


working with k-NN (k-NN regressor and k-NN classifier), we all know that the k-NN strategy may be very naive. It retains your complete coaching dataset in reminiscence, depends on uncooked distances, and doesn’t be taught any construction from the information.
We already started to enhance the k-NN classifier, and in immediately’s article, we’ll implement these totally different fashions:
- GNB: Gaussian Naive Bayes
- LDA: Linear Discriminant Evaluation
- QDA: Quadratic Discriminant Evaluation
For all these fashions, the distribution is taken into account as Gaussian. So on the finish, we may also see an strategy to get a extra custom-made distribution.
Should you learn my earlier article, listed here are some questions for you:
- What’s the relationship between LDA and QDA?
- What’s the relation between GBN and QDA?
- What occurs if the information shouldn’t be Gaussian in any respect?
- What’s the technique to get a custom-made distribution?
- What’s linear in LDA? What’s quadratic in QDA?
When studying by means of the article, you should use this Excel/Google sheet.

Nearest Centroids: What This Mannequin Actually Is
Let’s do a fast recap about what we already began yesterday.
We launched a easy concept: once we calculate the common of every steady function inside a category, that class collapses into one single consultant level.
This offers us the Nearest Centroids mannequin.
Every class is summarized by its centroid, the common of all its function values.
Now, allow us to take into consideration this from a Machine Studying perspective.
We often separate the method into two elements: the coaching step and the hyperparameter tuning step.
For Nearest Centroids, we will draw a small “mannequin card” to grasp what this mannequin actually is:
- How is the mannequin skilled? By computing one common vector per class. Nothing extra.
- Does it deal with lacking values? Sure. A centroid may be computed utilizing all out there (non-empty) values.
- Does scale matter? Sure, completely, as a result of distance to a centroid relies on the items of every function.
- What are the hyperparameters? None.
We mentioned that the k-NN classifier will not be an actual machine studying mannequin as a result of it’s not an precise mannequin.
For Nearest Centroids, we will say that it’s not actually a machine studying mannequin as a result of it can’t be tuned. So what about overfitting and underfitting?
Properly, the mannequin is so easy that it can not memorize noise in the identical manner k-NN does.
So, Nearest Centroids will solely are inclined to underfit when lessons are complicated or not properly separated, as a result of one single centroid can not seize their full construction.
Understanding Class Form with One Characteristic: Including Variance
Now, on this part, we’ll use just one steady function, and a couple of lessons.
To this point, we used just one statistic per class: the common worth.
Allow us to now add a second piece of knowledge: the variance (or equivalently, the usual deviation).
This tells us how “unfold out” every class is round its common.
A pure query seems instantly: Which variance ought to we use?
Essentially the most intuitive reply is to compute one variance per class, as a result of every class may need a unique unfold.
However there’s one other chance: we might compute one frequent variance for each lessons, often as a weighted common of the category variances.
This feels a bit unnatural at first, however we’ll see later that this concept leads on to LDA.
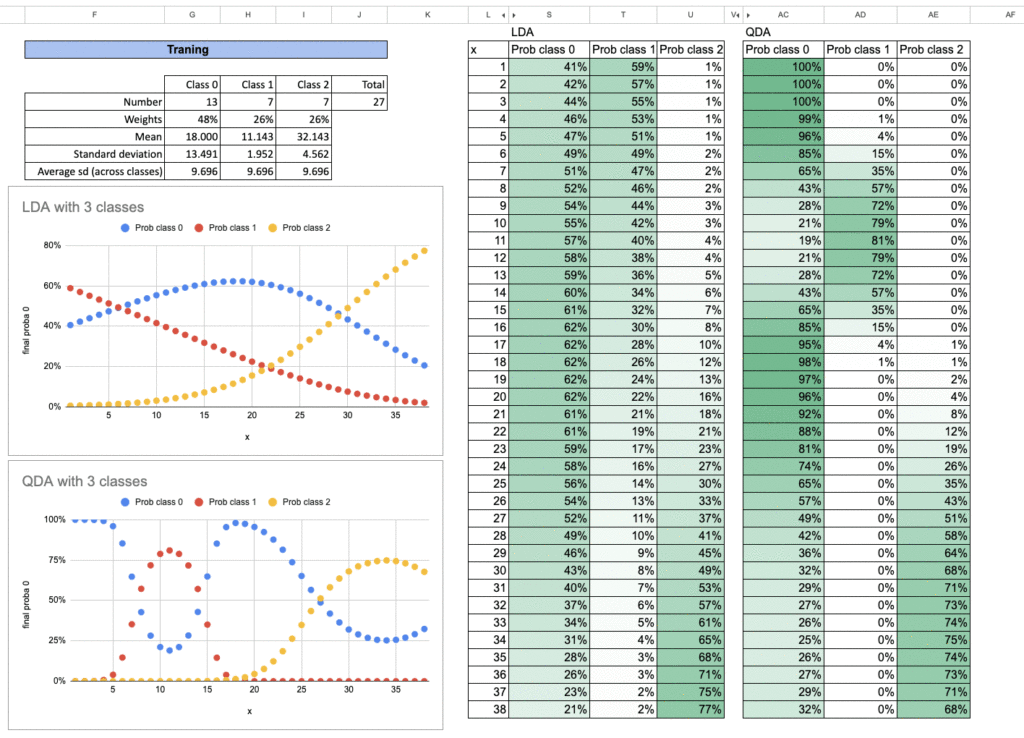
So the desk under offers us every thing we’d like for this mannequin, in actual fact, for each variations (LDA and QDA) of the mannequin.
- the variety of observations in every class (to weight the lessons)
- the imply of every class
- the usual deviation of every class
- and the frequent commonplace deviation throughout each lessons
With these values, your complete mannequin is totally outlined.

Now, as soon as we’ve a typical deviation, we will construct a extra refined distance: the space to the centroid divided by the usual deviation.
Why will we do that?
As a result of this provides a distance that’s scaled by how variable the category is.
If a category has a big commonplace deviation, being removed from its centroid is no surprise.
If a category has a really small commonplace deviation, even a small deviation turns into important.
This straightforward normalization turns our Euclidean distance into one thing slightly bit extra significant, that represents the form of every class.
This distance was launched by Mahalanobis, so we name it the Mahalanobis distance.
Now we will do all these calculations immediately within the Excel file.

The formulation are easy, and with conditional formatting, we will clearly see how the space to every middle adjustments and the way the scaling impacts the outcomes.

Now, let’s do some plots, all the time in Excel.
This diagram under exhibits the complete development: how we begin from the Mahalanobis distance, transfer to the probability beneath every class distribution, and at last receive the likelihood prediction.

LDA vs. QDA, what will we see?
With only one function, the distinction turns into very straightforward to visualise.
For LDA, the separation on the x-axis is all the time lower into two elements. This is the reason the strategy known as Linear Discriminant Evaluation.
For QDA, even with just one function, the mannequin produces two lower factors on the x-axis. In increased dimensions, this turns into a curved boundary, described by a quadratic operate. Therefore, the title Quadratic Discriminant Evaluation.

And you’ll immediately modify the parameters to see how they affect the choice boundary.
The adjustments within the means or variances will change the frontier, and Excel makes these results very straightforward to visualise.
By the best way, does the form of the LDA likelihood curve remind you of a mannequin that you just absolutely know? Sure, it seems to be precisely the identical.
You’ll be able to already guess which one, proper?
However now the true query is: are they actually the identical mannequin? And if not, how do they differ?

We will additionally research the case with three lessons. You’ll be able to do this your self as an train in Excel.
Listed below are the outcomes. For every class, we repeat precisely the identical process. And for the ultimate likelihood prediction, we merely sum all of the likelihoods and take the proportion of every one.

Once more, this strategy can be utilized in one other well-known mannequin.
Are you aware which one? It’s rather more acquainted to most individuals, and this exhibits how intently linked these fashions actually are.
If you perceive one in every of them, you robotically perceive the others significantly better.
Class Form in 2D: Variance Solely or Covariance as Properly?
With one function, we don’t speak about dependency, as there’s none. So on this case, QDA behaves precisely like Gaussian Naive Bayes. As a result of we often permit every class to have its personal variance, which is completely pure.
The distinction will seem once we transfer to 2 or extra options. At that time, we’ll distinguish instances of how the mannequin treats the covariance between the options.
Gaussian Naive Bayes makes one very robust simplifying assumption:
the options are impartial. That is the explanation for the phrase Naive in its title.
LDA and QDA, nonetheless, don’t make this assumption. They permit interactions between options, and that is what generates linear or quadratic boundaries in increased dimensions.
Let’s do the exercice in Excel!
Gaussian Naive Bayes: no covariance
Allow us to start with the only case: Gaussian Naive Bayes.
So, we don’t must compute any covariance in any respect, as a result of the mannequin assumes that the options are impartial.
As an example this, we will have a look at a small instance with three lessons.

QDA: every class has its personal covariance
For QDA, we now need to calculate the covariance matrix for every class.
And as soon as we’ve it, we additionally must compute its inverse, as a result of it’s used immediately within the system for the space and the probability.
So there are just a few extra parameters to compute in comparison with Gaussian Naive Bayes.

LDA: all lessons share the identical covariance
For LDA, all lessons share the identical covariance matrix, which reduces the variety of parameters and forces the choice boundary to be linear.
Though the mannequin is easier, it stays very efficient in lots of conditions, particularly when the quantity of knowledge is restricted.

Custom-made Class Distributions: Past the Gaussian Assumption
To this point, we solely talked about Gaussian distributions. And it’s for its simplificity. And we can also use different distributions. So even in Excel, it is rather straightforward to alter.
In actuality, information often don’t observe an ideal Gaussian curve.
For exploring a dataset, we use the empiric density plots virtually each time. They provide a direct visible feeling of how the information is distributed.
And the kernel density estimator (KDE) as a non-parametric technique, is usually used.
BUT, in follow, KDE is never used as a full classification mannequin. It isn’t very handy, and its predictions are sometimes delicate to the selection of bandwidth.
And what’s attention-grabbing is that this concept of kernels will come again once more once we focus on different fashions.
So despite the fact that we present it right here primarily for exploration, it’s a vital constructing block in machine studying.

Conclusion
Right this moment, we adopted a pure path that begins with easy averages and step by step results in full probabilistic fashions.
- Nearest Centroids compresses every class into one level.
- Gaussian Naive Bayes provides the notion of variance, and assumes the independance of the options.
- QDA offers every class its personal variance or covariance
- LDA simplifies the form by sharing the covariance.
We even noticed that we will step outdoors the Gaussian world and discover custom-made distributions.
All these fashions are linked by the identical concept: a brand new statement belongs to the category it most resembles.
The distinction is how we outline resemblance, by distance, by variance, by covariance, or by a full likelihood distribution.
For all these fashions, we will do the 2 steps simply in Excel:
- step one is to estimate the paramters, which may be thought-about because the mannequin coaching
- the inference step that’s to calculate the space and the likelihood for every class

Another factor
Earlier than closing this text, allow us to draw a small cartography of distance-based supervised fashions.
We now have two foremost households:
- native distance fashions
- international distance fashions
For native distance, we already know the 2 classical ones:
- k-NN regressor
- k-NN classifier
Each predict by taking a look at neighbors and utilizing the native geometry of the information.
For international distance, all of the fashions we studied immediately belong to the classification world.
Why?
As a result of international distance requires facilities outlined by lessons.
We measure how shut a brand new statement is to every class prototype?
However what about regression?
It appears that evidently this notion of world distance doesn’t exist for regression, or does it actually?
The reply is sure, it does exist…
















{kind=link}