


of this sequence, we’ll discuss deep studying.
And when individuals discuss deep studying, we instantly consider these pictures of deep neural networks architectures, with many layers, neurons, and parameters.
In follow, the true shift launched by deep studying is elsewhere.
It’s about studying information representations.
On this article, we concentrate on textual content embeddings, clarify their position within the machine studying panorama, and present how they are often understood and explored in Excel.
1. Basic Machine incomes vs. Deep studying
We are going to focus on, on this half, why embedding is launched.
1.1 The place does deep studying match?
To grasp embeddings, we first have to make clear the place of deep studying.
We are going to use the time period basic machine studying to explain strategies that don’t depend on deep architectures.
All of the earlier articles take care of basic machine studying, that may be described in two complementary methods.
Studying paradigms
- Supervised studying
- Unsupervised studying
Mannequin households
- Distance-based fashions
- Tree-based fashions
- Weight-based fashions
Throughout this sequence, now we have already studied the educational algorithms behind these fashions. Particularly, now we have seen that gradient descent applies to all weight-based fashions, from linear regression to neural networks.
Deep studying is commonly diminished to neural networks with many layers.
However this rationalization is incomplete.
From an optimization viewpoint, deep studying doesn’t introduce a brand new studying rule.
So what does it introduce?
1.2 Deep studying as information illustration studying
Deep studying is about how options are created.
As a substitute of manually designing options, deep studying learns representations routinely, usually by a number of successive transformations.
This additionally raises an essential conceptual query:
The place is the boundary between function engineering and mannequin studying?
Some examples make this clearer:
- Polynomial regression remains to be a linear mannequin, however the options are polynomial
- Kernel strategies venture information right into a high-dimensional function area
- Density-based strategies implicitly remodel the info earlier than studying
Deep studying continues this concept, however at scale.
From this angle, deep studying belongs to:
- the function engineering philosophy, for illustration
- the weight-based mannequin household, for studying
1.3 Pictures and convolutional neural networks
Pictures are represented as pixels.
From a technical viewpoint, picture information is already numerical and structured: a grid of numbers. Nonetheless, the info contained in these pixels is just not structured in a means that classical fashions can simply exploit.
Pixels don’t explicitly encode: edges, shapes, textures, or objects.
Convolutional Neural Networks (CNNs) are designed to create info from pixels. They apply filters to detect native patterns, then progressively mix them into higher-level representations.
I’ve revealed a this text displaying how CNNs will be applied in Excel to make this course of specific.

For pictures, the problem is not to make the info numerical, however to extract significant representations from already numerical information.
1.4 Textual content information: a distinct drawback
Textual content presents a essentially completely different problem.
In contrast to pictures, textual content is not numerical by nature.
Earlier than modeling context or order, the primary drawback is extra primary:
How will we characterize phrases numerically?
Making a numerical illustration for textual content step one.
In deep studying for textual content, this step is dealt with by embeddings.
Embeddings remodel discrete symbols (phrases) into vectors that fashions can work with. As soon as embeddings exist, we are able to then mannequin: context, order and relationships between phrases.
On this article, we concentrate on this primary and important step:
how embeddings create numerical representations for textual content, and the way this course of will be explored in Excel.
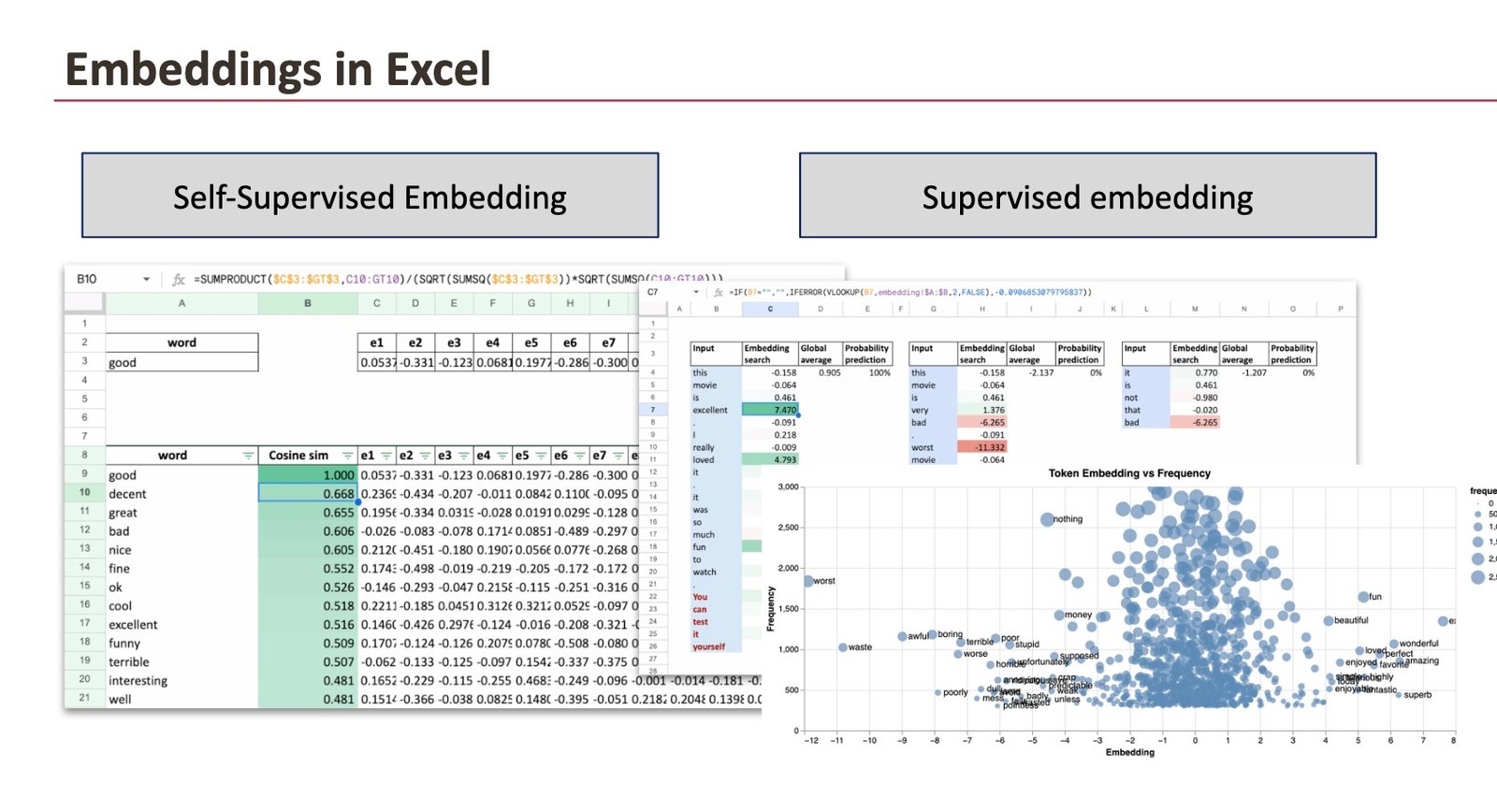
2. Two methods to be taught textual content embeddings
On this article, we’ll use the IMDB film opinions dataset as an example each approaches. The dataset is distributed underneath the Apache License 2.0.
There are two most important methods to be taught embeddings for textual content, and we’ll do each with this dataset:
- supervised: we’ll create embeddings to foretell the sentiment
- unsupervised or self-supervised: we’ll use word2vec algorithm
In each circumstances, the objective is similar:
to rework phrases into numerical vectors that can be utilized by machine studying fashions.
Earlier than evaluating these two approaches, we first have to make clear what embeddings are and the way they relate to basic machine studying.

2.1 Embeddings and basic machine studying
In basic machine studying, categorical information is often dealt with with:
- label encoding, which assigns mounted integers however introduces synthetic order
- one-hot encoding, which removes order however produces high-dimensional sparse vectors
How they can be utilized rely on the character of the fashions.
Distance-based fashions can’t successfully use one-hot encoding, as a result of all classes find yourself being equally distant from one another. Label encoding might work provided that we are able to attribute significant numerical values for the classes, which is mostly not the case in basic fashions.
Weight-based fashions can use one-hot encoding, as a result of the mannequin learns a weight for every class. In distinction, with label encoding, the numerical values are mounted and can’t be adjusted to characterize significant relationships.
Tree-based fashions deal with all variables as categorical splits quite than numerical magnitudes, which makes label encoding acceptable in follow. Nonetheless, most implementations, together with scikit-learn, nonetheless require numerical inputs. In consequence, classes should be transformed to numbers, both by label encoding or one-hot encoding. If the numerical values carried semantic that means, this is able to once more be useful.
Total, this highlights a limitation of basic approaches:
class values are mounted and never discovered.
Embeddings prolong this concept by studying the illustration itself.
Every phrase is related to a trainable vector, turning the illustration of classes right into a studying drawback quite than a preprocessing step.
2.2 Supervised embeddings
In supervised studying, embeddings are discovered as a part of a prediction job.
For instance, the IMDB dataset has labels in regards to the in sentiment evaluation. So we are able to create a quite simple structure:
In our case, we are able to use a quite simple structure: every phrase is mapped to a one-dimensional embedding
That is attainable as a result of the target is binary sentiment classification.

As soon as coaching is full, we are able to export the embeddings and discover them in Excel.
When plotting the embeddings on the x-axis and phrase frequency on the y-axis, a transparent sample seems:
- constructive values are related to phrases corresponding to glorious or great,
- destructive values are related to phrases corresponding to worst or waste
Relying on the initialization, the signal will be inverted, for the reason that logistic regression layer additionally has parameters that affect the ultimate prediction.

Lastly, in Excel, we reconstruct the total pipeline that corresponds to the structure we outline early.
Enter column
The enter textual content (a assessment) is lower into phrases, and every row corresponds to 1 phrase.
Embedding search
Utilizing a lookup perform, the embedding worth related to every phrase is retrieved from the embedding desk discovered throughout coaching.
World common
The worldwide common embedding is computed by averaging the embeddings of all phrases seen to date. This corresponds to a quite simple sentence illustration: the imply of phrase vectors.
Chance prediction
The averaged embedding is then handed by a logistic perform to supply a sentiment likelihood.

What we observe
- Phrases with strongly constructive embeddings (for instance glorious, love, enjoyable) push the common upward.
- Phrases with strongly destructive embeddings (for instance worst, horrible, waste) pull the common downward.
- Impartial or weakly weighted phrases have little affect.
As extra phrases are added, the worldwide common embedding stabilizes, and the sentiment prediction turns into extra assured.
2.3 Word2Vec: embeddings from co-occurrence
In Word2Vec, similarity doesn’t imply that two phrases have the identical that means.
It implies that they seem in related contexts.
Word2Vec learns phrase embeddings by taking a look at which phrases are likely to co-occur inside a hard and fast window within the textual content. Two phrases are thought of related in the event that they usually seem across the identical neighboring phrases, even when their meanings are reverse.
As proven within the Excel sheet beneath, we compute the cosine similarity for the phrase good and retrieve essentially the most related phrases.

From the mannequin’s perspective, the encircling phrases are nearly an identical. The one factor that modifications is the adjective itself.
In consequence, Word2Vec learns that “good” and “unhealthy” play the same position in language, though their meanings are reverse.
So, Word2Vec captures distributional similarity, not semantic polarity.
A helpful means to consider it’s:
Phrases are shut if they’re utilized in the identical locations.
2.4 How embeddings are used
In fashionable methods corresponding to RAG (Retrieval-Augmented Technology), embeddings are sometimes used to retrieve paperwork or passages for query answering.
Nonetheless, this strategy has limitations.
Mostly used embeddings are skilled in a self-supervised means, primarily based on co-occurrence or contextual prediction goals. In consequence, they seize common language similarity, not task-specific that means.
Because of this:
- embeddings could retrieve textual content that’s linguistically related however not related
- semantic proximity doesn’t assure reply correctness
Different embedding methods can be utilized, together with task-adapted or supervised embeddings, however they usually stay self-supervised at their core.
Understanding how embeddings are created, what they encode, and what they don’t encode is due to this fact important earlier than utilizing them in downstream methods corresponding to RAG.
Conclusion
Embeddings are discovered numerical representations of phrases that make similarity measurable.
Whether or not discovered by supervision or by co-occurrence, embeddings map phrases to vectors primarily based on how they’re utilized in information. By exporting them to Excel, we are able to examine these representations immediately, compute similarities, and perceive what they seize and what they don’t.
This makes embeddings much less mysterious and clarifies their position as a basis for extra advanced methods corresponding to retrieval or RAG.















{kind=link}