


Intro
This mission is about getting higher zero-shot Classification of photographs and textual content utilizing CV/LLM fashions with out spending money and time fine-tuning in coaching, or re-running fashions in inference. It makes use of a novel dimensionality discount method on embeddings and determines lessons utilizing event model pair-wise comparability. It resulted in a rise in textual content/picture settlement from 61% to 89% for a 50k dataset over 13 lessons.
https://github.com/doc1000/pairwise_classification
The place you’ll use it
The sensible software is in large-scale class search the place pace of inference is essential and mannequin price spend is a priority. It is usually helpful to find errors in your annotation course of — misclassifications in a big database.
Outcomes
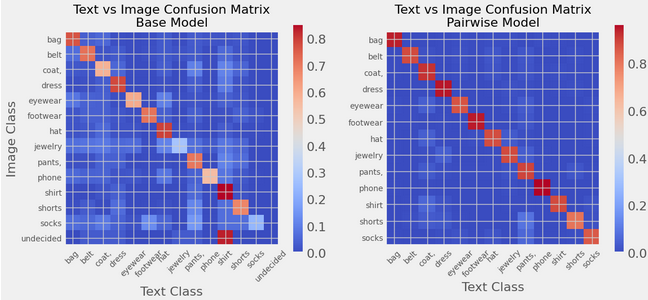
The weighted F1 rating evaluating the textual content and picture class settlement went from 61% to 88% for ~50k gadgets throughout 13 lessons. A visible inspection additionally validated the outcomes.
| F1_score (weighted) | base mannequin | pairwise |
| Multiclass | 0.613 | 0.889 |
| Binary | 0.661 | 0.645 |

Left: Base, full embedding, argmax on cosine similarity mannequin
Proper: pairwise tourney mannequin utilizing function sub-segments scored by crossratio
Picture by writer
Technique: Pairwise comparability of cosine similarity of embedding sub-dimensions decided by mean-scale scoring
An easy solution to vector classification is to match picture/textual content embeddings to class embeddings utilizing cosine similarity. It’s comparatively fast and requires minimal overhead. You may also run a classification mannequin on the embeddings (logistic regressions, bushes, svm) and goal the category with out additional embeddings.
My method was to scale back the function measurement within the embeddings figuring out which function distributions had been considerably completely different between two lessons, and thus contributed data with much less noise. For scoring options, I used a derivation of variance that encompasses two distributions, which I confer with as cross-variance (extra beneath). I used this to get essential dimensions for the ‘clothes’ class (one-vs-the relaxation) and re-classified utilizing the sub-features, which confirmed some enchancment in mannequin energy. Nevertheless, the sub-feature comparability confirmed higher outcomes when evaluating lessons pairwise (one vs one/face to face). Individually for photographs and textual content, I constructed an array-wide ‘event’ model bracket of pairwise comparisons, till a remaining class was decided for every merchandise. It finally ends up being pretty environment friendly. I then scored the settlement between the textual content and picture classifications.
Utilizing cross variance, pair particular function choice and pairwise tourney project.

I’m utilizing a product picture database that was available with pre-calculated CLIP embeddings (thanks SQID (Cited beneath. This dataset is launched underneath the MIT License), AMZN (Cited beneath. This dataset is licensed underneath Apache License 2.0) and concentrating on the clothes photographs as a result of that’s the place I first noticed this impact (thanks DS group at Nordstrom). The dataset was narrowed down from 150k gadgets/photographs/descriptions to ~50k clothes gadgets utilizing zero shot classification, then the augmented classification primarily based on focused subarrays.

Take a look at Statistic: Cross Variance
This can be a methodology to find out how completely different the distribution is for 2 completely different lessons when concentrating on a single function/dimension. It’s a measure of the mixed common variance if every ingredient of each distributions is dropped into the opposite distribution. It’s an growth of the mathematics of variance/customary deviation, however between two distributions (that may be of various measurement). I’ve not seen it used earlier than, though it could be listed underneath a unique moniker.
Cross Variance:

Just like variance, besides summing over each distributions and taking a distinction of every worth as an alternative of the imply of the only distribution. Should you enter the identical distribution as A and B, then it yields the identical outcomes as variance.
This simplifies to:

That is equal to the alternate definition of variance (the imply of the squares minus the sq. of the imply) for a single distribution when the distributions i and j are equal. Utilizing this model is massively sooner and extra reminiscence environment friendly than trying to broadcast the arrays instantly. I’ll present the proof and go into extra element in one other write-up. Cross deviation(ς) is the sq. root of undefined.
To attain options, I exploit a ratio. The numerator is cross variance. The denominator is the product of ij, identical because the denominator of Pearson correlation. Then I take the foundation (I may simply as simply use cross variance, which might evaluate extra instantly with covariance, however I’ve discovered the ratio to be extra compact and interpretable utilizing cross dev).

I interpret this because the elevated mixed customary deviation for those who swapped lessons for every merchandise. A big quantity means the function distribution is probably going fairly completely different for the 2 lessons.

Picture by writer
That is another mean-scale distinction Ks_test; Bayesian 2dist checks and Frechet Inception Distance are alternate options. I just like the class and novelty of cross var. I’ll seemingly comply with up by different differentiators. I ought to notice that figuring out distributional variations for a normalized function with total imply 0 and sd = 1 is its personal problem.
Sub-dimensions: dimensionality discount of embedding area for classification
When you find yourself looking for a specific attribute of a picture, do you want the entire embedding? Is coloration or whether or not one thing is a shirt or pair of pants situated in a slim part of the embedding? If I’m in search of a shirt, I don’t essentially care if it’s blue or purple, so I simply take a look at the scale that outline ‘shirtness’ and throw out the scale that outline coloration.

Picture by writer
I’m taking a [n,768] dimensional embedding and narrowing it right down to nearer to 100 dimensions that truly matter for a specific class pair. Why? As a result of the cosine similarity metric (cosim) will get influenced by the noise of the comparatively unimportant options. The embedding carries an amazing quantity of knowledge, a lot of which you merely don’t care about in a classification downside. Eliminate the noise and the sign will get stronger: cosim will increase with elimination of ‘unimportant’ dimensions.

Picture by writer
For a pairwise comparisons, first cut up gadgets into lessons utilizing customary cosine similarity utilized to the total embedding. I exclude some gadgets that present very low cosim on the belief that the mannequin ability is low for these gadgets (cosim restrict). I additionally exclude gadgets that present low differentiation between the 2 lessons (cosim diff). The result’s two distributions upon which to extract essential dimensions that ought to outline the ‘true’ distinction between the classifications:

Picture by writer
Array Pairwise Tourney Classification
Getting a worldwide class project out of pairwise comparisons requires some thought. You possibly can take the given project and evaluate simply that class to all of the others. If there was good ability within the preliminary project, this could work nicely, but when a number of alternate lessons are superior, you run into hassle. A cartesian method the place you evaluate all vs all would get you there, however would get huge shortly. I settled on an array-wide ‘event’ model bracket of pairwise comparisons.

This has log_2 (#lessons) rounds and complete variety of comparisons maxing at summation_round(combo(#lessons in spherical)*n_items) throughout some specified # of options. I randomize the ordering of ‘groups’ every spherical so the comparisons aren’t the identical every time. It has some match up danger however will get to a winner shortly. It’s constructed to deal with an array of comparisons at every spherical, reasonably than iterating over gadgets.
Scoring
Lastly, I scored the method by figuring out if the classification from textual content and pictures match. So long as the distribution isn’t closely obese in the direction of a ‘default’ class (it isn’t), this ought to be an excellent evaluation of whether or not the method is pulling actual data out of the embeddings.
I regarded on the weighted F1 rating evaluating the lessons assigned utilizing the picture vs the textual content description. The belief the higher the settlement, the extra seemingly the classification is appropriate. For my dataset of ~50k photographs and textual content descriptions of clothes with 13 lessons, the beginning rating of the straightforward full-embedding cosine similarity mannequin went from 42% to 55% for the sub-feature cosim, to 89% for the pairwise mannequin with sub-features.. A visible inspection additionally validated the outcomes. The binary classification wasn’t the first objective – it was largely to get a sub-segment of the info to then check multi-class boosting.
| base mannequin | pairwise | |
| Multiclass | 0.613 | 0.889 |
| Binary | 0.661 | 0.645 |

Picture by writer

Picture by writer utilizing code from Nils Flaschel
Remaining Ideas…
This can be an excellent methodology for locating errors in giant subsets of annotated knowledge, or doing zero shot labeling with out in depth additional GPU time for high-quality tuning and coaching. It introduces some novel scoring and approaches, however the total course of just isn’t overly sophisticated or CPU/GPU/reminiscence intensive.
Observe up might be making use of it to different picture/textual content datasets in addition to annotated/categorized picture or textual content datasets to find out if scoring is boosted. As well as, it could be fascinating to find out whether or not the increase in zero shot classification for this dataset modifications considerably if:
- Different scoring metrics are used as an alternative of cross deviation ratio
- Full function embeddings are substituted for focused options
- Pairwise tourney is changed by one other method
I hope you discover it helpful.
Citations
@article{reddy2022shopping,title={Purchasing Queries Dataset: A Giant-Scale {ESCI} Benchmark for Bettering Product Search},writer={Chandan Ok. Reddy and Lluís Màrquez and Fran Valero and Nikhil Rao and Hugo Zaragoza and Sambaran Bandyopadhyay and Arnab Biswas and Anlu Xing and Karthik Subbian},yr={2022},eprint={2206.06588},archivePrefix={arXiv}}
Purchasing Queries Picture Dataset (SQID): An Picture-Enriched ESCI Dataset for Exploring Multimodal Studying in Product Search, M. Al Ghossein, C.W. Chen, J. Tang
















{kind=link}