


: Why this comparability issues
RAG started with a simple aim: floor mannequin outputs in exterior proof relatively than relying solely on mannequin weights. Most groups applied this as a pipeline: retrieve as soon as, then generate a solution with citations.
During the last yr, extra groups have began shifting from that “one-pass” pipeline in the direction of agent-like loops that may retry retrieval and name instruments when the primary go is weak. Gartner even forecasts that 33% of enterprise software program purposes will embrace agentic AI by 2028, an indication that “agentic” patterns have gotten mainstream relatively than area of interest.
Agentic RAG adjustments the system construction. Retrieval turns into a management loop: retrieve, cause, determine, then retrieve once more or cease. This mirrors the core sample of “cause and act” approaches, reminiscent of ReAct, during which the system alternates between reasoning and motion to assemble new proof.
Nonetheless, brokers don’t improve RAG with out tradeoffs. Introducing loops and power calls will increase adaptability however reduces predictability. Correctness, latency, observability, and failure modes all change when debugging a course of as a substitute of a single retrieval step.
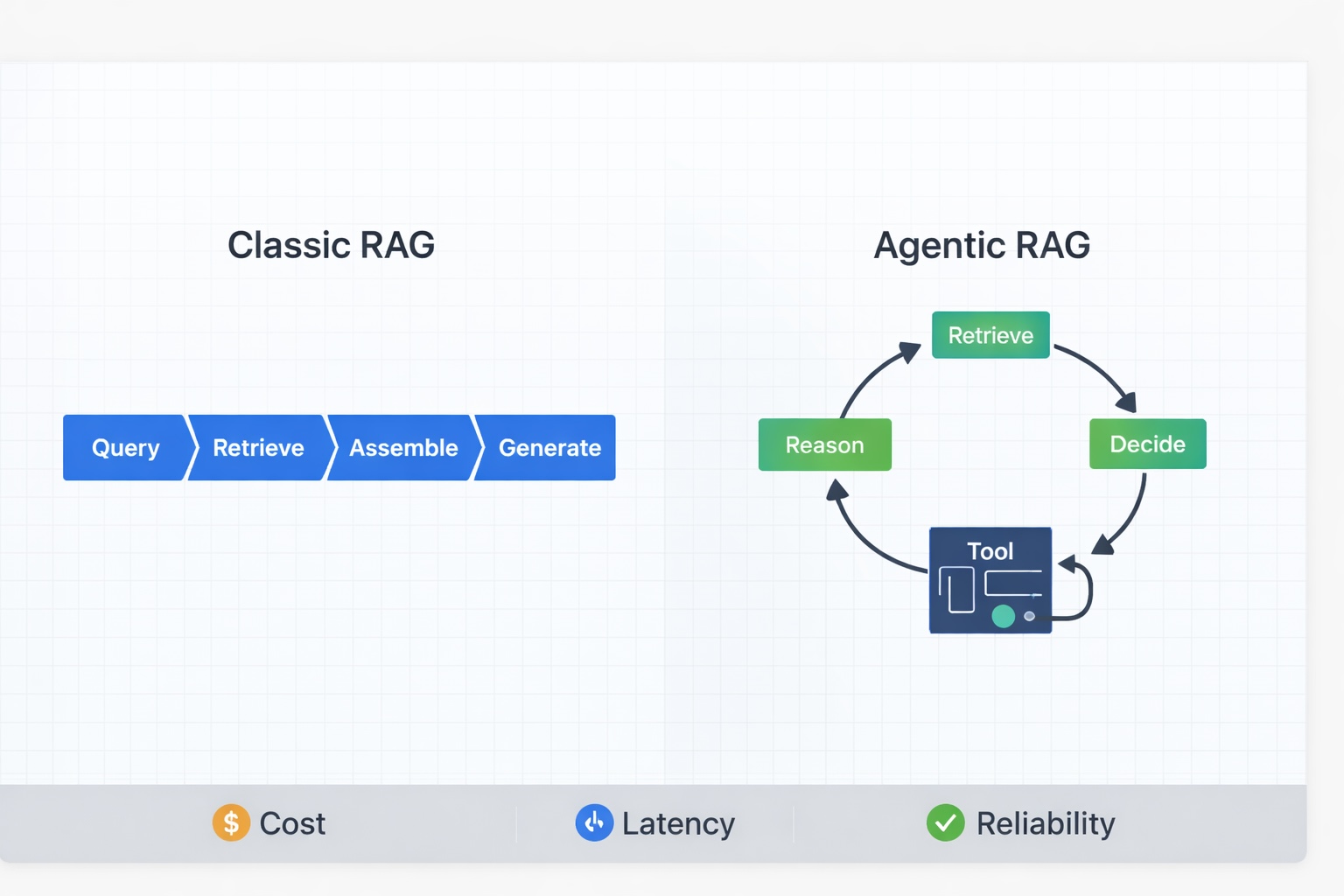
Traditional RAG: the pipeline psychological mannequin
Traditional RAG is simple to grasp as a result of it follows a linear course of. A person question is acquired, the system retrieves a hard and fast set of passages, and the mannequin generates a solution based mostly on that single retrieval. If points come up, debugging normally focuses on retrieval relevance or context meeting.
At a excessive stage, the pipeline seems like this:
- Question: take the person query (and any system directions) as enter
- Retrieve: fetch the top-k related chunks (normally through vector search, typically hybrid)
- Assemble context: Choose and prepare the very best passages right into a immediate context (usually with reranking)
- Generate: Produce a solution, ideally with citations again to the retrieved passages

What basic RAG is nice at
Traditional RAG is best when predictable value and latency are priorities. For easy “doc lookup” questions reminiscent of “What does this configuration flag do?”, “The place is the API endpoint for X?”, or “What are the bounds of plan Y?”, a single retrieval go is usually ample. Solutions are delivered shortly, and debugging is direct: if outputs are incorrect, first verify retrieval relevance and chunking, then overview immediate habits.
Instance (basic RAG in apply):
A person asks: “What does the MAX_UPLOAD_SIZE config flag do?”
The retriever pulls the configuration reference web page the place the flag is outlined.
The mannequin solutions in a single go, “It units the utmost add dimension allowed per request”, and cites the precise part.
There aren’t any loops or instrument calls, so value and latency stay secure.
The place basic RAG hits the wall
Traditional RAG is a “one-shot” method. If retrieval fails, the mannequin lacks a built-in restoration mechanism.
That exhibits up in a couple of frequent methods:
- Multi-hop questions: the reply wants proof unfold throughout a number of sources
- Underspecified queries: the person’s wording will not be the very best retrieval question
- Brittle chunking: related context is cut up throughout chunks or obscured by jargon
- Ambiguity: the system could have to ask clarifying questions, reformulate, or discover additional earlier than offering an correct reply.
Why this issues:
When basic RAG fails, it usually does so quietly. The system nonetheless gives a solution, however it could be a assured synthesis based mostly on weak proof.
Agentic RAG: from retrieval to a management loop
Agentic RAG retains the retriever and generator elements however adjustments the management construction. As an alternative of counting on a single retrieval go, retrieval is wrapped in a loop, permitting the system to overview its proof, establish gaps, and try retrieval once more if wanted. This loop provides the system an “agentic” high quality: it not solely generates solutions from proof but additionally actively chooses the best way to collect stronger proof till a cease situation is met. A useful analogy is incident debugging: basic RAG is like working one log question and writing the conclusion from no matter comes again, whereas agentic RAG is a debug loop. You question, examine the proof, discover what’s lacking, refine the question or verify a second system, and repeat till you’re assured otherwise you hit a time/value price range and escalate.
A minimal loop is:
- Retrieve: pull candidate proof (docs, search outcomes, or instrument outputs)
- Cause: synthesize what you could have and establish what’s lacking or unsure
- Resolve: cease and reply, refine the question, swap sources/instruments, or escalate
For a analysis reference, ReAct gives a helpful psychological mannequin: reasoning steps and actions are interleaved, enabling the system to assemble extra substantial proof earlier than finalizing a solution.
What brokers add
Planning (decomposition)
The agent can decompose a query into smaller evidence-based goals.
Instance: “Why is SSO setup failing for a subset of customers?”
- What error codes are we seeing?
- Which IdP configuration is used
- Is that this a docs query, a log query, or a configuration query
Traditional RAG treats the whole query as a single question. An agent can explicitly decide what info is required first.
Instrument use (past retrieval)
In agentic RAG, retrieval is one in every of a number of out there instruments. The agent can also use:
- A second index
- A database question
- A search API
- A config checker
- A light-weight verifier
That is essential as a result of related solutions usually exist outdoors the documentation index. The loop permits the system to retrieve proof from its precise supply.
Iterative refinement (deliberate retries)
This represents essentially the most vital development. As an alternative of making an attempt to generate a greater reply from weak retrieval, the agent can intentionally requery.
Self-RAG is an effective instance of this analysis path: it’s designed to retrieve on demand the critique of retrieved passages and to generate them, relatively than at all times utilizing a hard and fast top-k retrieval step.
That is the core functionality shift: the system can adapt its retrieval technique based mostly on info realized throughout execution.

Tradeoffs: Advantages and Drawbacks of Loops
Agentic RAG is useful as a result of it may possibly restore retrieval relatively than counting on guesses. When the preliminary retrieval is weak, the system can rewrite the question, swap sources, or collect extra proof earlier than answering. This method is best fitted to ambiguous questions, multi-hop reasoning, and conditions the place related info is dispersed.
Nonetheless, introducing a loop adjustments manufacturing expectations. What will we imply by a “loop”? On this article, a loop is one full iteration of the agent’s management cycle: Retrieve → Cause → Resolve, repeated till a cease situation is met (excessive confidence + citations, max steps, price range cap, or escalation). That definition issues as a result of as soon as retrieval is iterative, value and latency develop into distributions: some runs cease shortly, whereas others take further iterations, retries, or instrument calls. In apply, you cease optimizing for the “typical” run and begin managing tail habits (p95 latency, value spikes, and worst-case instrument cascades).
Right here’s a tiny instance of what that Retrieve → Cause → Resolve loop can seem like in code:
# Retrieve → Cause → Resolve Loop (agentic RAG)
proof = []
for step in vary(MAX_STEPS):
docs = retriever.search(question=build_query(user_question, proof))
gaps = find_gaps(user_question, docs, proof)
if gaps.happy and has_citations(docs):
return generate_answer(user_question, docs, proof)
motion = decide_next_action(gaps, step)
if motion.kind == "refine_query":
proof.append(("trace", motion.trace))
elif motion.kind == "call_tool":
proof.append(("instrument", instruments[action.name](motion.args)))
else:
break # secure cease if looping is not serving to
return safe_stop_response(user_question, proof)The place loops assist
Agentic RAG is most beneficial when “retrieve as soon as → reply” isn’t sufficient. In apply, loops assist in three typical instances:
- The query is underspecified and wishes question refinement
- The proof is unfold throughout a number of paperwork or sources
- The primary retrieval returns partial or conflicting info, and the system must confirm earlier than committing
The place loops harm
The tradeoff is operational complexity. With loops, you introduce extra shifting elements (planner, retriever, optionally available instruments, cease circumstances), which will increase variance and makes runs more durable to breed. You additionally broaden the floor space for failures: a run would possibly look “high quality” on the finish, however nonetheless burn tokens by means of repeated retrieval, retries, or instrument cascades.
That is additionally why “enterprise RAG” tends to get difficult in apply: safety constraints, messy inner information, and integration overhead make naive retrieval brittle.
Failure modes you’ll see early in manufacturing
As soon as you progress from a pipeline to a management loop, a couple of issues present up repeatedly:
- Retrieval thrash: the agent retains retrieving with out bettering proof high quality.
- Instrument-call cascades: one instrument name triggers one other, compounding latency and price.
- Context bloat: the immediate grows till high quality drops or the mannequin begins lacking key particulars.
- Cease-condition bugs: the loop doesn’t cease when it ought to (or stops too early).
- Assured-wrong solutions: the system converges on noisy proof and solutions with excessive confidence.
A key perspective is that basic RAG primarily fails resulting from retrieval high quality or prompting. Agentic RAG can encounter these points as effectively, but additionally introduces control-related failures, reminiscent of poor decision-making, insufficient cease guidelines, and uncontrolled loops. As autonomy will increase, observability turns into much more crucial.
Fast comparability: Traditional vs Agentic RAG
| Dimension | Traditional RAG | Agentic RAG |
|---|---|---|
| Price predictability | Excessive | Decrease (is dependent upon loop depth) |
| Latency predictability | Excessive | Decrease (p95 grows with iterations) |
| Multi-hop queries | Typically weak | Stronger |
| Debugging floor | Smaller | Bigger |
| Failure modes | Principally retrieval + immediate | Provides loop management failures |
Choice Framework: When to remain basic vs go agentic
A sensible method to selecting between basic and agentic RAG is to guage your use case alongside two axes: question complexity (the extent of multi-step reasoning or proof gathering required) and error tolerance (the chance related to incorrect solutions for customers or the enterprise). Traditional RAG is a powerful default resulting from its predictability. Agentic RAG is preferable when duties continuously require retries, decomposition, or cross-source verification.
Choice matrix: complexity × error tolerance
Right here, excessive error tolerance means a fallacious reply is appropriate (low stakes), whereas low error tolerance means a fallacious reply is dear (excessive stakes).
| Excessive error tolerance | Low error tolerance | |
|---|---|---|
| Low Complexity | Traditional RAG for quick solutions and predictable latency/value. | Traditional RAG with citations, cautious retrieval, escalation |
| Excessive Complexity | Traditional RAG + second go on failure indicators (solely loop when wanted). | Agentic RAG with strict cease circumstances, budgets, and debugging |
Sensible gating guidelines (what to route the place)
Traditional RAG is normally the higher match when the duty is usually lookup or extraction:
- FAQs and documentation Q&A
- Single-document solutions (insurance policies, specs, limits)
- Quick help the place latency predictability issues greater than excellent protection
Agentic RAG is normally well worth the added complexity when the duty wants multi-step proof gathering:
- Decomposing a query into sub-questions
- Iterative retrieval (rewrite, broaden/slender, swap sources)
- Verification and cross-checking throughout sources/instruments
- Workflows the place “strive once more” is required to achieve a assured, cited reply.
A easy rule: don’t pay for loops until your process routinely fails in a single go.
Rollout steerage: add a second go earlier than going “full agent.”
You don’t want to decide on between a everlasting pipeline and full agentic implementation. A sensible compromise is to make use of basic RAG by default and set off a second-pass loop solely when failure indicators are detected, reminiscent of lacking citations, low retrieval confidence, contradictory proof, or person follow-ups indicating the preliminary reply was inadequate. This method retains most queries environment friendly whereas offering a restoration path for extra complicated instances.

Core Takeaway
Agentic RAG will not be merely an improved model of RAG; it’s RAG with an added management loop. This loop can improve correctness for complicated, ambiguous, or multi-hop queries by permitting the system to refine retrieval and confirm proof earlier than answering. The tradeoff is operational: elevated complexity, increased tail latency and price spikes, and extra failure modes to debug. Clear budgets, cease guidelines, and traceability are important should you undertake this method.
Conclusion
In case your product primarily includes doc lookup, extraction, or fast help, basic RAG is usually the very best default. It’s easier, more cost effective, and simpler to handle. Contemplate agentic RAG solely when there may be clear proof that single-pass retrieval fails for a good portion of queries, or when the price of incorrect solutions justifies the extra verification and iterative proof gathering.
A sensible compromise is to start with basic RAG and introduce a managed second go solely when failure indicators come up, reminiscent of lacking citations, low retrieval confidence, contradictory proof, or repeated person follow-ups. If second-pass utilization turns into frequent, implementing an agent loop with outlined budgets and cease circumstances could also be useful.
For additional exploration of improved retrieval, analysis, and tool-calling patterns, the next references are beneficial.















{kind=link}