



The shopper help groups had been drowning with the overwhelming quantity of buyer inquiries at each firm I’ve labored at. Have you ever had related experiences?
What if I instructed you that you could possibly use AI to mechanically establish, categorize, and even resolve the most typical points?
By fine-tuning a transformer mannequin like BERT, you’ll be able to construct an automatic system that tags tickets by challenge kind and routes them to the fitting workforce.
On this tutorial, I’ll present you the right way to fine-tune a transformer mannequin for emotion classification in 5 steps:
- Set Up Your Surroundings: Put together your dataset and set up crucial libraries.
- Load and Preprocess Knowledge: Parse textual content recordsdata and arrange your information.
- High-quality-Tune Distilbert: Practice mannequin to categorise feelings utilizing your dataset.
- Consider Efficiency: Use metrics like accuracy, F1-score, and confusion matrices to measure mannequin efficiency.
- Interpret Predictions: Visualize and perceive predictions utilizing SHAP (SHapley Additive exPlanations).
By the tip, you’ll have a fine-tuned mannequin that classifies feelings from textual content inputs with excessive accuracy, and also you’ll additionally discover ways to interpret these predictions utilizing SHAP.
This similar strategy could be utilized to real-world use instances past emotion classification, reminiscent of buyer help automation, sentiment evaluation, content material moderation, and extra.
Let’s dive in!
Selecting the Proper Transformer Mannequin
When deciding on a transformer mannequin for Textual content Classification, right here’s a fast breakdown of the most typical fashions:
- BERT: Nice for basic NLP duties, however computationally costly for each coaching and inference.
- DistilBERT: 60% sooner than BERT whereas retaining 97% of its capabilities, making it perfect for real-time functions.
- RoBERTa: A extra strong model of BERT, however requires extra sources.
- XLM-RoBERTa: A multilingual variant of RoBERTa skilled on 100 languages. It’s excellent for multilingual duties, however is kind of resource-intensive.
For this tutorial, I selected to fine-tune DistilBERT as a result of it provides the very best stability between efficiency and effectivity.
Step 1: Setup and Putting in Dependencies
Guarantee you have got the required libraries put in:
!pip set up datasets transformers torch scikit-learn shapStep 2: Load and Preprocess Knowledge
I used the Feelings dataset for NLP by Praveen Govi, accessible on Kaggle and licensed for industrial use. It incorporates textual content labeled with feelings. The info is available in three .txt recordsdata: prepare, validation, and check.
Every line incorporates a sentence and its corresponding emotion label, separated by a semicolon:
textual content; emotion
"i didnt really feel humiliated"; "unhappiness"
"i'm feeling grouchy"; "anger"
"im updating my weblog as a result of i really feel shitty"; "unhappiness"Parsing the Dataset right into a Pandas DataFrame
Let’s load the dataset:
def parse_emotion_file(file_path):
"""
Parses a textual content file with every line within the format: {textual content; emotion}
and returns a pandas DataFrame with 'textual content' and 'emotion' columns.
Args:
- file_path (str): Path to the .txt file to be parsed
Returns:
- df (pd.DataFrame): DataFrame containing 'textual content' and 'emotion' columns
"""
texts = []
feelings = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
attempt:
# Break up every line by the semicolon separator
textual content, emotion = line.strip().cut up(';')
# append textual content and emotion to separate lists
texts.append(textual content)
feelings.append(emotion)
besides ValueError:
proceed
return pd.DataFrame({'textual content': texts, 'emotion': feelings})
# Parse textual content recordsdata and retailer as Pandas DataFrames
train_df = parse_emotion_file("prepare.txt")
val_df = parse_emotion_file("val.txt")
test_df = parse_emotion_file("check.txt")Understanding the Label Distribution
This dataset incorporates 16k coaching examples and 2k examples for the validation and testing. Right here’s the label distribution breakdown:
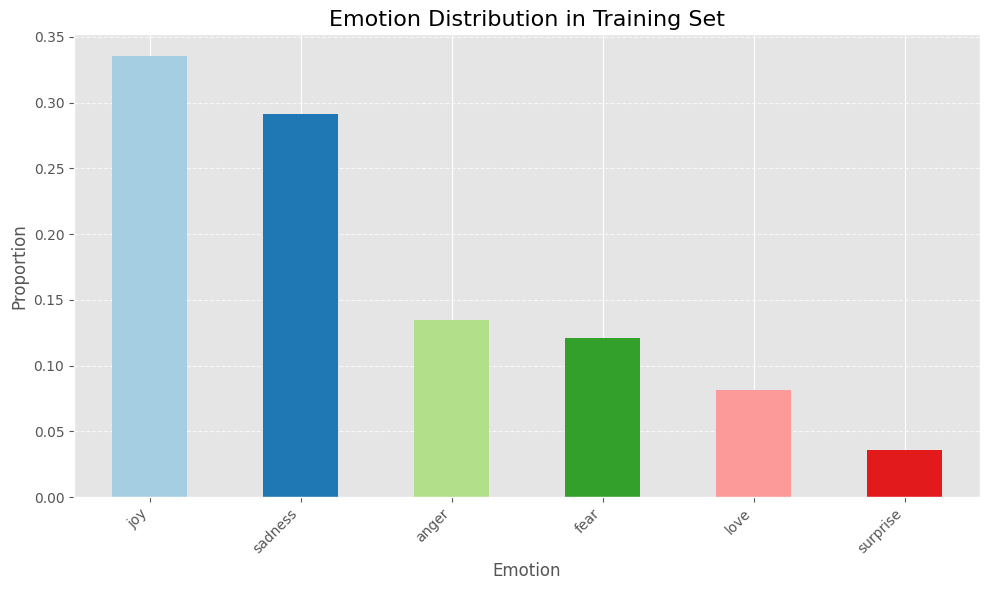
The bar chart above reveals that the dataset is imbalanced, with nearly all of samples labels as pleasure and unhappiness.
For a fine-tuning a manufacturing mannequin, I might think about experimenting with totally different sampling strategies to beat this class imbalance downside and enhance the mannequin’s efficiency.
Step 3: Tokenization and Knowledge Preprocessing
Subsequent, I loaded in DistilBERT’s tokenizer:
from transformers import AutoTokenizer
# Outline the mannequin path for DistilBERT
model_name = "distilbert-base-uncased"
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)Then, I used it to tokenize textual content information and rework the labels into numerical IDs:
# Tokenize information
def preprocess_function(df, label2id):
"""
Tokenizes textual content information and transforms labels into numerical IDs.
Args:
df (dict or pandas.Sequence): A dictionary-like object containing "textual content" and "emotion" fields.
label2id (dict): A mapping from emotion labels to numerical IDs.
Returns:
dict: A dictionary containing:
- "input_ids": Encoded token sequences
- "attention_mask": Masks to point padding tokens
- "label": Numerical labels for classification
Instance utilization:
train_dataset = train_dataset.map(lambda x: preprocess_function(x, tokenizer, label2id), batched=True)
"""
tokenized_inputs = tokenizer(
df["text"],
padding="longest",
truncation=True,
max_length=512,
return_tensors="pt"
)
tokenized_inputs["label"] = [label2id.get(emotion, -1) for emotion in df["emotion"]]
return tokenized_inputs
# Convert the DataFrames to HuggingFace Dataset format
train_dataset = Dataset.from_pandas(train_df)
# Apply the 'preprocess_function' to tokenize textual content information and rework labels
train_dataset = train_dataset.map(lambda x: preprocess_function(x, label2id), batched=True)Step 4: High-quality-Tuning Mannequin
Subsequent, I loaded a pre-trained DistilBERT mannequin with a classification head for our textual content classification textual content. I additionally specified what the labels for this dataset appears like:
# Get the distinctive emotion labels from the 'emotion' column within the coaching DataFrame
labels = train_df["emotion"].distinctive()
# Create label-to-id and id-to-label mappings
label2id = {label: idx for idx, label in enumerate(labels)}
id2label = {idx: label for idx, label in enumerate(labels)}
# Initialize mannequin
mannequin = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=len(labels),
id2label=id2label,
label2id=label2id
)The pre-trained DistilBERT mannequin for classification consists of 5 layers plus a classification head.
To stop overfitting, I froze the primary 4 layers, preserving the information realized throughout pre-training. This enables the mannequin to retain basic language understanding whereas solely fine-tuning the fifth layer and classification head to adapt to my dataset. Right here’s how I did this:
# freeze base mannequin parameters
for identify, param in mannequin.base_model.named_parameters():
param.requires_grad = False
# maintain classifier trainable
for identify, param in mannequin.base_model.named_parameters():
if "transformer.layer.5" in identify or "classifier" in identify:
param.requires_grad = TrueDefining Metrics
Given the label imbalance, I believed accuracy might not be probably the most acceptable metric, so I selected to incorporate different metrics suited to classification issues like precision, recall, F1-score, and AUC rating.
I additionally used “weighted” averaging for F1-score, precision, and recall to deal with the category imbalance downside. This parameter ensures that each one lessons contribute proportionally to the metric and forestall any single class from dominating the outcomes:
def compute_metrics(p):
"""
Computes accuracy, F1 rating, precision, and recall metrics for multiclass classification.
Args:
p (tuple): Tuple containing predictions and labels.
Returns:
dict: Dictionary with accuracy, F1 rating, precision, and recall metrics, utilizing weighted averaging
to account for sophistication imbalance in multiclass classification duties.
"""
logits, labels = p
# Convert logits to possibilities utilizing softmax (PyTorch)
softmax = torch.nn.Softmax(dim=1)
probs = softmax(torch.tensor(logits))
# Convert logits to predicted class labels
preds = probs.argmax(axis=1)
return {
"accuracy": accuracy_score(labels, preds), # Accuracy metric
"f1_score": f1_score(labels, preds, common="weighted"), # F1 rating with weighted common for imbalanced information
"precision": precision_score(labels, preds, common="weighted"), # Precision rating with weighted common
"recall": recall_score(labels, preds, common="weighted"), # Recall rating with weighted common
"auc_score": roc_auc_score(labels, probs, common="macro", multi_class="ovr")
}Let’s arrange the coaching course of:
# Outline hyperparameters
lr = 2e-5
batch_size = 16
num_epochs = 3
weight_decay = 0.01
# Arrange coaching arguments for fine-tuning fashions
training_args = TrainingArguments(
output_dir="./outcomes",
evaluation_strategy="steps",
eval_steps=500,
learning_rate=lr,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epochs,
weight_decay=weight_decay,
logging_dir="./logs",
logging_steps=500,
load_best_model_at_end=True,
metric_for_best_model="eval_f1_score",
greater_is_better=True,
)
# Initialize the Coach with the mannequin, arguments, and datasets
coach = Coach(
mannequin=mannequin,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
# Practice the mannequin
print(f"Coaching {model_name}...")
coach.prepare()Step 5: Evaluating Mannequin Efficiency
After coaching, I evaluated the mannequin’s efficiency on the check set:
# Generate predictions on the check dataset with fine-tuned mannequin
predictions_finetuned_model = coach.predict(test_dataset)
preds_finetuned = predictions_finetuned_model.predictions.argmax(axis=1)
# Compute analysis metrics (accuracy, precision, recall, and F1 rating)
eval_results_finetuned_model = compute_metrics((predictions_finetuned_model.predictions, test_dataset["label"]))That is how the fine-tuned DistilBERT mannequin did on the check set in comparison with the pre-trained base mannequin:

Earlier than fine-tuning, the pre-trained mannequin carried out poorly on our dataset, as a result of it hasn’t seen the precise emotion labels earlier than. It was primarily guessing at random, as mirrored in an AUC rating of 0.5 that signifies no higher than likelihood.
After fine-tuning, the mannequin considerably improved throughout all metrics, reaching 83% accuracy in accurately figuring out feelings. This demonstrates that the mannequin has efficiently realized significant patterns within the information, even with simply 16k coaching samples.
That’s superb!
Step 6: Decoding Predictions with SHAP
I examined the fine-tuned mannequin on three sentences and listed below are the feelings that it predicted:
- “The considered talking in entrance of a big crowd makes my coronary heart race, and I begin to really feel overwhelmed with nervousness.” → worry 😱
- “I can’t imagine how disrespectful they had been! I labored so exhausting on this mission, they usually simply dismissed it with out even listening. It’s infuriating!” → anger 😡
- “I completely love this new cellphone! The digicam high quality is superb, the battery lasts all day, and it’s so quick. I couldn’t be happier with my buy, and I extremely suggest it to anybody in search of a brand new cellphone.” → pleasure 😀
Spectacular, proper?!
I needed to know how the mannequin made its predictions, I used utilizing SHAP (Shapley Additive exPlanations) to visualise function significance.
I began by creating an explainer:
# Construct a pipeline object for predictions
preds = pipeline(
"text-classification",
mannequin=model_finetuned,
tokenizer=tokenizer,
return_all_scores=True,
)
# Create an explainer
explainer = shap.Explainer(preds)Then, I computed SHAP values utilizing the explainer:
# Compute SHAP values utilizing explainer
shap_values = explainer(example_texts)
# Make SHAP textual content plot
shap.plots.textual content(shap_values)The plot under visualizes how every phrase within the enter textual content contributes to the mannequin’s output utilizing SHAP values:

On this case, the plot reveals that “nervousness” is an important consider predicting “worry” because the emotion.
The SHAP textual content plot is a pleasant, intuitive, and interactive technique to perceive predictions by breaking down how a lot every phrase influences the ultimate prediction.
Abstract
You’ve efficiently realized to fine-tune DistilBERT for emotion classification from textual content information! (You’ll be able to take a look at the mannequin on Hugging Face right here).
Transformer fashions could be fine-tuned for a lot of real-world functions, together with:
- Tagging customer support tickets (as mentioned within the introduction),
- Flagging psychological well being dangers in text-based conversations,
- Detecting sentiment in product critiques.
High-quality-tuning is an efficient and environment friendly technique to adapt highly effective pre-trained fashions to particular duties with a comparatively small dataset.
What’s going to you fine-tune subsequent?
Need to construct your AI expertise?
👉🏻 I run the AI Weekender and write weekly weblog posts on information science, AI weekend initiatives, profession recommendation for professionals in information.
Assets















{kind=link}