


Palo Alto, CA – Generative AI firm SambaNova introduced final week that DeepSeek-R1 671B is working as we speak on SambaNova Cloud at 198 tokens per second (t/s), “attaining speeds and effectivity that no different platform can match,” the corporate stated.
DeepSeek-R1 has diminished AI coaching prices by 10X, however its widespread adoption has been hindered by excessive inference prices and inefficiencies — till now, in response to the corporate. “SambaNova has eliminated this barrier, unlocking real-time, cost-effective inference at scale for builders and enterprises,” the corporate stated.
“Powered by the SN40L RDU chip, SambaNova is the quickest platform working DeepSeek at 198 tokens per second per person,” acknowledged Rodrigo Liang, CEO and co-founder of SambaNova. “This can improve to 5X quicker than the most recent GPU velocity on a single rack — and by 12 months finish, we are going to supply 100X the capability for DeepSeek-R1.”
“Having the ability to run the total DeepSeek-R1 671B mannequin — not a distilled model — at SambaNova’s blazingly quick velocity is a recreation changer for builders. Reasoning fashions like R1 must generate quite a lot of reasoning tokens to provide you with a superior output, which makes them take longer than conventional LLMs. This makes dashing them up particularly necessary,” acknowledged Dr. Andrew Ng, Founding father of DeepLearning.AI, Managing Normal Companion at AI Fund, and an Adjunct Professor at Stanford College’s Laptop Science Division.
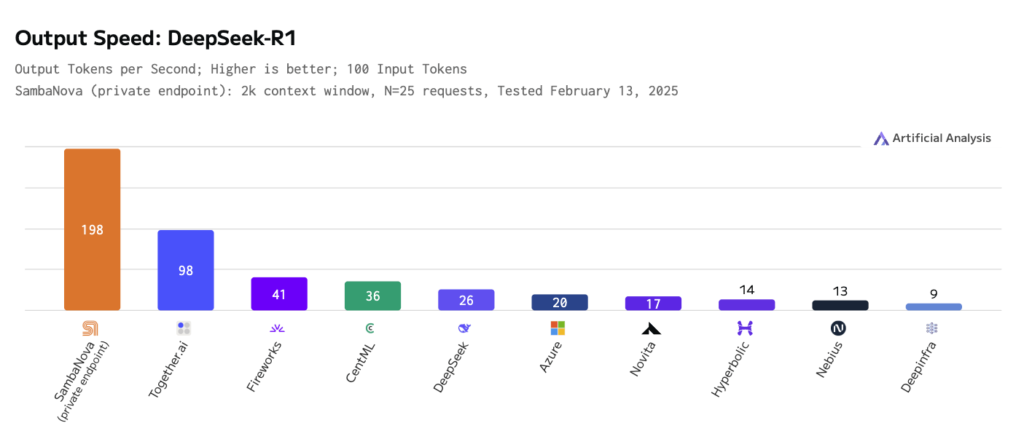
“Synthetic Evaluation has independently benchmarked SambaNova’s cloud deployment of the total 671 billion parameter DeepSeek- R1 Combination of Specialists mannequin at over 195 output token/s, the quickest output velocity we now have ever measured for DeepSeek-R1. Excessive output speeds are significantly necessary for reasoning fashions, as these fashions use reasoning output tokens to enhance the standard of their responses. SambaNova’s excessive output speeds will help the usage of reasoning fashions in latency delicate use instances,” stated George Cameron, Co-Founder, Synthetic Evaluation.
DeepSeek-R1 has revolutionized AI by collapsing coaching prices by tenfold, nonetheless, widespread adoption has stalled as a result of DeepSeek-R1’s reasoning capabilities require considerably extra compute for inference, making AI manufacturing costlier. In actuality, the inefficiency of GPU-based inference has stored DeepSeek-R1 out of attain for many builders.
SambaNova has solved this drawback. With a proprietary dataflow structure and three-tier reminiscence design, SambaNova’s SN40L Reconfigurable Dataflow Unit (RDU) chips collapse the {hardware} necessities to run DeepSeek-R1 671B effectively from 40 racks (320 of the most recent GPUs) all the way down to 1 rack (16 RDUs) — unlocking cost-effective inference at unmatched effectivity.
“DeepSeek-R1 is without doubt one of the most superior frontier AI fashions out there, however its full potential has been restricted by the inefficiency of GPUs,” stated Rodrigo Liang, CEO of SambaNova. “That modifications as we speak. We’re bringing the subsequent main breakthrough — collapsing inference prices and lowering {hardware} necessities from 40 racks to only one — to supply DeepSeek-R1 on the quickest speeds, effectively.”
“Greater than 10 million customers and engineering groups at Fortune 500 firms depend on Blackbox AI to rework how they write code and construct merchandise. Our partnership with SambaNova performs a essential function in accelerating our autonomous coding agent workflows. SambaNova’s chip capabilities are unmatched for serving the total DeepSeek-R1 671B mannequin, which supplies significantly better accuracy than any of the distilled variations. We couldn’t ask for a greater associate to work with to serve thousands and thousands of customers,” acknowledged Robert Rizk, CEO of Blackbox AI.
Sumti Jairath, Chief Architect, SambaNova, defined: “DeepSeek-R1 is the proper match for SambaNova’s three-tier reminiscence structure. With 671 billion parameters R1 is the biggest open supply giant language mannequin launched to this point, which suggests it wants quite a lot of reminiscence to run. GPUs are reminiscence constrained, however SambaNova’s distinctive dataflow structure means we will run the mannequin effectively to attain 20000 tokens/s of whole rack throughput within the close to future — unprecedented effectivity when in comparison with GPUs attributable to their inherent reminiscence and knowledge communication bottlenecks.”
SambaNova is quickly scaling its capability to fulfill anticipated demand, and by the top of the 12 months will supply greater than 100x the present international capability for DeepSeek-R1. This makes its RDUs essentially the most environment friendly enterprise answer for reasoning fashions.
DeepSeek-R1 671B full mannequin is accessible now to all customers to expertise and to pick out customers through API on SambaNova Cloud.
















{kind=link}