


to Constructing an Overengineered Retrieval System. That one was about constructing your complete system. This one is about doing the evals for it.
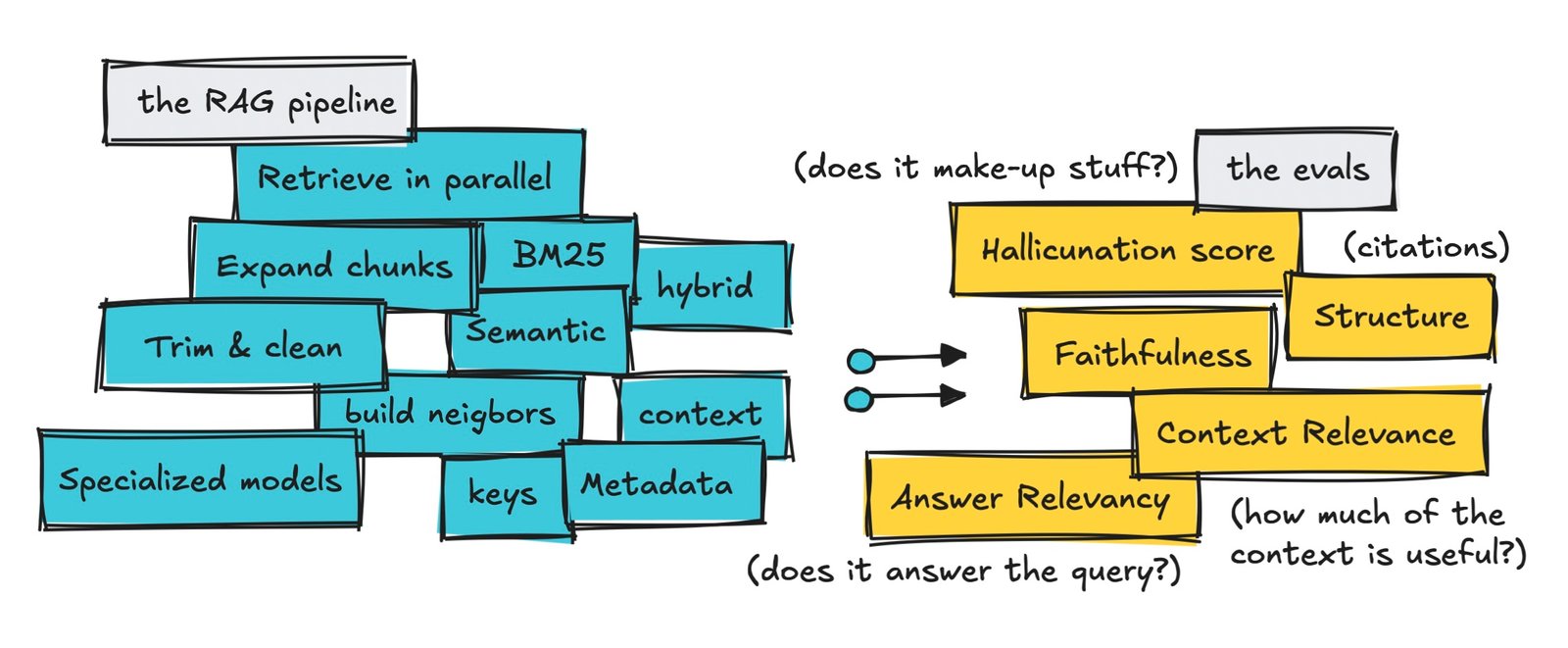
Within the earlier article, I went by totally different elements of a RAG pipeline: chunking the info correctly, question optimization, retrieval (semantic, BM25, or hybrid search), re-ranking, increasing chunks to neighbors, constructing the context, after which era with an LLM.
One of many questions I received was: does increasing chunks to neighbors really enhance solutions, or does it simply add noise and make it more durable for the mannequin to remain grounded?
In order that’s what we’ll check right here. We’ll run some fundamental evaluations and take a look at metrics like faithfulness, reply relevancy, context relevance, and hallucination price, and evaluate outcomes throughout totally different fashions and datasets.
I’ve collected a lot of the outcomes right here and right here already, however we’ll undergo them too.
As a notice, I’m planning to check this type of “superior” pipeline to a extra naive baseline later. However this text is especially about evaluating the pipeline as it’s.

I at all times undergo some intro sections earlier than I dig in, however in case you’re new-new, I’d first learn up on how you can construct a fundamental RAG system, how embeddings work, and an precise intro to evals/metrics. Then you too can learn how you can construct the over-engineered pipeline I launched above, or a minimum of skim it.
If none of that is new, then skip to the outcomes half.
Why we carry out evals
Evals are about ensuring to pressure-test the system on an even bigger (extra focused) corpus than your favourite 10 questions, and ensuring that no matter modifications you push don’t change the standard of the system.
Adjustments in knowledge, prompts, or fashions can very a lot have an effect on efficiency with out you seeing it.
You may additionally want to point out your workforce the overall efficiency of the system you’ve constructed earlier than being allowed to check it on actual customers.
However earlier than you do that, you might want to resolve what to check.
What does a profitable system appear like to you? Should you care about multi-hop, you want questions that truly require multi-hop. Should you care about Q&A and correct citations, you check for that. In any other case, you find yourself evaluating the improper factor.
It is a bit like doing investigative work: you check one thing, you attempt to perceive the outcomes, and then you definitely construct higher exams.
To do that properly, it is best to attempt to construct a golden set (usually from consumer logs) to check with.
This isn’t at all times potential, so in conditions like this we construct artificial datasets. This might not be the easiest way to do it, as it should clearly be biased and gained’t mirror what your customers will really ask. However, chances are you’ll want to begin someplace.
For this text, I’ve created three totally different datasets so we are able to focus on it: one created from the ingested corpus, one that creates messy consumer questions from the corpus, and one with random questions on RAG that haven’t been generated from the corpus in any respect.
You’ll have the ability to see how these datasets give us totally different outcomes on the metrics, however that all of them imply various things.
What to suppose about
I’m not going to undergo all the pieces there may be to consider right here, as a result of doing evals properly is fairly tough (though additionally enjoyable in case you like statistics and knowledge).
However there are a number of stuff you want to remember: LLM judges are biased, cherry-picking questions is an issue, gold solutions are finest if in case you have them, and utilizing a bigger dataset with tags helps you break down the place and the way the system is failing.

Should you’ve learn the eval metrics article, you’ve already seen the concept of LLM-as-a-judge. It may be helpful, nevertheless it’s not inherently dependable as a result of it has baked-in preferences and blind spots.
There are issues that may make you go mad, like a decide punishing a solution that’s based mostly on the corpus however not explicitly acknowledged within the retrieved chunks (summaries / small inferences), or judging the identical reply otherwise relying on how the query is phrased.
You’ll notice this later once you dig into the questions which might be failing to know why.
One other factor to remember is to ensure to not “cherry-pick” questions, even in case you really feel the urge to.
You clearly have to begin someplace, however the purpose is to get near what your customers are literally asking, discover the problems, and to replace the dataset constantly based mostly on what the system appears to fail in. It’s straightforward to get good numbers in case you largely check “straightforward” questions, however then the eval turns into much less helpful.
One of the best factor is to haven’t simply actual consumer questions but additionally gold solutions.
So even in case you can “bypass” having references by utilizing an LLM decide, having the right solutions for these questions is finest. That’s when you should use the LLM to guage whether or not the output matches the gold reply, as a substitute of asking it to guage the reply by itself.
Pattern measurement issues too. Too small and it might not be dependable. Too massive and it’s straightforward to overlook smaller issues.
When you have sufficient knowledge, you’ll be able to tag questions into subjects, totally different wordings (pessimistic / typical phrasing), and differing types (brief / lengthy / messy) so you’ll be able to see what breaks the place.
I’ve heard suggestions that begin with one thing like 200–1,000 actual queries with gold solutions if you need this to be an actual analysis setup.
Since this complete train is hypothetical, and the system has ingested paperwork to demo the concept of increasing to neighbors, the evals could have datasets which have been synthetically generated, and thus much less dependable, however there may be nonetheless learnings we are able to get from it.
Deciding on metrics & datasets
This part is about two issues: which metrics I’m utilizing to guage the pipeline, and the way I’m utilizing them throughout datasets to see if neighbor growth appears to assist.
First, in case you haven’t examine evals for LLM programs in any respect, go learn this article. It offers you a taxonomy of the totally different metrics on the market (RAG included).
Since I’m lazy for this, I wanted reference-free metrics, however this may also restrict us to what we are able to really check. We will have the decide take a look at the context, the query, and the generated reply.
A number of metrics that may assist listed below are faithfulness (is the reply grounded within the supplied context), reply relevancy (does it really reply the query), context relevancy (how a lot of the context is simply noise), and hallucination (what number of claims are literally backed up by the supplied context).

Since we need to determine if seed growth is helpful, and with out constructing two totally different pipelines, we are able to do one easy comparability: ask the decide to take a look at the seed chunks vs. the ultimate expanded context and rating how a lot of the reply comes from every for the faithfulness metric.
If grounding improves when the decide sees the expanded context, that’s a minimum of proof that the mannequin is utilizing the expanded chunks and it’s not simply noise. We would wish extra testing, although, to say for positive which is the winner.
Lastly, the datasets matter as a lot because the metrics.
Should you’ve learn the primary article, you realize that every one the docs which have been ingested are scientific articles that point out RAG. So all of the questions that we create right here must be about RAG.
I have generated three totally different datasets with a special RAG taste.
The first relies on the ingested corpus, going by every scientific article and writing two questions every that it might probably reply.
The second is doing the identical however offering messy questions like, “how does k2 btw rag enhance reply fetching in comparison with naive rag, like what’s the similarity scores by way of q3?”

This messy consumer questions dataset might be good to check the question optimizer in case you learn the primary article (however I don’t have these outcomes for you right here). Right here it should inform us if stating issues otherwise would skew the outcomes.
The third dataset relies on 66 random RAG questions discovered on-line. Which means these questions might not have solutions within the corpus (the ingested RAG articles are simply from September to October, so we don’t know precisely what they comprise).
So the primary two will consider how properly the pipeline behaves, whether or not it might probably reply questions on the paperwork it has, and the third one tells us what it’s lacking and the way it behaves on questions that it may not have the ability to reply.
Although this can be a bit simplified, as the primary questions could also be structured on sections and the random ones could also be higher answered by seed chunks.
Working the evals
To run the evals, you first must run the pipeline on each query, for each mannequin, and retailer the outcomes.
Should you don’t retailer all the pieces you want, you’ll be able to’t debug later. You need to have the ability to go from a low rating again to the precise reply, the precise retrieved context, and the precise mannequin settings.
I additionally needed to check fashions, as a result of individuals assume “larger mannequin = higher solutions,” and that’s not at all times true, particularly for simpler duties. So I’m working the identical pipeline throughout GPT-5-mini, GPT-5.1, and GPT-5.2, for a number of datasets.
As soon as that’s completed, I construct the eval layer on high of these saved outputs.
I used RAGAS for the usual metrics and DeepEval for the customized ones. You possibly can clearly construct it manually, nevertheless it’s a lot simpler this manner. I like how seamless DeepEval is, although it’s more durable to debug in case you discover points with the decide later.
A number of specifics: the pipeline runs with no context cap, the decide mannequin is gpt-4o-mini, and we use n=3 for RAGAS and n=1 for the customized judges.
Since neighbor growth is the entire level of this pipeline, bear in mind we additionally run this examine: for faithfulness, we rating grounding in opposition to the seed chunks and in opposition to the total expanded context, to see if there’s a distinction.
Eval outcomes of datasets & fashions
Let’s run the evals for the totally different datasets, metrics, and fashions to see how the pipeline is doing and the way we are able to interpret the outcomes. Keep in mind you will discover the total outcomes right here and right here (particularly in case you dislike my infantile sketches).
We will begin with the outcomes from the dataset generated by the corpus.

The desk above reveals the primary RAGAS metrics. Faithfulness (does it keep grounded within the context supplied) and reply relevancy (does it reply the query) are very excessive.
That is to be anticipated, as we’re mainly giving it questions that it ought to have the ability to reply with the paperwork. If these confirmed low numbers, there can be one thing severely off within the pipeline.
It additionally offers us again seed faithfulness, the place the decide is estimating how grounded the reply is to the seed chunks. This one is total quite a bit decrease than the total context faithfulness, 12–18 factors throughout the totally different fashions.
In fewer phrases: we are able to say that the LLM is utilizing among the full context, not simply the seed chunks, when producing its reply.
What we are able to’t decide although is that if the seed-only reply would have been simply pretty much as good. This can require us to run two pipelines and evaluate the identical metrics and datasets for every.
Now let’s take a look at these subsequent metrics (for a similar dataset).

I’d have estimated that context relevance would lower right here, because it’s wanting on the full context that pulls in as much as 10 totally different chunk neighbors for the part.
A purpose for this can be that the questions generated are based mostly on sections, which signifies that added context helps to reply them.
Construction citations (i.e. does it cite its claims appropriately) seems to be alright, however hallucination is excessive, which is sweet (1 means no made-up claims within the reply).
Now you’ll see that the totally different fashions present little or no distinction by way of efficiency.
Sure, that is fairly a simple Q&A activity. However it does display that the extra measurement of the mannequin might not be wanted for all the pieces, and the added context growth could possibly act as a buffer for the smaller fashions.
Now let’s take a look at the outcomes if we alter the dataset to these messy consumer questions as a substitute.

We see a number of drops in factors, however they nonetheless keep excessive, although with out isolating the outliers right here we are able to’t say why. However faithfulness seems to be decrease when solely judging with the seed chunks for the messy consumer questions, which is attention-grabbing.
Let’s now flip to the third dataset, which can have the ability to inform us much more.

We see throughout worse numbers which is after all anticipated, the corpus that has been ingested most likely can’t reply all of those questions so properly. This helps us level to the place we now have lacking data.
Faithfulness stays excessive although nonetheless for the total context runs. Right here the distinction from the seed-only runs are quite a bit greater, which suggests the added growth is getting used extra within the reply.
One thing that was unusual right here was how GPT-5.2 constantly did worse for reply relevance throughout two totally different runs. This is usually a metric factor, or it may be a mannequin factor the place it solutions extra cautiously than earlier than, thus getting a decrease rating.
This additionally tells you why it’s so necessary to check these new fashions by yourself pipelines earlier than including them in.
Let’s proceed with the opposite metrics for the random dataset.

Context relevance may be very low, so the decide thinks there may be numerous noise within the context that doesn’t immediately reply the query for this dataset.
The context relevance metric rewards retrieving a excessive proportion of immediately related chunks, however seed+increase deliberately provides neighbor chunks (definitions, adjoining sections, captions) that ought to enhance grounding. Sadly, there could also be some noise that comes with that.
Each construction citations and hallucination rating worse right here, most likely as a result of it’s more durable to remain grounded in case you’re not supplied any related data to make use of.
Now this was a primary construct for this pipeline. Based mostly on these outcomes, you’ll be able to enhance it till you drive these numbers up. Possibly change the metrics to be extra customized to your pipeline.
Each datasets present various things: the corpus-based one reveals the pipeline works, the random one reveals there may be lacking data and that there’s a lot extra noise to navigate round.
What to study
So what do you do now that you’ve got all these scores? You possibly can take a look at regressions, worst offenders, and do some random sampling.
Like I mentioned earlier than, this complete train is a bit like investigative work, which you’ll love in case you love working with knowledge. Should you do have sufficient knowledge and also you’ve tagged it, then by all means break it down and take a look at the person numbers and see what you discover. However there are three checks it is best to at all times do.
First is regressions: examine the stuff that used to cross and now fails following modifications.
Second is checking the worst offenders (backside ~5–10 knowledge factors) to see what is going on. It might be the metric, the decide, it might be the retrieval, and it might be the mannequin.
Under is among the worst ones for full faithfulness and reply relevancy.
"query": "how usually does entity linking mess up acronyms and lookalikes, and the way do i check that",
"reply": "The paperwork don't report a direct quantity for "how usually" entity linking fails particularly on acronyms or look‑alike names.nnWhat we do see is that:n- Even when construction is right, LLMs usually hyperlink to the improper property or entity (semantic inaccuracies) in SPARQL era over a scholarly KG [2]. This is similar failure mode you'd see when an acronym (e.g., NMF, ACE) is mapped to the improper node.n- In medical KGs, entity linking depends on actual key phrases after which semantic similarity of embeddings when no actual match exists [3]. This final step explicitly permits linking to a merely "semantically associated" idea somewhat than the precise one, which is the place lookalikes and acronym collisions can happen [3].n- In conversational entity‑centric programs, the biggest single error class is coreference/entity confusion (27% of failures) [4], exhibiting that complicated related mentions is a significant sensible downside even exterior strict EL.nnHow to check this in your setting, utilizing patterns from the papers:n1) Construct a focused check setn - Create a small benchmark that stresses acronyms and visually/lexically related entities, analogous to how MATE is used to emphasize cross‑modal entity linking [1].n - Embody constructive pairs (right acronym→entity) and laborious negatives (totally different entities sharing acronym or close to‑similar names).nn2) Run your full EL pipelinen - Use the identical identifier / key phrase / embedding‑based mostly linking technique described in MedKGent [3].nn3) Manually and/or LLM‑assisted evaluationn - Have people or an LLM rating whether or not every hyperlink is right vs. incorrect, just like the triple‑validity rubric utilized in MedKGent [3] and the SPARQL error audit in FIRESPARQL [2].nn4) Analyze error typesn - Break down errors just like the semantic vs. structural evaluation in [2] and the error desk in [4], however with classes "acronym collision," "lookalike floor kind," and so on.nnThis will provide you with an empirical error price on your personal stack, targeted particularly on acronyms and lookalikes.",
"full_faithfulness": 0.24,
"seed_faithfulness": 0.8260869565000001,
"answer_relevancy": 0.0,
"context_relevance": 0.208549739206933,
"context_relevance_reason": "The context supplied doesn't immediately tackle the consumer's query about how usually entity linking messes up acronyms and lookalikes, nor does it provide strategies for testing that. Whereas it discusses entity linking and its evolution, it lacks particular data on the problems associated to acronyms and lookalikes, which is the core of the consumer's inquiry.",
"hallucination_score": 0.6572611409640697,
"hallucination_reason": "The response precisely identifies that the paperwork don't present a particular frequency for the way usually entity linking fails with acronyms or lookalikes, which aligns with the enter question. It additionally discusses related points equivalent to semantic inaccuracies and coreference confusion, that are pertinent to the subject. Nevertheless, it lacks direct references to particular claims made within the context, equivalent to the constraints of conventional EL strategies or the position of actual key phrases in medical KGs, which may have strengthened the response additional.",
"full_contexts": ["Entity LinkingnnEntity Linking (EL) has evolved from text-only methods to Multimodal Entity Linking (MEL), and more recently to Cross-Modal Entity Linking (CMEL), which supports crossmodal reasoning. Traditional EL methods associate textual entities with their corresponding entries in a knowledge base, but overlook non-textual information (Shen, Wang, and Han 2015; Shen et al. 2023). MEL extends EL by incorporating visual information as auxiliary attributes to enhance alignment between entities and knowledge base entries (Gan et al. 2021; Liu et al. 2024b; Song et al. 2024).", "However, MEL does not establish cross-modal relations beyond these auxiliary associations, thereby limiting genuine cross-modal interaction.", "CMEL goes further by treating visual content as entities-aligning visual entities with their textual counterparts-to construct MMKGs and facilitate explicit crossmodal inference (Yao et al. 2023). Research on CMEL remains in its early stages, lacking a unified theoretical framework and robust evaluation protocols. The MATE benchmark is introduced to assess CMEL performance, but its synthetic 3D scenes fall short in capturing the complexity and diversity of real-world images (Alonso et al. 2025). To bridge this gap, we construct a CMEL dataset featuring greater real-world complexity and propose a spectral clustering-based method for candidate entity generation to drive further advances in CMEL research.", "3 Error type analysis on generated SPARQL queriesnnDespite the improvements of LLMs on QA over SKGs, LLMs face limitations when handling KG-specific parsing. The experimental results conducted by Sören Auer et al.[2] confirmed that solely 63 out of 100 handcrafted questions might be answered by ChatGPT, of which solely 14 solutions had been right. To raised perceive why LLMs fail to generate the right SPARQL question to a NLQ, we conduct a pilot experiment on utilizing ChatGPT(GPT-4) with a random one-shot instance to generate SPARQL queries for 30 handcrafted questions within the SciQA benchmark datasets.", "Insights from this pilot experiment revealed two main classes of errors LLMs are inclined to make on this activity: semantic inaccuracies and structural inconsistencies. Semantic inaccuracies happen when LLMs fail to hyperlink the right properties and entities in ORKG, regardless of producing SPARQL queries with right construction. Our observations reveal that LLMs are inclined to depend on the instance supplied within the one-shot studying course of to generate the right construction for a sure kind", "of questions, however usually wrestle with linking the right properties and entities as a result of LLMs don't study the content material of the underlying KG. Structural inconsistencies come up because of LLMs' lack of ontological schema of the underlying KG, resulting in errors in question construction, equivalent to lacking or considerable hyperlinks (triples), regardless of appropriately linking to the talked about entities or properties.", "Determine 1 reveals the instance of semantic inaccuracies and structural inconsistencies downside with the generated SPARQL queries in our pilot research. Within the instance of the semantic inaccuracies downside, ChatGPT did not hyperlink the right property orkgp:P15687; as a substitute, it linked to a improper property orkgp:P7101. Within the instance of the structural inconsistencies downside, the SPARQL question generated by ChatGPT immediately hyperlinks Contribution to Metrics, fails to detect the right schema of the ORKG the place Contribution and Metric are linked through Analysis.", "Fig. 1: Examples of semantic inaccuracies and structural inconsistencies downside with the generted SPARQL queriesnnSemantic inaccuracies ProblemnnFail to hyperlink the right properties and entities in ORKGnnWhat is the utmost pattern measurement?nnContribution Analysis Metric P34 P2006 P7046nnStructural inconsistencies ProblemnnMake errors in question construction, equivalent to lacking or considerable hyperlinks (triples)nnWhat are the metrics utilized by paper "Utilizing NMF-based textual content summarizationnnto enhance supervised and unsupervised classification?nnorkgp:P15687 rdfs:label Pattern measurement (n)nnorkgp:P7101 rdfs:label has components", "2 Resultsn2.1 Methodology overviewnnas its confidence rating. As an example, if the triple (NPPA, Adverse Correlate, Water) seems in 90% of the outputs, its confidence rating is 0.9. Low-confidence triples (rating < 0.6) are filtered out, and solely high-confidence triples are retained for downstream graph building. Every triple can be annotated with the PubMed ID of the supply summary and a timestamp, guaranteeing traceability and supply attribution. For instance, (NPPA, Adverse Correlate, Water) would have a PubMed ID of 10494624 and a timestamp of 2000-01-01.", "As proven in Determine 1 c , for every retained triple, equivalent to (NPPA, Adverse Correlate, Water), the Constructor Agent checks its presence within the present KG. If absent ( i.e. , both the pinnacle or tail entities are lacking), it's inserted; if current, its confidence rating is up to date in accordance with Equation (1). The related PubMed ID is appended, and the timestamp is up to date to mirror the newest publication. For instance, if an present triple (NPPA, Adverse Correlate, Water) has a confidence rating of 0.7, PubMed ID 10691132, and timestamp 1999-12-31, and a brand new prevalence with a confidence rating of 0.9, PubMed ID 10494624, and timestamp 2000-01-01 is encountered, the up to date triple could have a confidence rating of 0.97, PubMed IDs [10691132, 10494624], and a timestamp of 2000-01-01. If the pinnacle and tail entities are current however the relation differs, equivalent to present (NPPA, Affiliate, Water) vs. incoming (NPPA, Adverse Correlate, Water), solely essentially the most applicable relation is maintained. The Constructor Agent invokes the LLM to resolve the battle by choosing the extra appropriate relation, contemplating each the present and incoming triple's confidence scores and timestamps. If the LLM selects the brand new triple, the present one is changed; in any other case, no modifications are made. The immediate design for relation battle decision is proven in Prolonged Information Determine 2 c . Collectively, the 2 brokers extract structured medical information and combine them right into a dynamic, time-aware KG. See extra particulars within the Part 4.", "2.2 Structural Characterization of the Data GraphnnIn this part, we element the structural traits of the medical KG we constructed, with an emphasis on the distribution of node sorts, relationship sorts, and the boldness scores of relationship triples. We additionally current a visualization of a subgraph centered on COVID-19 as an example the graph's construction.", "Utilizing the MedKGent framework, we extracted information triples from the abstracts of 10,014,314 medical papers, with 3,472,524 abstracts (34.68%) yielding extractable triples. The comparatively low extraction price may be attributed to a number of components: first, some abstracts lacked ample structured data for triple extraction; second, solely triples with a confidence rating exceeding 0.6 had been retained, excluding these with decrease confidence; and third, some triples extracted by LLMs contained formatting points, equivalent to extraneous or irrelevant characters, which had been discarded. In complete, our Extractor Agent recognized 8,922,152 legitimate triples from the abstracts. Nevertheless, the extracted triples contained a major variety of duplicates and conflicts. To resolve this, our Constructor Agent integrates the triples in chronological order. Throughout this course of, duplicates are merged, with the boldness rating for every triple growing in proportion to its frequency, reflecting better certainty. For conflicting triples, the place the identical entity pair is related to a number of relations, the Constructor Agent retains essentially the most applicable relationship. Following this consolidation, the ultimate KG includes 2,971,384 distinct triples.", "We performed a complete statistical evaluation of the ultimate constructed KG, which includes 156,275 nodes. As proven in Determine 2 a , the node distribution is predominantly dominated by Gene and Chemical nodes, with smaller proportions of different entities equivalent to Illness, Variant, Species, and CellLine. The KG contains 2,971,384 relationship triples (edges), representing a spread of interactions between entities, as illustrated in Determine 2 b . The most typical relationship kind is 'Affiliate', adopted by 'Adverse Correlate' and 'Constructive Correlate', indicating sturdy associations between medical entities. Much less frequent relationships, equivalent to 'Work together', 'Stop', and 'Drug Work together', present further insights into the complexities of medical interactions. The distribution of confidence scores for these relationship triples, proven in Determine 2 c , with confidence values discretized to the closest smaller 0.05 increment (rounding all the way down to the closest a number of of 0.05), reveals a transparent dominance of high-confidence triples. A big proportion of triples exhibit confidence scores of 0.95, reflecting the cumulative enhance in confidence ensuing from the repetition of triples through the graph building course of. This high-confidence distribution reinforces the reliability and robustness of the KG.", "We visualized a neighborhood subgraph of the constructed KG with COVID-19 because the central node, highlighting 5 surrounding relationship triples, as proven in Determine 2 d . Every node is characterised by six key attributes: the Identifier, which uniquely references the node and normalizes a number of synonymous mentions to a standardized terminology entry; the Entity Kind, which classifies the entity; the Terminology, which maps the entity kind to its corresponding normal terminology; the Web page Hyperlink, offering a reference to the entity within the Terminology; the Actual Key phrases, which lists frequent names and aliases of the entity in lowercase; and the Semantic Embedding, a vector illustration of the entity. In observe, these attributes facilitate entity linking inside a question by matching entities to their corresponding nodes within the KG. When the Identifier of an entity within the question is on the market, entity linking may be effectively carried out utilizing this distinctive reference. Within the absence of an Identifier, exact matching", "Determine 2: A complete statistical evaluation and visualization of the constructed KG, consisting of 156,275 nodes and a couple of,971,384 relationship edges. a . Node distribution inside the KG, with Gene and Chemical nodes predominating, and smaller proportions of Illness, Variant, Species, and CellLine. b . Relationship kind distribution inside the KG, highlighting the prevalence of 'Affiliate' relationships, adopted by 'Adverse Correlate' and 'Constructive Correlate', with much less frequent interactions equivalent to 'Work together', 'Stop', and 'Drug Work together'. c . The distribution of confidence scores for relationship triples, discretized to the closest smaller 0.05 increment, ensures values are rounded all the way down to the closest a number of of 0.05. This distribution reveals a transparent dominance of high-confidence triples, notably these with scores of 0.95, underscoring the robustness of the KG. d . Native subgraph visualization centered on COVID-19, displaying 5 surrounding relationship triples. Every node is characterised by key attributes, together with Identifier, Entity Kind, Terminology, Web page Hyperlink, Actual Key phrases, and Semantic Embedding, facilitating environment friendly entity linking by actual or similarity matching. The relationships within the KG are additional enriched by attributes equivalent to Confidence, PubMed IDs, and Timestamp, enhancing traceability, accuracy, and temporal relevance.nnCOVID -19 ACE2 Pneu- monia Lung Disea -ses MAD00 04J08 tociliz- umab Deal with Identifier : MESH:C000718219 Entity Kind : Chemical Terminology : NCBI MeSH Web page Hyperlink", ": meshb.nlm.nih.gov/document/ui?ui=C000718219nnExact Key phrases : [mad0004j08] Semantic Embedding : [- 0.12, …, 0.10 ] : MESH:D000086382nnEntity Kind:nnDiseasenn: meshb.nlm.nih.gov/document/ui?ui=D000086382nn: [ncp, covid-19]n0.25, …, 0.09nnIdentifier:nnMESH:C502936nChemicalnnTerminology:nnNCBI MeSHnn: meshb.nlm.nih.gov/document/ui?ui=C502936nn: [mra, tocilizumab] 0.12, …, 0.13 Affiliate 59272 Genenn:nnNCBI Genenn: www.ncbi.nlm.nih.gov/gene/59272nn: [ace2, ace2p]n0.22, …, 0.09]nMESH:D011014nn: meshb.nlm.nih.gov/document/ui?ui=D011014nn: [pneumonia]n0.18, …, 0.01nMESH:D008171nn: meshb.nlm.nih.gov/document/ui?ui=D008171nn: [lung diseases,lung damage]nn: [ 0.06, …, 0.11 d a b Drug_Interact (0.1%) 0.70 0.65 'Prevent (0.79 0.75 7.89) (7.5%) 0.60 (8.1%) (5.4% (47.7%) 0.80 CellLine Positive (8.9%) (0.5%) Correlate 0.85 (19.9%) (10.3%) Variant (1.49) (5.9%) Cause (1.4% 0.90 (33.6%) Inhibit (1.2% Negative_Correlate Stimulate (0.5%) (13.7%) Species Compare (26.1%) Cotreat (1.0%)", "Figure 3: Comprehensive evaluation of extraction quality for relationship triples generated by the Extractor Agent. Systematic assessment of extraction accuracy using both automated evaluations by LLMs and independent manual expert review. a . Proportion of valid relationship triples (score ≥ 2.0) across relation types, as assessed by GPT4.1 on a randomly selected subset of 34,725 abstracts (83,438 triples). b . Proportion of valid relationship triples across relation types, as assessed by DeepSeek-v3 on the same subset. c . Validity rates from independent manual evaluation by three domain experts on a subset of 400 abstracts (1,060 triples), demonstrating high inter-expert consistency. d-f . Performance of GPT-4.1 and DeepSeek-v3 compared to three expert evaluations on the shared evaluation subset, reporting precision, recall, and F1 score. g . Pairwise inter-rater agreement between experts and LLMs quantified by Cohen's kappa coefficients, demonstrating substantial consistency across all evaluators.nnGPT-4.nnAutomated EvaluationnnDeepSeek-v3 Automated EvaluationnnManual Evaluation 0936| 0.0307 0,8875 0,8880 0 8700 0.7160 0.4nnExpert1's Evaluation as ReferencennExpert2's Evaluation as ReferencennExpert3's Evaluation as ReferencennPairvise Cohen's 0 9761 09761 0 0602 00760 0.9502 00537 0,9503 0 9440 0.5663 08143 0,8818 0 5446 0.6762 0,8853 0.5446 0.6906 06818 0.6008 0 6560 GPT-4,1 DeepSeek-v3 GPT-4.1 Correlale Corelate Cause Inhon Irhon Cotcat Inlatact Colrcat Kappa ison", "is achieved by checking whether the entity appears in the Exact Keywords list of a specific node. Alternatively, semantic vectors of the query entities can be compared with those in the KG to identify the most similar entities, enabling semantic similarity matching. This approach is particularly beneficial for entities with multiple names, ensuring accurate linking even when not all aliases are captured in the Exact Keywords list.", "The relationships between entities are characterized by three key attributes. Confidence reflects the reliability of the relationship, with higher values indicating greater certainty based on its frequency across multiple sources. The PubMed IDs attribute lists the PubMed identifiers of the papers from which the relationship is derived, enabling easy access to the original publications via the PubMed website 2 . If the relationship appears in multiple papers, all relevant PubMed IDs are included, further increasing the confidence score. Finally, Timestamp denotes the most recent occurrence of the relationship, specifically the publication date of the latest paper. Notably, while Timestamp captures only the latest appearance, the full temporal span of the relationship-including its earliest mention-can be readily retrieved through the associated PubMed IDs via the PubMed website. These attributes collectively enhance the traceability, accuracy, and temporal relevance of the relationships within the KG.", "4 Methodsn4.2.2 Constructor AgentnnA chemical/drug treats a disease. The Treat relationship typically occurs between Chemical and Disease.nnMeSH (Medical Subject Headings)nndbSNP, otherwise HGNV formatnnNCBI TaxonomynCell LinenCellosaurusnnYour task is to select the most appropriate relationnnbetween two medical entities to form morennreasonable knowledge triple.nnThere is an and Now, a new between e1 andnne2 is proposed.nnPlease decide which relation should be retainednnbetween e1 and e2.nnIf r1 should be kept, respond with "Y".nnIf r2 should replace it, respond with "N".nnYou may consider the following two factors to assistnnyour decision:nn(1) Then, andnthat ofnn;nn(2) ThenfornnIn general, relations withnnhigher confidence scores or more recent timestamps are likelynnretained.nnYour output should contain only "Y" or "N". Do notnnprovide any explanations.nnOutput:nnc", "Extended Data Figure 2: a . Prompt template for relation extraction. Given a biomedical abstract and its extracted entities, the Extractor Agent prompts the LLM to infer semantic relations between entity pairs using a predefined relation set and textual descriptions. b . Reference terminologies for entity normalization. Each biomedical entity type is mapped to a standard terminology: Gene (NCBI Gene), Disease and Chemical (MeSH), Variant (dbSNP or HGNV), Species (NCBI Taxonomy), and Cell Line (Cellosaurus). c . Prompt design for relation conflict resolution. When conflicting relations exist between the same entity pair, the Constructor Agent prompts the LLM to select the most appropriate one based on confidence scores and timestamps. d . Schema for predefined relation types. The 12 core relation types-seven bidirectional and five unidirectional-are listed alongside their directionality, descriptions, and allowed entity-type combinations.", "4.3 Quality AssessmentnnWe assessed the quality of relational triples extracted by the Extractor Agent through both automated and manual evaluations, leveraging two state-of-the-art LLMs-GPT-4.1 [74] and DeepSeek-v3 [75]-as properly as three PhD college students with interdisciplinary experience in drugs and laptop science. For every medical summary and its corresponding set of extracted triples, particular person triples had been evaluated utilizing a standardized four-level scoring rubric: 3.0 (Right), 2.0 (Probably Right), 1.0 (Probably Incorrect), and 0.0 (Incorrect). The analysis immediate supplied to each LLMs and human annotators is illustrated in Prolonged Information Determine 3 a .", "A relational triple was outlined as legitimate if it acquired a rating of ≥ 2 . 0 . The validity price was calculated as:nnTo assess the reliability of computerized analysis, we in contrast LLM-based assessments with human annotations on a shared analysis subset, treating human judgments as floor fact. The precision, recall, and F 1 -score of the automated evaluations had been computed as:nnwhere TP, FP, and FN symbolize true positives, false positives, and false negatives, respectively. To additional quantify inter-rater settlement, we calculated Cohen's Kappa coefficient [82] for every pair of evaluators, together with each LLMs and human annotators, leading to 10 pairwise comparisons throughout the 5 raters. The Kappa coefficient was computed as:nnwhere p 0 represents the noticed settlement and p e denotes the anticipated settlement by likelihood. This evaluation offers a quantitative measure of ranking consistency throughout evaluators.", "4.4 Retrieval-Augmented GenerationnnThe constructed KG serves as a dependable exterior supply for data retrieval and may be built-in into LLMs through a RAG framework. By offering structured biomedical context, the KG enhances LLM efficiency throughout a spread of medical QA benchmarks.", "Given a consumer question q , we first extract the set of medical entities current within the query, denoted as E q = { e q 1 , e q 2 , · · · } . When utilizing PubTator3 [80]-the identical entity recognition device employed throughout KG constructioneach extracted entity is assigned a singular identifier. This enables for environment friendly entity linking by matching these identifiers to the corresponding nodes N q = { n q 1 , n q 2 , · · · } inside the graph. Alternatively, if medical entities are extracted utilizing different methods-such as prompting a LLM-they might lack standardized identifiers. In such instances, the extracted entity mentions are first transformed to lowercase and matched in opposition to the Actual Key phrases attribute of every node within the KG. A profitable match allows linkage of the entity to the corresponding graph node. In each approaches, if an entity can't be linked through its identifier or if its floor kind doesn't seem in any node's Actual Key phrases listing, we apply a semantic similarity technique to finish the entity linking course of. Particularly, the embedding of the question entity is computed utilizing the identical mannequin employed for producing node-level semantic representations ( i.e. , BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext [81]) and is in contrast in opposition to the Semantic Embedding of all nodes within the KG. The entity is then linked to the node with the very best semantic similarity rating, which can correspond to both the precise idea or a semantically associated medical entity. This entity linking framework-combining identifier-based matching, lexical normalization, and semantic embedding-ensures strong and versatile integration of KG-derived information into downstream QA duties.", "Following entity linking, we assemble proof subgraphs utilizing a neighbor-based exploration technique [86] to reinforce the reasoning capabilities of LLMs. For every entity-linked node within the query-specific set N q , we retrieve its one-hop neighbors inside the KG. Particularly, for every node n q i ∈ N q , all adjoining nodes n q ′ i are recognized, and the corresponding triples ( n q i , r, n q ′ i ) are appended to kind a localized subgraph G q i . This growth captures the rapid relational context surrounding the question entities, which is important for enabling fine-grained medical reasoning. The entire proof set for a given question is then outlined because the union of those localized subgraphs: G q = { G q 1 , G q 2 , · · · } . The ensuing subgraph G q might comprise numerous relational triples, together with redundant or irrelevant data, which may adversely influence LLM reasoning [87]. To handle this, we leverage the LLM's inherent rating functionality to selectively filter high-value information [88]. Given the query q and", "You're tasked with evaluating the validity of the information triples extracted from the summary of a medical paper.nnGiven the summary (nn) of a medical paper and the extracted triplesnn) from this summary.nnEach triple is represented within the format:nn"Head Entity Title (Alias1, Alias2) | Relationship Title | Tail Entity Title (Alias1, Alias2)"nn,nnwith triples separated by ' $ '.", "Some entities might don't have any aliases or a number of aliases, that are separated by ', ' inside the '()'.nnYour activity is to guage the validity of every triple, with a selected concentrate on thennrelationshipnnit describes, based mostly on the data supplied within the summary. Think about whether or not the acknowledged relationship accuratelynnreflects the connection between the pinnacle and tail entities as introduced or implied within the textual content.", "For every triple, consider its validity utilizing the next scoring scale and assign a confidence rating:nn•nnCorrect (3.0):nnThe relationship logically and precisely describes the relation between the pinnacle and tail entities asnnexplicitly talked about or immediately and strongly supportednnby the summary. Thennrelationship kind isnprecisennand the connection isnnundeniablennbased on the textual content, requiring minimal inference.nnLikely Right (2.0):nnThe relationship isnngenerally acceptable and directionally correctnn. The core connection between the entities isnnvalid and supported by the textual content (explicitly, implicitly, or viannreasonable inference)nn, even when the connection kind hasnnminor inaccuracies or lacks best precisionnn.nnLikely Incorrect (1.0):nnsubstantially inaccurate or misleadingnnsignificantly misrepresentingnnthe connection described within the summary, even when the entities are talked about collectively.nnIncorrect (0.0):nnnot supported by the summary whatsoevernn, isnnclearly and undeniably contradictednnby the textual content, or entails annfundamental misunderstandingnnof the entities or theirnnconnection as introduced.nnOutput the analysis in a set format:nnFirst line: 'Evaluation: ' adopted by the evaluation of all triples, separated by '; '. Every triple's evaluation ought to explainnnwhynnthe particular confidence rating (3.0, 2.0, 1.0, or 0.0) was assigned based mostly on the criteriannabove and the summary's content material.", "Second line: Solely the numerical confidence scores for all triples, separated by ' $ ', in the identical order because the enter triples (e.g., 3.0 $ 2.0 $ 1.0 $ 0.0). This line should comprise solely numbers (formatted to onenndecimal locations like 3.0, 2.0, 1.0, 0.0), decimal factors, and ' $ ' as separator, with no further textual content or English letters.", "5 Resultsn5.1 Most important Resultsnn| | Mannequin | FR (%) | DC (%) | UCS (/5) |n|---:|:-------------------|:-----------|:-----------|:-----------|n| 0 | Stateless LLM | 54.1 (0.4) | 48.3 (0.5) | 2.1 (0.1) |n| 1 | Vector RAG | 71.6 (0.6) | 66.4 (0.7) | 3.4 (0.1) |n| 2 | Entity-RAG | 75.9 (0.5) | 72.2 (0.6) | 3.7 (0.1) |n| 3 | Semantic Anchoring | 83.5 (0.3) | 80.8 (0.4) | 4.3 (0.1) |nnTable 1: General efficiency on MultiWOZ-Lengthy. Semantic Anchoring outperforms all baselines throughout metrics. Enhancements in FR and DC are statistically vital at p < 0 . 01 ; UCS positive aspects are vital at p < 0 . 05 . Values are imply ± stdev over three runs.", "Determine 2 analyzes how efficiency varies with session depth. Whereas all fashions degrade as dialogue span will increase, Semantic Anchoring sustains over 75% recall at 10 classes, indicating stronger long-range monitoring.", "5.2 Per-Dataset BreakdownnnTo check generality, we consider on DialogRE-L , which emphasizes relation extraction throughout classes. Ends in Desk 2 present constant enhancements, although broader domains are wanted to assert robustness.", "Determine 2: Factual Recall by session depth on MultiWOZ-Lengthy. Semantic Anchoring reveals the slowest degradation, sustaining > 75% recall at 10-session distance. Error bars denote normal deviation throughout three runs.nnFactual Recall vs. Session Depth (MultiWOZ-Lengthy)nnStateless LLM Vector RAG Entity-RAG Semantic Anchoring Session Depthnn|---:|:-------------------|---------:|---------:|-----------:|n| 0 | Stateless LLM | 49.8 | 44.1 | 2 |n| 1 | Vector RAG | 68.7 | 62.5 | 3.2 |n| 2 | Entity-RAG | 72.1 | 68.3 | 3.6 |n| 3 | Semantic Anchoring | 81.4 | 77.9 | 4.2 |nnTable 2: Efficiency on DialogRE-L. Semantic Anchoring achieves constant positive aspects throughout metrics, suggesting effectiveness in relation extraction duties that require long-range entity monitoring.", "5.3 Ablation StudiesnnTable 3 examines the position of linguistic parts. Eradicating discourse tagging reduces FR by 4.7 factors, whereas excluding coreference decision reduces DC by 6.2 factors. Eliminating all symbolic options collapses efficiency to Vector RAG ranges. These outcomes align with noticed error patterns (§5.6), underscoring the worth of symbolic options.", "5.4 Qualitative ExamplesnnIn MultiWOZ-Lengthy, when the consumer later asks 'Did he affirm the time for the taxi?' , Semantic Anchoring retrieves:nn[Entity: John Smith][CorefID: E17] confirmed the taxi is booked for 9 AM.", "In contrast, Vector RAG surfaces unrelated mentions of 'taxi.' Extra examples, together with instances the place Semantic Anchoring fails, are proven in Appendix C.", "| | Variant | FR (%) | DC (%) | UCS (/5) |n|---:|:-------------------------|---------:|---------:|-----------:|n| 0 | Full Mannequin | 83.5 | 80.8 | 4.3 |n| 1 | - Discourse Tagging | 78.8 | 75.6 | 4 |n| 2 | - Coreference Decision | 80.1 | 74.6 | 4.1 |n| 3 | - Dependency Parsing | 81.2 | 78.5 | 4.1 |n| 4 | Dense-only (Vector RAG) | 71.6 | 66.4 | 3.4 |nnTable 3: Ablation outcomes on MultiWOZ-Lengthy. Eradicating discourse or coreference modules considerably reduces FR and DC, respectively. With out all symbolic options, efficiency falls to the dense-only baseline.", "5.5 Human EvaluationnnFive skilled annotators rated 50 randomly sampled conversations for Person Continuity Satisfaction (UCS). Settlement was excessive ( α = 0 . 81 ). As Desk 1 reveals, Semantic Anchoring achieves the very best UCS (4.3), with annotators noting higher consistency in entity references. Full protocol particulars are in Appendix B.", "5.6 Error AnalysisnnTable 4 categorizes frequent failures. Coreference errors (27%) and parsing errors (19%) are essentially the most frequent, in step with ablation findings. Discourse mislabeling (15%) usually arises in sarcasm or overlapping speech. Whereas total error frequency is decrease than dense retrieval, these stay open challenges.", "| | Error Kind | Proportion of Failures |n|---:|:----------------------|:-------------------------|n| 0 | Parsing errors | 19% |n| 1 | Coreference errors | 27% |n| 2 | Discourse mislabeling | 15% |n| 3 | Different / miscellaneous | 39% |nnTable 4: Error evaluation on MultiWOZ-Lengthy. Coreference errors are essentially the most frequent error kind, adopted by parsing and discourse points. These patterns align with ablation outcomes."],
"seed_texts": ["Entity LinkingnnEntity Linking (EL) has evolved from text-only methods to Multimodal Entity Linking (MEL), and more recently to Cross-Modal Entity Linking (CMEL), which supports crossmodal reasoning. Traditional EL methods associate textual entities with their corresponding entries in a knowledge base, but overlook non-textual information (Shen, Wang, and Han 2015; Shen et al. 2023). MEL extends EL by incorporating visual information as auxiliary attributes to enhance alignment between entities and knowledge base entries (Gan et al. 2021; Liu et al. 2024b; Song et al. 2024).", "Insights from this pilot experiment revealed two major categories of errors LLMs tend to make in this task: semantic inaccuracies and structural inconsistencies. Semantic inaccuracies occur when LLMs fail to link the correct properties and entities in ORKG, despite generating SPARQL queries with correct structure. Our observations reveal that LLMs tend to rely on the example provided in the one-shot learning process to generate the correct structure for a certain type", "We visualized a local subgraph of the constructed KG with COVID-19 as the central node, highlighting five surrounding relationship triples, as shown in Figure 2 d . Each node is characterized by six key attributes: the Identifier, which uniquely references the node and normalizes multiple synonymous mentions to a standardized terminology entry; the Entity Type, which classifies the entity; the Terminology, which maps the entity type to its corresponding standard terminology; the Page Link, providing a reference to the entity in the Terminology; the Exact Keywords, which lists common names and aliases of the entity in lowercase; and the Semantic Embedding, a vector representation of the entity. In practice, these attributes facilitate entity linking within a query by matching entities to their corresponding nodes in the KG. When the Identifier of an entity in the query is available, entity linking can be efficiently performed using this unique reference. In the absence of an Identifier, precise matching", "Given a user query q , we first extract the set of medical entities present in the question, denoted as E q = { e q 1 , e q 2 , · · · } . When using PubTator3 [80]-the identical entity recognition device employed throughout KG constructioneach extracted entity is assigned a singular identifier. This enables for environment friendly entity linking by matching these identifiers to the corresponding nodes N q = { n q 1 , n q 2 , · · · } inside the graph. Alternatively, if medical entities are extracted utilizing different methods-such as prompting a LLM-they might lack standardized identifiers. In such instances, the extracted entity mentions are first transformed to lowercase and matched in opposition to the Actual Key phrases attribute of every node within the KG. A profitable match allows linkage of the entity to the corresponding graph node. In each approaches, if an entity can't be linked through its identifier or if its floor kind doesn't seem in any node's Actual Key phrases listing, we apply a semantic similarity technique to finish the entity linking course of. Particularly, the embedding of the question entity is computed utilizing the identical mannequin employed for producing node-level semantic representations ( i.e. , BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext [81]) and is in contrast in opposition to the Semantic Embedding of all nodes within the KG. The entity is then linked to the node with the very best semantic similarity rating, which can correspond to both the precise idea or a semantically associated medical entity. This entity linking framework-combining identifier-based matching, lexical normalization, and semantic embedding-ensures strong and versatile integration of KG-derived information into downstream QA duties.", "5.6 Error AnalysisnnTable 4 categorizes frequent failures. Coreference errors (27%) and parsing errors (19%) are essentially the most frequent, in step with ablation findings. Discourse mislabeling (15%) usually arises in sarcasm or overlapping speech. Whereas total error frequency is decrease than dense retrieval, these stay open challenges."]Right here we are able to see the corpus didn’t really comprise direct proof for what was requested however the seed chunks had been extra contained so faithfulness received a better rating when solely offering the seed chunks.
Reply relevancy was punished unusually low for not with the ability to reply the direct query.
This one was an outlier although and basically full faithfulness is greater than seed faithfulness.
It’s also possible to examine a very good one to know the way it estimates those that passes.
"query": "What retrieval settings assist cut back needle-in-a-haystack points for medical QA?",
"reply": "To scale back "needle‑in‑a‑haystack" issues in medical QA, the retrieval setup ought to concentrate on bringing again a small, very targeted set of extremely related gadgets as a substitute of huge, noisy context.nn1. Management context measurement and granularityn- Use abstracts or snippets somewhat than full articles; lengthy, unfocused context diluted mannequin efficiency in biomedical QA, so reranking all the way down to a smaller, excessive‑high quality subset was obligatory for good solutions [1].n- Restrict the variety of paperwork handed to the mannequin (e.g., rerank from 1000's down to some hundred or much less) to keep away from disorienting the mannequin with an excessive amount of textual content [1].nn2. Use multi‑stage retrievaln- Begin with excessive‑recall lexical retrieval (e.g., BM25 over PubMed) to get a broad set of candidates (as much as 1000's) [1].n- Apply a powerful semantic reranker to choose solely the highest slice for RAG (e.g., high 300) [1].n- If proof is lacking, fall again to broader net‑or multi‑supply search over trusted medical websites to fill gaps, somewhat than over‑stuffing the primary cross with all the pieces [1].nn3. Enhance question qualityn- Use an LLM to rewrite or increase queries (synonyms, associated phrases, much less uncommon jargon) when preliminary recall is poor, boosting the prospect that the important thing paper is retrieved with out over‑increasing each question by default [1].nn4. Use structured, corpus‑conscious retrievaln- Retrieve from structured medical information sources equivalent to information graphs and prepend solely essentially the most related subgraph, which constantly improved accuracy throughout a number of medical QA benchmarks [3].n- In multimodal/heterogeneous setups, use corpus‑particular retrieval for various information sources so every corpus is searched with strategies tuned to its content material, as a substitute of 1 generic retriever over all the pieces [2].",
"full_faithfulness": 1.0,
"seed_faithfulness": 0.8636363636000001,
"answer_relevancy": 0.9135841092,
"context_relevance": 0.8976322813389481,
"context_relevance_reason": "The context passages present complete insights into retrieval settings that may mitigate needle-in-a-haystack points in medical QA. Particularly, the dialogue on the mixing of LLMs for data retrieval, the usage of semantic reranking, and the multi-stage retrieval method immediately addresses the consumer's query. The emphasis on sustaining relevance whereas increasing question protection and the point out of ensemble strategies spotlight efficient methods for bettering retrieval accuracy in advanced biomedical queries. Nevertheless, whereas the data is very related, a extra specific connection to particular 'needle-in-a-haystack' challenges may improve readability.",
"hallucination_score": 0.8893376167284271,
"full_contexts": ["AbstractnnBiomedical question answering (QA) poses significant challenges due to the need for precise interpretation of specialized knowledge drawn from a vast, complex, and rapidly evolving corpus. In this work, we explore how large language models (LLMs) can be used for information retrieval (IR), and an ensemble of zero-shot models can accomplish state-of-the-art performance on a domain-specific Yes/No QA task. Evaluating our approach on the BioASQ challenge tasks, we show that ensembles can outperform individual LLMs and in some cases rival or surpass domain-tuned systems - all while preserving generalizability and avoiding the need for costly fine-tuning or labeled data. Our method aggregates outputs from multiple LLM variants, including models from Anthropic and Google, to synthesize more accurate and robust answers. Moreover, our investigation highlights a relationship between context length and performance: while expanded contexts are meant to provide valuable evidence, they simultaneously risk information dilution and model disorientation. These findings emphasize IR as a critical foundation in Retrieval-Augmented Generation (RAG) approaches for biomedical QA systems. Precise, focused retrieval remains essential for ensuring LLMs operate within relevant information boundaries when generating answers from retrieved documents. Our results establish that ensemble-based zero-shot approaches, when paired with effective RAG pipelines, constitute a practical and scalable alternative to domain-tuned systems for biomedical question answering.", "3. Our methodologynn3.1. Information Retrieval PipelinennTo support high-quality RAG for Phase A+, we developed an IR pipeline that integrates traditional lexical search with LLM-based query generation and semantic reranking (Fig. 1).", "If the initial query returns fewer than five documents, we invoke Gemini 2.5 Pro Preview (05-06) to automatically revise the query. The model is prompted to enhance retrieval recall by enabling approximate matching and omitting overly rare or domain-specific terms. This refinement step is done to improve the query coverage while maintaining relevance. Our experiments have shown that this process is required in less than 5% of the queries in the BioASQ 13 test set.", "We index all PubMed article titles and abstracts in an Elasticsearch instance, using BM25 retrieval as the ranking function. For each input question, we use Gemini 2.0 Flash to generate a structured Elasticsearch query that captures the semantic intent of the question using synonyms, related terms, and full boolean query string syntax rules supported by Elasticsearch. This query is validated using regular expressions and then is used to retrieve up to 10,000 documents.", "Following document retrieval, we apply a semantic reranking model (Google semantic-ranker-default004) to reduce the number of candidate documents [11]. This mannequin re-scores the initially retrieved paperwork based mostly on semantic similarity to the unique query, permitting us to pick the highest 300 most related paperwork. This reranked subset is used for downstream RAG-based QA, since regardless of actually lengthy context supported by fashionable Transformer architectures [12, 13], we couldn't get ample QA outcomes on full article abstracts with out this step.", "Lastly, we now have added further IR searches to deal with the instances the place a QA step doesn't return a response based mostly on the proof retrieved from Elasticsearch. We've noticed that Elasticsearch context may not present ample proof for QA in 3-7% of check instances for Part A+, relying on the batch. An automatic course of is used to increase IR sources to handle these instances. First, we're utilizing a Google search restricted to PubMed sources to try to search out new matches. If that fails, we lengthen our sources to incorporate House of the Workplace of Well being Promotion and Illness Prevention, WebMD,nnThis multi-stage retrieval method, combining LLM-generated queries, a standard BM25 search, and semantic reranking, allows versatile, high-recall, and high-precision doc choice tailor-made to advanced biomedical queries.", "Determine 1: IR processnnPubMed corpus in Elasticsearch Question Era (Gemini 2.0 Flash) Question Valida- tion and IR (BM25, ≤ 10,000 docs) Outcomes < Refinement 2.5 Professional) Reranking (semantic- reranker-4) Prime 300 Articles for RAG No Sure RefinennHealthline, and Wikipedia. This ensures that we now have a solution candidate for all questions in Part A+ check units.", "3.2. Query Answering PipelinennWe undertake a unified, zero-shot QA framework for each Part A+ and Part B of the problem. Whereas the core QA process stays constant throughout phases, Part A+ incorporates a further IR step to confirm the presence of candidate solutions inside related paperwork (described on the finish of Part 3.1). This ensures that chosen paperwork comprise ample data to assist reply era.", "To generate candidate solutions, we leverage a number of giant language fashions (LLMs): Gemini 2.0 Flash, Gemini 2.5 Flash Preview (2025-04-17), and Claude 3.7 Sonnet (2025-02-19). Prompts are adjusted utilizing examples derived from the BioASQ 11 check set, bettering the response construction and high quality.", "The system makes use of zero-shot prompting, tailor-made to the query kind: Sure/No, Factoid, or Checklist. We experiment with a number of sorts of enter context: (1) IR-derived outcomes from Part A+, (2) curated snippets supplied in Part B, and (3) full abstracts of articles chosen throughout Part B. This enables us to look at the affect of context granularity on reply accuracy and completeness.", "To consolidate candidate solutions, we carry out a secondary synthesis step utilizing Gemini 2.0 Flash. This mannequin is prompted to resolve any contradictions, choose essentially the most exact and particular reply parts, and combine complementary data right into a single, unified response. As a part of this step, the mannequin additionally returns a confidence rating estimating the reliability of the synthesized reply. If the rating is beneath a predefined threshold (0.5, decided empirically), the synthesis is re-run with diminished sampling temperature (from 0.1 to 0.0) to enhance determinism. This synthesis course of is evaluated utilizing the BioASQ 12 dataset to make sure consistency with benchmark requirements.", "Desk 1nnResults of our runs on BioASQ 13 Part A+, Sure/No questions.", "| | Batch | System | Accuracy | Rating |n|---:|:--------|:------------------|-----------:|----------:|n| 0 | 3 | Extractive | 0.73 | 41 |n| 1 | | (final) | 0.23 | 58 |n| 2 | 4 | Extractive | 0.92 | 1 |n| 3 | | Easy truncation | 0.88 | 11 |n| 4 | | Kmeans | 0.65 | 67 |n| 5 | | (final) | 0.65 | 67 |nnTable 2nnResults of our runs on BioASQ 13 Part A+, Factoid questions.", "| | Batch | System | MRR | Rating |n|---:|:--------|:------------------|------:|----------:|n| 0 | 3 | Extractive | 0.14 | 41 |n| 1 | | (final) | 0.05 | 47 |n| 2 | 4 | Extractive | 0.43 | 17 |n| 3 | | Easy truncation | 0.29 | 51 |n| 4 | | Kmeans | 0.05 | 62 |n| 5 | | (final) | 0.05 | 62 |", "2 Associated WorknnMedical Report Retrieval for Era. Present Medical MMRAG approaches primarily make the most of the medical photographs to retrieve related studies (He et al. 2024; Solar et al. 2025; Xia et al. 2024, 2025). As an example, FactMM-RAG (Solar et al. 2025) enhances report era by incorporating high-quality reference studies. Equally, RULE (Xia et al. 2024) and MMed-RAG (Xia et al. 2025) combine reference studies and make use of desire fine-tuning to enhance mannequin utilization of retrieved studies. Though these approaches enhance the factual accuracy of responses, they neglect the retrieval of medical paperwork, that are essential for Med-LVLM's dependable inference.", "Medical Doc Retrieval for Era. Acknowledging the constraints of report-only retrieval, latest research have more and more emphasised medical paperwork as information sources (Choi et al. 2025; Shaaban et al. 2025; Wu et al. 2025; Hamza et al. 2025). Amongst them, MKGF (Wu et al. 2025) and Ok-LLaVA (Hamza et al. 2025) each make use of multimodal retrievers to fetch paperwork from the database, aiming to mitigate hallucination points in language fashions. ChatCAD+ (Zhao et al. 2024b) and MIRA (Wang et al. 2025) make the most of a zero-shot question rewriting module for retrieval. However, these retrieval strategies overlook the substantial content material variations amongst varied corpora, missing corpus-specific retrieval mechanisms.", "6 ConclusionnnThis work addresses the important challenges of efficient retrieval and multi-aspect alignment for heterogeneous information within the Medical MMRAG area. MedAtlas offers a wealthy, multi-source information base for medical multimodal duties. The HeteroRAG framework allows exact report retrieval and multi-corpus retrieval, adopted by aligning heterogeneous retrieval outcomes by Heterogeneous Data Choice Tuning. In depth experiments display that our framework achieves state-of-the-art efficiency throughout a number of medical VQA and report era benchmarks. Our work paves the best way for successfully integrating multi-source medical information, advancing the reliability and applicability of Med-LVLMs in medical situations.", "2 Resultsnn2.3 High quality Evaluation of Extracted Relationship TriplesnnFor automated analysis, two state-of-the-art LLMs, GPT-4.1 [74] and DeepSeek-v3 [75], had been employed. A random subset comprising 1% of the abstracts (n = 34,725), leading to 83,438 extracted triples, was chosen for analysis. Every summary and its corresponding triples had been formatted into structured prompts and independently assessed by each fashions in accordance with a standardized four-tier rubric: Right (3.0), Probably Right (2.0), Probably Incorrect (1.0), and Incorrect (0.0) (the precise analysis immediate is illustrated in Prolonged Information Determine 3 a ). Triples receiving scores of ≥ 2 . 0 had been deemed legitimate. The analysis outcomes are introduced in Determine 3 a and b , illustrating the proportion of legitimate triples throughout relation sorts for GPT-4.1 and DeepSeek-v3, respectively. Each fashions demonstrated excessive total accuracy, with 85.44% and 88.10% of triples rated as legitimate bynn2 https://pubmed.ncbi.nlm.nih.gov/", "GPT-4.1 and DeepSeek-v3, respectively. For many relation sorts, validity was roughly 90%, apart from Adverse Correlate, which exhibited barely decrease settlement. These findings underscore the excessive precision of the Extractor Agent throughout various biomedical relation sorts and assist its utility for downstream analyses.", "In parallel, a guide analysis was performed to additional validate extraction accuracy. Three area consultants with doctoral-level coaching in synthetic intelligence and drugs independently reviewed a randomly chosen subset of 400 abstracts, comprising 1,060 extracted triples. Every summary and its related triples had been evaluated utilizing the identical standardized scoring rubric. Triples receiving scores of ≥ 2.0 had been thought of legitimate. As proven in Determine 3 c , all three reviewers demonstrated excessive consistency, with total validity charges exceeding 86% throughout assessors. The shut concordance between guide and automatic evaluations additional substantiates the robustness of the Extractor Agent in precisely capturing biomedical relationships, offering sturdy assist for the appliance of the extracted information in large-scale medical analyses.", "To additional validate the reliability of the LLM-based assessments, we used three skilled annotations as reference requirements to guage GPT-4.1 and DeepSeek-v3 on the identical subset of 400 abstracts, respectively. As proven in Determine 3 d -f , each fashions exhibited sturdy concordance with skilled evaluations, reaching precision, recall, and F1 scores of roughly 95% throughout metrics. These outcomes additional corroborate the accuracy of the automated scoring framework and its alignment with skilled judgment.", "Lastly, inter-rater settlement was assessed throughout all evaluators-including three human consultants and two LLMs-by computing pairwise Cohen's kappa coefficients on a shared analysis subset (Determine 3 g ) [82]. Most pairwise comparisons (80%) yielded kappa values exceeding 0.6, indicating substantial agreement-an accepted threshold for dependable concordance in domains involving subjective judgment, together with drugs, psychology, and pure language processing [83]. The coefficients between skilled 1 and skilled 2 (0.5663), and between skilled 2 and skilled 3 (0.5446), fell barely beneath this threshold however nonetheless mirrored reasonable settlement, intently approaching the substantial vary. These findings display sturdy inter-rater reliability throughout each human and automatic evaluators, underscoring the robustness and reproducibility of the analysis framework.", "2.4 Evaluating Downstream Utility in Medical Query AnsweringnnWe evaluated the downstream utility of our constructed KG as a RAG data supply throughout seven multiplechoice medical QA datasets. These included 4 extensively used benchmarks [76]-MMLU-Med, MedQA-US, PubMedQA*, and BioASQ-Y/N-spanning a broad spectrum of medical and biomedical reasoning duties. To additional assess diagnostic reasoning underneath various complexity, we introduce MedDDx, a newly developed benchmark suite targeted on differential prognosis [77]. Questions are stratified into three levels-MedDDx-Primary, MedDDxIntermediate, and MedDDx-Professional-based on the variance in semantic similarity amongst reply decisions. All MedDDx subsets had been designed to cut back coaching knowledge leakage and extra intently mirror genuine medical reasoning. Detailed dataset statistics are proven in Determine 4 a . We systematically evaluated 5 state-of-the-art LLMs to measure the influence of KG-based retrieval. Every mannequin was examined in a zero-shot setting underneath two circumstances: (1) direct answering utilizing inner information alone, and (2) RAG, with related KG subgraphs prepended as exterior context. The models-GPT-4-turbo, GPT-3.5-turbo (OpenAI) [78], DeepSeek-v3 (DeepSeek) [75], Qwen-Max, and Qwen-Plus (Qwen) [79]-span various architectures and coaching regimes, representing each proprietary and open-source programs. All fashions had been accessed through publicly out there APIs with out further fine-tuning. Model particulars and entry endpoints are summarized in Determine 4 b .", "Figures 4 c -i current mannequin efficiency throughout the seven medical QA datasets utilizing radar plots, every depicting the 5 LLMs underneath each direct answering (w/o RAG) and RAG circumstances (w/ RAG). Notably, the background shading within the radar plots is lighter for the MedDDx suite (Determine 4 g -i ) than for the 4 extensively used benchmarks (Determine 4 c -f ), reflecting the general decrease accuracy of all fashions on these lately launched and semantically tougher datasets. This distinction highlights the better complexity and diminished danger of coaching knowledge leakage inherent to the MedDDx design. Throughout all datasets, RAG with our KG constantly outperformed direct answering. Probably the most substantial enhancements had been noticed in duties requiring deeper medical reasoning, equivalent to MedQA-US and the MedDDx suite. For instance, on MedQA-US, GPT-3.5-turbo improved from 0.5986 to 0.6834 (+8.5 share factors), and Qwen-Max from 0.7306 to 0.7636. On MedDDx-Professional, RAG yielded absolute positive aspects of as much as +8.6 factors for GPT-3.5-turbo and +5.7 factors for Qwen-Max. Even in knowledge-intensive however semantically less complicated duties equivalent to MMLU-Med and BioASQ-Y/N, RAG supplied modest but constant advantages. On MMLU-Med, GPT-4-turbo improved from 0.8724 to 0.9054, whereas DeepSeek-v3 achieved the very best rating total at 0.9183 with KG assist. In BioASQ-Y/N, RAG additional enhanced already sturdy efficiency, with 4 fashions exceeding 0.85 accuracy following augmentation. Notably, a number of fashions carried out higher on MedDDx-Professional than on MedDDx-Primary, regardless of the previous being constructed with greater semantic complexity. This counterintuitive pattern could also be associated to variations in distractor framing, the place Professional-level distractors-", "Determine 4: Overview of analysis datasets, mannequin configurations, and efficiency throughout medical QA duties. a . Dataset statistics for the seven medical QA benchmarks used on this research. The benchmark suite contains 4 extensively adopted datasets [76] (MMLU-Med, MedQA-US, PubMedQA*, and BioASQ-Y/N) and three newly developed differential prognosis datasets [77] (MedDDx-Primary, MedDDx-Intermediate, and MedDDx-Professional). For every dataset, we report the variety of multiple-choice questions and the corresponding reply possibility codecs. b . Configuration of the 5 LLMs evaluated: GPT-4-turbo, GPT-3.5-turbo (OpenAI) [78], DeepSeek-v3 (DeepSeek) [75], Qwen-Max, and Qwen-Plus (Qwen) [79]. All fashions had been accessed by public APIs of their zero-shot settings with out fine-tuning. The particular model identifiers and entry platforms are indicated. c -i . Mannequin efficiency throughout the seven QA datasets, proven as radar plots. Every chart compares zero-shot accuracy for 5 LLMs underneath two circumstances: direct answering with out retrieval (w/o RAG) and RAG with our KG (w/ RAG). Throughout all datasets, RAG with our KG constantly outperformed direct answering.nnDatasets Dimension Choices MMLU-Med 1,089 A/B/C/D MedQA-US 1,273 PubMedQA* Sure/No/Possibly BioASQ-Y/N Sure/No MedDDx-Primary MedDDx-Intermediate 1,041 MedDDx-Professional Supplier Mannequin Model Accessed URL OpenAI GPT-4-turbonnhttps://platform.openai.com/docs/fashions/gpt-4-turbonnGPT-3.5-turbonnhttps://platform.openai.com/docs/fashions/gpt-3.5-turbonnDeepSeeknDeepSeek-v3", "https://huggingface.co/deepseek-ai/DeepSeek-V3nnQwennQwen-Maxnnhttps://www.alibabacloud.com/assist/en/model-nnstudio/what-is-qwen-llm Qwen-Plus b BioASQ-YIN w/o RAG RAG 0.9054 0.8130 0.5780 0.8625 0.5660 0,5720 0.5520 0.7401 0.7880 0.4940 0.831 0.5300 0.8953 0.8834 0.9183 0.8036 h wlo RAG 0.5197 0.5437 0,5714 0.5207 0.5347 0.4890 0,4265 506- 0.3685 0.4204 0,.4688 0.5020 0,4720 0.5259 0.4990 0.5043 0.5592 0,5878 0.8935 0.8576 7855| 0.8398 DeepSe -Max Search-v3 0,5135 ) 5673 0.5469 0.4700", "Determine 5: Case research of tocilizumab for literature-based discovery and drug repurposing inside the KG. a . Identified affiliation between tocilizumab and rheumatoid arthritis, supported by a number of publications, with the earliest reported date outlined by the primary extracted supporting paper. b . Two multi-hop reasoning paths linking tocilizumab to COVID-19 through intermediate genes FGB and TNF. The inferred Deal with relation (purple arrow) was derived solely from earlier literature, whereas later research validated this prediction (inexperienced arrow). The temporal order of proof highlights the KG's capability to anticipate therapeutic connections previous to their recognition within the literature.nntociliz-numabnnIdentifier:nnMESH:C502936nnEntity Kind:nnChemicalnnTerminology:nnNCBI MeSHnPage Linknn: meshb.nlm.nih.gov/document/ui?ui=C502936nnTreat Arthritis Rheum atoid MESH:D001172 Diseasenn: meshb.nlm.nih.gov/document/ui?ui=D001172nnConfidencen: 0.999999925nPubMed IDsnn:nn26374404,27958380,29146040,30859494,308nn88472,32844216,35713462,36688476nnEarliest Reported Daten: 2016-07-01nnmeshb.nlm.nih.gov/document/ui?ui=C502936nnFGB Gene Terminology NCBI Genenn: www.ncbi.nlm.nih.gov/gene/2244nnCOVID -19 Identifier : MESH:D000086382 : NCBI MeSHnnmeshb.nlm.nih.gov/document/ui?ui=D000086382nnTNF"],
"seed_texts": ["AbstractnnBiomedical question answering (QA) poses significant challenges due to the need for precise interpretation of specialized knowledge drawn from a vast, complex, and rapidly evolving corpus. In this work, we explore how large language models (LLMs) can be used for information retrieval (IR), and an ensemble of zero-shot models can accomplish state-of-the-art performance on a domain-specific Yes/No QA task. Evaluating our approach on the BioASQ challenge tasks, we show that ensembles can outperform individual LLMs and in some cases rival or surpass domain-tuned systems - all while preserving generalizability and avoiding the need for costly fine-tuning or labeled data. Our method aggregates outputs from multiple LLM variants, including models from Anthropic and Google, to synthesize more accurate and robust answers. Moreover, our investigation highlights a relationship between context length and performance: while expanded contexts are meant to provide valuable evidence, they simultaneously risk information dilution and model disorientation. These findings emphasize IR as a critical foundation in Retrieval-Augmented Generation (RAG) approaches for biomedical QA systems. Precise, focused retrieval remains essential for ensuring LLMs operate within relevant information boundaries when generating answers from retrieved documents. Our results establish that ensemble-based zero-shot approaches, when paired with effective RAG pipelines, constitute a practical and scalable alternative to domain-tuned systems for biomedical question answering.", "Finally, we have added additional IR searches to handle the cases where a QA step does not return a response based on the evidence retrieved from Elasticsearch. We have observed that Elasticsearch context might not provide sufficient evidence for QA in 3-7% of test cases for Phase A+, depending on the batch. An automated process is used to expand IR sources to address these cases. First, we are using a Google search restricted to PubMed sources to attempt to find new matches. If that fails, we extend our sources to include Home of the Office of Health Promotion and Disease Prevention, WebMD,nnThis multi-stage retrieval approach, combining LLM-generated queries, a traditional BM25 search, and semantic reranking, enables flexible, high-recall, and high-precision document selection tailored to complex biomedical queries.", "Medical Document Retrieval for Generation. Acknowledging the limitations of report-only retrieval, recent studies have increasingly emphasized medical documents as knowledge sources (Choi et al. 2025; Shaaban et al. 2025; Wu et al. 2025; Hamza et al. 2025). Among them, MKGF (Wu et al. 2025) and K-LLaVA (Hamza et al. 2025) both employ multimodal retrievers to fetch documents from the database, aiming to mitigate hallucination issues in language models. ChatCAD+ (Zhao et al. 2024b) and MIRA (Wang et al. 2025) utilize a zero-shot query rewriting module for retrieval. Nevertheless, these retrieval methods overlook the substantial content differences among various corpora, lacking corpus-specific retrieval mechanisms.", "6 ConclusionnnThis work addresses the critical challenges of effective retrieval and multi-aspect alignment for heterogeneous knowledge in the Medical MMRAG field. MedAtlas provides a rich, multi-source knowledge base for medical multimodal tasks. The HeteroRAG framework enables precise report retrieval and multi-corpus retrieval, followed by aligning heterogeneous retrieval results through Heterogeneous Knowledge Preference Tuning. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across multiple medical VQA and report generation benchmarks. Our work paves the way for effectively integrating multi-source medical knowledge, advancing the reliability and applicability of Med-LVLMs in clinical scenarios.", "2.4 Evaluating Downstream Utility in Medical Question AnsweringnnWe evaluated the downstream utility of our constructed KG as a RAG information source across seven multiplechoice medical QA datasets. These included four widely used benchmarks [76]-MMLU-Med, MedQA-US, PubMedQA*, and BioASQ-Y/N-spanning a broad spectrum of medical and biomedical reasoning duties. To additional assess diagnostic reasoning underneath various complexity, we introduce MedDDx, a newly developed benchmark suite targeted on differential prognosis [77]. Questions are stratified into three levels-MedDDx-Primary, MedDDxIntermediate, and MedDDx-Professional-based on the variance in semantic similarity amongst reply decisions. All MedDDx subsets had been designed to cut back coaching knowledge leakage and extra intently mirror genuine medical reasoning. Detailed dataset statistics are proven in Determine 4 a . We systematically evaluated 5 state-of-the-art LLMs to measure the influence of KG-based retrieval. Every mannequin was examined in a zero-shot setting underneath two circumstances: (1) direct answering utilizing inner information alone, and (2) RAG, with related KG subgraphs prepended as exterior context. The models-GPT-4-turbo, GPT-3.5-turbo (OpenAI) [78], DeepSeek-v3 (DeepSeek) [75], Qwen-Max, and Qwen-Plus (Qwen) [79]-span various architectures and coaching regimes, representing each proprietary and open-source programs. All fashions had been accessed through publicly out there APIs with out further fine-tuning. Model particulars and entry endpoints are summarized in Determine 4 b ."]Right here, the additional (full) context really incorporates the lacking proof which helped and due to this fact received a better rating than the seeds.
However frankly although I discover the reply is a bit lackluster nonetheless, there may be nothing all that attention-grabbing within the reply. However this factors to points on the retrieval facet although.
Lastly, examine a number of random ones and see how it’s evaluating these.
"query": "how do i measure if iu2019m getting various sources as a substitute of 10 chunks from the identical pdf",
"reply": "You possibly can deal with u201cdiverse sourcesu201d as one thing you measure immediately, not simply eyeball.nn1. Easy source-diversity rating (like within the paper)nIn Doc 1, they outline a retrieval range metric because the fraction of distinctive evaluation IDs among the many topu201110 chunks: Range = (variety of distinct IDs) / 10 [1].nYou can copy this concept for paperwork:n- Give each PDF (or doc) a singular ID.n- If you retrieve Ok chunks (say Ok=10), take a look at which doc every chunk got here from.n- Compute: Range = (variety of distinct doc IDs) / Ok.n u2022 If all 10 chunks come from the identical PDF, Range = 1 / 10 = 0.1 (very low).n u2022 If all 10 chunks come from totally different PDFs, Range = 10 / 10 = 1.0 (excellent range).nnYou can log this quantity for every question to watch whether or not youu2019re repeatedly pulling from the identical file or really spreading throughout your corpus.nn2. Mix with relevancenIn Doc 1, in addition they monitor how shut the chunks are to the question utilizing a mean cosine similarity between the question embedding and every chunk [1]. In observe you need each:n- Excessive similarity (onu2011topic).n- Excessive range (many alternative supply IDs).nn3. Optionally available: richer range laternDocument 2 reveals that range will also be measured at totally different ranges (lexical, semantic, ingredient) when you might have a number of outputs for one enter [2]. By analogy, as soon as youu2019re pleased with supply range, you could possibly later add:n- Semantic range between chunks (are they saying various things?).nBut the simplest start line is the per-query u2018distinct doc IDs / Ku2019 metric.",
"full_faithfulness": 0.8823529412000001,
"seed_faithfulness": 0.5294117647000001,
"answer_relevancy": 0.8588673985,
"context_relevance": 0.5303662744007874,
"context_relevance_reason": "The context passages present related details about measuring range in retrieval programs, notably within the context of recipe adaptation and LLMs. Nevertheless, whereas some passages focus on range metrics and retrieval strategies, they don't immediately tackle the consumer's particular query about measuring various sources versus a number of chunks from the identical PDF. The relevance of the context is considerably oblique, resulting in a reasonable rating.",
"hallucination_score": 0.7209711030557213,
"hallucination_reason": "The response successfully outlines a way for measuring supply range by introducing a easy source-diversity rating and offering a transparent method. It aligns properly with the context, which discusses retrieval range metrics. Nevertheless, whereas it mentions combining relevance with range, it doesn't explicitly join this to the context's concentrate on common cosine similarity, which may improve the completeness of the reply. General, the claims are largely supported, with minor gaps in direct references to the context."
"full_context": ["D. Question and Answering (QA)nnFor retrieval of reviews, we sampled five Spotify-centric queries and retrieved the top K = 10 review chunks for each. We measured two unsupervised metrics:nnAverage Cosine Similarity : the mean cosine similarity between each query embedding and its top-10 chunk embeddings.", "Retrieval Diversity : the fraction of unique review IDs among all retrieved chunks (distinct IDs / 10).nnOur retriever achieved perfect diversity and cosine scores from 0.618 to 0.754, demonstrating reliable, on-topic retrieval. Table IX summarizes these proxy metrics.", "For generation of answers, we randomly sampled 20 generated answers (each paired with its cited snippets) and annotated them ourselves, confirming that each answer (1) reflected the cited excerpts, (2) covered the main points of those excerpts, and (3) was written in clear, reader-friendly prose. We found the responses to be accurate and comprehensive.", "| | Query | Avg. Cosine Sim. | Diversity |n|---:|:-------------------------------------------------------------------------------|-------------------:|------------:|n| 0 | What complaints do users have about | 0.713 | 1 |n| 1 | What do listeners say about Spotify crashing or freezing on startup? | 0.754 | 1 |n| 2 | How do listeners describe the app's offline playback experience? | 0.696 | 1 |n| 3 | How do users report errors or failures when downloading songs for offline use? | 0.618 | 1 |n| 4 | What do users say about Spotify's crossfade and track-transition experience? | 0.65 | 1 |nnTABLE IX RETRIEVAL PROXY METRICS (K=10) FOR SELECTED SPOTIFY QUERIES (HIGHER DIVERSITY IS BETTER)", "2 Related WorknnRecipe Cross-Cultural Adaptation Recipe cross-cultural adaptation (Cao et al., 2024) involves modifying recipes to suit the dietary preferences and writing styles of the target culture. This includes not just translation, but also adjusting formats, ingredients, and cooking methods to align with cultural norms. Previous studies (Cao et al., 2024; Pandey et al., 2025; Zhang et al., 2024) often treat recipe adaptation as a cross-cultural translation task, exploring how prompt-based LLMs can be used for Chinese-English recipe adaptation.", "However, LLM-based recipe adaptation still faces challenges. Magomere et al.'s (2024) show that such methods can be misleading and may reinforce regional stereotypes. Hu et al.'s (2024) further identify two main challenges: First, LLMs lack culinary cultural knowledge, leading to insufficient cultural appropriateness. Second, the adapted recipes have quality issues, such as changing ingredients without adjusting the cooking steps accordingly. They propose another way to address these issues, namely through cross-cultural recipe retrieval, which sources recipes from real cooking practices within the target culture, generally offering better quality and cultural alignment. However, compared to directly using LLMs, the retrieved recipes often have low similarity to the original.", "All the above-mentioned studies primarily focus on the quality of generated results, including cultural appropriateness and their preservation of the original . However, they overlook the diversity of the results and do not explore the use of RAG for cross-cultural recipe adaptation. Our study emphasizes the trade-off between diversity and quality, with a particular focus on RAG-based approaches.", "Diversity in text generation, IR, and RAG Previous studies (Lanchantin et al., 2025) have shown that post-training LLMs tend to sharpen their output probability distribution, leading to reduced response diversity. This has raised a common concern about the insufficient diversity of LLMs, particularly in creative tasks. Several stochastic sampling-based decoding methods are widely used to control the level of diversity, most notably by adjusting hyperparameters such as temperature (Shi et al., 2024). However, these methods often still fall short in achieving sufficient diversity and may lead to a rapid decline in output quality, which is another important factor to consider when measuring diversity (Lanchantin et al., 2025).", "Figure 2: Overview of CARRIAGE . Diversity components are highlighted. We first enhance the diversity of retrieved results, then we enable more diverse use of contextual information via dynamic context selection, and inject contrastive context to prevent the LLM from generating outputs similar to previously generated recipes.nnMulti-Query Retrieval Source Culture Recipe Target Culture Diversity-aware Reranking Query Rewriting Dynamic Context Organization Pool of Previously Generated Recipes LLM Generation Contrastive Context Injection Previously : Diversity component Reference Recipes Selection Relevance DiversitynnMay generate multiple timesnnIn IR, retrieving text with high diversity can cover a wider range of subtopics, thereby accommodating the potentially diverse preferences of different users. Methods such as diverse query rewriting (Mohankumar et al., 2021) and diversity-aware re-ranking (Carbonell and Goldstein, 1998; Krestel and Fankhauser, 2012) can effectively enhance the diversity of retrieval results. Some recent works (Carraro and Bridge, 2024) have explored using LLMs to enhance diversity in re-ranking.", "In RAG, prior works have mainly focused on retrieving diverse results to obtain more comprehensive information, such as mitigating context window limitations (Wang et al., 2025) and addressing multi-hop question answering tasks (Rezaei and Dieng, 2025). These works are primarily framed as question answering, aiming to acquire comprehensive knowledge to produce a single correct answer. Consequently, the evaluation metrics emphasize answer accuracy rather than diversity. In contrast, our task naturally permits multiple valid answers. Therefore, we adopt different strategies to encourage answer diversity and use metrics that explicitly evaluate the diversity of final outputs. While prior works have largely focused on retrieving diverse contexts, our approach goes a step further by investigating how to utilize such diverse contexts to produce diverse outputs.", "5 MetricsnnOur evaluation metrics focus on two key aspects: diversity and quality . To assess diversity, we consider factors such as lexical , semantic , and ingredient diversity from a per-input perspective. As a trade-off, we evaluate quality from two dimensions: the preservation of the source recipe, and cultural appropriateness for users in the target culture.", "5.1 DiversitynnKirk et al.'s (2023) have proposed two paradigms for measuring diversity: across-input (over pairs of one input and one output) and per-input diversity (one input, several outputs). Per-input diversity helps us investigate whether a single recipe can be adapted into multiple variants to meet different dietary preferences, while across-input diversity assesses whether the generated recipes collectively exhibit a diverse range of linguistic patterns. Because our investigation primarily focuses on whether a single recipe can be adapted into diverse variations to meet a broader range of needs, we adopt the per-input diversity setting as our main experimental focus. The across-input diversity setting is discussed further in Section 7.", "For a diversity metric D , under model configuration c , A denotes a set of adapted recipes,", "containing N source recipes, we define A i c = { a i c, 1 , a i c, 2 , . . . , a i c,K } as the set of K adaptations for the i -th source recipe under configuration c . The per-input diversity is defined as follows:nnLexical Diversity Lexical diversity is a measure of the variety of vocabulary used within a set of text. High lexical diversity indicates using a broad range of unique words, which may correspond to a wider variety of ingredients, cooking methods, and flavors. We employ Unique-n (Johnson, 1944) to evaluate lexical diversity, calculated as the ratio of unique n -grams to the total number of n -grams, reflecting the proportion of distinct n -grams and indicates vocabulary richness. Following prior work (Guo et al., 2024), we report the average Unique-n across unigrams, bigrams, and trigrams.", "Semantic Diversity Semantic diversity refers to the variety of meanings within a set of texts. High semantic diversity suggests a wide range of culinary ideas. We measure per-input semantic diversity using the average pairwise cosine distance between Sentence-BERT embeddings because embedding-based semantic diversity enables a more fine-grained evaluation of variation beyond surface-level vocabulary (Stasaski and Hearst, 2023). Specifically, for a set of K adapted recipes, we define the sum of their average semantic similarity and semantic diversity to be 1. In this formulation, higher semantic similarity implies lower semantic diversity. We define semantic diversity, scaled to the range [0 , 1] , as follows:nnwhere e represents embeddings of the recipe.", "Ingredient Range Ingredient range measures the variation in units of substances throughout totally different recipes. Ingredient alternative performs a vital position in recipe range (Borghini, 2015). In comparison with basic lexical variation, ingredient modifications provide a extra exact sign for capturing the important thing components driving range in recipes.", "Recipes usually describe the identical ingredient in various methods, equivalent to variations in amount or models of measurement. To mitigate this, we introduce Commonplace Substances , which retain solely the ingredient identify by stripping away non-essential particulars. Since ingredient descriptions sometimes comply with the format < amount > < unit > < ingredient identify >, we extract solely the < ingredient identify > to compute ingredient range. The detailed process is supplied in Appendix B.", "To keep away from the affect of differing ingredient counts throughout recipes, we outline ingredient range because the ratio of distinctive standardized substances to the entire variety of substances. For a set of Ok tailored recipes, let the set of standardized substances for every recipe be I 1 , I 2 , . . . , I Ok . We outline ingredient range as follows:", "5.2 QualitynnWe outline computerized high quality metrics to function a trade-off when evaluating recipe range. Additional particulars on the coaching and analysis of the CultureScore mannequin are supplied in Appendix B.", "Supply Recipe Preservation Following prior work (Cao et al., 2024; Hu et al., 2024), we make use of BERTScore (Zhang* et al., 2020), a standard cosine embedding-based methodology for measuring the similarity between supply and output recipes. Earlier research have proven that BERTScore aligns properly with human evaluations by way of supply recipe preservation (Hu et al., 2024).", "Cultural Appropriateness We suggest a novel metric, the Recipe Cultural Appropriateness Rating (CultureScore), to evaluate how properly the output recipes align with the goal tradition. Particularly, we make use of a BERT-based classifier (Devlin et al., 2019; Cau00f1ete et al., 2020) to foretell the nation of origin of a recipe utilizing its title and listing of substances as enter. The CultureScore is outlined as the common predicted chance assigned by the mannequin to the goal tradition throughout all tailored recipes, with greater scores indicating higher cultural alignment. Since Latin American and Spanish recipes share the identical language, the mannequin can not depend on linguistic cues; as a substitute, it should study to tell apart them based mostly on culturally related options equivalent to substances, flavors, and writing kinds. On condition that the classification mannequin achieves an F1-score of over 90% in distinguishing between Latin American and Spanish recipes, we take into account CultureScore a dependable proxy for assessing cultural appropriateness.", "| | | Methodology. | Range ( u2191 ).Lexical | Range ( u2191 ).Ingredient | Range ( u2191 ).Semantic | High quality ( u2191 ).CultureScore | High quality ( u2191 ).BERTScore |n|---:|:------------------|:----------------------------------------------------------------------------|:--------------------------|:-----------------------------|:---------------------------|:-----------------------------|:--------------------------|n| 0 | Closed- Guide LLMs | Llama3.1-8B Qwen2.5-7B Gemma2-9B | 0.557 0.551 0.538 | 0.667 0.531 0.639 | 0.232 0.247 0.196 | 0.451 0.404 0.468 | 0.404 0.439 0.370 |n| 1 | IR | JINA-ES CARROT CARROT-MMR | 0.742 0.735 0.741 | 0.937 0.925 0.941 | 0.459 0.462 0.527 | 0.511 0.512 0.503 | 0.295 0.301 0.298 |n| 2 | RAG | Vanilla-LLaMA RAG CARROT-LLaMA RAG CARROT-MMR-LLaMA RAG CARROT-MMR-Qwen RAG | 0.518 0.525 0.520 0.532 | 0.748 0.765 0.748 0.536 | 0.155 0.152 0.164 0.212 | 0.383 0.385 0.393 0.402 | 0.551 0.545 0.545 0.448 |n| 3 | Ours | CARRIAGE -LLaMA CARRIAGE -Qwen | 0.577 0.628 | 0.739 0.676 | 0.269 0.303 | 0.463 0.590 | 0.442 0.342 |", "Desk 1: Analysis of range and high quality on the RecetasDeLaAbuel@ dataset reveals that our proposed CARRIAGE -LLaMA outperforms all closed-book LLMs by way of Pareto effectivity throughout each range and high quality metrics. In distinction, IR-based strategies wrestle with preserving the supply recipe, whereas different RAG-based approaches are inclined to underperform by way of range and cultural appropriateness."This above is attention-grabbing as you see that the evaluator is taking an inexpensive generalization and treats it as “kinda supported” or “meh.”
Evaluating this merchandise above with one other LLM, it mentioned that it thought the context relevance remark was a bit whiny.
However as you see, low scores don’t need to imply that the system is dangerous. It’s a must to study why they’re low and in addition why they’re excessive to know how the decide works or why the pipeline is failing.
A great instance is context relevance right here. Context relevance is measuring how a lot of the retrieved context was helpful. Should you’re doing neighbor growth, you’ll nearly at all times pull in some irrelevant textual content, so context precision will look worse, particularly if the corpus can’t reply the query within the first place.
The query is whether or not the additional context really helps grounding (faithfulness / hallucination price) sufficient to be well worth the noise.
Some cautious notes
Okay, some notes earlier than I spherical this off.
Testing seeds right here is clearly biased, and it doesn’t inform us whether or not they had been really helpful on their very own. We’d need to construct two totally different pipelines and evaluate them facet by facet to say that correctly.
I’ll attempt to do that sooner or later, with this actual makes use of case.
I also needs to notice that the system has only a few docs within the pipeline: solely about 150 PDF recordsdata together with some Excel recordsdata, which is a number of thousand pages. However I’ve to demo this in public, and this was the one approach.
Keep in mind we used solely metrics on the era facet right here, wanting on the context that was retrieved. If the context retrieved is mendacity or has conflicting data, these metrics might not present it, it’s important to measure that earlier than.
Moreover many groups additionally construct their very own customized metrics, that’s distinctive to their pipeline and to what they need to check, and even in case you begin like this, with basic ones, you’ll be able to spot what you want alongside the road to construct higher focused ones.
The very last thing to notice is LLM decide bias. I’m utilizing OpenAI fashions each for the RAG pipeline and for the evaluator. That is usually not beneficial, however so long as the fashions are totally different from the generator and decide it’s usually accepted.
Hopefully it was a enjoyable learn (in case you’re a dork about knowledge like me).
Keep tuned for the final article the place I attempt to check a extra naive pipeline in opposition to this one (hopefully I’ve time to complete it).
If you wish to keep up to date or simply join you’ll discover me at LinkedIn, my web site, or Medium (and right here too).
❤
















{kind=link}