


There are many good assets explaining the transformer structure on-line, however Rotary Place Embedding (RoPE) is usually poorly defined or skipped fully.
RoPE was first launched within the paper RoFormer: Enhanced Transformer with Rotary Place Embedding, and whereas the mathematical operations concerned are comparatively simple — primarily rotation matrix and matrix multiplications — the actual problem lies in understanding the instinct behind the way it works. I’ll attempt to present a option to visualize what it’s doing to vectors and clarify why this method is so efficient.
I assume you could have a primary understanding of transformers and the eye mechanism all through this put up.
RoPE Instinct
Since transformers lack inherent understanding of order and distances, researchers developed positional embeddings. Right here’s what positional embeddings ought to accomplish:
- Tokens nearer to one another ought to attend with greater weights, whereas distant tokens ought to attend with decrease weights.
- Place inside a sequence shouldn’t matter, i.e. if two phrases are shut to one another, they need to attend to one another with greater weights no matter whether or not they seem firstly or finish of an extended sequence.
- To perform these objectives, relative positional embeddings are much more helpful than absolute positional embeddings.
Key perception: LLMs ought to concentrate on the relative positions between two tokens, which is what really issues for consideration.
When you perceive these ideas, you’re already midway there.
Earlier than RoPE
The unique positional embeddings from the seminal paper Consideration is All You Want had been outlined by a closed kind equation after which added into the semantic embeddings. Mixing place and semantics indicators within the hidden state was not a good suggestion. Later analysis confirmed that LLMs had been memorizing (overfitting) fairly than generalizing positions, inflicting speedy deterioration when sequence lengths exceeded coaching information. However utilizing a closed kind system is sensible, it permits us to increase it indefinitely, and RoPE does one thing related.
One technique that proved profitable in early deep studying was: when uncertain the way to compute helpful options for a neural community, let the community study them itself! That’s what fashions like GPT-3 did — they discovered their very own place embeddings. Nonetheless, offering an excessive amount of freedom will increase overfitting dangers and, on this case, creates exhausting limits on context home windows (you possibly can’t lengthen it past your educated context window).
One of the best approaches targeted on modifying the eye mechanism in order that close by tokens obtain greater consideration weights whereas distant tokens obtain decrease weights. By isolating the place info into the eye mechanism, it preserves the hidden state and retains it targeted on semantics. These strategies primarily tried to cleverly modify Q and Okay so their dot merchandise would replicate proximity. Many papers tried totally different strategies, however RoPE was the one which finest solved the issue.
Rotation Instinct
RoPE modifies Q and Okay by making use of rotations to them. One of many nicest properties of rotation is that it preserves vector modules (dimension), which probably carries semantic info.
Let q be the question projection of a token and ok be the important thing projection of one other. For tokens which might be shut within the textual content, minimal rotation is utilized, whereas distant tokens bear bigger rotational transformations.
Think about two equivalent projection vectors — any rotation would make them extra distant from one another. That’s precisely what we wish.

Now, right here’s a probably complicated scenario: if two projection vectors are already far aside, rotation would possibly carry them nearer collectively. That’s not what we wish! They’re being rotated as a result of they’re distant within the textual content, so that they shouldn’t obtain excessive consideration weights. Why does this nonetheless work?
- In 2D, there’s just one rotation airplane (
xy). You may solely rotate clockwise or counterclockwise.
- In 3D, there are infinitely many rotation planes, making it extremely unlikely that rotation will carry two vectors nearer collectively.
- Fashionable fashions function in very high-dimensional areas (10k+ dimensions), making this much more inconceivable.
Bear in mind: in deep studying, possibilities matter most! It’s acceptable to be often flawed so long as the possibilities are low.
Angle of Rotation
The rotation angle depends upon two components: m and i. Let’s look at every.
Token Absolute Place m
Rotation will increase because the token’s absolute place m will increase.
I do know what you’re considering: “m is absolute place, however didn’t you say relative positions matter most?”
Right here’s the magic: take into account a 2D airplane the place you rotate one vector by 𝛼 and one other by β. The angular distinction between them turns into 𝛼-β. Absolutely the values of 𝛼 and β don’t matter, solely their distinction does. So for 2 tokens at positions m and n, the rotation modifies the angle between them proportionally to m-n.

For simplicity, we are able to assume that we’re solely rotating
q(that is mathematically correct since we care about ultimate distances, not coordinates).
Hidden State Index i
As an alternative of making use of uniform rotation throughout all hidden state dimensions, RoPE processes two dimensions at a time, making use of totally different rotation angles to every pair. In different phrases, it breaks the lengthy vector into a number of pairs that may be rotated in 2D by totally different angles.
We rotate hidden state dimensions in a different way — rotation is greater when i is low (vector starting) and decrease when i is excessive (vector finish).
Understanding this operation is simple, however understanding why we want it requires extra rationalization:
- It permits the mannequin to decide on what ought to have shorter or longer ranges of affect.
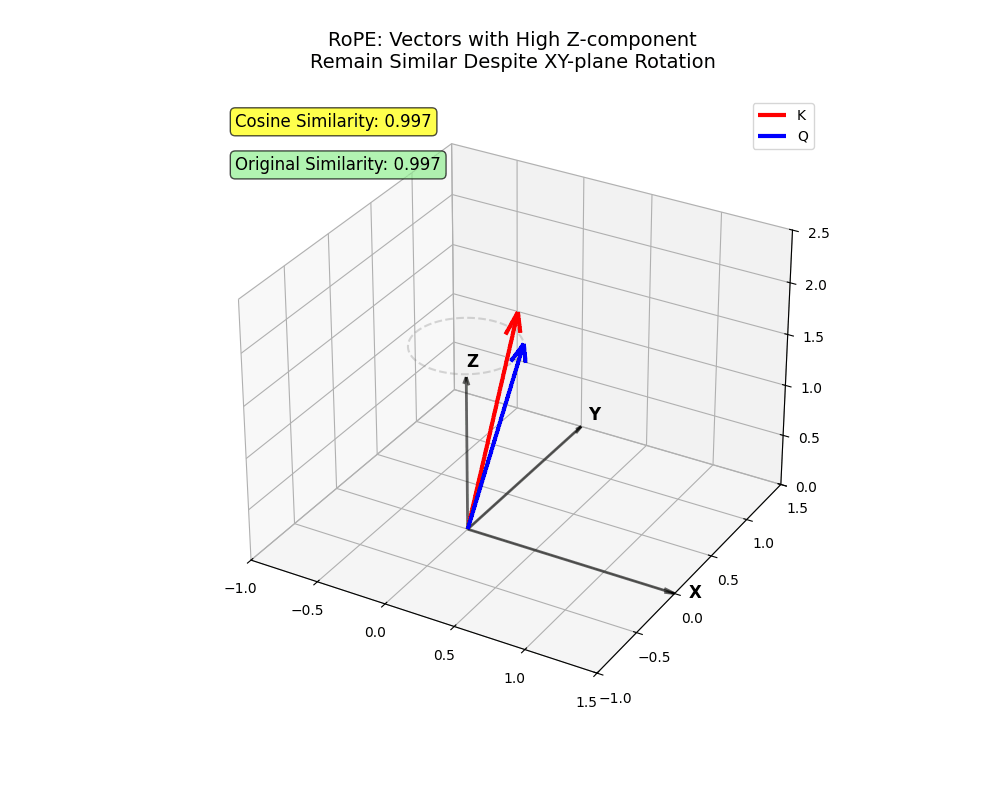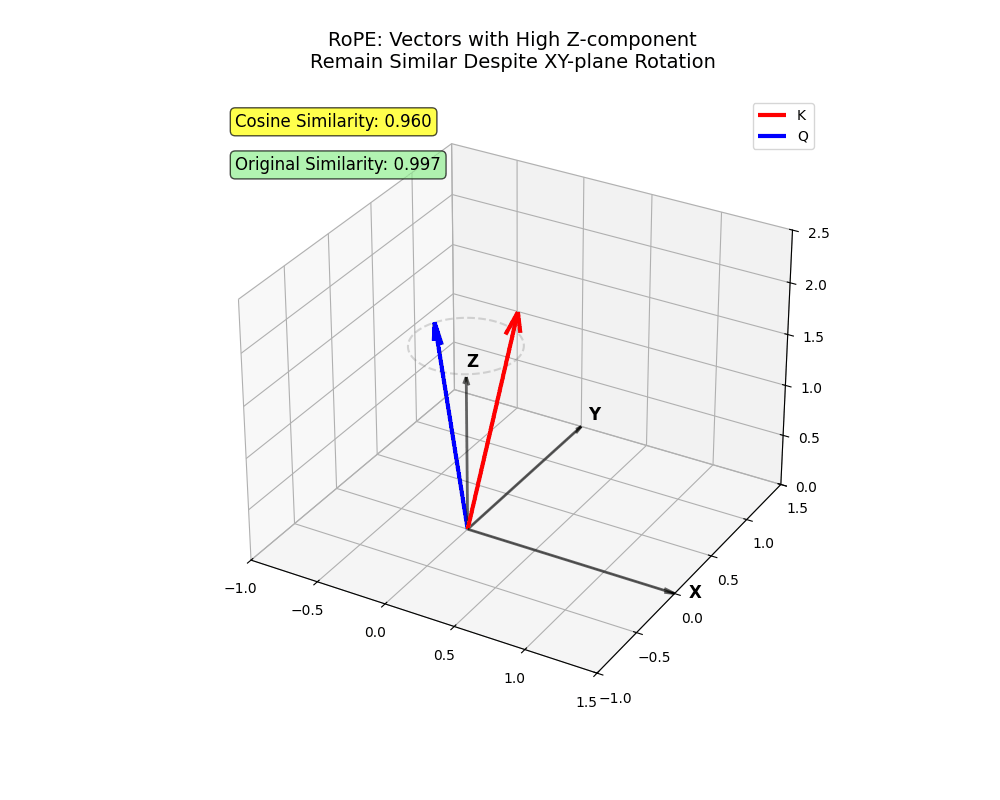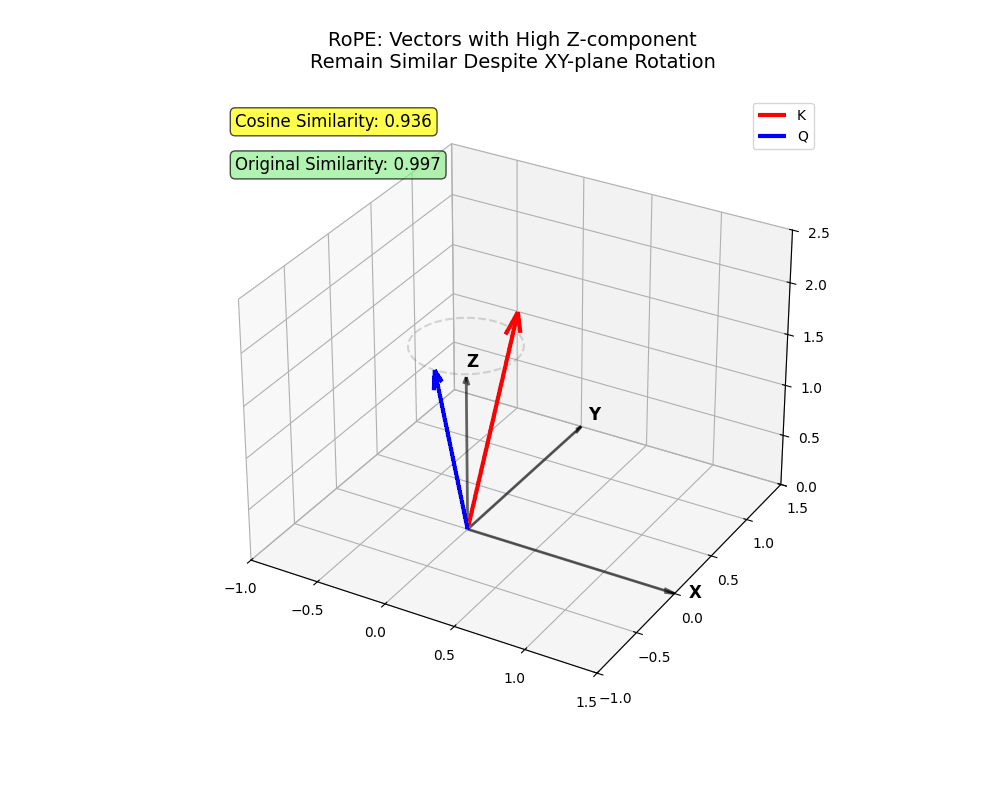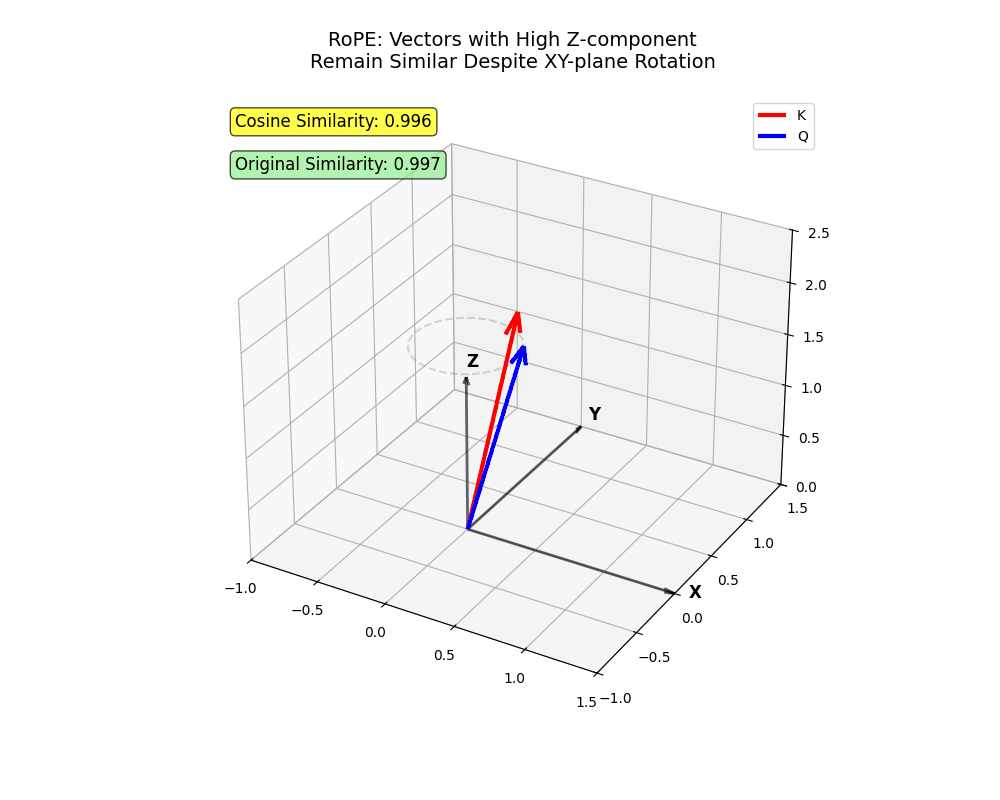
- Think about vectors in 3D (
xyz).
- The
xandyaxes signify early dimensions (lowi) that bear greater rotation. Tokens projected primarily ontoxandyhave to be very near attend with excessive depth.
- The
zaxis, the placeiis greater, rotates much less. Tokens projected primarily ontozcan attend even when distant.

xy airplane. Two vectors encoding info primarily in z stay shut regardless of rotation (tokens that ought to attend regardless of longer distances!)
x and y change into very far aside (close by tokens the place one shouldn’t attend to the opposite).This construction captures sophisticated nuances in human language — fairly cool, proper?
As soon as once more, I do know what you’re considering: “after an excessive amount of rotation, they begin getting shut once more”.
That’s appropriate, however right here’s why it nonetheless works:
- We’re visualizing in 3D, however this really occurs in a lot greater dimensions.
- Though some dimensions develop nearer, others that rotate extra slowly proceed rising farther aside. Therefore the significance of rotating dimensions by totally different angles.
- RoPE isn’t excellent — on account of its rotational nature, native maxima do happen. See the theoretical chart from the unique authors:

The theoretical curve has some loopy bumps, however in apply I discovered it to be rather more behaved:

An concept that occurred to me was clipping the rotation angle so the similarity strictly decreases with distance will increase. I’ve seen clipping being utilized to different strategies, however to not RoPE.
Naked in thoughts that cosine similarity tends to develop (though slowly) as the gap grows so much previous our base worth (later you’ll see precisely what is that this base of the system). A easy resolution right here is to extend the bottom, and even let strategies like native or window consideration deal with it.

Backside line: The LLM learns to undertaking long-range and short-range which means affect in numerous dimensions of q and ok.
Listed below are some concrete examples of long-range and short-range dependencies:
- The LLM processes Python code the place an preliminary transformation is utilized to a dataframe
df. This related info ought to probably carry over an extended vary and affect the contextual embedding of downstreamdftokens.
- Adjectives usually characterize close by nouns. In “An attractive mountain stretches past the valley”, the adjective stunning particularly describes the mountain, not the valley, so it ought to primarily have an effect on the mountain embedding.
The Angle System
Now that you just perceive the ideas and have sturdy instinct, listed below are the equations. The rotation angle is outlined by:
[text{angle} = m times theta]
[theta = 10,000^{-2(i-1)/d_{model}}]
mis the token’s absolute place
- i ∈ {1, 2, …, d/2} representing hidden state dimensions, since we course of two dimensions at a time we solely have to iterate to
d/2fairly thand.
dmannequinis the hidden state dimension (e.g., 4,096)
Discover that when:
[i=1 Rightarrow theta=1 quad text{(high rotation)} ]
[i=d/2 Rightarrow theta approx 1/10,000 quad text{(low rotation)}]
Conclusion
- We should always discover intelligent methods to inject information into LLMs fairly than letting them study the whole lot independently.
- We do that by offering the correct operations a neural community must course of information — consideration and convolutions are nice examples.
- Closed-form equations can lengthen indefinitely because you don’t have to study every place embedding.
- This is the reason RoPE gives wonderful sequence size flexibility.
- An important property: consideration weights lower as relative distances improve.
- This follows the identical instinct as native consideration in alternating consideration architectures.

















{kind=link}