


earlier than we dive in:
- I’m a developer at Google Cloud. Ideas and opinions expressed right here are fully my very own.
- The whole supply code for this text, together with future updates, is out there in this pocket book underneath the Apache 2.0 license.
- All new pictures on this article have been generated with Gemini Nano Banana utilizing the proof-of-concept era pipeline explored right here.
- You’ll be able to experiment with Gemini totally free in Google AI Studio. Please be aware that programmatic API entry to Nano Banana is a pay-as-you-go service.
🔥 Problem
All of us have current pictures value reusing in numerous contexts. This might usually indicate modifying the pictures, a posh (if not unimaginable) activity requiring very particular abilities and instruments. This explains why our archives are filled with forgotten or unused treasures. State-of-the-art imaginative and prescient fashions have developed a lot that we are able to rethink this downside.
So, can we breathe new life into our visible archives?
Let’s attempt to full this problem with the next steps:
- 1️⃣ Begin from an archive picture we’d prefer to reuse
- 2️⃣ Extract a personality to create a brand-new reference picture
- 3️⃣ Generate a sequence of pictures for example the character’s journey, utilizing solely prompts and the brand new belongings
For this, we’ll discover the capabilities of “Gemini 2.5 Flash Picture”, often known as “Nano Banana” 🍌.
🏁 Setup
🐍 Python packages
We’ll use the next packages:
google-genai: The Google Gen AI Python SDK lets us name Gemini with a number of strains of codenetworkxfor graph administration
We’ll additionally use the next dependencies:
pillowandmatplotlibfor knowledge visualizationtenacityfor request administration
%pip set up --quiet "google-genai>=1.38.0" "networkx[default]"🤖 Gen AI SDK
Create a google.genai consumer:
from google import genai
check_environment()
consumer = genai.Shopper()Test your configuration:
check_configuration(consumer)Utilizing the Vertex AI API with mission "…" in location "international"🧠 Gemini mannequin
For this problem, we’ll choose the most recent Gemini 2.5 Flash Picture mannequin (presently in preview):
GEMINI_2_5_FLASH_IMAGE = "gemini-2.5-flash-image-preview"
💡 “Gemini 2.5 Flash Picture” is often known as “Nano Banana” 🍌
🛠️ Helpers
Outline some helper features to generate and show pictures: 🔽
import IPython.show
import tenacity
from google.genai.errors import ClientError
from google.genai.sorts import GenerateContentConfig, PIL_Image
GEMINI_2_5_FLASH_IMAGE = "gemini-2.5-flash-image-preview"
GENERATION_CONFIG = GenerateContentConfig(response_modalities=["TEXT", "IMAGE"])
def generate_content(sources: record[PIL_Image], immediate: str) -> PIL_Image | None:
immediate = immediate.strip()
contents = [*sources, prompt] if sources else immediate
response = None
for try in get_retrier():
with try:
response = consumer.fashions.generate_content(
mannequin=GEMINI_2_5_FLASH_IMAGE,
contents=contents,
config=GENERATION_CONFIG,
)
if not response or not response.candidates:
return None
if not (content material := response.candidates[0].content material):
return None
if not (components := content material.components):
return None
picture: PIL_Image | None = None
for half in components:
if half.textual content:
display_markdown(half.textual content)
proceed
assert (sdk_image := half.as_image())
assert (picture := sdk_image._pil_image)
display_image(picture)
return picture
def get_retrier() -> tenacity.Retrying:
return tenacity.Retrying(
cease=tenacity.stop_after_attempt(7),
wait=tenacity.wait_incrementing(begin=10, increment=1),
retry=should_retry_request,
reraise=True,
)
def should_retry_request(retry_state: tenacity.RetryCallState) -> bool:
if not retry_state.final result:
return False
err = retry_state.final result.exception()
if not isinstance(err, ClientError):
return False
print(f"❌ ClientError {err.code}: {err.message}")
retry = False
match err.code:
case 400 if err.message shouldn't be None and " attempt once more " in err.message:
# Workshop: Cloud Storage accessed for the primary time (service agent provisioning)
retry = True
case 429:
# Workshop: momentary mission with 1 QPM quota
retry = True
print(f"🔄 Retry: {retry}")
return retry
def display_markdown(markdown: str) -> None:
IPython.show.show(IPython.show.Markdown(markdown))
def display_image(picture: PIL_Image) -> None:
IPython.show.show(picture)🖼️ Property
Let’s outline the belongings for our character’s journey and the features to handle them:
import enum
from collections.abc import Sequence
from dataclasses import dataclass
class AssetId(enum.StrEnum):
ARCHIVE = "0_archive"
ROBOT = "1_robot"
MOUNTAINS = "2_mountains"
VALLEY = "3_valley"
FOREST = "4_forest"
CLEARING = "5_clearing"
ASCENSION = "6_ascension"
SUMMIT = "7_summit"
BRIDGE = "8_bridge"
HAMMOCK = "9_hammock"
@dataclass
class Asset:
id: str
source_ids: Sequence[str]
immediate: str
pil_image: PIL_Image
class Property(dict[str, Asset]):
def set_asset(self, asset: Asset) -> None:
# Word: This replaces any current asset (if wanted, add guardrails to auto-save|hold all variations)
self[asset.id] = asset
def generate_image(source_ids: Sequence[str], immediate: str, new_id: str = "") -> None:
sources = [assets[source_id].pil_image for source_id in source_ids]
immediate = immediate.strip()
picture = generate_content(sources, immediate)
if picture and new_id:
belongings.set_asset(Asset(new_id, source_ids, immediate, picture))
belongings = Property()📦 Reference archive
We are able to now fetch our reference archive and make it our first asset: 🔽
import urllib.request
import PIL.Picture
import PIL.ImageOps
ARCHIVE_URL = "https://storage.googleapis.com/github-repo/generative-ai/gemini/use-cases/media-generation/consistent_imagery_generation/0_archive.png"
def load_archive() -> None:
picture = get_image_from_url(ARCHIVE_URL)
# Hold authentic particulars in 16:9 panorama side ratio (arbitrary)
picture = crop_expand_if_needed(picture, 1344, 768)
belongings.set_asset(Asset(AssetId.ARCHIVE, [], "", picture))
display_image(picture)
def get_image_from_url(image_url: str) -> PIL_Image:
with urllib.request.urlopen(image_url) as response:
return PIL.Picture.open(response)
def crop_expand_if_needed(picture: PIL_Image, dst_w: int, dst_h: int) -> PIL_Image:
src_w, src_h = picture.dimension
if dst_w < src_w or dst_h < src_h:
crop_l, crop_t = (src_w - dst_w) // 2, (src_h - dst_h) // 2
picture = picture.crop((crop_l, crop_t, crop_l + dst_w, crop_t + dst_h))
src_w, src_h = picture.dimension
if src_w < dst_w or src_h < dst_h:
off_l, off_t = (dst_w - src_w) // 2, (dst_h - src_h) // 2
borders = (off_l, off_t, dst_w - src_w - off_l, dst_h - src_h - off_t)
picture = PIL.ImageOps.increase(picture, borders, fill="white")
assert picture.dimension == (dst_w, dst_h)
return pictureload_archive()
💡 Gemini will protect the closest side ratio of the final enter picture. Consequently, we cropped the archive picture to
1344 × 768pixels (near16:9) to protect the unique particulars (no rescaling) and hold the identical panorama decision in all our future scenes. Gemini can generate1024 × 1024pictures (1:1) but additionally their16:9,9:16,4:3, and3:4equivalents (by way of tokens).
This archive picture was generated in July 2024 with a beta model of Imagen 3, prompted with “On white background, a small hand-felted toy of blue robotic. The felt is delicate and cuddly…”. The end result appeared actually good however, on the time, there was completely no determinism and no consistency. Consequently, this was a pleasant one-shot picture era and the lovable little robotic appeared gone ceaselessly…
Let’s attempt to extract our little robotic:
source_ids = [AssetId.ARCHIVE]
immediate = "Extract the robotic as is, with out its shadow, changing every little thing with a strong white fill."
generate_image(source_ids, immediate)
⚠️ The robotic is completely extracted, however that is basically an excellent background removing, which many fashions can carry out. This immediate makes use of phrases from graphics software program, whereas we are able to now cause by way of picture composition. It’s additionally not essentially a good suggestion to attempt to use conventional binary masks, as object edges and shadows convey vital particulars about shapes, textures, positions, and lighting.
Let’s return to our archive to carry out a sophisticated extraction as an alternative, and instantly generate a personality sheet…
🪄 Character sheet
Gemini has spatial understanding, so it’s capable of present completely different views whereas preserving visible options. Let’s generate a entrance/again character sheet and, as our little robotic will go on a journey, additionally add a backpack on the similar time:
source_ids = [AssetId.ARCHIVE]
immediate = """
- Scene: Robotic character sheet.
- Left: Entrance view of the extracted robotic.
- Proper: Again view of the extracted robotic (seamless again).
- The robotic wears a similar small, brown-felt backpack, with a tiny polished-brass buckle and easy straps in each views. The backpack straps are seen in each views.
- Background: Pure white.
- Textual content: On the highest, caption the picture "ROBOT CHARACTER SHEET" and, on the underside, caption the views "FRONT VIEW" and "BACK VIEW".
"""
new_id = AssetId.ROBOT
generate_image(source_ids, immediate, new_id)
💡 A number of remarks:
- The immediate describes the scene by way of composition, as generally utilized in media studios.
- If we attempt successive generations, they’re constant, with all robotic options preserved.
- Our immediate does element some points of the backpack, however we’ll get barely completely different backpacks for every little thing that’s unspecified.
- For the sake of simplicity, we added the backpack instantly within the character sheet however, in an actual manufacturing pipeline, we’d in all probability make it a part of a separate accent sheet.
- To manage precisely the backpack form and design, we might additionally use a reference picture and “remodel the backpack right into a stylized felt model”.
This new asset can now function a design reference in our future picture generations.
✨ First scene
Let’s get began with a mountain surroundings:
source_ids = [AssetId.ROBOT]
immediate = """
- Picture 1: Robotic character sheet.
- Scene: Macro images of a superbly crafted miniature diorama.
- Background: Comfortable-focus of a panoramic vary of interspersed, dome-like felt mountains, in numerous shades of medium blue/inexperienced, with curvy white snowcaps, extending over your entire horizon.
- Foreground: Within the bottom-left, the robotic stands on the sting of a medium-gray felt cliff, seen from a 3/4 again angle, searching over a sea of clouds (fabricated from white cotton).
- Lighting: Studio, clear and delicate.
"""
new_id = AssetId.MOUNTAINS
generate_image(source_ids, immediate, new_id)
💡 The mountain form is specified as “dome-like” so our character can stand on one of many summits afterward.
It’s essential to spend a while on this primary scene as, in a cascading impact, it would outline the general look of our story. Take a while to refine the immediate or attempt a few instances to get the perfect variation.
Any more, our era inputs might be each the character sheet and a reference scene…
✨ Successive scenes
Let’s get the robotic down a valley:
source_ids = [AssetId.ROBOT, AssetId.MOUNTAINS]
immediate = """
- Picture 1: Robotic character sheet.
- Picture 2: Earlier scene.
- The robotic has descended from the cliff to a grey felt valley. It stands within the middle, seen instantly from the again. It's holding/studying a felt map with outstretched arms.
- Giant easy, spherical, felt rocks in numerous beige/grey shades are seen on the perimeters.
- Background: The distant mountain vary. A skinny layer of clouds obscures its base and the tip of the valley.
- Lighting: Golden hour mild, delicate and subtle.
"""
new_id = AssetId.VALLEY
generate_image(source_ids, immediate, new_id)
💡 A number of notes:
- The supplied specs about our enter pictures (
"Picture 1:…","Picture 2:…") are essential. With out them, “the robotic” might discuss with any of the three robots within the enter pictures (2 within the character sheet, 1 within the earlier scene). With them, we point out that it’s the identical robotic. In case of confusion, we will be extra particular with"the [entity] from picture [number]". - Alternatively, since we didn’t present a exact description of the valley, successive requests will give completely different, fascinating, and inventive outcomes (we are able to decide our favourite or make the immediate extra exact for extra determinism).
- Right here, we additionally examined a distinct lighting, which considerably adjustments the entire scene.
Then, we are able to transfer ahead into this scene:
source_ids = [AssetId.ROBOT, AssetId.VALLEY]
immediate = """
- Picture 1: Robotic character sheet.
- Picture 2: Earlier scene.
- The robotic goes on and faces a dense, infinite forest of easy, big, skinny bushes, that fills your entire background.
- The bushes are comprised of numerous shades of sunshine/medium/darkish inexperienced felt.
- The robotic is on the precise, seen from a 3/4 rear angle, now not holding the map, with each fingers clasped to its ears in despair.
- On the left & proper backside sides, rocks (just like picture 2) are partially seen.
"""
new_id = AssetId.FOREST
generate_image(source_ids, immediate, new_id)
💡 Of curiosity:
- We might place the character, change its perspective, and even “animate” its arms for extra expressivity.
- The “now not holding the map” precision prevents the mannequin from making an attempt to maintain it from the earlier scene in a significant manner (e.g., the robotic dropped the map on the ground).
- We didn’t present lighting particulars: The lighting supply, high quality, and course have been stored from the earlier scene.
Let’s undergo the forest:
source_ids = [AssetId.ROBOT, AssetId.FOREST]
immediate = """
- Picture 1: Robotic character sheet.
- Picture 2: Earlier scene.
- The robotic goes by means of the dense forest and emerges right into a clearing, pushing apart two tree trunks.
- The robotic is within the middle, now seen from the entrance view.
- The bottom is fabricated from inexperienced felt, with flat patches of white felt snow. Rocks are now not seen.
"""
new_id = AssetId.CLEARING
generate_image(source_ids, immediate, new_id)
💡 We modified the bottom however didn’t present extra particulars for the view and the forest: The mannequin will usually protect many of the bushes.
Now that the valley-forest sequence is over, we are able to journey as much as the mountains, utilizing the unique mountain scene as our reference to return to that surroundings:
source_ids = [AssetId.ROBOT, AssetId.MOUNTAINS]
immediate = """
- Picture 1: Robotic character sheet.
- Picture 2: Earlier scene.
- Shut-up of the robotic now climbing the height of a medium-green mountain and reaching its summit.
- The mountain is true within the middle, with the robotic on its left slope, seen from a 3/4 rear angle.
- The robotic has each ft on the mountain and is utilizing two felt ice axes (brown handles, grey heads), reaching the snowcap.
- Horizon: The distant mountain vary.
"""
new_id = AssetId.ASCENSION
generate_image(source_ids, immediate, new_id)
💡 The mountain close-up, inferred from the blurred background, is fairly spectacular.
Let’s climb to the summit:
source_ids = [AssetId.ROBOT, AssetId.ASCENSION]
immediate = """
- Picture 1: Robotic character sheet.
- Picture 2: Earlier scene.
- The robotic reaches the highest and stands on the summit, seen within the entrance view, in close-up.
- It's now not holding the ice axes, that are planted upright within the snow on either side.
- It has each arms raised in signal of victory.
"""
new_id = AssetId.SUMMIT
generate_image(source_ids, immediate, new_id)
💡 It is a logical follow-up but additionally a pleasant, completely different view.
Now, let’s attempt one thing completely different to considerably recompose the scene:
source_ids = [AssetId.ROBOT, AssetId.SUMMIT]
immediate = """
- Picture 1: Robotic character sheet.
- Picture 2: Earlier scene.
- Take away the ice axes.
- Transfer the middle mountain to the left fringe of the picture and add a barely taller medium-blue mountain to the precise edge.
- Droop a stylized felt bridge between the 2 mountains: Its deck is fabricated from thick felt planks in numerous wooden shades.
- Place the robotic on the middle of the bridge with one arm pointing towards the blue mountain.
- View: Shut-up.
"""
new_id = AssetId.BRIDGE
generate_image(source_ids, immediate, new_id)
💡 Of curiosity:
- This crucial immediate composes the scene by way of actions. It’s typically simpler than descriptions.
- A brand new mountain is added as instructed, and it’s each completely different and constant.
- The bridge attaches to the summits in very believable methods and appears to obey the legal guidelines of physics.
- The “Take away the ice axes” instruction is right here for a cause. With out it, it’s as if we have been prompting “do no matter you possibly can with the ice axes from the earlier scene: depart them the place they’re, don’t let the robotic depart with out them, or anything”, resulting in random outcomes.
- It’s additionally potential to get the robotic to stroll on the bridge, seen from the facet (which we by no means generated earlier than), however it’s laborious to have it persistently stroll from left to proper. Including left and proper views within the character sheet ought to repair this.
Let’s generate a closing scene and let the robotic get some well-deserved relaxation:
source_ids = [AssetId.ROBOT, AssetId.BRIDGE]
immediate = """
- Picture 1: Robotic character sheet.
- Picture 2: Earlier scene.
- The robotic is sleeping peacefully (each eyes became a "closed" state), in a cushty brown-and-tan tartan hammock that has changed the bridge.
"""
new_id = AssetId.HAMMOCK
generate_image(source_ids, immediate, new_id)
💡 Of curiosity:
- This time, the immediate is descriptive, and it really works in addition to the earlier crucial immediate.
- The bridge-hammock transformation is very nice and preserves the attachments on the mountain summits.
- The robotic transformation can be spectacular, because it hasn’t been seen on this place earlier than.
- The closed eyes are probably the most troublesome element to get persistently (could require a few makes an attempt), in all probability as a result of we’re accumulating many various transformations without delay (and diluting the mannequin’s consideration). For full management and extra deterministic outcomes, we are able to deal with vital adjustments over iterative steps, or create numerous character sheets upfront.
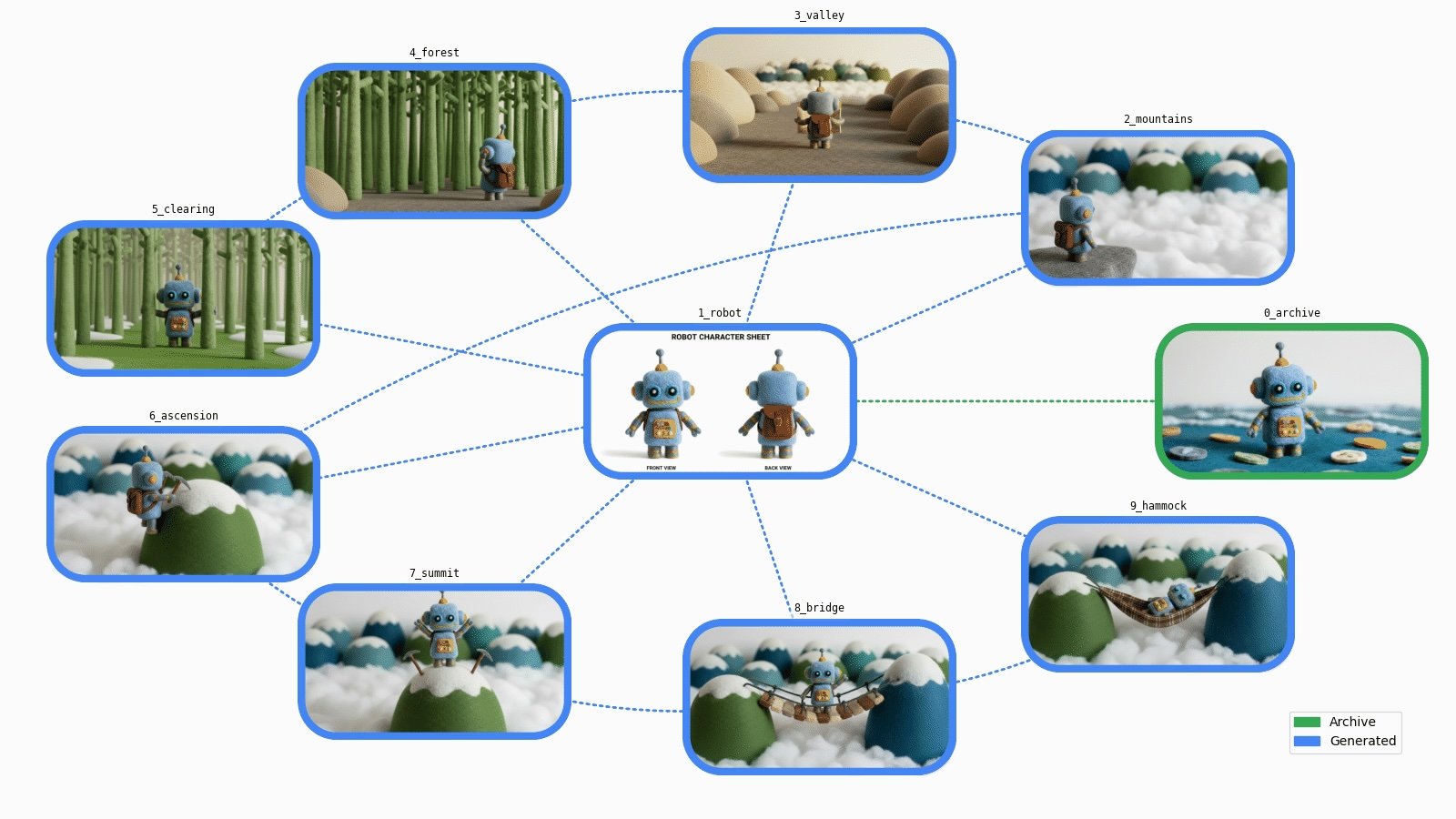
We have now illustrated our story with 9 new constant pictures! Let’s take a step again to know what we’ve constructed…
🗺️ Graph visualization
We now have a set of picture belongings, from archives to brand-new generated belongings.
Let’s add some knowledge visualization to get a greater sense of the steps accomplished…
🔗 Directed graph
Our new belongings are all associated, linked by a number of “generated from” hyperlinks. From an information construction perspective, it is a directed graph.
We are able to construct the corresponding directed graph utilizing the networkx library:
import networkx as nx
def build_graph(belongings: Property) -> nx.DiGraph:
graph = nx.DiGraph(belongings=belongings)
# Nodes
for asset in belongings.values():
graph.add_node(asset.id, asset=asset)
# Edges
for asset in belongings.values():
for source_id in asset.source_ids:
graph.add_edge(source_id, asset.id)
return graph
asset_graph = build_graph(belongings)
print(asset_graph)DiGraph with 10 nodes and 16 edgesLet’s place probably the most used asset within the middle and show the opposite belongings round: 🔽
import matplotlib.pyplot as plt
def display_basic_graph(graph: nx.Graph) -> None:
pos = compute_node_positions(graph)
colour = "#4285F4"
choices = dict(
node_color=colour,
edge_color=colour,
arrowstyle="wedge",
with_labels=True,
font_size="small",
bbox=dict(ec="black", fc="white", alpha=0.7),
)
nx.draw(graph, pos, **choices)
plt.present()
def compute_node_positions(graph: nx.Graph) -> dict[str, tuple[float, float]]:
# Put probably the most linked node within the middle
center_node = most_connected_node(graph)
edge_nodes = set(graph) - {center_node}
pos = nx.circular_layout(graph.subgraph(edge_nodes))
pos[center_node] = (0.0, 0.0)
return pos
def most_connected_node(graph: nx.Graph) -> str:
if not graph.nodes():
return ""
centrality_by_id = nx.degree_centrality(graph)
return max(centrality_by_id, key=lambda s: centrality_by_id.get(s, 0.0))display_basic_graph(asset_graph)
That’s an accurate abstract of our completely different steps. It’d be good if we might additionally visualize our belongings…
🌟 Asset graph
Let’s add customized matplotlib features to render the graph nodes with the belongings in a extra visually interesting manner: 🔽
import typing
from collections.abc import Iterator
from io import BytesIO
from pathlib import Path
import PIL.Picture
import PIL.ImageDraw
from google.genai.sorts import PIL_Image
from matplotlib.axes import Axes
from matplotlib.backends.backend_agg import FigureCanvasAgg
from matplotlib.determine import Determine
from matplotlib.picture import AxesImage
from matplotlib.patches import Patch
from matplotlib.textual content import Annotation
from matplotlib.transforms import Bbox, TransformedBbox
@enum.distinctive
class ImageFormat(enum.StrEnum):
# Matches PIL.Picture.Picture.format
WEBP = enum.auto()
PNG = enum.auto()
GIF = enum.auto()
def yield_generation_graph_frames(
graph: nx.DiGraph,
animated: bool,
) -> Iterator[PIL_Image]:
def get_fig_ax() -> tuple[Figure, Axes]:
issue = 1.0
figsize = (16 * issue, 9 * issue)
fig, ax = plt.subplots(figsize=figsize)
fig.tight_layout(pad=3)
handles = [
Patch(color=COL_OLD, label="Archive"),
Patch(color=COL_NEW, label="Generated"),
]
ax.legend(handles=handles, loc="decrease proper")
ax.set_axis_off()
return fig, ax
def prepare_graph() -> None:
arrows = nx.draw_networkx_edges(graph, pos, ax=ax)
for arrow in arrows:
arrow.set_visible(False)
def get_box_size() -> tuple[float, float]:
xlim_l, xlim_r = ax.get_xlim()
ylim_t, ylim_b = ax.get_ylim()
issue = 0.08
box_w = (xlim_r - xlim_l) * issue
box_h = (ylim_b - ylim_t) * issue
return box_w, box_h
def add_axes() -> Axes:
xf, yf = tr_figure(pos[node])
xa, ya = tr_axes([xf, yf])
x_y_w_h = (xa - box_w / 2.0, ya - box_h / 2.0, box_w, box_h)
a = plt.axes(x_y_w_h)
a.set_title(
asset.id,
loc="middle",
backgroundcolor="#FFF8",
fontfamily="monospace",
fontsize="small",
)
a.set_axis_off()
return a
def draw_box(colour: str, picture: bool) -> AxesImage:
if picture:
end result = pil_image.copy()
else:
end result = PIL.Picture.new("RGB", image_size, colour="white")
xy = ((0, 0), image_size)
# Draw field define
draw = PIL.ImageDraw.Draw(end result)
draw.rounded_rectangle(xy, box_r, define=colour, width=outline_w)
# Make every little thing outdoors the field define clear
masks = PIL.Picture.new("L", image_size, 0)
draw = PIL.ImageDraw.Draw(masks)
draw.rounded_rectangle(xy, box_r, fill=0xFF)
end result.putalpha(masks)
return a.imshow(end result)
def draw_prompt() -> Annotation:
textual content = f"Immediate:n{asset.immediate}"
margin = 2 * outline_w
image_w, image_h = image_size
bbox = Bbox([[0, margin], [image_w - margin, image_h - margin]])
clip_box = TransformedBbox(bbox, a.transData)
return a.annotate(
textual content,
xy=(0, 0),
xytext=(0.06, 0.5),
xycoords="axes fraction",
textcoords="axes fraction",
verticalalignment="middle",
fontfamily="monospace",
fontsize="small",
linespacing=1.3,
annotation_clip=True,
clip_box=clip_box,
)
def draw_edges() -> None:
STYLE_STRAIGHT = "arc3"
STYLE_CURVED = "arc3,rad=0.15"
for guardian in graph.predecessors(node):
edge = (guardian, node)
colour = COL_NEW if belongings[parent].immediate else COL_OLD
fashion = STYLE_STRAIGHT if center_node in edge else STYLE_CURVED
nx.draw_networkx_edges(
graph,
pos,
[edge],
width=2,
edge_color=colour,
fashion="dotted",
ax=ax,
connectionstyle=fashion,
)
def get_frame() -> PIL_Image:
canvas = typing.forged(FigureCanvasAgg, fig.canvas)
canvas.draw()
image_size = canvas.get_width_height()
image_bytes = canvas.buffer_rgba()
return PIL.Picture.frombytes("RGBA", image_size, image_bytes).convert("RGB")
COL_OLD = "#34A853"
COL_NEW = "#4285F4"
belongings = graph.graph["assets"]
center_node = most_connected_node(graph)
pos = compute_node_positions(graph)
fig, ax = get_fig_ax()
prepare_graph()
box_w, box_h = get_box_size()
tr_figure = ax.transData.remodel # Knowledge → show coords
tr_axes = fig.transFigure.inverted().remodel # Show → determine coords
for node, knowledge in graph.nodes(knowledge=True):
if animated:
yield get_frame()
# Edges and sub-plot
asset = knowledge["asset"]
pil_image = asset.pil_image
image_size = pil_image.dimension
box_r = min(image_size) * 25 / 100 # Radius for rounded rect
outline_w = min(image_size) * 5 // 100
draw_edges()
a = add_axes() # a is utilized in sub-functions
# Immediate
if animated and asset.immediate:
field = draw_box(COL_NEW, picture=False)
immediate = draw_prompt()
yield get_frame()
field.set_visible(False)
immediate.set_visible(False)
# Generated picture
colour = COL_NEW if asset.immediate else COL_OLD
draw_box(colour, picture=True)
plt.shut()
yield get_frame()
def draw_generation_graph(
graph: nx.DiGraph,
format: ImageFormat,
) -> BytesIO:
frames = record(yield_generation_graph_frames(graph, animated=False))
assert len(frames) == 1
body = frames[0]
params: dict[str, typing.Any] = dict()
match format:
case ImageFormat.WEBP:
params.replace(lossless=True)
image_io = BytesIO()
body.save(image_io, format, **params)
return image_io
def draw_generation_graph_animation(
graph: nx.DiGraph,
format: ImageFormat,
) -> BytesIO:
frames = record(yield_generation_graph_frames(graph, animated=True))
assert 1 <= len(frames)
if format == ImageFormat.GIF:
# Dither all frames with the identical palette to optimize the animation
# The animation is cumulative, so most colours are within the final body
methodology = PIL.Picture.Quantize.MEDIANCUT
palettized = frames[-1].quantize(methodology=methodology)
frames = [frame.quantize(method=method, palette=palettized) for frame in frames]
# The animation might be performed in a loop: begin biking with probably the most full body
first_frame = frames[-1]
next_frames = frames[:-1]
INTRO_DURATION = 3000
FRAME_DURATION = 1000
durations = [INTRO_DURATION] + [FRAME_DURATION] * len(next_frames)
params: dict[str, typing.Any] = dict(
save_all=True,
append_images=next_frames,
length=durations,
loop=0,
)
match format:
case ImageFormat.GIF:
params.replace(optimize=False)
case ImageFormat.WEBP:
params.replace(lossless=True)
image_io = BytesIO()
first_frame.save(image_io, format, **params)
return image_io
def display_generation_graph(
graph: nx.DiGraph,
format: ImageFormat | None = None,
animated: bool = False,
save_image: bool = False,
) -> None:
if format is None:
format = ImageFormat.WEBP if running_in_colab_env else ImageFormat.PNG
if animated:
image_io = draw_generation_graph_animation(graph, format)
else:
image_io = draw_generation_graph(graph, format)
image_bytes = image_io.getvalue()
IPython.show.show(IPython.show.Picture(image_bytes))
if save_image:
stem = "graph_animated" if animated else "graph"
Path(f"./{stem}.{format.worth}").write_bytes(image_bytes)We are able to now show our era graph:
display_generation_graph(asset_graph)
🚀 Problem accomplished
We managed to generate a full set of latest constant pictures with Nano Banana and discovered a number of issues alongside the way in which:
- Pictures show once more that they’re value a thousand phrases: It’s now quite a bit simpler to generate new pictures from current ones and easy directions.
- We are able to create or edit pictures simply by way of composition (letting us all change into inventive administrators).
- We are able to use descriptive or crucial directions.
- The mannequin’s spatial understanding permits 3D manipulations.
- We are able to add textual content in our outputs (character sheet) and likewise discuss with textual content in our inputs (entrance/again views).
- Consistency will be preserved at very completely different ranges: character, scene, texture, lighting, digicam angle/kind…
- The era course of can nonetheless be iterative however it seems like 10x-100x quicker for reaching better-than-hoped-for outcomes.
- It’s now potential to breathe new life into our archives!
Potential subsequent steps:
- The method we adopted is actually a era pipeline. It may be industrialized for automation (e.g., altering a node regenerates its descendants) or for the era of various variations in parallel (e.g., the identical set of pictures may very well be generated for various aesthetics, audiences, or simulations).
- For the sake of simplicity and exploration, the prompts are deliberately easy. In a manufacturing surroundings, they may have a hard and fast construction with a scientific set of parameters.
- We described scenes as if in a photograph studio. Nearly another conceivable inventive fashion is feasible (photorealistic, summary, 2D…).
- Our belongings may very well be made self-sufficient by saving prompts and ancestors within the picture metadata (e.g., in PNG chunks), permitting for full native storage and retrieval (no database wanted and no extra misplaced prompts!). For particulars, see the “asset metadata” part within the pocket book (hyperlink beneath).
As a bonus, let’s finish with an animated model of our journey, with the era graph additionally displaying a glimpse of our directions:
display_generation_graph(asset_graph, animated=True)
➕ Extra!
Need to go deeper?
Thanks for studying. I sit up for seeing what you create!

















{kind=link}