


The trade’s outliers have distorted our definition of Recommender Methods. TikTok, Spotify, and Netflix make use of hybrid deep studying fashions combining collaborative- and content-based filtering to ship personalised suggestions you didn’t even know you’d like. In the event you’re contemplating a RecSys position, you may count on to dive into these straight away. However not all RecSys issues function — or must function — at this stage. Most practitioners work with comparatively easy, tabular fashions, usually gradient-boosted bushes. Till attending RecSys ’25 in Prague, I assumed my expertise was an outlier. Now I imagine that is the norm, hidden behind the large outliers that drive the trade’s cutting-edge. So what units these giants aside from most different corporations? On this article, I exploit the framework mapped within the picture above to motive about these variations and assist place your personal advice work on the spectrum.
Most advice programs start with a candidate era part, lowering tens of millions of potential objects to a manageable set that may be ranked by higher-latency options. However candidate era isn’t all the time the uphill battle it’s made out to be, nor does it essentially require machine studying. Contexts with well-defined scopes and exhausting filters usually don’t require advanced querying logic or vector search. Think about Reserving.com: when a person searches for “4-star inns in Barcelona, October 1-4,” the geography and availability constraints have already narrowed tens of millions of properties down to some hundred. The true problem for machine studying practitioners is then rating these inns with precision. That is vastly completely different from Amazon’s product search or the YouTube homepage, the place exhausting filters are absent. In these environments, scalable machine studying is required to cut back an immense catalog to a smaller, semantic- and intent-sensitive candidate set — all earlier than rating even takes place.
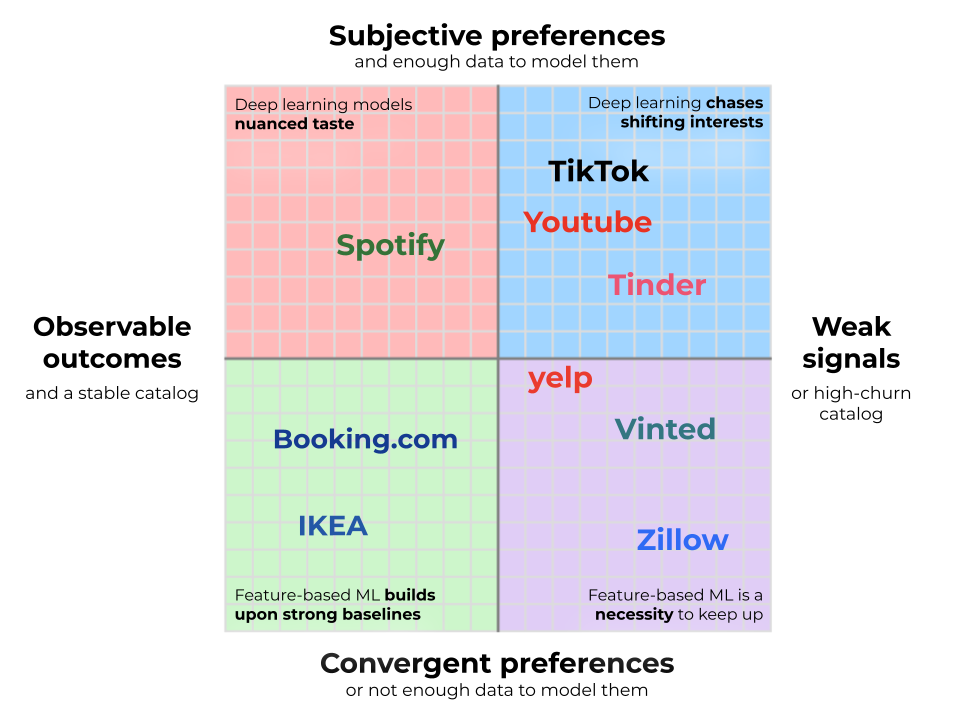
Past candidate era, the complexity of rating is greatest understood by way of the 2 dimensions mapped within the picture under. First, observable outcomes and catalog stability, which decide how robust a baseline you possibly can have. Second, the subjectivity of preferences and their learnability, which decide how advanced your personalization answer must be.

Observable Outcomes and Catalog Stability
On the left finish of the x-axis are companies that instantly observe their most essential outcomes. Giant retailers like IKEA are a great instance of this: when a buyer buys an ESKILSTUNA couch as a substitute of a KIVIK, the sign is unambiguous. Mixture sufficient of those, and the corporate is aware of precisely which product has the upper buy price. When you possibly can instantly observe customers voting with their wallets, you’ve a powerful baseline that’s exhausting to beat.
On the different excessive are platforms that may’t observe whether or not their suggestions truly succeeded. Tinder and Bumble may see customers match, however they usually gained’t know whether or not the pair hit it off (particularly as customers transfer off to different platforms). Yelp can advocate eating places, however for the overwhelming majority, they’ll’t observe whether or not you truly visited, simply which listings you clicked. Counting on such upper-funnel indicators means place bias dominates: objects in prime positions accumulate interactions no matter true high quality, making it practically not possible to inform whether or not engagement displays real choice or mere visibility. Distinction this with the IKEA instance: a person may click on a restaurant on Yelp just because it appeared first, however they’re far much less possible to purchase a settee for that very same motive. Within the absence of a tough conversion, you lose the anchor of a dependable leaderboard. This forces you to work a lot more durable to extract sign from the noise. Critiques can provide some grounding, however they’re hardly ever dense sufficient to work as a main sign. As a substitute, you might be left to run countless experiments in your rating heuristics, always tuning logic to squeeze a proxy for high quality out of a stream of weak indicators.
Excessive-Churn Catalog
Even with observable outcomes, nevertheless, a powerful baseline is just not assured. In case your catalog is continually altering, you might not accumulate sufficient information to construct a correct leaderboard. Actual property platforms like Zillow and secondhand websites like Vinted face probably the most excessive model: every merchandise has a list of 1, disappearing the second it’s bought. This forces you to depend on simplistic and inflexible types like “latest first” or “lowest value per sq. meter.” These are far weaker than conversion leaderboards primarily based on actual, dense person sign. To do higher, you will need to leverage machine studying to foretell conversion chance instantly, combining intrinsic attributes with debiased short-term efficiency to floor the most effective stock earlier than it disappears.
The Ubiquity of Characteristic-Primarily based Fashions
No matter your catalog’s stability or sign energy, the core problem stays the identical: you are attempting to enhance upon no matter baseline is accessible. That is usually achieved by coaching a machine studying (ML) mannequin to foretell the chance of engagement or conversion given a selected context. Gradient-boosted bushes (GBDTs) are the pragmatic selection, a lot sooner to coach and tune than deep studying.
GBDTs predict these outcomes primarily based on engineered merchandise options: categorical and numerical attributes that quantify and describe a product. Even earlier than particular person preferences are recognized, GBDTs may adapt suggestions leveraging fundamental person options like nation and machine kind. With these merchandise and person options alone, an ML mannequin can already enhance upon the baseline — whether or not which means debiasing a recognition leaderboard or rating a high-churn feed. As an illustration, in vogue e-commerce, fashions generally use location and time of yr to floor objects tied to the season, whereas concurrently utilizing nation and machine to calibrate the worth level.
These options enable the mannequin to fight the aforementioned place bias by separating true high quality from mere visibility. By studying which intrinsic attributes drive conversion, the mannequin can appropriate for the place bias inherent in your recognition baseline. It learns to establish objects that carry out on benefit, somewhat than just because they had been ranked on the prime. That is more durable than it appears to be like: you threat demoting confirmed winners greater than you must, doubtlessly degrading the expertise.
Opposite to common perception, feature-based fashions may drive personalization. Gadgets may be encoded into embeddings from two sources: semantic content material (descriptions, photographs, and critiques on platforms like Reserving.com and Yelp) or interplay information (strategies like StarSpace that study from which objects are clicked or seen collectively). By leveraging a person’s latest interactions, we will calculate similarity scores in opposition to candidate objects and feed these to the gradient-boosted mannequin as options.
This strategy has its limits, nevertheless. A GBDT may study to advertise eating places much like a person’s latest Italian searches on Yelp, however the similarity itself is drawn from semantic content material or from which eating places are incessantly clicked collectively, not from which of them customers truly e book. Deep studying fashions study merchandise representations end-to-end: the embeddings are optimized to maximise efficiency on the ultimate process. Whether or not this limitation issues is determined by one thing extra basic: how a lot customers truly disagree.
Subjectivity
Not all domains are equally private or controversial. In some, customers largely agree on what makes a great product as soon as fundamental constraints are glad. We name these convergent preferences, and so they occupy the underside half of the chart. Take Reserving.com: vacationers could have completely different budgets and placement preferences, however as soon as these are revealed by way of filters and map interactions, rating standards converge — greater costs are unhealthy, facilities are good, good critiques are higher. Or take into account Staples: as soon as a person wants printer paper or AA batteries, model and value dominate, making person preferences remarkably constant.
On the different excessive — the highest half — are subjective domains outlined by extremely fragmented style. Spotify exemplifies this: one person’s favourite observe is one other’s instant skip. But, style hardly ever exists in a vacuum. Someplace within the information is a person in your actual wavelength, and machine studying bridges the hole, turning their discoveries from yesterday into your suggestions for at the moment. Right here, the worth of personalization is big, and so is the technical funding required.
The Proper Information
Subjective style is simply actionable in case you have sufficient information to watch it. Many domains contain distinct preferences however lack the suggestions loop to seize them. A distinct segment content material platform, new market, or B2B product could face wildly divergent tastes but lack the clear sign to study them. Yelp restaurant suggestions illustrate this problem: eating preferences are subjective, however the platform can’t observe precise restaurant visits, solely clicks. This implies they’ll’t optimize personalization for the true goal (conversions). They will solely optimize for proxy metrics like clicks, however extra clicks may truly sign failure, indicating customers are shopping a number of listings with out discovering what they need.
However in subjective domains with dense behavioral information, failing to personalize leaves cash on the desk. YouTube exemplifies this: with billions of each day interactions, the platform learns nuanced viewer preferences and surfaces movies you didn’t know you needed. Right here, deep studying turns into unavoidable. That is the purpose the place you’ll see giant groups coordinating over Jira and cloud payments that require VP approval. Whether or not that complexity is justified comes down completely to the information you’ve.
Know The place You Stand
Understanding the place your downside sits on this spectrum is much extra helpful than blindly chasing the most recent structure. The trade’s “state-of-the-art” is essentially outlined by the outliers — the tech giants coping with huge, subjective inventories and dense person information. Their options are well-known as a result of their issues are excessive, not as a result of they’re universally appropriate.
Nonetheless, you’ll possible face completely different constraints in your personal work. In case your area is outlined by a secure catalog and observable outcomes, you land within the bottom-left quadrant alongside corporations like IKEA and Reserving.com. Right here, recognition baselines are so robust that the problem is solely constructing upon them with machine studying fashions that may drive measurable A/B take a look at wins. If, as a substitute, you face excessive churn (like Vinted) or weak indicators (like Yelp), machine studying turns into a necessity simply to maintain up.
However that doesn’t imply you’ll want deep studying. That added complexity solely really pays off in territories the place preferences are deeply subjective and there’s sufficient information to mannequin them. We frequently deal with programs like Netflix or Spotify because the gold commonplace, however they’re specialised options to uncommon situations. For the remainder of us, excellence isn’t about deploying probably the most advanced structure accessible; it’s about recognizing the constraints of the terrain and having the boldness to decide on the answer that solves your issues.
Photographs by the creator.















{kind=link}