


In the present day, MLCommons introduced new outcomes for the MLPerf Coaching v5.1 benchmark suite, highlighting the speedy evolution and growing richness of the AI ecosystem in addition to vital efficiency enhancements from new generations of programs.
Go right here to view the total outcomes for MLPerf Coaching v5.1 and discover extra details about the benchmarks.
The MLPerf Coaching benchmark suite contains full system checks that stress fashions, software program, and {hardware} for a spread of machine studying (ML) functions. The open-source and peer-reviewed benchmark suite offers a degree taking part in discipline for competitors that drives innovation, efficiency, and power effectivity for the whole trade.
Model 5.1 set new information for variety of the programs submitted. Contributors on this spherical of the benchmark submitted 65 distinctive programs, that includes 12 totally different {hardware} accelerators and a wide range of software program frameworks. Almost half of the submissions had been multi-node, which is an 86 % improve from the model 4.1 spherical one yr in the past. The multi-node submissions employed a number of totally different community architectures, many incorporating customized options.
This spherical recorded substantial efficiency enhancements over the model 5.0 outcomes for 2 benchmark checks centered on generative AI situations, outpacing the speed of enchancment predicted by Moore’s Regulation.
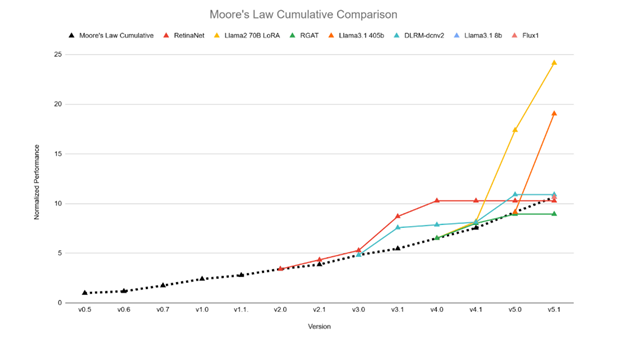
Relative efficiency enhancements throughout the MLPerf Coaching benchmarks, normalized to the Moore’s Regulation trendline on the time limit when every benchmark was launched. (Supply: MLCommons)
“Extra selections of {hardware} programs enable clients to check programs on state-of-the-art MLPerf benchmarks and make knowledgeable shopping for selections,” stated Shriya Rishab, co-chair of the MLPerf Coaching working group. “{Hardware} suppliers are utilizing MLPerf as a solution to showcase their merchandise in multi-node settings with nice scaling effectivity, and the efficiency enhancements recorded on this spherical exhibit that the colourful innovation within the AI ecosystem is making a giant distinction.”
The MLPerf Coaching v5.1 spherical consists of efficiency outcomes from 20 submitting organizations: AMD, ASUSTeK, Cisco, Datacrunch, Dell, Giga Computing, HPE, Krai, Lambda, Lenovo, MangoBoost, MiTAC, Nebius, NVIDIA, Oracle, Quanta Cloud Expertise, Supermicro, Supermicro + MangoBoost, College of Florida, Wiwynn. “We might particularly wish to welcome first-time MLPerf Coaching submitters, Datacrunch, College of Florida, and Wiwynn” stated David Kanter, Head of MLPerf at MLCommons.
The sample of submissions additionally exhibits an growing emphasis on benchmarks centered on generative AI (genAI) duties, with a 24 % improve in submissions for the Llama 2 70B LoRA benchmark, and a 15 % improve for the brand new Llama 3.1 8B benchmark over the take a look at it changed (BERT). “Taken collectively, the elevated submissions to genAI benchmarks and the sizable efficiency enhancements recorded in these checks make it clear that the group is closely centered on genAI situations, to some extent on the expense of different potential functions of AI expertise,” stated Kanter. “We’re proud to be delivering these sorts of key insights into the place the sector is headed that enable all stakeholders to make extra knowledgeable selections.”
Sturdy participation by a broad set of trade stakeholders strengthens the AI ecosystem as a complete and helps to make sure that the benchmark is serving the group’s wants. We invite submitters and different stakeholders to hitch the MLPerf Coaching working group and assist us proceed to evolve the benchmark.
MLPerf Coaching v5.1 Updates 2 Benchmarks
The gathering of checks within the suite is curated to maintain tempo with the sector, with particular person checks added, up to date, or eliminated as deemed obligatory by a panel of consultants from the AI group.
Within the 5.1 benchmark launch, two earlier checks had been changed with new ones that higher symbolize the state-of-the-art expertise options for a similar activity. Particularly: Llama 3.1 8B replaces BERT; and Flux.1 replaces Steady Diffusion v2.
Llama 3.1 8B is a benchmark take a look at for pretraining a big language mannequin (LLM). It belongs to the identical “herd” of fashions because the Llama 3.1 405B benchmark already within the suite, however because it has fewer trainable parameters, it may be run on only a single node and deployed to a broader vary of programs. This makes the take a look at accessible to a wider vary of potential submitters, whereas remaining a very good proxy for the efficiency of bigger clusters. Extra particulars on the Llama 3.1 8B benchmark will be discovered on this white paper https://mlcommons.org/2025/10/training-llama-3-1-8b/.
Flux.1 is a transformer-based text-to-image benchmark. Since Steady Diffusion v2 was launched into the MLPerf Coaching suite in 2023, text-to-image fashions have developed in two essential methods: they’ve built-in a transformer structure into the diffusion course of, and their parameter counts have grown by an order of magnitude. Flux.1, incorporating a transformer-based 11.9 billion–parameter mannequin, displays the present cutting-edge in generative AI for text-to-image duties. This white paper https://mlcommons.org/2025/10/training-flux1/ offers extra info on the Flux.1 benchmark.
“The sphere of AI is a shifting goal, continuously evolving with new situations and capabilities,” stated Paul Baumstarck, co-chair of the MLPerf Coaching working group. “We’ll proceed to evolve the MLPerf Coaching benchmark suite to make sure that we’re measuring what’s essential to the group, each at this time and tomorrow.”
















{kind=link}