


How do neural networks be taught to estimate depth from 2D photos?
14 hours in the past
What’s Monocular Depth Estimation?

Monocular Depth Estimation (MDE) is the duty of coaching a neural community to find out depth data from a single picture. That is an thrilling and difficult space of Machine Studying and Laptop Imaginative and prescient as a result of predicting a depth map requires the neural community to type a three-d understanding from only a 2-dimensional picture.
On this article, we’ll talk about a brand new mannequin known as Depth Something V2 and its precursor, Depth Something V1. Depth Something V2 has outperformed almost all different fashions in Depth Estimation, exhibiting spectacular outcomes on difficult photos.

This text relies on a video I made on the identical subject. Here’s a video hyperlink for learners preferring a visible medium. For individuals who want studying, proceed!
Why ought to we even care about MDE fashions?
Good MDE fashions have many sensible makes use of, akin to aiding navigation and impediment avoidance for robots, drones, and autonomous automobiles. They may also be utilized in video and picture enhancing, background alternative, object elimination, and creating 3D results. Moreover, they’re helpful for AR and VR headsets to create interactive 3D areas across the consumer.
There are two predominant approaches for doing MDE (this text solely covers one)
Two predominant approaches have emerged for coaching MDE fashions — one, discriminative approaches the place the community tries to foretell depth as a supervised studying goal, and two, generative approaches like conditional diffusion the place depth prediction is an iterative picture era process. Depth Something belongs to the primary class of discriminative approaches, and that’s what we might be discussing right now. Welcome to Neural Breakdown, and let’s go deep with Depth Estimation[!
To fully understand Depth Anything, let’s first revisit the MiDAS paper from 2019, which serves as a precursor to the Depth Anything algorithm.

MiDAS trains an MDE model using a combination of different datasets containing labeled depth information. For instance, the KITTI dataset for autonomous driving provides outdoor images, while the NYU-Depth V2 dataset offers indoor scenes. Understanding how these datasets are collected is crucial because newer models like Depth Anything and Depth Anything V2 address several issues inherent in the data collection process.
How real-world depth datasets are collected
These datasets are typically collected using stereo cameras, where two or more cameras placed at fixed distances capture images simultaneously from slightly different perspectives, allowing for depth information extraction. The NYU-Depth V2 dataset uses RGB-D cameras that capture depth values along with pixel colors. Some datasets utilize LiDAR, projecting laser beams to capture 3D information about a scene.
However, these methods come with several problems. The amount of labeled data is limited due to the high operational costs of obtaining these datasets. Additionally, the annotations can be noisy and low-resolution. Stereo cameras struggle under various lighting conditions and can’t reliably identify transparent or highly reflective surfaces. LiDAR is expensive, and both LiDAR and RGB-D cameras have limited range and generate low-resolution, sparse depth maps.
Can we use Unlabelled Images to learn Depth Estimation?
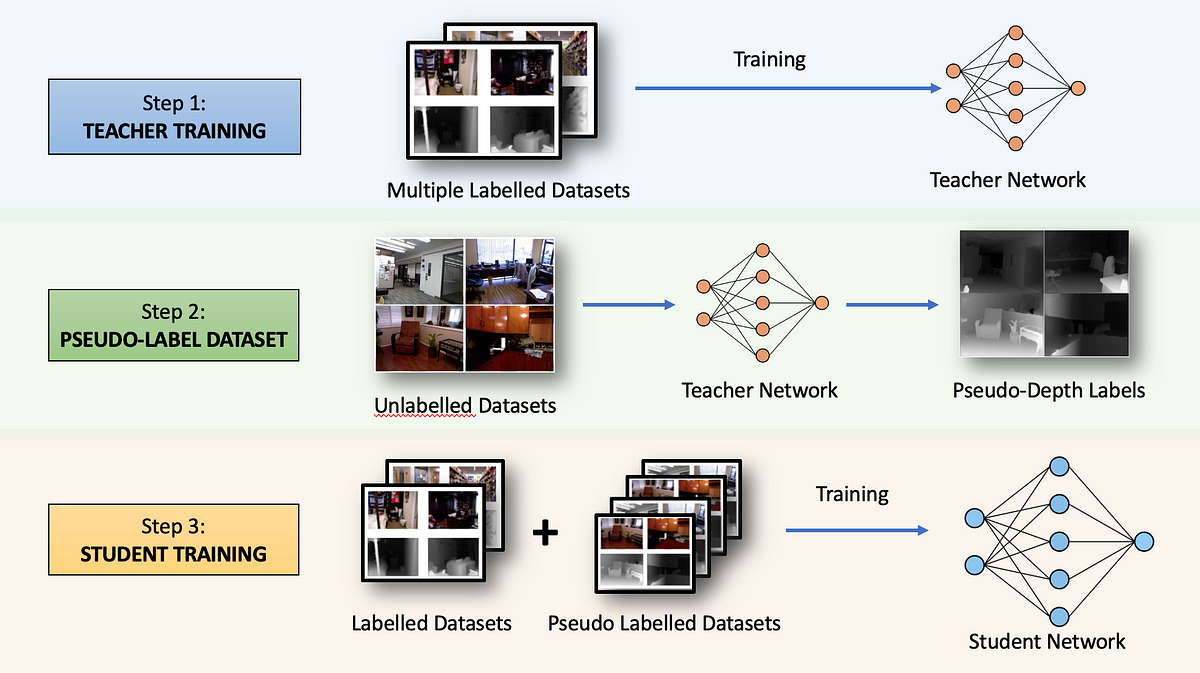
It would be beneficial to use unlabeled images to train depth estimation models, given the abundance of such images available online. The major innovation proposed in the original Depth Anything paper from 2023 was the incorporation of these unlabeled datasets into the training pipeline. In the next section, we’ll explore how this was achieved.
How do neural networks be taught to estimate depth from 2D photos?
14 hours in the past
What’s Monocular Depth Estimation?
Monocular Depth Estimation (MDE) is the duty of coaching a neural community to find out depth data from a single picture. That is an thrilling and difficult space of Machine Studying and Laptop Imaginative and prescient as a result of predicting a depth map requires the neural community to type a three-d understanding from only a 2-dimensional picture.
On this article, we’ll talk about a brand new mannequin known as Depth Something V2 and its precursor, Depth Something V1. Depth Something V2 has outperformed almost all different fashions in Depth Estimation, exhibiting spectacular outcomes on difficult photos.
This text relies on a video I made on the identical subject. Here’s a video hyperlink for learners preferring a visible medium. For individuals who want studying, proceed!
Why ought to we even care about MDE fashions?
Good MDE fashions have many sensible makes use of, akin to aiding navigation and impediment avoidance for robots, drones, and autonomous automobiles. They may also be utilized in video and picture enhancing, background alternative, object elimination, and creating 3D results. Moreover, they’re helpful for AR and VR headsets to create interactive 3D areas across the consumer.
There are two predominant approaches for doing MDE (this text solely covers one)
Two predominant approaches have emerged for coaching MDE fashions — one, discriminative approaches the place the community tries to foretell depth as a supervised studying goal, and two, generative approaches like conditional diffusion the place depth prediction is an iterative picture era process. Depth Something belongs to the primary class of discriminative approaches, and that’s what we might be discussing right now. Welcome to Neural Breakdown, and let’s go deep with Depth Estimation[!
To fully understand Depth Anything, let’s first revisit the MiDAS paper from 2019, which serves as a precursor to the Depth Anything algorithm.
MiDAS trains an MDE model using a combination of different datasets containing labeled depth information. For instance, the KITTI dataset for autonomous driving provides outdoor images, while the NYU-Depth V2 dataset offers indoor scenes. Understanding how these datasets are collected is crucial because newer models like Depth Anything and Depth Anything V2 address several issues inherent in the data collection process.
How real-world depth datasets are collected
These datasets are typically collected using stereo cameras, where two or more cameras placed at fixed distances capture images simultaneously from slightly different perspectives, allowing for depth information extraction. The NYU-Depth V2 dataset uses RGB-D cameras that capture depth values along with pixel colors. Some datasets utilize LiDAR, projecting laser beams to capture 3D information about a scene.
However, these methods come with several problems. The amount of labeled data is limited due to the high operational costs of obtaining these datasets. Additionally, the annotations can be noisy and low-resolution. Stereo cameras struggle under various lighting conditions and can’t reliably identify transparent or highly reflective surfaces. LiDAR is expensive, and both LiDAR and RGB-D cameras have limited range and generate low-resolution, sparse depth maps.
Can we use Unlabelled Images to learn Depth Estimation?
It would be beneficial to use unlabeled images to train depth estimation models, given the abundance of such images available online. The major innovation proposed in the original Depth Anything paper from 2023 was the incorporation of these unlabeled datasets into the training pipeline. In the next section, we’ll explore how this was achieved.















{kind=link}