


This text was a collaborative effort. A particular thanks to Estevão Prado, whose experience helped refine each the technical ideas and the narrative move.
Characteristic choice stays one of the vital vital but computationally costly steps within the machine studying pipeline. When working with high-dimensional datasets, figuring out which options actually contribute to predictive energy can imply the distinction between an interpretable, environment friendly mannequin and an overfit, sluggish one.
On this article, I current the Grasping Boruta algorithm—a modification to the Boruta algorithm [1] that, in our checks, reduces computation time by 5-40× whereas mathematically provably sustaining or bettering recall. Via theoretical evaluation and simulation experiments, I show how a easy leisure of the affirmation criterion gives assured convergence in O(-log α) iterations, the place α is the boldness stage of the binomial checks, in comparison with the vanilla algorithm’s unbounded runtime.
The Boruta algorithm has lengthy been a favourite amongst information scientists for its “all-relevant” method to function choice and its statistical framework. In contrast to minimal-optimal strategies, comparable to Minimal Redundancy Most Relevance (mRMR) and recursive function elimination (RFE), that search the smallest set of options for prediction, Boruta goals to determine all options that carry helpful info. This philosophical distinction issues tremendously when the purpose is knowing a phenomenon somewhat than merely making predictions, for example.
Nevertheless, Boruta’s thoroughness comes at a excessive computational price. In real-world purposes with a whole bunch or hundreds of options, the algorithm can take prohibitively lengthy to converge. That is the place the Grasping Boruta Algorithm enters the image.
Understanding the vanilla Boruta algorithm
Earlier than inspecting the modification, let’s recap how the vanilla Boruta algorithm works.
Boruta’s genius lies in its elegant method to figuring out function significance. Slightly than counting on arbitrary thresholds or p-values straight from a mannequin, it creates a aggressive benchmark utilizing shadow options.
Right here’s the method:
- Shadow function creation: For every function within the dataset, Boruta creates a “shadow” copy by randomly shuffling its values. This destroys any relationship the unique function had with the response (or goal) variable whereas preserving its distribution.
- Significance computation: A Random Forest is educated on the mixed dataset and have importances are calculated for all options. Though Boruta was initially proposed for Random Forest estimators, the algorithm can work with another tree-based ensemble that gives function significance scores (e.g., Additional Timber [2], XGBoost [3], LightGBM [4]).
- Hit registration: For every non-shadow function, Boruta checks whether or not the significance of the function is bigger than the utmost significance of the shadows. Non-shadow options which are extra vital than the utmost shadow are assigned a “hit” and those which are much less vital are assigned “no-hit”.
- Statistical testing: Primarily based on the lists of hits and no-hits for every of the non-shadow options, Boruta performs a binomial take a look at to find out if its significance is considerably higher than the utmost significance amongst shadow options throughout a number of iterations.
- Determination making: Options that persistently outperform one of the best shadow function are marked as “confirmed.” Options that persistently underperform are “rejected.” Options within the center (these that aren’t statistically considerably completely different from one of the best shadow) stay “tentative”.
- Iteration: Steps 2–5 repeat till all options are labeled as confirmed or rejected. On this article, I say that the Boruta algorithm “has converged” when all options are both confirmed or rejected or when a most variety of iterations has been reached.
The binomial take a look at: Boruta’s resolution criterion
The vanilla Boruta makes use of a rigorous statistical framework. After a number of iterations, the algorithm performs a binomial take a look at on the hits for every of the non-shadow options:
- Null speculation: The function isn’t any higher than one of the best shadow function (50% likelihood of beating shadows by random likelihood).
- Different speculation: The function is healthier than one of the best shadow function.
- Affirmation criterion: If the binomial take a look at p-value is beneath α (usually between 0.05–0.01), the function is confirmed.
This similar course of can also be accomplished to reject options:
- Null speculation: The function is healthier than one of the best shadow (50% likelihood of not beating shadows by random likelihood).
- Different speculation: The function isn’t any higher than one of the best shadow function.
- Rejection criterion: If the binomial take a look at p-value is beneath α, the function is rejected.
This method is statistically sound and conservative; nonetheless, it requires many iterations to build up ample proof, particularly for options which are related however solely marginally higher than noise.
The convergence drawback
The vanilla Boruta algorithm faces two main convergence points:
Lengthy runtime: As a result of the binomial take a look at requires many iterations to achieve statistical significance, the algorithm may require a whole bunch of iterations to categorise all options, particularly when utilizing small α values for top confidence. Moreover, there aren’t any ensures or estimates for convergence, that’s, there is no such thing as a method to decide what number of iterations can be required for all of the options to be categorized into “confirmed” or “rejected”.
Tentative options: Even after reaching a most variety of iterations, some options could stay within the “tentative” class, leaving the analyst with incomplete info.
These challenges motivated the event of the Grasping Boruta Algorithm.
The Grasping Boruta algorithm
The Grasping Boruta Algorithm introduces a basic change to the affirmation criterion that dramatically improves convergence pace whereas sustaining excessive recall.
The identify comes from the algorithm’s keen method to affirmation. Like grasping algorithms that make regionally optimum selections, Grasping Boruta instantly accepts any function that reveals promise, with out ready to build up statistical proof. This trade-off favors pace and sensitivity over specificity.
Relaxed affirmation
As a substitute of requiring statistical significance by means of a binomial take a look at, the Grasping Boruta confirms any function that has overwhelmed the utmost shadow significance a minimum of as soon as throughout all iterations, whereas retaining the identical rejection criterion.
The rationale behind this leisure is that in “all-relevant” function choice, because the identify suggests, we usually prioritize retaining all related options over eliminating all irrelevant options. The additional elimination of the non-relevant options might be accomplished with “minimal-optimal” function choice algorithms downstream within the machine studying pipeline. Due to this fact, this leisure is virtually sound and produces the anticipated outcomes from an “all-relevant” function choice algorithm.
This seemingly easy change has a number of vital implications:
- Maintained recall: As a result of we’re enjoyable the affirmation criterion (making it simpler to substantiate options), we will by no means have decrease recall than the vanilla Boruta. Any function that’s confirmed by the vanilla methodology may also be confirmed by the grasping model. This may be simply confirmed since it’s unimaginable for a function to be deemed extra vital than one of the best shadow within the binomial take a look at and not using a single hit.
- Assured Convergence in Okay iterations: As can be proven beneath, this variation makes it in order that it’s doable to compute what number of iterations are required till all options are both confirmed or rejected.
- Quicker convergence: As a direct consequence of the purpose above, the Grasping Boruta algorithm wants far much less iterations than the vanilla Boruta for all options to be sorted. Extra particularly, the minimal variety of iterations for the vanilla algorithm to type its “first batch” of options is similar at which the grasping model finishes working.
- Hyperparameter Simplification: One other consequence of the assured convergence is that a few of the parameters used within the vanilla Boruta algorithm, comparable to max_iter (most variety of iterations), early_stopping (boolean figuring out whether or not the algorithm ought to cease earlier if no change is seen throughout plenty of iterations) and n_iter_no_change (minimal variety of iterations with no change earlier than early stopping is triggered), might be fully eliminated with out loss in flexibility. This simplification improves the algorithm’s usability and makes the function choice course of simpler to handle.
The modified algorithm
The Grasping Boruta algorithm follows this course of:
- Shadow function creation: Precisely the identical because the vanilla Boruta. Shadow options are created based mostly on every of the options of the dataset.
- Significance computation: Precisely the identical because the vanilla Boruta. Characteristic significance scores are computed based mostly on any tree-based ensemble machine studying algorithm.
- Hit registration: Precisely the identical because the vanilla Boruta. Assigns hits to non-shadow options which are extra vital than an important shadow function.
- Statistical testing: Primarily based on the lists of no-hits for every of the non-shadow function, Grasping Boruta performs a binomial take a look at to find out whether or not its significance isn’t considerably higher than the utmost significance amongst shadow options throughout a number of iterations.
- Determination making [Modified]: Options with a minimum of one hit are confirmed. Options that persistently underperform in relation to one of the best shadow are “rejected.” Options with zero hits stay “tentative”.
- Iteration: Steps 2–5 repeat till all options are labeled as confirmed or rejected.
This grasping model is predicated on the unique boruta_py [5] implementation with a number of tweaks, so most issues are stored the identical as this implementation, apart from the modifications talked about above.
Statistical perception on convergence assure
One of the crucial elegant properties of the Grasping Boruta Algorithm is its assured convergence inside a specified variety of iterations that is determined by the chosen α worth.
Due to the relaxed affirmation criterion, we all know that any function with a number of hits is confirmed and we don’t have to run binomial checks for affirmation. Conversely, we all know that each tentative function has zero hits. This truth drastically simplifies the equation representing the binomial take a look at required to reject options.
Extra particularly, the binomial take a look at is simplified as follows. Contemplating the one-sided binomial take a look at described above for rejection within the vanilla Boruta algorithm, with H₀ being p = p₀ and H₁ being p < p₀, the p-value is calculated as:

This system sums the possibilities of observing okay successes for all values from okay = 0 as much as the noticed x. Now, given the recognized values on this state of affairs (p₀ = 0.5 and x = 0), the system simplifies to:

To reject H₀ at significance stage α, we want:

Substituting our simplified p-value:

Taking the reciprocal (and reversing the inequality):

Taking logarithms base 2 of each side:

Due to this fact, the pattern dimension required is:

This means that at most ⌈ log₂(1/α)⌉ iterations of the Grasping Boruta algorithm are run till all options are sorted into both “confirmed” or “rejected” and convergence has been achieved. Which means the Grasping Boruta algorithm has O(-log α) complexity.
One other consequence of all tentative options having 0 hits is the truth that we will additional optimize the algorithm by not working any statistical checks throughout iterations.
Extra particularly, given α, it’s doable to find out the utmost variety of iterations Okay required to reject a variable. Due to this fact, for each iteration < Okay, if a variable has a success, it’s confirmed, and if it doesn’t, it’s tentative (for the reason that p-value for all iterations < Okay can be higher than α). Then, at precisely iteration Okay, all variables which have 0 hits might be moved into the rejected class with no binomial checks being run, since we all know that the p-values will all be smaller than α at this level.
This additionally signifies that, for a given α, the full variety of iterations run by the Grasping Boruta algorithm is the same as the minimal variety of iterations it takes for the vanilla implementation to both verify or reject any function!
Lastly, you will need to observe that the boruta_py implementation makes use of False Discovery Charge (FDR) correction to account for the elevated likelihood of false positives when performing a number of speculation checks. In follow, the required worth of Okay isn’t precisely as proven within the equation above, however the complexity in relation to α continues to be logarithmic.
The desk beneath comprises the variety of required iterations for various α values with the correction utilized:

Simulation experiments
To empirically consider the Grasping Boruta Algorithm, I performed experiments utilizing artificial datasets the place the bottom fact is understood. This method permits exact measurement of the algorithm’s efficiency.
Methodology
Artificial information technology: I created datasets with a recognized set of vital and unimportant options utilizing sklearn’s make_classification operate, permitting for direct computation of choice efficiency metrics. Moreover, these datasets embrace ‘redundant options’—linear mixtures of informative options that carry predictive info however should not strictly mandatory for prediction. Within the ‘all-relevant’ paradigm, these options ought to ideally be recognized as vital since they do comprise sign, even when that sign is redundant. The analysis subsequently considers informative options and redundant options collectively because the ‘floor fact related set’ when computing recall.
Metrics: Each algorithms are evaluated on:
- Recall (Sensitivity): What quantity of actually vital options had been appropriately recognized?
- Specificity: What quantity of actually unimportant options had been appropriately rejected?
- F1 Rating: The harmonic imply of precision and recall, balancing the trade-off between appropriately figuring out vital options and avoiding false positives
- Computational time: Wall-clock time to completion
Experiment 1 – Various α
Dataset traits
X_orig, y_orig = sklearn.make_classification(
n_samples=1000,
n_features=500,
n_informative=5,
n_redundant=50, # LOTS of redundant options correlated with informative
n_repeated=0,
n_clusters_per_class=1,
flip_y=0.3, # Some label noise
class_sep=0.0001,
random_state=42
)This constitutes a “laborious” function choice drawback due to the excessive dimensionality (500 variables), with a small pattern dimension (1000 samples), small variety of related options (sparse drawback, with round 10% of the options being related in any method) and pretty excessive label noise. You will need to create such a “laborious” drawback to successfully evaluate the performances of the strategies, in any other case, each strategies obtain near-perfect outcomes after only some iterations.
Hyperparameters used
On this experiment, we assess how the algorithms carry out with completely different α, so we evaluated each strategies utilizing α from the record [0.00001, 0.0001, 0.001, 0.01, 0.1, 0.2].
Relating to the hyperparameters of the Boruta and Grasping Boruta algorithms, each use an sklearn ExtraTreesClassifier because the estimator with the next parameters:
ExtraTreesClassifier(
n_estimators: 500,
max_depth: 5,
n_jobs: -1,
max_features: 'log2'
)The Additional Timber classifier was chosen because the estimator due to its quick becoming time and the truth that it’s extra steady when contemplating function significance estimation duties [2].
Lastly, the vanilla Boruta makes use of no early stopping (this parameter is not sensible within the context of Grasping Boruta).
Variety of trials
The vanilla Boruta algorithm is configured to run at most 512 iterations however with a early stopping situation. Which means if no modifications are seen in X iterations (n_iter_no_change), the run stops. For every α, a price of n_iter_no_change is outlined as follows:

Early stopping is enabled as a result of a cautious person of the vanilla Boruta algorithm would set this if the wall-clock time of the algorithm run is high-enough, and is a extra wise use of the algorithm general.
These early stopping thresholds had been chosen to stability computational price with convergence chance: smaller thresholds for bigger α values (the place convergence is quicker) and bigger thresholds for smaller α values (the place statistical significance takes extra iterations to build up). This displays how a sensible person would configure the algorithm to keep away from unnecessarily lengthy runtimes.
Outcomes: efficiency comparability

Key discovering: As offered within the left-most panel of determine 1, Grasping Boruta achieves recall that’s higher than or equal to that of the vanilla Boruta throughout all experimental circumstances. For the 2 smallest α values, the recall is equal and for the others, the Grasping Boruta implementation has barely higher recall, confirming that the relaxed affirmation criterion doesn’t miss options that the vanilla methodology would catch.
Noticed trade-off: Grasping Boruta reveals modestly decrease specificity in some settings, confirming that the relaxed criterion does lead to extra false positives. Nevertheless, the magnitude of this impact is smaller than anticipated, leading to solely 2-6 further options being chosen on this dataset with 500 variables. This elevated false-positive fee is appropriate in most downstream pipelines for 2 causes: (1) absolutely the variety of further options is small (2-6 options on this 500-feature dataset), and (2) subsequent modeling steps (e.g., regularization, cross-validation, or minimal-optimal function choice) can filter these options if they don’t contribute to predictive efficiency.
Speedup: Grasping Boruta persistently requires 5-15× much less time when in comparison with the vanilla implementation, with the speedup rising for extra conservative α values. For α = 0.00001, the development approaches 15x. It’s also anticipated that even smaller α values would result in more and more bigger speedups. You will need to observe that for many situations with α < 0.001, the vanilla Boruta implementation “doesn’t converge” (not all options are confirmed or rejected) and with out early-stopping, they’d run for for much longer than this.
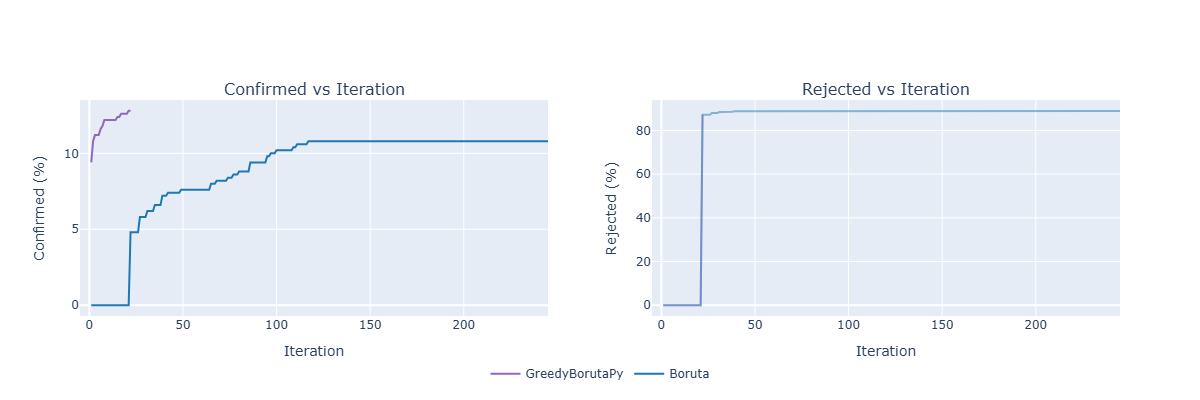
Convergence: We are able to additionally consider how briskly every of the strategy “converges” by analysing the standing of the variables at every iteration, as proven within the plot beneath:

On this state of affairs, utilizing α = 0.00001, we will observe the conduct talked about above: the primary affirmation/rejection of the vanilla algorithm happens on the final iteration of the grasping algorithm (therefore the entire overlap of the strains within the rejection plot).
Due to the logarithmic progress of the utmost variety of iterations by the Grasping Boruta by way of α, we will additionally discover excessive values for α when utilizing the grasping model:

Experiment 2 – Exploring most variety of iterations
Parameters
On this experiment, the identical dataset and hyperparameters as described within the final experiment had been used, apart from α which was mounted at α = 0.00001, and the utmost variety of iterations (for the vanilla algorithm) modified throughout runs. The utmost numbers of iterations analyzed are [16, 32, 64, 128, 256, 512]. Additionally, early stopping was disabled for this experiment to be able to showcase one of many weaknesses of the vanilla Boruta algorithm.
You will need to observe that for this experiment there is just one information level for the Grasping Boruta methodology for the reason that most variety of iterations isn’t a parameter by itself on the modified model, since it’s uniquely outlined by the α used.
Outcomes: Efficiency Comparability

As soon as once more, we observe that the Grasping Boruta achieves greater recall than the vanilla Boruta algorithm whereas having barely decreased specificity, throughout all of the variety of iterations thought of. On this state of affairs, we additionally observe that the Grasping Boruta achieves recall ranges just like these of the vanilla algorithm in ~4x much less time.
Moreover, as a result of within the vanilla algorithm there is no such thing as a “assure of convergence” in a given variety of iterations, the person should outline a most variety of iterations for which the algorithm will run. In follow, it’s tough to find out this quantity with out realizing the bottom fact for vital options and the doable accompanying variety of iterations to set off early stopping. Contemplating this problem, a very conservative person could run the algorithm for a lot too many iterations and not using a important enchancment within the function choice high quality.
On this particular case, utilizing a most variety of iterations equal to 512 iterations, with out early stopping, achieves a recall similar to that achieved with 64, 128 and 256 iterations. When evaluating the grasping model to the 512 iterations of the vanilla algorithm, we see {that a} 40x speedup is achieved, whereas having a barely higher recall.
When to make use of Grasping Boruta?
The Grasping Boruta Algorithm is especially worthwhile in particular situations:
- Excessive-dimensional information with restricted time: When working with datasets that comprise a whole bunch or hundreds of options, the computational price of the vanilla Boruta might be prohibitive. If fast outcomes are required for exploratory evaluation or fast prototyping, Grasping Boruta gives a compelling speed-accuracy trade-off.
- All-relevant function choice objectives: In case your goal aligns with Boruta’s authentic “all-relevant” philosophy—discovering each function that contributes with some info somewhat than the minimal optimum set—then Grasping Boruta’s excessive recall is strictly what you want. The algorithm favors inclusion, which is suitable when function elimination is expensive (e.g., in scientific discovery or causal inference duties).
- Iterative evaluation workflows: In follow, function choice is never a one-shot resolution. Information scientists typically iterate, experimenting with completely different function units and fashions. Grasping Boruta permits fast iteration by offering quick preliminary outcomes that may be refined in subsequent analyses. Moreover, different function choice strategies can be utilized to additional cut back the dimensionality of the function set.
- Just a few further options are OK: The vanilla Boruta’s strict statistical testing is efficacious when false positives are significantly expensive. Nevertheless, in lots of purposes, together with a number of further options is preferable to lacking vital ones. Grasping Boruta is right when the downstream pipeline can deal with barely bigger function units however advantages from sooner processing.
Conclusion
The Grasping Boruta algorithm is an extension/modification to a well-established function choice methodology, with considerably completely different properties. By enjoyable the affirmation criterion from statistical significance to a single hit, we obtain:
- 5-40x sooner run occasions in comparison with normal Boruta, for the situations explored.
- Equal or higher recall, guaranteeing no related options are missed.
- Assured convergence with all options labeled.
- Maintained interpretability and theoretical grounding.
The trade-off—a modest enhance within the false optimistic fee—is appropriate in lots of real-world purposes, significantly when working with high-dimensional information below time constraints.
For practitioners, the Grasping Boruta algorithm gives a worthwhile instrument for fast, high-recall function choice in exploratory evaluation, with the choice to comply with up with extra conservative strategies if wanted. For researchers, it demonstrates how considerate modifications to established algorithms can yield important sensible advantages by fastidiously contemplating the precise necessities of real-world purposes.
The algorithm is most applicable when your philosophy aligns with discovering “all related” options somewhat than a minimal set, when pace issues, and when false positives might be tolerated or filtered in downstream evaluation. In these widespread situations, Grasping Boruta gives a compelling different to the vanilla algorithm.
References
[1] Kursa, M. B., & Rudnicki, W. R. (2010). Characteristic Choice with the Boruta Bundle. Journal of Statistical Software program, 36(11), 1–13.
[2] Geurts, P., Ernst, D., & Wehenkel, L. (2006). Extraordinarily randomized timber. Machine Studying, 63(1), 3–42.
[3] Chen, T., & Guestrin, C. (2016). XGBoost: A scalable tree boosting system. Proceedings of the twenty second ACM SIGKDD Worldwide Convention on Information Discovery and Information Mining, 785–794.
[4] Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., & Liu, T.-Y. (2017). LightGBM: A extremely environment friendly gradient boosting resolution tree. Advances in Neural Info Processing Techniques 30 (NIPS 2017), 3146–3154.
[5] BorutaPy implementation: https://github.com/scikit-learn-contrib/boruta_py
Code availability
The whole implementation of Grasping Boruta is offered at GreedyBorutaPy.
Grasping Boruta can also be obtainable as a PyPI package deal at greedyboruta.
Thanks for studying! Should you discovered this text useful, please take into account following for extra content material on function choice, machine studying algorithms, and sensible information science.














{kind=link}