



On this article, you’ll learn to flip a uncooked time sequence right into a supervised studying dataset and use determination tree-based fashions to forecast future values.
Subjects we’ll cowl embody:
- Engineering lag options and rolling statistics from a univariate sequence.
- Making ready a chronological prepare/check break up and becoming a choice tree regressor.
- Evaluating with MAE and avoiding information leakage with correct function design.
Let’s not waste any extra time.

Forecasting the Future with Tree-Primarily based Fashions for Time Collection
Picture by Editor
Introduction
Resolution tree-based fashions in machine studying are regularly used for a variety of predictive duties resembling classification and regression, sometimes on structured, tabular information. Nonetheless, when mixed with the suitable information processing and have extraction approaches, determination timber additionally turn into a robust predictive device for different information codecs like textual content, photos, or time sequence.
This text demonstrates how determination timber can be utilized to carry out time sequence forecasting. Extra particularly, we present find out how to extract important options from uncooked time sequence — resembling lagged options and rolling statistics — and leverage this structured data to carry out the aforementioned predictive duties by coaching determination tree-based fashions.
Constructing Resolution Timber for Time Collection Forecasting
On this hands-on tutorial, we’ll use the month-to-month airline passengers dataset accessible without spending a dime within the sktime library. It is a small univariate time sequence dataset containing month-to-month passenger numbers for an airline listed by year-month, between 1949 and 1960.
Let’s begin by loading the dataset — it’s possible you’ll must pip set up sktime first if you happen to haven’t used the library earlier than:
|
import pandas as pd from sktime.datasets import load_airline
y = load_airline() y.head() |
Since it is a univariate time sequence, it’s managed as a one-dimensional pandas Collection listed by date (month-year), somewhat than a two-dimensional DataFrame object.
To extract related options from our time sequence and switch it into a totally structured dataset, we outline a customized operate referred to as make_lagged_df_with_rolling, which takes the uncooked time sequence as enter, plus two key phrase arguments: lags and roll_window, which we’ll clarify shortly:
|
def make_lagged_df_with_rolling(sequence, lags=12, roll_window=3): df = pd.DataFrame({“y”: sequence})
for lag in vary(1, lags+1): df[f“lag_{lag}”] = df[“y”].shift(lag)
df[f“roll_mean_{roll_window}”] = df[“y”].shift(1).rolling(roll_window).imply() df[f“roll_std_{roll_window}”] = df[“y”].shift(1).rolling(roll_window).std()
return df.dropna()
df_features = make_lagged_df_with_rolling(y, lags=12, roll_window=3) df_features.head() |
Time to revisit the above code and see what occurred contained in the operate:
- We first pressure our univariate time sequence to turn into a pandas
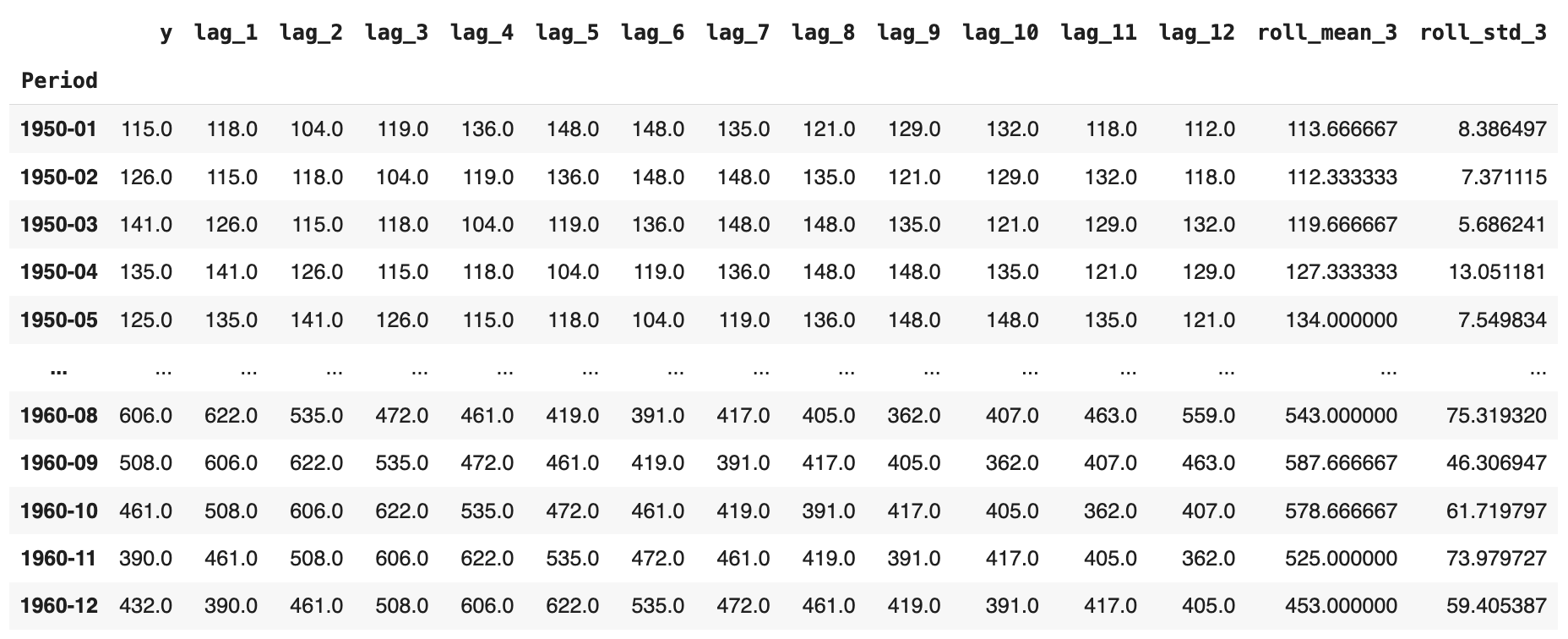
DataFrame, as we’ll shortly broaden it with a number of extra options. - We incorporate lagged options; i.e., given a particular passenger worth at a timestamp, we gather the earlier values from previous months. In our state of affairs, at time t, we embody all consecutive readings from t-1 as much as t-12 months earlier, as proven within the picture under. For January 1950, as an illustration, now we have each the unique passenger numbers and the equal values for the earlier 12 months added throughout 12 extra attributes, in reverse temporal order.
- Lastly, we add two extra attributes containing the rolling common and rolling normal deviation, respectively, spanning three months. That’s, given a month-to-month studying of passenger numbers, we calculate the typical or normal deviation of the most recent n = 3 months excluding the present month (see using
.shift(1)earlier than the.rolling()name), which prevents look-ahead leakage.
The ensuing enriched dataset ought to seem like this:
After that, coaching and testing the choice tree is easy and finished as ordinary with scikit-learn fashions. The one side to remember is: what shall be our goal variable to foretell? In fact, we wish to forecast “unknown” values of passenger numbers at a given month based mostly on the remainder of the options extracted. Subsequently, the unique time sequence variable turns into our goal label. Additionally, be sure you select the DecisionTreeRegressor, as we’re centered on numerical predictions on this state of affairs, not classifications:
Partitioning the dataset into coaching and check, and separating the labels from predictor options:
|
train_size = int(len(df_features) * 0.8) prepare, check = df_features.iloc[:train_size], df_features.iloc[train_size:]
X_train, y_train = prepare.drop(“y”, axis=1), prepare[“y”] X_test, y_test = check.drop(“y”, axis=1), check[“y”] |
Coaching and evaluating the choice tree error (MAE):
|
from sklearn.tree import DecisionTreeRegressor from sklearn.metrics import mean_absolute_error
dt_reg = DecisionTreeRegressor(max_depth=5, random_state=42) dt_reg.match(X_train, y_train) y_pred = dt_reg.predict(X_test)
print(“Forecasting:”) print(“MAE:”, mean_absolute_error(y_test, y_pred)) |
In a single run, the ensuing error was MAE ≈ 45.32. That isn’t dangerous, contemplating that month-to-month passenger numbers within the dataset are within the a number of a whole bunch; after all, there may be room for enchancment by utilizing ensembles, extracting extra options, tuning hyperparameters, or exploring different fashions.
A remaining takeaway: in contrast to conventional time sequence forecasting strategies, which predict a future or unknown worth based mostly solely on previous values of the identical variable, the choice tree we constructed predicts that worth based mostly on different options we created. In observe, it’s typically efficient to mix each approaches with two completely different mannequin varieties to acquire extra sturdy predictions.
Wrapping Up
This text confirmed find out how to prepare determination tree fashions able to coping with time sequence information by extracting options from them. Beginning with a uncooked univariate time sequence of month-to-month passenger numbers for an airline, we extracted lagged options and rolling statistics to behave as predictor attributes and carried out forecasting through a educated determination tree.
On this article, you’ll learn to flip a uncooked time sequence right into a supervised studying dataset and use determination tree-based fashions to forecast future values.
Subjects we’ll cowl embody:
- Engineering lag options and rolling statistics from a univariate sequence.
- Making ready a chronological prepare/check break up and becoming a choice tree regressor.
- Evaluating with MAE and avoiding information leakage with correct function design.
Let’s not waste any extra time.
Forecasting the Future with Tree-Primarily based Fashions for Time Collection
Picture by Editor
Introduction
Resolution tree-based fashions in machine studying are regularly used for a variety of predictive duties resembling classification and regression, sometimes on structured, tabular information. Nonetheless, when mixed with the suitable information processing and have extraction approaches, determination timber additionally turn into a robust predictive device for different information codecs like textual content, photos, or time sequence.
This text demonstrates how determination timber can be utilized to carry out time sequence forecasting. Extra particularly, we present find out how to extract important options from uncooked time sequence — resembling lagged options and rolling statistics — and leverage this structured data to carry out the aforementioned predictive duties by coaching determination tree-based fashions.
Constructing Resolution Timber for Time Collection Forecasting
On this hands-on tutorial, we’ll use the month-to-month airline passengers dataset accessible without spending a dime within the sktime library. It is a small univariate time sequence dataset containing month-to-month passenger numbers for an airline listed by year-month, between 1949 and 1960.
Let’s begin by loading the dataset — it’s possible you’ll must pip set up sktime first if you happen to haven’t used the library earlier than:
|
import pandas as pd from sktime.datasets import load_airline
y = load_airline() y.head() |
Since it is a univariate time sequence, it’s managed as a one-dimensional pandas Collection listed by date (month-year), somewhat than a two-dimensional DataFrame object.
To extract related options from our time sequence and switch it into a totally structured dataset, we outline a customized operate referred to as make_lagged_df_with_rolling, which takes the uncooked time sequence as enter, plus two key phrase arguments: lags and roll_window, which we’ll clarify shortly:
|
def make_lagged_df_with_rolling(sequence, lags=12, roll_window=3): df = pd.DataFrame({“y”: sequence})
for lag in vary(1, lags+1): df[f“lag_{lag}”] = df[“y”].shift(lag)
df[f“roll_mean_{roll_window}”] = df[“y”].shift(1).rolling(roll_window).imply() df[f“roll_std_{roll_window}”] = df[“y”].shift(1).rolling(roll_window).std()
return df.dropna()
df_features = make_lagged_df_with_rolling(y, lags=12, roll_window=3) df_features.head() |
Time to revisit the above code and see what occurred contained in the operate:
- We first pressure our univariate time sequence to turn into a pandas
DataFrame, as we’ll shortly broaden it with a number of extra options. - We incorporate lagged options; i.e., given a particular passenger worth at a timestamp, we gather the earlier values from previous months. In our state of affairs, at time t, we embody all consecutive readings from t-1 as much as t-12 months earlier, as proven within the picture under. For January 1950, as an illustration, now we have each the unique passenger numbers and the equal values for the earlier 12 months added throughout 12 extra attributes, in reverse temporal order.
- Lastly, we add two extra attributes containing the rolling common and rolling normal deviation, respectively, spanning three months. That’s, given a month-to-month studying of passenger numbers, we calculate the typical or normal deviation of the most recent n = 3 months excluding the present month (see using
.shift(1)earlier than the.rolling()name), which prevents look-ahead leakage.
The ensuing enriched dataset ought to seem like this:
After that, coaching and testing the choice tree is easy and finished as ordinary with scikit-learn fashions. The one side to remember is: what shall be our goal variable to foretell? In fact, we wish to forecast “unknown” values of passenger numbers at a given month based mostly on the remainder of the options extracted. Subsequently, the unique time sequence variable turns into our goal label. Additionally, be sure you select the DecisionTreeRegressor, as we’re centered on numerical predictions on this state of affairs, not classifications:
Partitioning the dataset into coaching and check, and separating the labels from predictor options:
|
train_size = int(len(df_features) * 0.8) prepare, check = df_features.iloc[:train_size], df_features.iloc[train_size:]
X_train, y_train = prepare.drop(“y”, axis=1), prepare[“y”] X_test, y_test = check.drop(“y”, axis=1), check[“y”] |
Coaching and evaluating the choice tree error (MAE):
|
from sklearn.tree import DecisionTreeRegressor from sklearn.metrics import mean_absolute_error
dt_reg = DecisionTreeRegressor(max_depth=5, random_state=42) dt_reg.match(X_train, y_train) y_pred = dt_reg.predict(X_test)
print(“Forecasting:”) print(“MAE:”, mean_absolute_error(y_test, y_pred)) |
In a single run, the ensuing error was MAE ≈ 45.32. That isn’t dangerous, contemplating that month-to-month passenger numbers within the dataset are within the a number of a whole bunch; after all, there may be room for enchancment by utilizing ensembles, extracting extra options, tuning hyperparameters, or exploring different fashions.
A remaining takeaway: in contrast to conventional time sequence forecasting strategies, which predict a future or unknown worth based mostly solely on previous values of the identical variable, the choice tree we constructed predicts that worth based mostly on different options we created. In observe, it’s typically efficient to mix each approaches with two completely different mannequin varieties to acquire extra sturdy predictions.
Wrapping Up
This text confirmed find out how to prepare determination tree fashions able to coping with time sequence information by extracting options from them. Beginning with a uncooked univariate time sequence of month-to-month passenger numbers for an airline, we extracted lagged options and rolling statistics to behave as predictor attributes and carried out forecasting through a educated determination tree.

















{kind=link}