


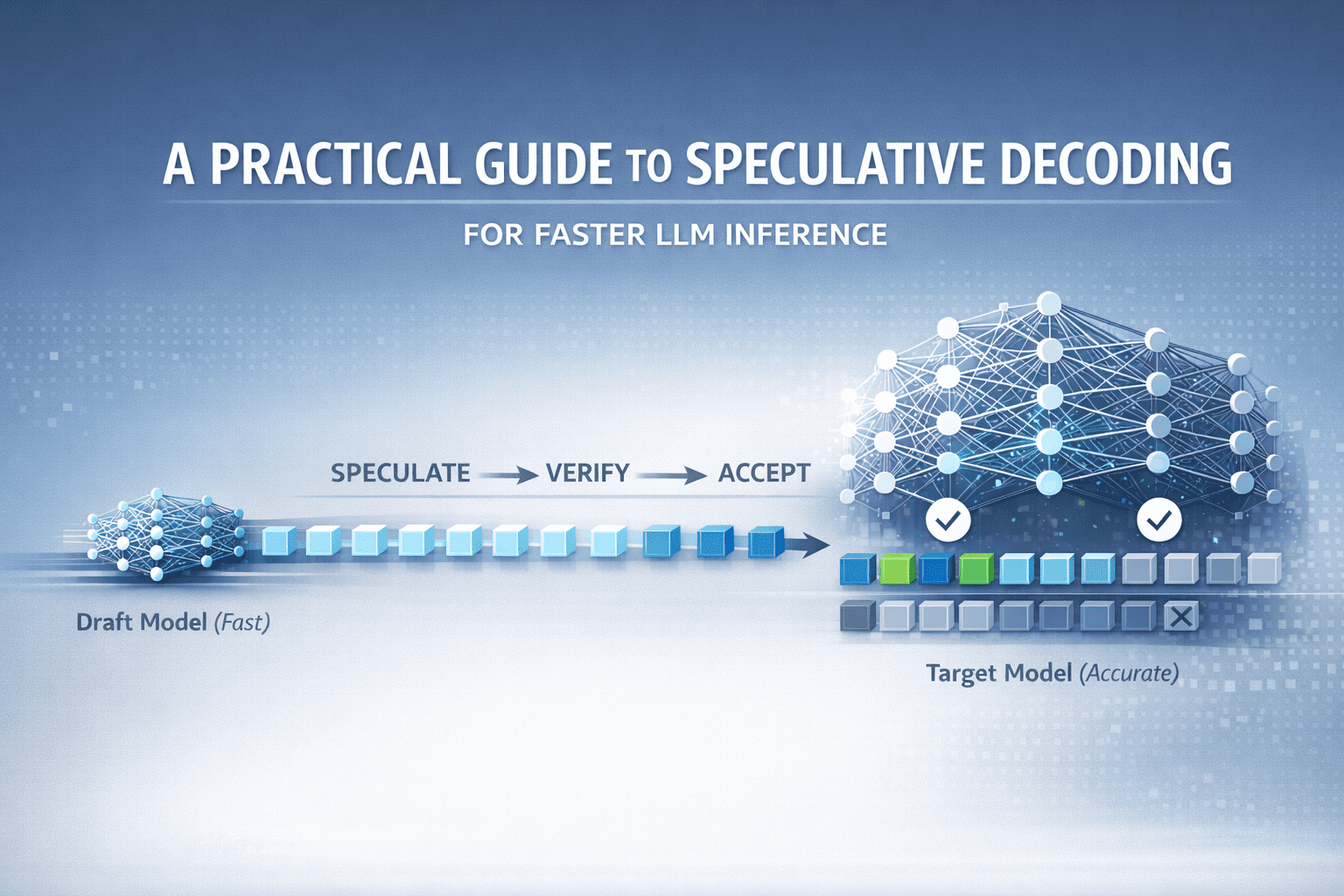
On this article, you’ll find out how speculative decoding works and the way to implement it to scale back massive language mannequin inference latency with out sacrificing output high quality.
Matters we are going to cowl embody:
- Why massive language mannequin inference is commonly memory-bound moderately than compute-bound.
- How speculative decoding works by way of draft technology, parallel verification, and rejection sampling.
- Methods to measure, implement, and apply speculative decoding in actual tasks.
Let’s get straight to it.

The Machine Studying Practitioner’s Information to Speculative Decoding
Picture by Writer
Introduction
Massive language fashions generate textual content one token at a time. Every token requires a full ahead move via the mannequin, loading billions of parameters from reminiscence. This creates latency in functions and drives up inference prices.
Speculative decoding addresses this through the use of a small draft mannequin to generate a number of tokens, then verifying them in parallel with a bigger goal mannequin. The output is analogous in high quality to straightforward technology, however you get 2–3× quicker inference, and typically much more.
Why Massive Language Mannequin Inference Is Sluggish
Earlier than we get into the specifics of speculative decoding, let’s take a more in-depth take a look at the issue and a few ideas that’ll allow you to perceive why speculative decoding works.
The Sequential Technology Downside
Massive language fashions generate textual content autoregressively — one token at a time — the place every new token relies on all earlier tokens. The generated token is then appended to the enter and fed because the enter to the following step.
A token may be an entire phrase, a part of a phrase, or perhaps a single character relying on the mannequin’s tokenizer.
Right here’s what occurs throughout autoregressive technology:
- The mannequin receives enter tokens
- It runs a ahead move via all its layers
- It predicts the chance distribution for the following token
- It samples or selects the most certainly token
- It appends that token to the enter
- Repeat from step 1
For instance, to generate the sentence “The scientist found a brand new species” (say, six tokens), the mannequin should carry out six full ahead passes sequentially.
The Reminiscence Bandwidth Bottleneck
You may assume the bottleneck is computation. In any case, these fashions have billions of parameters. However that’s not fairly proper as a result of trendy GPUs and TPUs have huge computational capability. Nevertheless, their reminiscence bandwidth is way more restricted.
The issue is that every ahead move requires loading your complete mannequin’s weights from reminiscence into the computation cores. For big fashions, this could imply loading terabytes of knowledge per generated token. The GPU’s compute cores sit idle whereas ready for information to reach. That is known as being memory-bound.
A Notice on Tokens
Right here’s one thing fascinating: not all tokens are equally troublesome to foretell. Take into account this textual content:
The scientist found a brand new species within the Amazon. The invention was made within the Amazon rainforest.
After “The invention was made within the”, predicting “Amazon” is comparatively simpler as a result of it appeared earlier within the context. However after “The scientist found a brand new”, predicting “species” requires understanding the semantic context and customary analysis outcomes.
The important thing commentary, due to this fact, is if some tokens are simple to foretell, possibly a smaller, quicker mannequin may deal with them.
How Speculative Decoding Works
Speculative decoding is impressed by a pc structure approach known as speculative execution, the place you carry out duties earlier than figuring out in the event that they’re really wanted, then confirm and discard them in the event that they’re improper.
At a excessive degree, the concept is to scale back sequential bottlenecks by separating quick guessing from correct verification.
- Use a small, quick draft mannequin to guess a number of tokens forward
- Then use a bigger goal mannequin to confirm all these guesses in parallel in a single ahead move
This shifts technology from strictly one-token-at-a-time to a speculate-then-verify loop. This considerably improves inference pace with no lower in output high quality.
Listed here are the three important steps.
Step 1: Token Hypothesis or Draft Technology
The smaller, quicker mannequin — the draft mannequin — generates a number of candidate tokens, sometimes three to 10 tokens forward. This mannequin may not be as correct as your massive mannequin, however it’s a lot quicker.
Consider this like a quick-thinking assistant who makes educated guesses about what comes subsequent. As an apart, speculative decoding can be known as assisted technology, supported within the Hugging Face Transformers library.
Step 2: Parallel Verification
Okay, we have now the tokens from the draft mannequin… what subsequent?
Recall {that a} single ahead move via the big mannequin produces one token. Right here, we solely want a single ahead move via the bigger goal mannequin with your complete sequence of draft tokens as enter.
Due to how transformer fashions work, this single ahead move produces chance distributions for the following token at each place within the sequence. This implies we are able to confirm all draft tokens without delay.
The computational price right here is roughly the identical as a single normal ahead move, however we’re doubtlessly validating a number of tokens.
Step 3: Rejection Sampling
Now we have to determine which draft tokens to just accept or reject. That is accomplished via a probabilistic methodology known as rejection sampling that ensures the output distribution matches what the goal mannequin would have produced by itself.
For every draft token place, we examine:
- P(draft): The chance the draft mannequin assigned to its chosen token
- P(goal): The chance the goal mannequin assigns to that very same token
The acceptance logic works like this:
|
For every draft token in sequence: if P(goal) >= P(draft): Settle for the token (goal agrees or is extra assured) else: Settle for with chance P(goal)/P(draft)
if rejected: Discard this token and all following draft tokens Generate one new token from goal mannequin Break and begin subsequent hypothesis spherical |
Let’s see this with numbers. Suppose the draft mannequin proposed the sequence “found a breakthrough”:
Token 1: “found”
- P(draft) = 0.6
- P(goal) = 0.8
- Since 0.8 ≥ 0.6 → ACCEPT
Token 2: “a”
- P(draft) = 0.7
- P(goal) = 0.75
- Since 0.75 ≥ 0.7 → ACCEPT
Token 3: “breakthrough”
- P(draft) = 0.5
- P(goal) = 0.2
- Since 0.2 < 0.5, this token is questionable
- Say we reject it and all following tokens
- The goal mannequin generates its personal token: “new”
Right here, we accepted two draft tokens and generated one new token, giving us three tokens from what was basically one goal mannequin ahead move (plus the draft token technology from the smaller mannequin).
Suppose the draft mannequin generates Okay tokens. What occurs when all Okay draft tokens are accepted?
When the goal mannequin accepts all Okay draft tokens, the method generates Okay+1 tokens complete in that iteration. The goal mannequin verifies the Okay draft tokens and concurrently generates one extra token past them. For instance, if Okay=5 and all drafts are accepted, you get six tokens from a single goal ahead move. That is the very best case: Okay+1 tokens per iteration versus one token in normal technology. The algorithm then repeats with the prolonged sequence as the brand new enter.
Understanding the Key Efficiency Metrics
To grasp if speculative decoding is working properly on your use case, it’s essential to observe these metrics.
Acceptance Fee (α)
That is the chance that the goal mannequin accepts a draft token. It’s the one most necessary metric.
[
alpha = frac{text{Number of accepted tokens}}{text{Total draft tokens proposed}}.
]
Instance: In case you draft 5 tokens per spherical and common three acceptances, your α = 0.6.
- Excessive acceptance charge (α ≥ 0.7): Wonderful speedup, your draft mannequin is well-matched
- Medium acceptance charge (α = 0.5–0.7): Good speedup, worthwhile to make use of
- Low acceptance charge (α < 0.5): Poor speedup, take into account a distinct draft mannequin
Speculative Token Depend (γ)
That is what number of tokens your draft mannequin proposes every spherical. It’s configurable.
The optimum γ relies on your acceptance charge:
- Excessive α: Use bigger γ (7–10 tokens) to maximise speedup
- Low α: Use smaller γ (3–5 tokens) to keep away from wasted computation
Acceptance Size (τ)
That is the typical variety of tokens really accepted per spherical. There’s a theoretical method:
[
tau = frac{1 – alpha^{gamma + 1}}{1 – alpha}.
]
Actual-world benchmarks present that speculative decoding can obtain 2–3× speedup with good acceptance charges (α ≥ 0.6, γ ≥ 5). Duties which can be input-grounded, similar to translation or summarization, see increased speedups, whereas inventive duties profit much less.
Implementing Speculative Decoding
Let’s implement speculative decoding utilizing the Hugging Face Transformers library. We’ll use Google’s Gemma fashions: the 7B mannequin as our goal and the 2B mannequin as our draft. However you’ll be able to experiment with goal and draft mannequin pairings. Simply do not forget that the goal mannequin is a bigger and higher mannequin and the draft mannequin is far smaller.
It’s also possible to observe together with this Colab pocket book.
Step 1: Putting in Dependencies
First, you’ll want the Transformers library from Hugging Face together with PyTorch for mannequin inference.
|
pip set up transformers torch speed up huggingface_hub |
This installs all the pieces wanted to load and run massive language fashions effectively.
Step 2: Loading the Fashions
Now let’s load each the goal mannequin and the draft mannequin. The important thing requirement is that each the goal and the draft fashions should use the identical tokenizer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
from transformers import AutoModelForCausalLM, AutoTokenizer import torch
# Select your fashions – draft needs to be a lot smaller than goal target_model_name = “google/gemma-7b-it” draft_model_name = “google/gemma-2b-it”
# Set system system = “cuda” if torch.cuda.is_available() else “cpu” print(f“Utilizing system: {system}”)
# Load tokenizer (have to be the identical for each fashions) tokenizer = AutoTokenizer.from_pretrained(target_model_name)
# Load goal mannequin (the big, high-quality mannequin) print(“Loading goal mannequin…”) target_model = AutoModelForCausalLM.from_pretrained( target_model_name, torch_dtype=torch.float16, # Use fp16 for quicker inference device_map=“auto” )
# Load draft mannequin (the small, quick mannequin) print(“Loading draft mannequin…”) draft_model = AutoModelForCausalLM.from_pretrained( draft_model_name, torch_dtype=torch.float16, device_map=“auto” )
print(“Fashions loaded efficiently!”) |
To entry gated fashions like Gemma, it’s essential to log in to Hugging Face.
First, get a Hugging Face API token. Go to huggingface.co/settings/tokens and create a brand new entry token (guarantee it has no less than “learn” permissions).
Possibility 1 (Really helpful in Colab): Run the next code in a brand new cell and paste your token when prompted:
|
from huggingface_hub import login login() |
Possibility 2 (Setting Variable): Set the HF_TOKEN surroundings variable earlier than operating any code that accesses Hugging Face. For instance:
|
import os os.environ[“HF_TOKEN”] = “YOUR_HF_TOKEN_HERE” |
For gated fashions, you additionally want to go to the mannequin’s web page on Hugging Face and settle for the license or phrases of use earlier than you’ll be able to obtain it. As soon as authenticated and accepted, you’ll be able to obtain the mannequin and use it.
Step 3: Making ready Your Enter
Let’s create a immediate and tokenize it. The tokenizer converts textual content into numerical IDs that the mannequin can course of.
|
# Create a immediate immediate = “Quantum entanglement is a phenomenon the place”
# Tokenize the enter inputs = tokenizer(immediate, return_tensors=“pt”).to(system)
print(f“Enter immediate: {immediate}”) print(f“Enter token depend: {inputs[‘input_ids’].form[1]}”) |
The tokenizer splits our immediate into tokens, which is able to function the beginning context for technology.
Step 4: Implementing Autoregressive Inference (Baseline)
First, let’s set up a baseline by producing textual content the usual manner. This can assist us measure the speedup from speculative decoding.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import time
# Commonplace technology (no hypothesis) print(“n— Commonplace Technology (Baseline) —“) start_time = time.time()
baseline_output = target_model.generate( **inputs, max_new_tokens=50, do_sample=False, pad_token_id=tokenizer.eos_token_id )
baseline_time = time.time() – start_time baseline_text = tokenizer.decode(baseline_output[0], skip_special_tokens=True)
print(f“Generated textual content:n{baseline_text}n”) print(f“Time taken: {baseline_time:.2f} seconds”) print(f“Tokens per second: {50/baseline_time:.2f}”) |
Step 5: Producing With Speculative Decoding
Now let’s allow speculative decoding. The one change is including the assistant_model and num_assistant_tokens parameters to inform the goal mannequin to make use of the draft mannequin to generate num_assistant_tokens per hypothesis spherical.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import time import warnings # Import warnings module
# Speculative decoding – simply add assistant_model parameter! print(“n— Speculative Decoding —“) start_time = time.time()
with warnings.catch_warnings(): warnings.simplefilter(“ignore”) # Ignore all warnings inside this block speculative_output = target_model.generate( **inputs, max_new_tokens=50, do_sample=True, # Set to False for grasping decoding pad_token_id=tokenizer.eos_token_id, assistant_model=draft_model, # This permits speculative decoding! num_assistant_tokens=10 )
speculative_time = time.time() – start_time speculative_text = tokenizer.decode(speculative_output[0], skip_special_tokens=True)
print(f“Generated textual content:n{speculative_text}n”) print(f“Time taken: {speculative_time:.2f} seconds”) print(f“Tokens per second: {50/speculative_time:.2f}”)
# Calculate speedup speedup = baseline_time / speculative_time print(f“nSpeedup: {speedup:.2f}x quicker!”) |
You need to sometimes see round a 2× enchancment. Once more, the speedup relies on the target-draft pairing. To sum up, the draft mannequin proposes tokens, and the goal mannequin verifies a number of candidates in parallel, considerably lowering the variety of sequential ahead passes via the bigger mannequin.
When to Use Speculative Decoding (And When Not To)
Based mostly on the analysis and real-world deployments, right here’s when speculative decoding works finest:
Good Use Instances
- Speculative decoding accelerates input-grounded duties like translation, summarization, and transcription.
- It really works properly when performing grasping decoding by all the time deciding on the most certainly token.
- It’s helpful for low-temperature sampling when outputs should be centered and predictable.
- Helpful when the mannequin barely suits in GPU reminiscence.
- It reduces latency in manufacturing deployments the place including GPUs just isn’t an choice.
When You Don’t Want Speculative Decoding
- Speculative decoding will increase reminiscence overhead as a result of each fashions have to be loaded.
- It’s much less efficient for high-temperature sampling similar to inventive writing.
- Advantages drop if the draft mannequin is poorly matched to the goal mannequin.
- Beneficial properties are minimal for very small goal fashions that already match simply in reminiscence.
Let’s wrap up with a word on how to decide on a great draft mannequin that gives non-trivial enchancment in inference occasions.
Selecting a Good Draft Mannequin
As you may need guessed, the effectiveness of speculative decoding relies on deciding on the appropriate draft mannequin. A poor selection gives you minimal speedup and even sluggish issues down.
The draft mannequin should have:
- Similar tokenizer because the goal mannequin. That is non-negotiable.
- At the very least 10× fewer parameters than the goal. In case your draft mannequin is simply too massive, then draft token technology goes to be sluggish as properly, which defeats the aim.
- Comparable coaching information to maximise acceptance charge
- Similar structure household when potential
For domain-specific functions, take into account fine-tuning a small mannequin to imitate your goal mannequin’s habits. This may considerably increase acceptance charges. Right here’s how you are able to do that:
- Gather outputs out of your goal mannequin on consultant inputs
- Effective-tune a small mannequin to foretell those self same outputs
This further effort pays off while you want constant excessive efficiency in manufacturing. Learn Get 3× Quicker LLM Inference with Speculative Decoding Utilizing the Proper Draft Mannequin to be taught extra.
Wrapping Up
Speculative decoding provides a sensible solution to pace up massive language mannequin inference with out sacrificing output high quality. Through the use of a smaller draft mannequin to suggest a number of tokens and verifying them in parallel with the goal mannequin, you’ll be able to obtain 2–3× speedups or extra.
The approach works as a result of it addresses the basic memory-bound nature of enormous language mannequin inference, lowering the variety of occasions it’s essential to load the complete mannequin’s parameters from reminiscence. Whereas the effectiveness nonetheless relies on components like draft mannequin high quality and acceptance charge, speculative decoding is beneficial in manufacturing methods the place latency and price matter. To be taught extra, try the next sources:
We’ll cowl extra inference optimization strategies within the subsequent articles, exploring extra strategies to make your massive language mannequin functions quicker and more cost effective.
On this article, you’ll find out how speculative decoding works and the way to implement it to scale back massive language mannequin inference latency with out sacrificing output high quality.
Matters we are going to cowl embody:
- Why massive language mannequin inference is commonly memory-bound moderately than compute-bound.
- How speculative decoding works by way of draft technology, parallel verification, and rejection sampling.
- Methods to measure, implement, and apply speculative decoding in actual tasks.
Let’s get straight to it.
The Machine Studying Practitioner’s Information to Speculative Decoding
Picture by Writer
Introduction
Massive language fashions generate textual content one token at a time. Every token requires a full ahead move via the mannequin, loading billions of parameters from reminiscence. This creates latency in functions and drives up inference prices.
Speculative decoding addresses this through the use of a small draft mannequin to generate a number of tokens, then verifying them in parallel with a bigger goal mannequin. The output is analogous in high quality to straightforward technology, however you get 2–3× quicker inference, and typically much more.
Why Massive Language Mannequin Inference Is Sluggish
Earlier than we get into the specifics of speculative decoding, let’s take a more in-depth take a look at the issue and a few ideas that’ll allow you to perceive why speculative decoding works.
The Sequential Technology Downside
Massive language fashions generate textual content autoregressively — one token at a time — the place every new token relies on all earlier tokens. The generated token is then appended to the enter and fed because the enter to the following step.
A token may be an entire phrase, a part of a phrase, or perhaps a single character relying on the mannequin’s tokenizer.
Right here’s what occurs throughout autoregressive technology:
- The mannequin receives enter tokens
- It runs a ahead move via all its layers
- It predicts the chance distribution for the following token
- It samples or selects the most certainly token
- It appends that token to the enter
- Repeat from step 1
For instance, to generate the sentence “The scientist found a brand new species” (say, six tokens), the mannequin should carry out six full ahead passes sequentially.
The Reminiscence Bandwidth Bottleneck
You may assume the bottleneck is computation. In any case, these fashions have billions of parameters. However that’s not fairly proper as a result of trendy GPUs and TPUs have huge computational capability. Nevertheless, their reminiscence bandwidth is way more restricted.
The issue is that every ahead move requires loading your complete mannequin’s weights from reminiscence into the computation cores. For big fashions, this could imply loading terabytes of knowledge per generated token. The GPU’s compute cores sit idle whereas ready for information to reach. That is known as being memory-bound.
A Notice on Tokens
Right here’s one thing fascinating: not all tokens are equally troublesome to foretell. Take into account this textual content:
The scientist found a brand new species within the Amazon. The invention was made within the Amazon rainforest.
After “The invention was made within the”, predicting “Amazon” is comparatively simpler as a result of it appeared earlier within the context. However after “The scientist found a brand new”, predicting “species” requires understanding the semantic context and customary analysis outcomes.
The important thing commentary, due to this fact, is if some tokens are simple to foretell, possibly a smaller, quicker mannequin may deal with them.
How Speculative Decoding Works
Speculative decoding is impressed by a pc structure approach known as speculative execution, the place you carry out duties earlier than figuring out in the event that they’re really wanted, then confirm and discard them in the event that they’re improper.
At a excessive degree, the concept is to scale back sequential bottlenecks by separating quick guessing from correct verification.
- Use a small, quick draft mannequin to guess a number of tokens forward
- Then use a bigger goal mannequin to confirm all these guesses in parallel in a single ahead move
This shifts technology from strictly one-token-at-a-time to a speculate-then-verify loop. This considerably improves inference pace with no lower in output high quality.
Listed here are the three important steps.
Step 1: Token Hypothesis or Draft Technology
The smaller, quicker mannequin — the draft mannequin — generates a number of candidate tokens, sometimes three to 10 tokens forward. This mannequin may not be as correct as your massive mannequin, however it’s a lot quicker.
Consider this like a quick-thinking assistant who makes educated guesses about what comes subsequent. As an apart, speculative decoding can be known as assisted technology, supported within the Hugging Face Transformers library.
Step 2: Parallel Verification
Okay, we have now the tokens from the draft mannequin… what subsequent?
Recall {that a} single ahead move via the big mannequin produces one token. Right here, we solely want a single ahead move via the bigger goal mannequin with your complete sequence of draft tokens as enter.
Due to how transformer fashions work, this single ahead move produces chance distributions for the following token at each place within the sequence. This implies we are able to confirm all draft tokens without delay.
The computational price right here is roughly the identical as a single normal ahead move, however we’re doubtlessly validating a number of tokens.
Step 3: Rejection Sampling
Now we have to determine which draft tokens to just accept or reject. That is accomplished via a probabilistic methodology known as rejection sampling that ensures the output distribution matches what the goal mannequin would have produced by itself.
For every draft token place, we examine:
- P(draft): The chance the draft mannequin assigned to its chosen token
- P(goal): The chance the goal mannequin assigns to that very same token
The acceptance logic works like this:
|
For every draft token in sequence: if P(goal) >= P(draft): Settle for the token (goal agrees or is extra assured) else: Settle for with chance P(goal)/P(draft)
if rejected: Discard this token and all following draft tokens Generate one new token from goal mannequin Break and begin subsequent hypothesis spherical |
Let’s see this with numbers. Suppose the draft mannequin proposed the sequence “found a breakthrough”:
Token 1: “found”
- P(draft) = 0.6
- P(goal) = 0.8
- Since 0.8 ≥ 0.6 → ACCEPT
Token 2: “a”
- P(draft) = 0.7
- P(goal) = 0.75
- Since 0.75 ≥ 0.7 → ACCEPT
Token 3: “breakthrough”
- P(draft) = 0.5
- P(goal) = 0.2
- Since 0.2 < 0.5, this token is questionable
- Say we reject it and all following tokens
- The goal mannequin generates its personal token: “new”
Right here, we accepted two draft tokens and generated one new token, giving us three tokens from what was basically one goal mannequin ahead move (plus the draft token technology from the smaller mannequin).
Suppose the draft mannequin generates Okay tokens. What occurs when all Okay draft tokens are accepted?
When the goal mannequin accepts all Okay draft tokens, the method generates Okay+1 tokens complete in that iteration. The goal mannequin verifies the Okay draft tokens and concurrently generates one extra token past them. For instance, if Okay=5 and all drafts are accepted, you get six tokens from a single goal ahead move. That is the very best case: Okay+1 tokens per iteration versus one token in normal technology. The algorithm then repeats with the prolonged sequence as the brand new enter.
Understanding the Key Efficiency Metrics
To grasp if speculative decoding is working properly on your use case, it’s essential to observe these metrics.
Acceptance Fee (α)
That is the chance that the goal mannequin accepts a draft token. It’s the one most necessary metric.
[
alpha = frac{text{Number of accepted tokens}}{text{Total draft tokens proposed}}.
]
Instance: In case you draft 5 tokens per spherical and common three acceptances, your α = 0.6.
- Excessive acceptance charge (α ≥ 0.7): Wonderful speedup, your draft mannequin is well-matched
- Medium acceptance charge (α = 0.5–0.7): Good speedup, worthwhile to make use of
- Low acceptance charge (α < 0.5): Poor speedup, take into account a distinct draft mannequin
Speculative Token Depend (γ)
That is what number of tokens your draft mannequin proposes every spherical. It’s configurable.
The optimum γ relies on your acceptance charge:
- Excessive α: Use bigger γ (7–10 tokens) to maximise speedup
- Low α: Use smaller γ (3–5 tokens) to keep away from wasted computation
Acceptance Size (τ)
That is the typical variety of tokens really accepted per spherical. There’s a theoretical method:
[
tau = frac{1 – alpha^{gamma + 1}}{1 – alpha}.
]
Actual-world benchmarks present that speculative decoding can obtain 2–3× speedup with good acceptance charges (α ≥ 0.6, γ ≥ 5). Duties which can be input-grounded, similar to translation or summarization, see increased speedups, whereas inventive duties profit much less.
Implementing Speculative Decoding
Let’s implement speculative decoding utilizing the Hugging Face Transformers library. We’ll use Google’s Gemma fashions: the 7B mannequin as our goal and the 2B mannequin as our draft. However you’ll be able to experiment with goal and draft mannequin pairings. Simply do not forget that the goal mannequin is a bigger and higher mannequin and the draft mannequin is far smaller.
It’s also possible to observe together with this Colab pocket book.
Step 1: Putting in Dependencies
First, you’ll want the Transformers library from Hugging Face together with PyTorch for mannequin inference.
|
pip set up transformers torch speed up huggingface_hub |
This installs all the pieces wanted to load and run massive language fashions effectively.
Step 2: Loading the Fashions
Now let’s load each the goal mannequin and the draft mannequin. The important thing requirement is that each the goal and the draft fashions should use the identical tokenizer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
from transformers import AutoModelForCausalLM, AutoTokenizer import torch
# Select your fashions – draft needs to be a lot smaller than goal target_model_name = “google/gemma-7b-it” draft_model_name = “google/gemma-2b-it”
# Set system system = “cuda” if torch.cuda.is_available() else “cpu” print(f“Utilizing system: {system}”)
# Load tokenizer (have to be the identical for each fashions) tokenizer = AutoTokenizer.from_pretrained(target_model_name)
# Load goal mannequin (the big, high-quality mannequin) print(“Loading goal mannequin…”) target_model = AutoModelForCausalLM.from_pretrained( target_model_name, torch_dtype=torch.float16, # Use fp16 for quicker inference device_map=“auto” )
# Load draft mannequin (the small, quick mannequin) print(“Loading draft mannequin…”) draft_model = AutoModelForCausalLM.from_pretrained( draft_model_name, torch_dtype=torch.float16, device_map=“auto” )
print(“Fashions loaded efficiently!”) |
To entry gated fashions like Gemma, it’s essential to log in to Hugging Face.
First, get a Hugging Face API token. Go to huggingface.co/settings/tokens and create a brand new entry token (guarantee it has no less than “learn” permissions).
Possibility 1 (Really helpful in Colab): Run the next code in a brand new cell and paste your token when prompted:
|
from huggingface_hub import login login() |
Possibility 2 (Setting Variable): Set the HF_TOKEN surroundings variable earlier than operating any code that accesses Hugging Face. For instance:
|
import os os.environ[“HF_TOKEN”] = “YOUR_HF_TOKEN_HERE” |
For gated fashions, you additionally want to go to the mannequin’s web page on Hugging Face and settle for the license or phrases of use earlier than you’ll be able to obtain it. As soon as authenticated and accepted, you’ll be able to obtain the mannequin and use it.
Step 3: Making ready Your Enter
Let’s create a immediate and tokenize it. The tokenizer converts textual content into numerical IDs that the mannequin can course of.
|
# Create a immediate immediate = “Quantum entanglement is a phenomenon the place”
# Tokenize the enter inputs = tokenizer(immediate, return_tensors=“pt”).to(system)
print(f“Enter immediate: {immediate}”) print(f“Enter token depend: {inputs[‘input_ids’].form[1]}”) |
The tokenizer splits our immediate into tokens, which is able to function the beginning context for technology.
Step 4: Implementing Autoregressive Inference (Baseline)
First, let’s set up a baseline by producing textual content the usual manner. This can assist us measure the speedup from speculative decoding.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import time
# Commonplace technology (no hypothesis) print(“n— Commonplace Technology (Baseline) —“) start_time = time.time()
baseline_output = target_model.generate( **inputs, max_new_tokens=50, do_sample=False, pad_token_id=tokenizer.eos_token_id )
baseline_time = time.time() – start_time baseline_text = tokenizer.decode(baseline_output[0], skip_special_tokens=True)
print(f“Generated textual content:n{baseline_text}n”) print(f“Time taken: {baseline_time:.2f} seconds”) print(f“Tokens per second: {50/baseline_time:.2f}”) |
Step 5: Producing With Speculative Decoding
Now let’s allow speculative decoding. The one change is including the assistant_model and num_assistant_tokens parameters to inform the goal mannequin to make use of the draft mannequin to generate num_assistant_tokens per hypothesis spherical.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import time import warnings # Import warnings module
# Speculative decoding – simply add assistant_model parameter! print(“n— Speculative Decoding —“) start_time = time.time()
with warnings.catch_warnings(): warnings.simplefilter(“ignore”) # Ignore all warnings inside this block speculative_output = target_model.generate( **inputs, max_new_tokens=50, do_sample=True, # Set to False for grasping decoding pad_token_id=tokenizer.eos_token_id, assistant_model=draft_model, # This permits speculative decoding! num_assistant_tokens=10 )
speculative_time = time.time() – start_time speculative_text = tokenizer.decode(speculative_output[0], skip_special_tokens=True)
print(f“Generated textual content:n{speculative_text}n”) print(f“Time taken: {speculative_time:.2f} seconds”) print(f“Tokens per second: {50/speculative_time:.2f}”)
# Calculate speedup speedup = baseline_time / speculative_time print(f“nSpeedup: {speedup:.2f}x quicker!”) |
You need to sometimes see round a 2× enchancment. Once more, the speedup relies on the target-draft pairing. To sum up, the draft mannequin proposes tokens, and the goal mannequin verifies a number of candidates in parallel, considerably lowering the variety of sequential ahead passes via the bigger mannequin.
When to Use Speculative Decoding (And When Not To)
Based mostly on the analysis and real-world deployments, right here’s when speculative decoding works finest:
Good Use Instances
- Speculative decoding accelerates input-grounded duties like translation, summarization, and transcription.
- It really works properly when performing grasping decoding by all the time deciding on the most certainly token.
- It’s helpful for low-temperature sampling when outputs should be centered and predictable.
- Helpful when the mannequin barely suits in GPU reminiscence.
- It reduces latency in manufacturing deployments the place including GPUs just isn’t an choice.
When You Don’t Want Speculative Decoding
- Speculative decoding will increase reminiscence overhead as a result of each fashions have to be loaded.
- It’s much less efficient for high-temperature sampling similar to inventive writing.
- Advantages drop if the draft mannequin is poorly matched to the goal mannequin.
- Beneficial properties are minimal for very small goal fashions that already match simply in reminiscence.
Let’s wrap up with a word on how to decide on a great draft mannequin that gives non-trivial enchancment in inference occasions.
Selecting a Good Draft Mannequin
As you may need guessed, the effectiveness of speculative decoding relies on deciding on the appropriate draft mannequin. A poor selection gives you minimal speedup and even sluggish issues down.
The draft mannequin should have:
- Similar tokenizer because the goal mannequin. That is non-negotiable.
- At the very least 10× fewer parameters than the goal. In case your draft mannequin is simply too massive, then draft token technology goes to be sluggish as properly, which defeats the aim.
- Comparable coaching information to maximise acceptance charge
- Similar structure household when potential
For domain-specific functions, take into account fine-tuning a small mannequin to imitate your goal mannequin’s habits. This may considerably increase acceptance charges. Right here’s how you are able to do that:
- Gather outputs out of your goal mannequin on consultant inputs
- Effective-tune a small mannequin to foretell those self same outputs
This further effort pays off while you want constant excessive efficiency in manufacturing. Learn Get 3× Quicker LLM Inference with Speculative Decoding Utilizing the Proper Draft Mannequin to be taught extra.
Wrapping Up
Speculative decoding provides a sensible solution to pace up massive language mannequin inference with out sacrificing output high quality. Through the use of a smaller draft mannequin to suggest a number of tokens and verifying them in parallel with the goal mannequin, you’ll be able to obtain 2–3× speedups or extra.
The approach works as a result of it addresses the basic memory-bound nature of enormous language mannequin inference, lowering the variety of occasions it’s essential to load the complete mannequin’s parameters from reminiscence. Whereas the effectiveness nonetheless relies on components like draft mannequin high quality and acceptance charge, speculative decoding is beneficial in manufacturing methods the place latency and price matter. To be taught extra, try the next sources:
We’ll cowl extra inference optimization strategies within the subsequent articles, exploring extra strategies to make your massive language mannequin functions quicker and more cost effective.














{kind=link}