


Neural Community Regressor, we now transfer to the classifier model.
From a mathematical viewpoint, the 2 fashions are very comparable. In reality, they differ primarily by the interpretation of the output and the selection of the loss perform.
Nonetheless, this classifier model is the place instinct normally turns into a lot stronger.
In observe, neural networks are used much more typically for classification than for regression. Pondering by way of possibilities, resolution boundaries, and lessons makes the function of neurons and layers simpler to understand.
On this article, you will note:
- how you can outline the construction of a neural community in an intuitive manner,
- why the variety of neurons issues,
- and why a single hidden layer is already ample, a minimum of in principle.
At this level, a pure query arises:
If one hidden layer is sufficient, why will we speak a lot about deep studying?
The reply is essential.
Deep studying is not nearly stacking many hidden layers on prime of one another. Depth helps, however it’s not the entire story. What actually issues is how representations are constructed, reused, and constrained, and why deeper architectures are extra environment friendly to coach and generalize in observe.
We are going to come again to this distinction later. For now, we intentionally maintain the community small, so that each computation may be understood, written, and checked by hand.
That is one of the simplest ways to actually perceive how a neural community classifier works.
As with the neural community regressor we constructed yesterday, we’ll cut up the work into two elements.
First, we have a look at ahead propagation and outline the neural community as a set mathematical perform that maps inputs to predicted possibilities.
Then, we transfer to backpropagation, the place we practice this perform by minimizing the log loss utilizing gradient descent.
The ideas are precisely the identical as earlier than. Solely the interpretation of the output and the loss perform change.
1. Ahead propagation
On this part, we give attention to just one factor: the mannequin itself. No coaching but. Simply the perform.
1.1 A easy dataset and the instinct of constructing a perform
We begin with a really small dataset:
- 12 observations
- One single characteristic x
- A binary goal y
The dataset is deliberately easy so that each computation may be adopted manually. Nonetheless, it has one essential property: the lessons are not linearly separable.
Which means that a easy logistic regression can not resolve the issue, no matter how properly it’s educated.

Nonetheless, the instinct is exactly the other of what it might appear at first.
What we’re going to do is construct two logistic regressions first. Every one creates a reduce within the enter house, as illustrated beneath.
In different phrases, we begin with one single characteristic, and we remodel it into two new options.

Then, we apply one other logistic regression, this time on these two options, to acquire the ultimate output likelihood.
When written as a single mathematical expression, the ensuing perform is already a bit advanced to learn. That is precisely why we use a diagram: not as a result of the diagram is extra correct, however as a result of it’s simpler to know how the perform is constructed by composition.

1.2 Neural Community Construction
So the visible diagram represents the next mannequin:
- One hidden layer with two neurons within the hidden layer, which permits us to characterize the 2 cuts we observe within the dataset
- One output neuron, and it’s a logistic regression right here.

In our case, the mannequin depends upon seven coefficients:
- Weights and biases for the 2 hidden neurons
- Weights and bias for the output neuron
Taken collectively, these seven numbers absolutely outline the mannequin.
Now, when you already perceive how a neural community classifier works, here’s a query for you:
What number of completely different options can this mannequin have?
In different phrases, what number of distinct units of seven coefficients can produce the identical classification boundary, or nearly the identical predicted possibilities, on this dataset?
1.3 Implementing ahead propagation in Excel
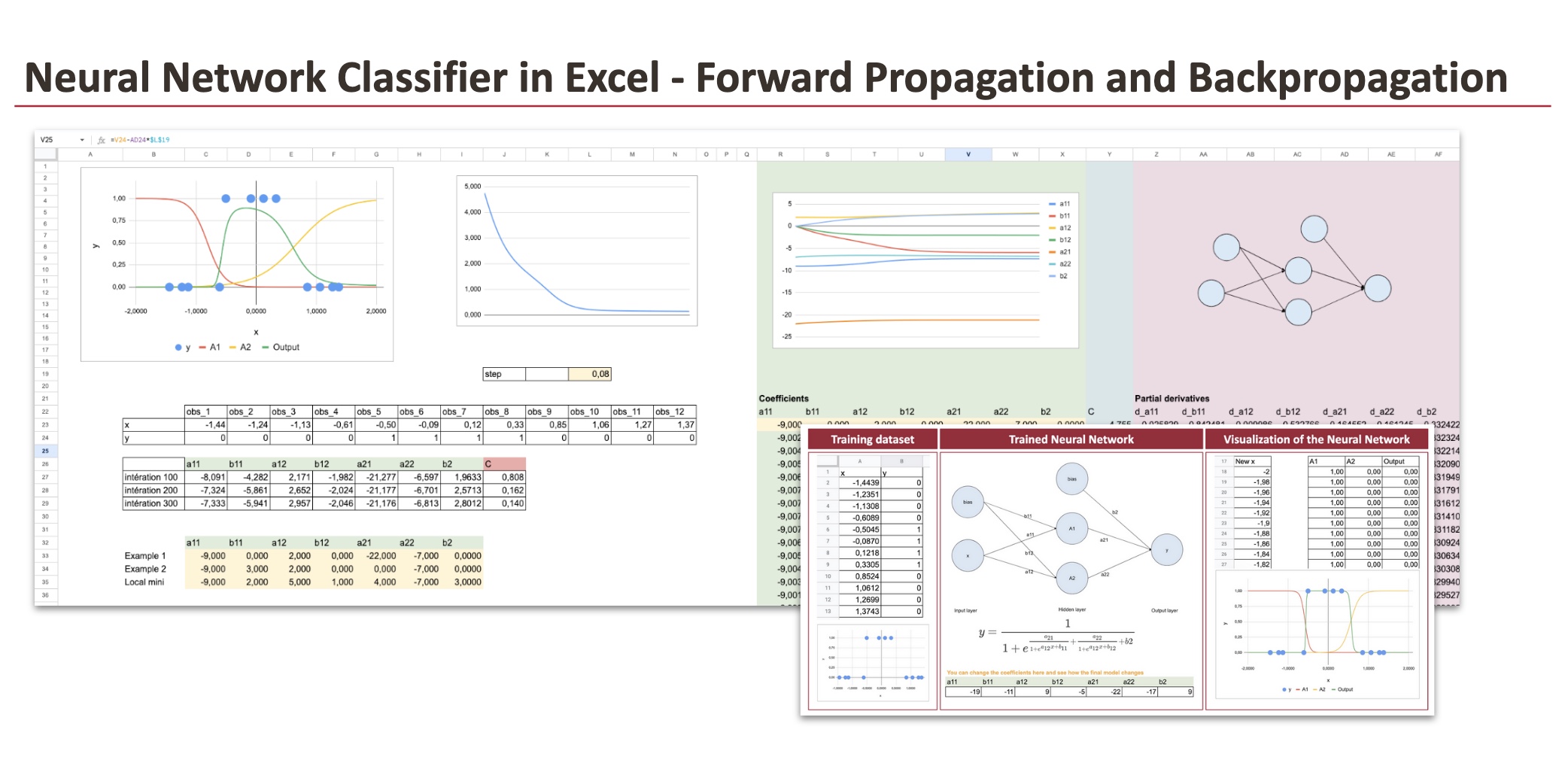
We now implement the mannequin utilizing Excel formulation.
To visualise the output of the neural community, we generate new values of x starting from −2 to 2 with a step of 0.02.
For every worth of x, we compute:
- The outputs of the 2 hidden neurons (A1 and A2)
- The ultimate output of the community
At this stage, the mannequin will not be educated but. We due to this fact want to repair the seven parameters of the community. For now, we merely use a set of cheap values, proven beneath, which permits us to visualise the ahead propagation of the mannequin.
It is only one potential configuration of the parameters. Even earlier than coaching, this already raises an attention-grabbing query: what number of completely different parameter configurations may produce a sound resolution for this downside?

We are able to use the next equations to compute the values of the hidden layers and the output.

The intermediate values A1 and A2 are displayed explicitly. This avoids massive, unreadable formulation and makes the ahead propagation straightforward to observe.

The dataset has been efficiently divided into two distinct lessons utilizing the neural community.

1.4 Ahead propagation: abstract and observations
To recap, we began with a easy coaching dataset and outlined a neural community as an specific mathematical perform, carried out utilizing easy Excel formulation and a set set of coefficients. By feeding new values of xxx into this perform, we have been in a position to visualize the output of the neural community and observe the way it separates the information.

Now, when you look intently on the shapes produced by the hidden layer, which comprises the 2 logistic regressions, you possibly can see that there are 4 potential configurations. They correspond to the completely different potential orientations of the slopes of the 2 logistic capabilities.
Every hidden neuron can have both a optimistic or a destructive slope. With two neurons, this results in 2×2=4 potential combos. These completely different configurations can produce very comparable resolution boundaries on the output, though the underlying parameters are completely different.
This explains why the mannequin can admit a number of options for a similar classification downside.

The more difficult half is now to find out the values of those coefficients.
That is the place backpropagation comes into play.
2. Backpropagation: coaching the neural community with gradient descent
As soon as the mannequin is outlined, coaching turns into a numerical downside.
Regardless of its title, backpropagation will not be a separate algorithm. It’s merely gradient descent utilized to a composed perform.
2.1 Reminder of the backpropagation algorithm
The precept is identical for all weight-based fashions.
We first outline the mannequin, that’s, the mathematical perform that maps the enter to the output.
Then we outline the loss perform. Since it is a binary classification activity, we use log loss, precisely as in logistic regression.
Lastly, with the intention to study the coefficients, we compute the partial derivatives of the loss with respect to every coefficient of the mannequin. These derivatives are what permit us to replace the parameters utilizing gradient descent.
Beneath is a screenshot displaying the ultimate formulation for these partial derivatives.

The backpropagation algorithm can then be summarized as follows:
- Initialize the weights of the neural community randomly.
- Feedforward the inputs by the neural community to get the anticipated output.
- Calculate the error between the anticipated output and the precise output.
- Backpropagate the error by the community to calculate the gradient of the loss perform with respect to the weights.
- Replace the weights utilizing the calculated gradient and a studying price.
- Repeat steps 2 to five till the mannequin converges.
2.2 Initialization of the coefficients
The dataset is organized in columns to make Excel formulation straightforward to increase.

The coefficients are initialized with particular values right here. You possibly can change them, however convergence will not be assured. Relying on the initialization, the gradient descent could converge to a special resolution, converge very slowly, or fail to converge altogether.

2.3 Ahead propagation
Within the columns from AG to BP, we implement the ahead propagation step. We first compute the 2 hidden activations A1 and A2, after which the output of the community. These are precisely the identical formulation as these used earlier to outline the ahead propagation of the mannequin.
To maintain the computations readable, we course of every statement individually. Because of this, we’ve got 12 columns for the hidden layer outputs (A1 and A2) and 12 columns for the output layer.
As an alternative of writing a single summation system, we compute the values statement by statement. This avoids very massive and hard-to-read formulation, and it makes the logic of the computations a lot clearer.
This column-wise group additionally makes it straightforward to imitate a for-loop throughout gradient descent: the formulation can merely be prolonged by row to characterize successive iterations.

2.4 Errors and the price perform
Within the columns from BQ to CN, we compute the error phrases and the values of the price perform.
For every statement, we consider the log loss primarily based on the anticipated output and the true label. These particular person losses are then mixed to acquire the whole value for the every iteration.

2.5 Partial derivatives
We now transfer to the computation of the partial derivatives.
The neural community has 7 coefficients, so we have to compute 7 partial derivatives, one for every parameter. For every spinoff, the computation is completed for all 12 observations, which ends up in a complete of 84 intermediate values.
To maintain this manageable, the sheet is rigorously organized. The columns are grouped and color-coded so that every spinoff may be adopted simply.
Within the columns from CO to DL, we compute the partial derivatives related to a11 and a12.

Within the columns from DM to EJ, we compute the partial derivatives related to b11 and b12.

Within the columns from EK to FH, we compute the partial derivatives related to a21 and a22.

Within the columns from FI to FT, we compute the partial derivatives related to b2.

And to wrap it up, we sum the partial derivatives throughout the 12 observations.
The ensuing gradients are grouped and proven within the columns from Z to FI.

2.6 Updating weights in a for loop
These partial derivatives permit us to carry out gradient descent for every coefficient. The updates are computed within the columns from R to X.
At every iteration, we are able to observe how the coefficients evolve. The worth of the price perform is proven in column Y, which makes it straightforward to see whether or not the descent is working and whether or not the loss is lowering.

After updating the coefficients at every step of the for loop, we recompute the output of the neural community.

If the preliminary values of the coefficients are poorly chosen, the algorithm could fail to converge or could converge to an undesired resolution, even with an inexpensive step dimension.

The GIF beneath exhibits the output of the neural community at every iteration of the for loop. It helps visualize how the mannequin evolves throughout coaching and the way the choice boundary step by step converges towards an answer.

Conclusion
We’ve got now accomplished the complete implementation of a neural community classifier, from ahead propagation to backpropagation, utilizing solely specific formulation.
By constructing the whole lot step-by-step, we’ve got seen {that a} neural community is nothing greater than a mathematical perform, educated by gradient descent. Ahead propagation defines what the mannequin computes. Backpropagation tells us how you can alter the coefficients to cut back the loss.
This file permits you to experiment freely: you possibly can change the dataset, modify the preliminary values of the coefficients, and observe how the coaching behaves. Relying on the initialization, the mannequin could converge shortly, converge to a special resolution, or get caught in a neighborhood minimal.
By means of this train, the mechanics of neural networks grow to be concrete. As soon as these foundations are clear, utilizing high-level libraries feels a lot much less opaque, as a result of you realize precisely what is occurring behind the scenes.
Additional Studying
Thanks on your help for my Machine Studying “Creation Calendar“.
Folks normally speak loads about supervised studying, unsupervised studying is typically ignored, though it may be very helpful in lots of conditions. These articles particularly discover these approaches.
Thanks, and comfortable studying.
https://towardsdatascience.com/the-machine-learning-advent-calendar-day-5-gmm-in-excel/
https://towardsdatascience.com/the-machine-learning-advent-calendar-day-10-dbscan-in-excel/
https://towardsdatascience.com/the-machine-learning-advent-calendar-day-9-lof-in-excel/














{kind=link}