


. What a present to society that is. If not for google traits, how would we’ve ever identified that extra Disney films launched within the 2000s led to fewer divorces within the UK. Or that ingesting Coca Cola is an unknown treatment for cat scratches.
Wait, am I getting confused by correlation vs causation once more?
For those who want watching over studying, you are able to do so proper right here:
Google Developments is among the most generally used instruments for analysing human behaviour at scale. Journalists use it. Knowledge scientists use it. Total papers are constructed on it. However there’s a basic property of Google Developments information that makes it very straightforward to misuse, particularly if you’re working with time sequence or making an attempt to construct fashions, and most of the people by no means realise they’re doing it.
All charts and screenshots are created by the creator until acknowledged in any other case.
The Downside with Google Developments Knowledge
Google doesn’t truly publish figures on their search quantity. That info prints {dollars} for them and there’s no approach they might open that up for different folks to monetise. However what they do give us is a approach to see a time sequence, to grasp modifications in folks’s searches of a specific time period and the way in which they do that’s by giving us a normalised set of information.
This doesn’t sound like an issue till you try to do some machine studying with it. As a result of relating to getting a machine to study something, we have to give it a variety of information.
My preliminary concept was to seize a window of 5 years however I instantly have an issue: the bigger the time window, the much less granular the info. I couldn’t get every day information for 5 years and whereas I then thought “simply take the utmost time interval you will get every day information for and transfer that window”, that was an issue too. As a result of it was right here that I found the true terror of normalisation:
No matter time interval I exploit or no matter single search time period I exploit, the info level with the very best variety of searches is instantly set to 100. Which means the that means of 100 modifications with each window I exploit.
This whole put up exists because of this.
Google Developments Fundamentals
Now, I don’t know for those who’ve used Google Developments earlier than however for those who haven’t, I’m going to speak you thru it so we will get to the meat of the issue.
So I’m going to look the phrase “motivation” and it’s going to default to the UK as a result of that’s the place I’m from and to the previous day and we’ve a beautiful graph which exhibits how usually folks have been looking out the phrase “motivation” within the final 24 hours.

I really like this as a result of you may see actually clearly that persons are largely trying to find motivation in the course of the working day, nobody is looking out it when a lot of the nation is asleep and there’s positively a few children needing some encouragement for his or her homework. I don’t have an evidence for the late evening searches however I might type of guess these are folks not prepared to return to work tomorrow.
Now that is pretty however whereas eight minute increments over 24 hours does give us a pleasant 180 information factors to make use of, most of them are literally zero and I don’t know if the previous 24 hours have been extremely demotivating in comparison with the remainder of the yr or if in the present day represents the yr’s highest GDP contribution, so I’m going to extend the window just a little bit.
The second we go to per week, the very first thing you discover is that the info is quite a bit much less granular. We now have per week of information however now it’s solely hourly and I nonetheless have the identical core downside of not realizing how consultant this week is.
I can hold zooming out. 30 days, 90 days. At every level we lose granularity and don’t have wherever close to as many information factors as we did for twenty-four hours. If I’m going to construct an precise mannequin, this isn’t going to chop it. I have to go large.
And once I choose 5 years is the place we’re going to come across the issue that motivated this complete video (excuse the pun, that was unintentional): I can’t get every day information. And likewise, why is in the present day not at 100 anymore?

Herein lies the actual downside with google traits information
As I discussed earlier, google traits information is normalised. Because of this no matter time interval I exploit or no matter single search time period I exploit, the info level with the very best variety of searches is instantly set to 100. All the opposite factors are scaled down accordingly. If the first of April had half the searches of the utmost, then the first of April goes to have a google traits rating of fifty.
So let’s have a look at an instance right here simply as an example the purpose. Let’s take the months of Might and June 2025, each 30 or 31 days so we’ve every day information right here, we truly lose it past 90 days. If I have a look at Might you may see we’re scaled so we hit 100 on the thirteenth and in June we hit it on the tenth. So does that imply motivation was searched simply as usually on the tenth of June because it was on the thirteenth of Might?


If I zoom out now in order that I’ve Might and June on the identical graph, you may instantly see that that’s not the case. When each months are included we see that the searches for motivation had a google traits rating of 83 on the tenth of June, that means as a proportion of searches within the UK, it was 81% of the proportion of searches on the thirteenth Might. If we didn’t zoom out, we wouldn’t have identified that.

Now all isn’t misplaced, we did get a great bit of knowledge from this experiment as a result of we all know that we will see the relative distinction between two information factors in the event that they’re each included in the identical graph, so if we did load Might and June individually, realizing tenth of June is 81% of thirteenth of Might means we will scale June down accordingly and the info can be comparable.
In order that’s what I made a decision I’d do. I’d fetch my google traits information with a sooner or later overlap on every window, so 1st of Jan to thirty first of March, then thirty first of March to thirty first of July. Then I may use March thirty first in each information units to scale the second set to be similar to the primary.
However whereas that is near one thing we will use, there’s yet another downside I have to make you conscious of.
Google Developments: One other Layer of Randomness
So relating to google traits information, google isn’t truly monitoring each single search. That will be a computational nightmare. As a substitute, Google makes use of sampling strategies so to construct a illustration of search volumes.
Because of this whereas the pattern is probably going very well-built, it’s Google in spite of everything, every day could have some pure random variation. If by probability March thirty first was a day the place Google’s pattern occurred to be unusually excessive or low in comparison with the actual world, our overlap technique would introduce an error into our complete information set.
On prime of this, we even have to contemplate rounding. Google traits rounds every part to the closest complete quantity. There’s no 50.5, it’s 50 or it’s 51. Now this looks as if a small element however it will possibly truly turn out to be a giant downside. Let me present you why.
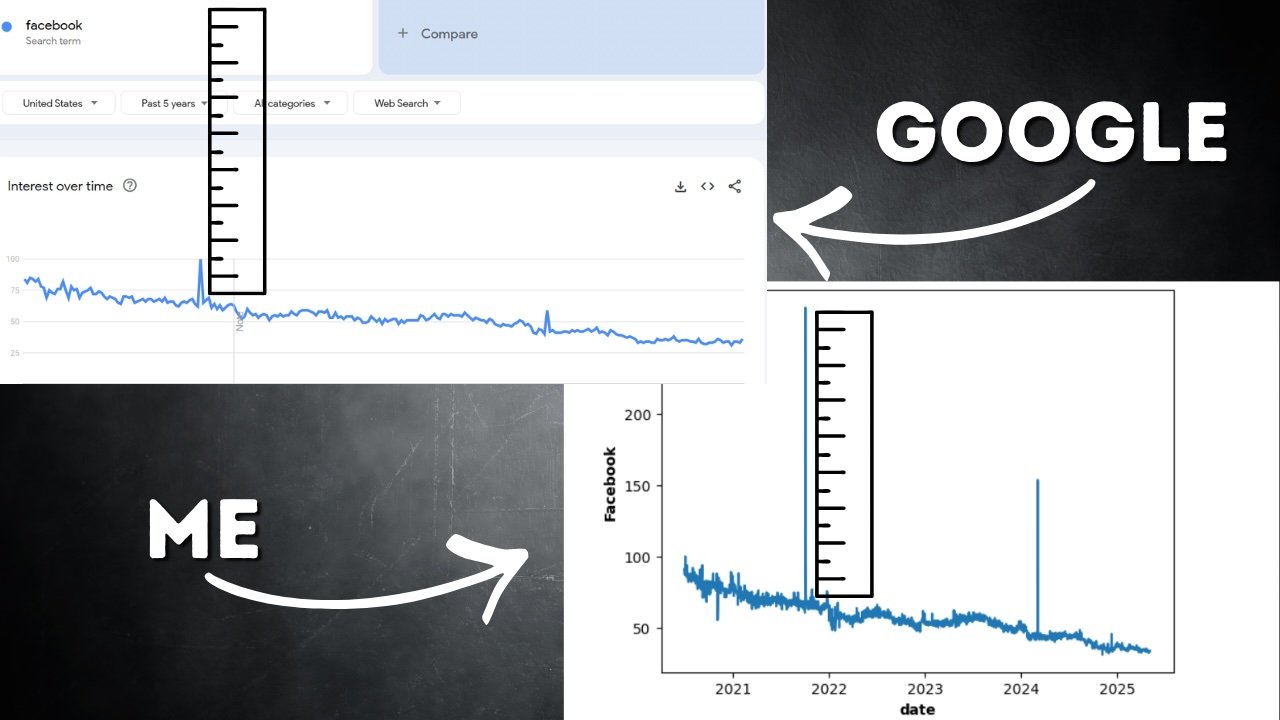
On the 4th of October 2021, there was a large spike in searches for Fb. This large spike will get scaled to 100 and in consequence every part else in that interval is far nearer to zero. Once you’re rounding to the closest complete quantity that tiny error of 0.5 all of a sudden turns into a big proportional error when your quantity is just one or 2. Because of this our resolution needs to be sturdy sufficient to deal with noise, not simply scaling.
So how will we clear up this? Effectively we all know that on common the samples can be consultant, so let’s simply take a much bigger pattern. If we use a bigger window to get our overlap, the random variation and rounding errors have much less of an affect.
So right here’s the ultimate plan. I do know I can get every day information for as much as 90 days. I’m going to load a rolling window of 90-day intervals however I’ll be sure that every window overlaps by a full month with the subsequent. That approach, our overlap isn’t only one doubtlessly noisy day however a steady month-long anchor that we will use to scale our information extra precisely.
So it seems like we’ve bought a plan. I’ve bought some considerations, primarily that by having plenty of batches there’s going to be compounding errors and it may end in large numbers completely blowing up. However as a way to see how this shakes out with actual information we’ve to go and do it. So right here’s one I made earlier.
Writing Code to Determine Out Google Developments
After writing up every part we’ve mentioned in code kind and, after having some enjoyable getting briefly banned from google traits for pulling an excessive amount of information, I’ve put collectively some graphs. My fast response once I noticed this was: “Oh no, it blew up”.

The graph under exhibits my chained-together 5 years of search volumes for Fb. You’ll see a reasonably regular downward pattern however two spikes stand out. The primary of those was the huge spike on 4th October 2021 that we talked about earlier.

My first thought was to confirm the spikes. I, unironically, googled it and came upon about widespread Meta outages that day. I pulled information for Instagram and Whatsapp over the identical interval and noticed related spikes. So I knew the spike was actual however I nonetheless had a query: Was it too large?
Once I put my time sequence side-by-side with Google Developments’ personal graph, my coronary heart sank. My spikes have been big as compared. I began fascinated by the best way to deal with this. Ought to I cap the utmost spike worth? That felt arbitrary and would lose details about the relative sizes of spikes. Ought to I apply an arbitrary scaling issue? Once more, it felt like a guess.

That was till I had a bolt of inspiration. Keep in mind, Google Developments is giving us weekly information for this era, that’s the entire cause we’re doing this. What if I averaged my information for that week to see the way it in comparison with Google’s weekly worth?
That is the place I breathed an enormous sigh of aid. That week was the largest spike on Google Developments so set to 100. Once I averaged my information for a similar week, I bought 102.8. Extremely near Google Developments. We additionally end in about the identical place. This implies the compounding errors from my scaling technique haven’t blown up my information. I’ve one thing that appears and behaves similar to the Google Developments information!
So now we’ve a strong methodology for making a clear, comparable every day time sequence for any search time period. Which is nice. However what if we truly wish to do one thing helpful with it, like evaluating search phrases around the globe for instance?
As a result of whereas Google Developments means that you can examine a number of search phrases it doesn’t permit direct comparability of a number of international locations. So I can seize a dataset of motivation for every nation utilizing the tactic we’ve mentioned in the present day, however how do I make them comparable? Fb is a part of the answer.
However this resolution is one for a later weblog put up, one through which we’re going to construct a “basket of products” to match international locations and see precisely how Fb matches into all of this.
So in the present day we began with the query of whether or not we will mannequin nationwide motivation and in making an attempt to take action instantly hit a wall. As a result of Google Developments every day information is deceptive. Not attributable to an error, however by its very design. We’ve discovered a approach to sort out that now, however within the lifetime of a knowledge scientist, there are all the time extra issues lurking across the nook.
















{kind=link}