


On this submit, I discuss by means of the motivation, complexities and implementation particulars of constructing torchvista, an open-source package deal to interactively visualize the ahead cross of any Pytorch mannequin from inside web-based notebooks.
To get a way of the workings of torchvista whereas studying this submit, you may try:
- Github web page if you wish to set up it by way of
pipand use it from web-based notebooks (Jupyter, Colab, Kaggle, VSCode, and so on) - An interactive demo web page with numerous well-known fashions visualized
- A Google Colab tutorial
- A video demo:
Motivation
Pytorch fashions can get very giant and sophisticated, and making sense of 1 from the code alone generally is a tiresome and even intractable train. Having a graph-like visualization of it’s simply what we have to make this simpler.
Whereas there exist instruments like Netron, pytorchviz, and torchview that make this simpler, my motivation for constructing torchvista was that I discovered that they have been missing in some or all of those necessities:
- Interplay help: The visualized graph ought to be interactive and never a static picture. It ought to be a construction you may zoom, drag, increase/collapse, and so on. Fashions can get very giant, and if all you might be see is a huge static picture of the graph, how are you going to actually discover it?

- Modular exploration: Giant Pytorch fashions are modular in thought and implementation. For instance, consider a module which has a
Sequentialmodule which accommodates a number ofConsiderationblocks, which in flip every has Absolutely linked blocks which includeLinearlayers with activation features and so forth. The device ought to let you faucet into this modular construction, and never simply current a low-level tensor hyperlink graph.

- Pocket book help: We are inclined to prototype and construct our fashions in notebooks. If a device have been supplied as a standalone software that required you to construct your mannequin and cargo it to visualise it, it’s simply too lengthy a suggestions loop. So the device has to ideally work from inside notebooks.

- Error debugging help: Whereas constructing fashions from scratch, we frequently run into many errors till the mannequin is ready to run a full ahead cross end-to-end. So the visualization device ought to be error tolerant and present you a partial visualization graph even when there are errors, so as to debug the error.

torch.cat failed as a result of mismatched tensor shapes- Ahead cross tracing: Pytorch natively exposes a backward cross graph by means of its autograd system, which the package deal pytorchviz exposes as a graph, however that is totally different from the ahead cross. Once we construct, examine and picture fashions, we expect extra concerning the ahead cross, and this may be very helpful to visualise.
Constructing torchvista
Primary API
The aim was to have a easy API that works with nearly any Pytorch mannequin.
import torch
from transformers import XLNetModel
from torchvista import trace_model
mannequin = XLNetModel.from_pretrained("xlnet-base-cased")
example_input = torch.randint(0, 32000, (1, 10))
# Hint it!
trace_model(mannequin, example_input)With one line of code calling trace_model( it ought to simply produce an interactive visualization of the ahead cross.
Steps concerned
Behind the scenes, torchvista, when referred to as, works in two phases:
- Tracing: That is the place torchvista extracts a graph information construction from the ahead cross of the mannequin. Pytorch doesn’t inherently expose this graph construction (although it does expose a graph for the backward cross), so torchvista has to construct this information construction by itself.
- Visualization: As soon as the graph is extracted, torchvista has to provide the precise visualization as an interactive graph. torchvista’s tracer does this by loading a template HTML file (with JS embedded inside it), and injecting serialized graph information construction objects as strings into the template to be subsequently loaded by the browser engine.

Tracing
Tracing is basically performed by (briefly) wrapping all of the essential and identified tensor operations, and commonplace Pytorch modules. The aim of wrapping is to change the features in order that when referred to as, they moreover do the bookkeeping mandatory for tracing.
Construction of the graph
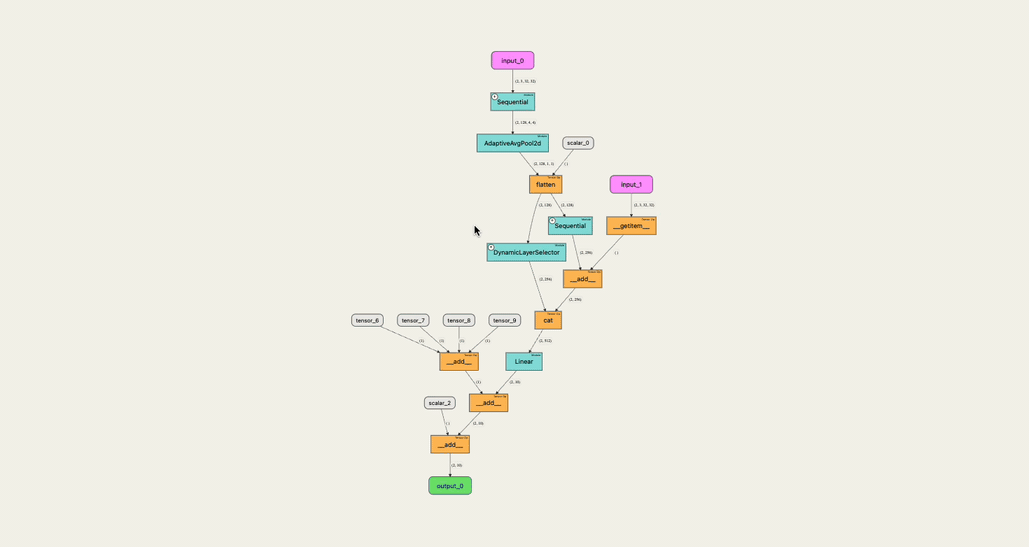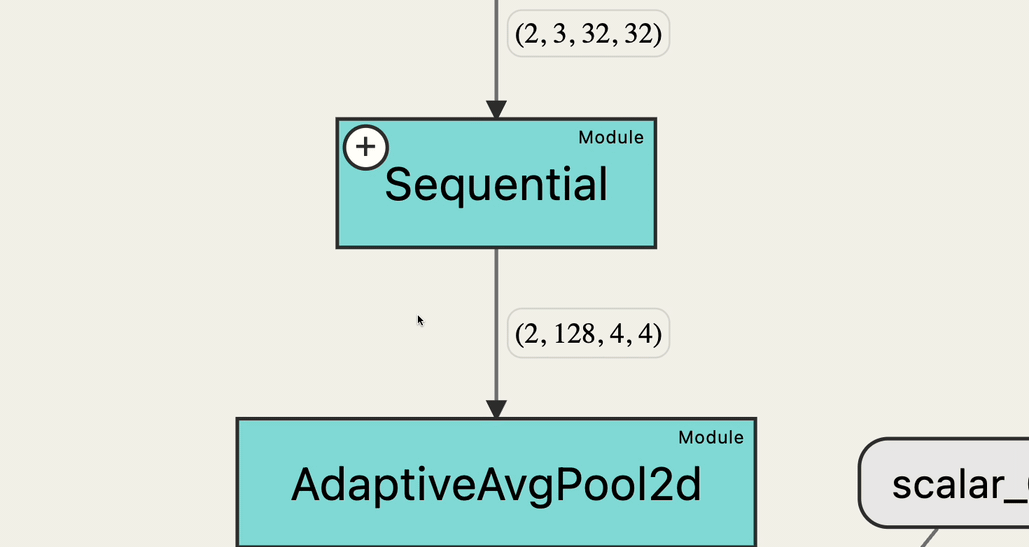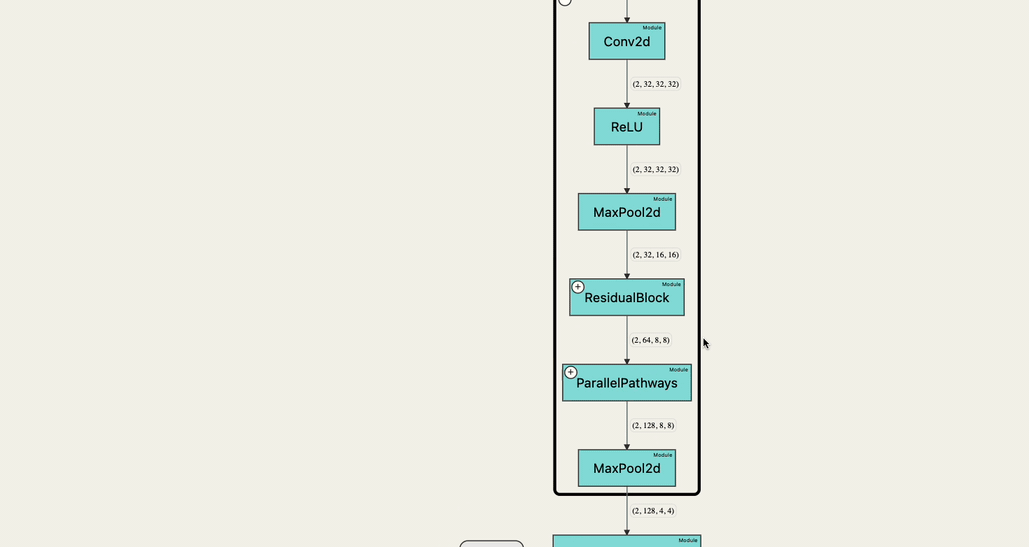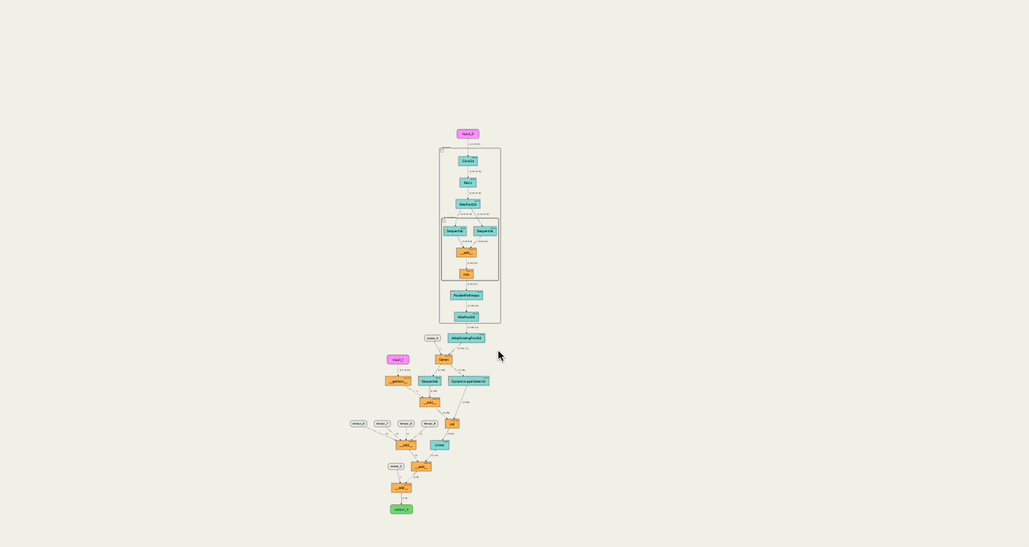
The graph we extract from the mannequin is a directed graph the place:
- The nodes are the varied Tensor operations and the varied inbuilt Pytorch modules that get referred to as through the ahead cross
- Moreover, enter and output tensors, and fixed valued tensors are additionally nodes within the graph.
- An edge exists from one node to the opposite for every tensor despatched from the previous to the latter.
- The sting label is the dimension of the related tensor.

However, the construction of our graph might be extra difficult as a result of most Pytorch modules name tensor operations and generally different modules’ ahead technique. This implies we’ve to take care of a graph construction that holds info to visually discover it at any degree of depth.

Subsequently, the construction that torchvista extracts contains two essential information constructions:
- Adjacency listing of the bottom degree operations/modules that get referred to as.
input_0 -> [ linear ]
linear -> [ __add__ ]
__getitem__ -> [ __add__ ]
__add__ -> [ multi_head_attention_forward ]
multi_head_attention_forward -> [ dropout ]
dropout -> [ __add__ ]- Hierarchy map that maps every node to its mum or dad module container (if current)
linear -> Linear
multi_head_attention_forward -> MultiheadAttention
MultiheadAttention -> TransformerEncoderLayer
TransformerEncoderLayer -> TransformerEncoderWith each of those, we’re capable of assemble any desired views of the ahead cross within the visualization layer.
Wrapping operations and modules
The entire concept behind wrapping is to do some bookkeeping earlier than and after the precise operation, in order that when the operation known as, our wrapped perform as an alternative will get referred to as, and the bookkeeping is carried out. The targets of bookkeeping are:
- File connections between nodes based mostly on tensor references.
- File tensor dimensions to indicate as edge labels.
- File module hierarchy for modules within the case the place modules are nested inside each other
Here’s a simplified code snippet of how wrapping works:
original_operations = {}
def wrap_operation(module, operation):
original_operations[get_hashable_key(module, operation)] = operation
def wrapped_operation(*args, **kwargs):
# Do the mandatory pre-call bookkeeping
do_pre_call_bookkeeping()
# Name the unique operation
consequence = operation(*args, **kwargs)
do_post_call_bookkeeping()
return consequence
setattr(module, func_name, wrapped_operation)
for module, operation in LONG_LIST_OF_PYTORCH_OPS:
wrap_operation(module, operation)
And when trace_model is about to finish, we should reset every little thing again to its unique state:
for module, operation in LONG_LIST_OF_PYTORCH_OPS:
setattr(module, func_name, original_operations[get_hashable_key(module,
operation)])That is performed in the identical method for the ahead() strategies of inbuilt Pytorch modules like Linear, Conv2d and so on.
Connections between nodes
As said beforehand, an edge exists between two nodes if a tensor was despatched from one to the opposite. This varieties the idea of making connections between nodes whereas constructing the graph.
Here’s a simplified code snippet of how this works:
adj_list = {}
def do_post_call_bookkeeping(module, operation, tensor_output):
# Set a "marker" on the output tensor in order that whoever consumes it
# is aware of which operation produced it
tensor_output._source_node = get_hashable_key(module, operation)
def do_pre_call_bookkeeping(module, operation, tensor_input):
source_node = tensor_input._source_node
# Add a hyperlink from the producer of the tensor to this node (the patron)
adj_list[source_node].append(get_hashable_key(module, operation))

Module hierarchy map
Once we wrap modules, issues need to be performed a little bit in a different way to construct the module hierarchy map. The thought is to take care of a stack of modules presently being referred to as in order that the highest of the stack at all times represents within the instant mum or dad within the hierarchy map.
Here’s a simplified code snippet of how this works:
hierarchy_map = {}
module_call_stack = []
def do_pre_call_bookkeeping_for_module(package deal, module, tensor_output):
# Add it to the stack
module_call_stack.append(get_hashable_key(package deal, module))
def do_post_call_bookkeeping_for_module(module, operation, tensor_input):
module_call_stack.pop()
# Prime of the stack now's the mum or dad node
hierarchy_map[get_hashable_key(package, module)] = module_call_stack[-1]
Visualization
This half is completely dealt with in Javscript as a result of the visualization occurs in web-based notebooks. The important thing libraries which are used listed below are:
- graphviz: for producing the format for the graph (viz-js is the JS port)
- d3: for drawing the interactive graph on a canvas
- iPython: to render HTML contents inside a pocket book
Graph Structure
Getting the format for the graph proper is an especially complicated downside. The primary aim is for the graph to have a top-to-bottom “movement” of edges, and most significantly, for there to not be an overlap between the varied nodes, edges, and edge labels.
That is made all of the extra complicated after we are working with a “hierarchical” graph the place there are “container” containers for modules inside which the underlying nodes and subcomponents are proven.

Fortunately, graphviz (viz-js) involves the rescue for us. graphviz makes use of a language referred to as “DOT language” by means of which we specify how we require the graph format to be constructed.
Here’s a pattern of the DOT syntax for the above graph:
# Edges and nodes
"input_0" [width=1.2, height=0.5];
"output_0" [width=1.2, height=0.5];
"input_0" -> "linear_1"[label="(1, 16)", fontsize="10", edge_data_id="5623840688" ];
"linear_1" -> "layer_norm_1"[label="(1, 32)", fontsize="10", edge_data_id="5801314448" ];
"linear_1" -> "layer_norm_2"[label="(1, 32)", fontsize="10", edge_data_id="5801314448" ];
...
# Module hierarchy specified utilizing clusters
subgraph cluster_FeatureEncoder_1 {
label="FeatureEncoder_1";
type=rounded;
subgraph cluster_MiddleBlock_1 {
label="MiddleBlock_1";
type=rounded;
subgraph cluster_InnerBlock_1 {
label="InnerBlock_1";
type=rounded;
subgraph cluster_LayerNorm_1 {
label="LayerNorm_1";
type=rounded;
"layer_norm_1";
}
subgraph cluster_TinyBranch_1 {
label="TinyBranch_1";
type=rounded;
subgraph cluster_MicroBranch_1 {
label="MicroBranch_1";
type=rounded;
subgraph cluster_Linear_2 {
label="Linear_2";
type=rounded;
"linear_2";
}
...As soon as this DOT illustration is generated from our adjacency listing and hierarchy map, graphviz produces a format with positions and sizes of all nodes and paths for edges.
Rendering
As soon as the format is generated, d3 is used to render the graph visually. Every little thing is drawn on a canvas (which is straightforward to make draggable and zoomable), and we set numerous occasion handlers to detect person clicks.
When the person makes these two sorts of increase/collapse clicks on modules (utilizing the ‘+’ ‘-‘ buttons), torchvista data which node the motion was carried out on, and simply re-renders the graph as a result of the format needs to be reconstructed, after which robotically drags and zooms in to an applicable degree based mostly on the recorded pre-click place.
Rendering a graph utilizing d3 is a really detailed subject and in any other case to not distinctive to torchvista, and therefore I miss the main points from this submit.
[Bonus] Dealing with errors in Pytorch fashions
When customers hint their Pytorch fashions (particularly whereas creating the fashions), generally the fashions throw errors. It will have been simple for torchvista to only surrender when this occurs and let the person repair the error first earlier than they may use torchvista. However torchvista as an alternative lends a hand at debugging these errors by doing best-effort tracing of the mannequin. The thought is straightforward – simply hint the utmost it may possibly till the error occurs, after which render the graph with simply a lot (with visible indicators displaying the place the error occurred), after which simply increase the exception in order that the person also can see the stacktrace like they usually would.


Here’s a simplified code snippet of how this works:
def trace_model(...):
exception = None
strive:
# All of the tracing code
besides Exception as e:
exception = e
lastly:
# do all the mandatory cleanups (unwrapping all of the operations and modules)
if exception shouldn't be None:
increase exceptionWrapping up
This submit shed some mild on the journey of constructing a Pytorch visualization package deal. We first talked concerning the very particular motivation for constructing such a device by evaluating with different comparable instruments. Then, we mentioned the design and implementation of torchvista in two elements. The primary half was concerning the technique of tracing the ahead cross of a Pytorch mannequin utilizing (non permanent) wrapping of operations and modules to extract detailed details about the mannequin’s ahead cross, together with not solely the connections between numerous operations, but additionally the module hierarchy. Then, within the second half, we went over the visualization layer, and the complexities of format era, which have been solved utilizing the appropriate selection of libraries.
torchvista is open supply, and all contributions, together with suggestions, points and pull requests, are welcome. I hope torchvista helps folks of all ranges of experience in constructing and visualizing their fashions (no matter mannequin measurement), showcasing their work, and as a device for educating others about machine studying fashions.
Future instructions
Potential future enhancements to torchvista embody:
- Including help for “rolling”, the place if the identical substructure of a mannequin is repeated a number of occasions, it’s proven simply as soon as with a depend of what number of occasions it repeats
- Systematic exploration of state-of-the-art fashions to make sure all their tensor operations are adequately lined
- Assist for exporting static photographs of fashions as png or pdf information
- Effectivity and pace enhancements
References
- Open supply libraries used:
- Dot language from graphviz
- Different comparable visualization instruments:
- torchvista:
All photographs until in any other case said are by the writer.

















{kind=link}