


, we ensemble studying with voting, bagging and Random Forest.
Voting itself is barely an aggregation mechanism. It doesn’t create variety, however combines predictions from already completely different fashions.
Bagging, then again, explicitly creates variety by coaching the identical base mannequin on a number of bootstrapped variations of the coaching dataset.
Random Forest extends bagging by moreover limiting the set of options thought of at every break up.
From a statistical viewpoint, the thought is easy and intuitive: variety is created by means of randomness, with out introducing any basically new modeling idea.
However ensemble studying doesn’t cease there.
There exists one other household of ensemble strategies that doesn’t depend on randomness in any respect, however on optimization. Gradient Boosting belongs to this household. And to really perceive it, we are going to begin with a intentionally unusual thought:
We are going to apply Gradient Boosting to Linear Regression.
Sure, I do know. That is most likely the primary time you’ve got heard about making use of Gradient Boosted Linear Regression.
(We are going to see Gradient Boosted Choice Timber, tomorrow).
On this article, right here is the plan:
- First, we are going to step again and revisit the three elementary steps of machine studying.
- Then, we are going to introduce the Gradient Boosting algorithm.
- Subsequent, we are going to apply Gradient Boosting to linear regression.
- Lastly, we are going to replicate on the connection between Gradient Boosting and Gradient Descent.
1. Machine Studying in Three steps
To make machine studying simpler to be taught, I all the time separate it into three clear steps. Allow us to apply this framework to Gradient Boosted Linear Regression.
As a result of not like bagging, every step reveals one thing attention-grabbing.

1. Mannequin
A mannequin is one thing that takes enter options and produces an output prediction.
On this article, the bottom mannequin shall be Linear Regression.
1 bis. Ensemble Methodology Mannequin
Gradient Boosting is not a mannequin itself. It’s an ensemble technique that aggregates a number of base fashions right into a single meta-model. By itself, it doesn’t map inputs to outputs. It have to be utilized to a base mannequin.
Right here, Gradient Boosting shall be used to mixture linear regression fashions.
2. Mannequin becoming
Every base mannequin have to be fitted to the coaching knowledge.
For Linear Regression, becoming means estimating the coefficients. This may be performed numerically utilizing Gradient Descent, but in addition analytically. In Google Sheets or Excel, we are able to immediately use the LINEST perform to estimate these coefficients.
2 bis. Ensemble mannequin studying
At first, Gradient Boosting could appear like a easy aggregation of fashions. However it’s nonetheless a studying course of. As we are going to see, it depends on a loss perform, precisely like classical fashions that be taught weights.
3. Mannequin tuning
Mannequin tuning consists of optimizing hyperparameters.
In our case, the bottom mannequin Linear Regression itself has no hyperparameters (except we use regularized variants reminiscent of Ridge or Lasso).
Gradient Boosting, nevertheless, introduces two necessary hyperparameters: the variety of boosting steps and the training fee. We are going to see this within the subsequent part.
In a nutshell, that’s machine studying, made simple, in three steps!
2. Gradient Boosting Regressor algorithm
2.1 Algorithm precept
Listed below are the principle steps of the Gradient Boosting algorithm, utilized to regression.
- Initialization: We begin with a quite simple mannequin. For regression, that is often the typical worth of the goal variable.
- Residual Errors Calculation: We compute residuals, outlined because the distinction between the precise values and the present predictions.
- Becoming Linear Regression to Residuals: We match a brand new base mannequin (right here, a linear regression) to those residuals.
- Replace the ensemble : We add this new mannequin to the ensemble, scaled by a studying fee (additionally known as shrinkage).
- Repeating the method: We repeat steps 2 to 4 till we attain the specified variety of boosting iterations or till the error converges.
That’s it! That is the essential process for performing a Gradient Boosting utilized to Linear Regression.
2.2 Algorithm expressed with formulation
Now we are able to write the formulation explicitly, it helps make every step concrete.
Step 1 – Initialization
We begin with a continuing mannequin equal to the typical of the goal variable:
f0 = common(y)
Step 2 – Residual computation
We compute the residuals, outlined because the distinction between the precise values and the present predictions:
r1 = y − f0
Step 3 – Match a base mannequin to the residuals
We match a linear regression mannequin to those residuals:
r̂1 = a0 · x + b0
Step 4 – Replace the ensemble
We replace the mannequin by including the fitted regression, scaled by the training fee:
f1 = f0 − learning_rate · (a0 · x + b0)
Subsequent iteration
We repeat the identical process:
r2 = y − f1
r̂2 = a1 · x + b1
f2 = f1 − learning_rate · (a1 · x + b1)
By increasing this expression, we get hold of:
f2 = f0 − learning_rate · (a0 · x + b0) − learning_rate · (a1 · x + b1)
The identical course of continues at every iteration. Residuals are recomputed, a brand new mannequin is fitted, and the ensemble is up to date by including this mannequin with a studying fee.
This formulation makes it clear that Gradient Boosting builds the ultimate mannequin as a sum of successive correction fashions.
3. Gradient Boosted Linear Regression
3.1 Base mannequin coaching
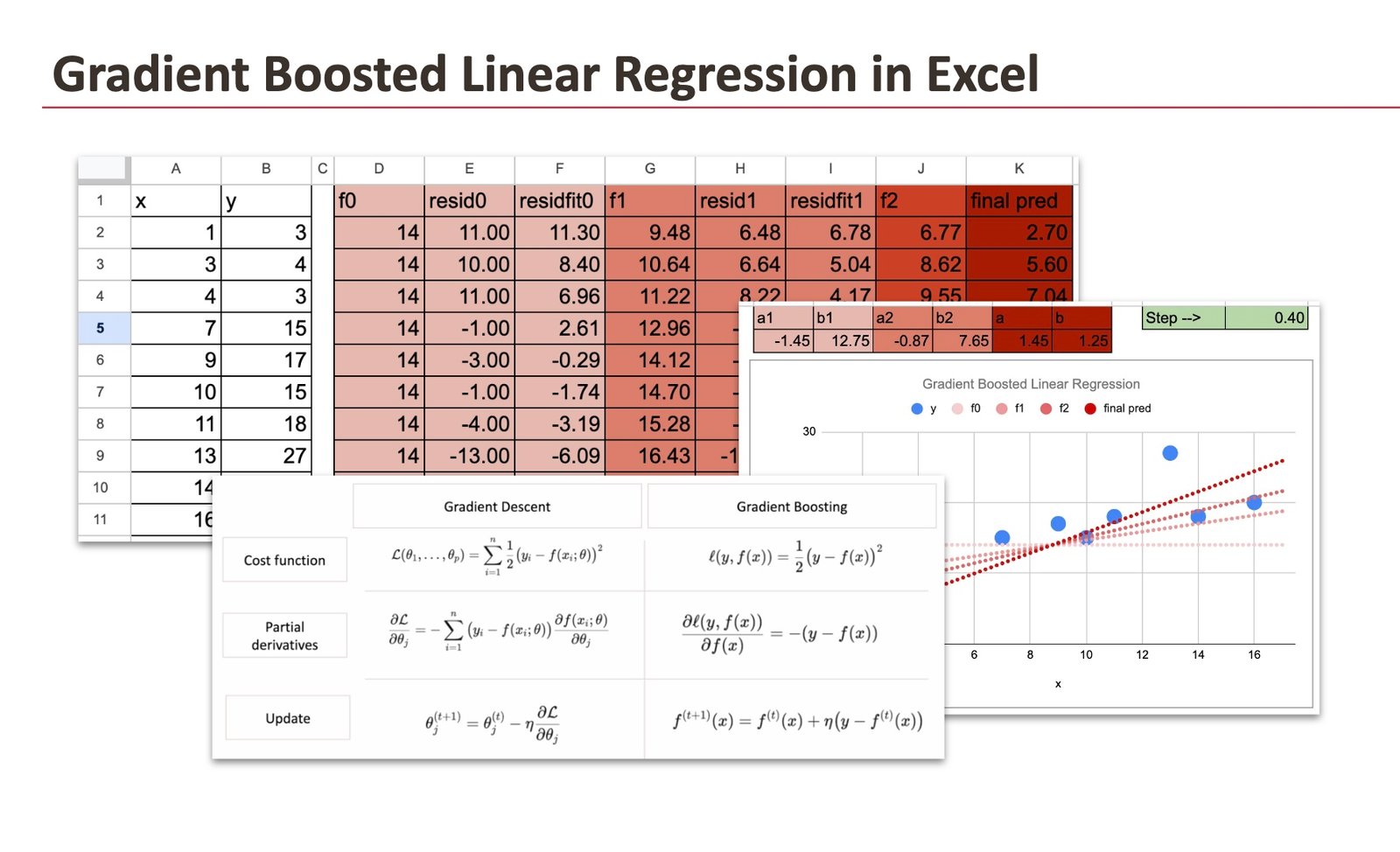
We begin with a easy linear regression as our base mannequin, utilizing a small dataset of ten observations that I generated.
For the becoming of the bottom mannequin, we are going to use a perform in Google Sheet (it additionally works in Excel): LINEST to estimate the coefficients of the linear regression.

3.2 Gradient Boosting algorithm
The implementation of those formulation is simple in Google Sheet or Excel.
The desk beneath reveals the coaching dataset together with the completely different steps of the gradient boosting steps:

For every becoming step, we use the Excel perform LINEST:

We are going to solely do 2 iterations, and we are able to guess the way it goes for extra iterations. Right here beneath is a graphic to point out the fashions at every iteration. The completely different shades of pink illustrate the convergence of the mannequin and we additionally present the ultimate mannequin that’s immediately discovered with gradient descent utilized on to y.

3.3 Why Boosting Linear Regression is only pedagogical
When you look fastidiously on the algorithm, two necessary observations emerge.
First, in step 2, we match a linear regression to residuals, it can take time and algorithmic steps to realize the mannequin becoming steps, as an alternative of becoming a linear regression to residuals, we are able to immediately match a linear regression to the precise values of y, and we already would discover the ultimate optimum mannequin!
Secondly, when including a linear regression to a different linear regression, it’s nonetheless a linear regression.
For instance, we are able to rewrite f2 as:
f2 = f0 - learning_rate *(b0+b1) - learning_rate * (a0+a1) x
That is nonetheless a linear perform of x.
This explains why Gradient Boosted Linear Regression doesn’t convey any sensible profit. Its worth is only pedagogical: it helps us perceive how the Gradient Boosting algorithm works, however it doesn’t enhance predictive efficiency.
In reality, it’s even much less helpful than bagging utilized to linear regression. With bagging, the variability between bootstrapped fashions permits us to estimate prediction uncertainty and assemble confidence intervals. Gradient Boosted Linear Regression, then again, collapses again to a single linear mannequin and gives no further details about uncertainty.
As we are going to see tomorrow, the scenario could be very completely different when the bottom mannequin is a choice tree.
3.4 Tuning hyperparameters
There are two hyperparameters we are able to tune: the variety of iterations and the training fee.
For the variety of iterations, we solely applied two, however it’s simple to think about extra, and we are able to cease by inspecting the magnitude of the residuals.
For the training fee, we are able to change it in Google Sheet and see what occurs. When the training fee is small, the “studying course of” shall be sluggish. And if the training fee is 1, we are able to see that the convergence is achieved at iteration 1.

And the residuals of iteration 1 are already zeros.

If the training fee is increased than 1, then the mannequin will diverge.

4. Boosting as Gradient Descent in Perform Area
4.1 Comparability with Gradient Descent Algorithm
At first look, the function of the training fee and the variety of iterations in Gradient Boosting seems similar to what we see in Gradient Descent. This naturally results in confusion.
- Newcomers typically discover that each algorithms include the phrase “gradient” and observe an iterative process. It’s subsequently tempting to imagine that Gradient Descent and Gradient Boosting are carefully associated, with out actually understanding why.
- Skilled practitioners often react in a different way. From their perspective, the 2 strategies seem unrelated. Gradient Descent is used to suit weight-based fashions by optimizing their parameters, whereas Gradient Boosting is an ensemble technique that mixes a number of fashions fitted with the residuals. The use circumstances, the implementations, and the instinct appear utterly completely different.
- At a deeper degree, nevertheless, consultants will say that these two algorithms are actually the identical optimization thought. The distinction doesn’t lie within the studying rule, however within the area the place this rule is utilized. Or we are able to say that the variable of curiosity is completely different.
Gradient Descent performs gradient-based updates in parameter area. Gradient Boosting performs gradient-based updates in perform area.
That’s the solely distinction on this mathematical numerical optimization. Let’s see the equations within the case of regression and within the basic case beneath.
4.2 The Imply Squared Error Case: Identical Algorithm, Totally different Area
With the Imply Squared Error, Gradient Descent and Gradient Boosting reduce the identical goal and are pushed by an identical quantity: the residual.
In Gradient Descent, residuals affect the updates of the mannequin parameters.
In Gradient Boosting, residuals immediately replace the prediction perform.
In each circumstances, the training fee and the variety of iterations play the identical function. The distinction lies solely in the place the replace is utilized: parameter area versus perform area.
As soon as this distinction is obvious, it turns into evident that Gradient Boosting with MSE is just Gradient Descent expressed on the degree of capabilities.

4.3 Gradient Boosting with any loss perform
The comparability above isn’t restricted to the Imply Squared Error. Each Gradient Descent and Gradient Boosting may be outlined with respect to completely different loss capabilities.
In Gradient Descent, the loss is outlined in parameter area. This requires the mannequin to be differentiable with respect to its parameters, which naturally restricts the strategy to weight-based fashions.
In Gradient Boosting, the loss is outlined in prediction area. Solely the loss have to be differentiable with respect to the predictions. The bottom mannequin itself doesn’t should be differentiable, and naturally, it doesn’t have to have its personal loss perform.
This explains why Gradient Boosting can mix arbitrary loss capabilities with non–weight-based fashions reminiscent of resolution timber.

Conclusion
Gradient Boosting isn’t just a naive ensemble method however an optimization algorithm. It follows the identical studying logic as Gradient Descent, differing solely within the area the place the optimization is carried out: parameters versus capabilities. Utilizing linear regression allowed us to isolate this mechanism in its easiest type.
Within the subsequent article, we are going to see how this framework turns into really highly effective when the bottom mannequin is a choice tree, resulting in Gradient Boosted Choice Tree Regressors.
All of the Excel recordsdata can be found by means of this Kofi hyperlink. Your help means lots to me. The worth will enhance through the month, so early supporters get the perfect worth.

















{kind=link}