opposition to all of the audio chunks
print("Calculating similarities...")
sim_scores = cosine_similarity(text_emb, audio_embeddings)[0]
# Discover the chunk with the very best rating
best_chunk_idx = np.argmax(sim_scores)
best_score = sim_scores[best_chunk_idx]
# Calculate the timestamp
start_time = best_chunk_idx * chunk_seconds
end_time = start_time + chunk_seconds
print("n--- Outcomes ---")
print(f"The idea '{search_phrase}' most carefully matches the audio between {start_time}s and {end_time}s!")
print(f"Confidence rating: {best_score:.3f}")
# --- RUN IT ---
# Change with no matter phrase you're on the lookout for!
search_audio_with_embeddings("fishing2.mp3", "yellow dolphin", chunk_seconds=5)Right here is the output.
Loading fishing2.mp3...
Slicing audio into 5-second items...
Embedding chunk 1...
Embedding chunk 2...
Embedding chunk 3...
Embedding chunk 4...
Embedding chunk 5...
Embedding chunk 6...
Embedding chunk 7...
Embedding chunk 8...
Embedding your search: 'yellow dolphin'...
Calculating similarities...
--- Outcomes ---
The idea 'yellow dolphin' most carefully matches the audio between 25s and 30s!
Confidence rating: 0.643That’s fairly correct. Listening to the audio once more, the phrase “dolphin” is talked about on the 25-second mark and “shiny yellow” is talked about on the 29-second mark. Earlier within the audio, I intentionally launched the phrase “yellow solar” to see whether or not the mannequin could be confused, but it surely dealt with the distraction effectively.
Abstract
This text introduces Gemini Embeddings 2 Preview as Google’s new all-in-one embedding mannequin for textual content, PDFs, pictures, audio, and video. It explains why that issues for RAG techniques, the place embeddings assist flip content material and search queries into vectors that may be in contrast for similarity.
I then walked by means of two Python examples displaying the right way to generate embeddings for pictures and audio with the Google GenAI SDK, use similarity scoring to match textual content queries in opposition to pictures, and chunk audio into smaller segments to establish the a part of a spoken recording that’s semantically closest to a given search phrase.
The chance to carry out semantic searches past simply textual content and different paperwork is an actual boon. Google’s new embedding mannequin guarantees to open up an entire new raft of potentialities for multimodal search, retrieval, and suggestion techniques, making it a lot simpler to work with pictures, audio, video, and paperwork in a single pipeline. Because the tooling matures, it might turn out to be a really sensible basis for richer RAG functions that perceive excess of textual content alone.
You could find the unique weblog submit saying Gemini Embeddings 2 utilizing the hyperlink beneath.
https://weblog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2












{kind=link}