


On this article, you’ll study what small language fashions are, why they matter in 2026, and tips on how to use them successfully in actual manufacturing programs.
Subjects we are going to cowl embrace:
- What defines small language fashions and the way they differ from giant language fashions.
- The price, latency, and privateness benefits driving SLM adoption.
- Sensible use circumstances and a transparent path to getting began.
Let’s get straight to it.
Introduction to Small Language Fashions: The Full Information for 2026
Picture by Writer
Introduction
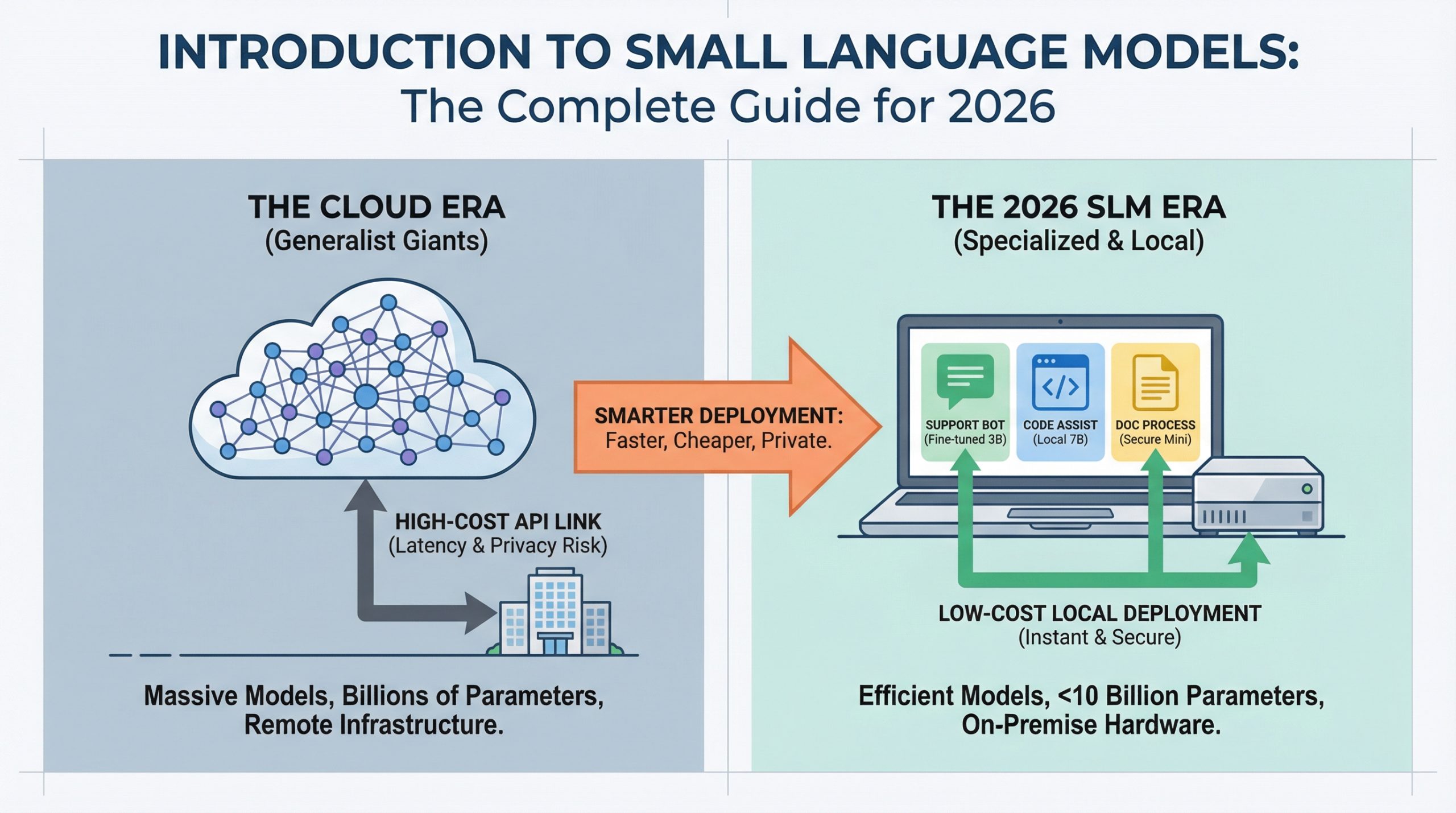
AI deployment is altering. Whereas headlines deal with ever-larger language fashions breaking new benchmarks, manufacturing groups are discovering that smaller fashions can deal with most on a regular basis duties at a fraction of the price.
In case you’ve deployed a chatbot, constructed a code assistant, or automated doc processing, you’ve in all probability paid for cloud API calls to fashions with a whole lot of billions of parameters. However most practitioners working in 2026 are discovering that for 80% of manufacturing use circumstances, a mannequin you possibly can run on a laptop computer works simply as properly and prices 95% much less. If you wish to soar straight into hands-on choices, our information to the Prime 7 Small Language Fashions You Can Run on a Laptop computer covers the very best fashions accessible right now and tips on how to get them working domestically.
Small language fashions (SLMs) make this doable. This information covers what they’re, when to make use of them, and the way they’re altering the economics of AI deployment.
What Are Small Language Fashions?
Small language fashions are language fashions with fewer than 10 billion parameters, normally starting from 1 billion to 7 billion.
Parameters are the “knobs and dials” inside a neural community. Every parameter is a numerical worth the mannequin makes use of to remodel enter textual content into predictions about what comes subsequent. Once you see “GPT-4 has over 1 trillion parameters,” which means the mannequin has 1 trillion of those adjustable values working collectively to know and generate language. Extra parameters usually imply extra capability to study patterns, however in addition they imply extra computational energy, reminiscence, and price to run.
The dimensions distinction is important. GPT-4 has over 1 trillion parameters, Claude Opus has a whole lot of billions, and even Llama 3.1 70B is taken into account “giant.” SLMs function at a very completely different scale.
However “small” doesn’t imply “easy.” Trendy SLMs like Phi-3 Mini (3.8B parameters), Llama 3.2 3B, and Mistral 7B ship efficiency that rivals fashions 10× their measurement on many duties. The actual distinction is specialization.
The place giant language fashions are skilled to be generalists with broad information spanning each subject conceivable, SLMs excel when fine-tuned for particular domains. A 3B mannequin skilled on buyer assist conversations will outperform GPT-4 in your particular assist queries whereas working on {hardware} you already personal.
You Don’t Construct Them From Scratch
Adopting an SLM doesn’t imply constructing one from the bottom up. Even “small” fashions are far too advanced for people or small groups to coach from scratch. As an alternative, you obtain a pre-trained mannequin that already understands language, then train it your particular area via fine-tuning.
It’s like hiring an worker who already speaks English and coaching them in your firm’s procedures, slightly than educating a child to talk from delivery. The mannequin arrives with normal language understanding in-built. You’re simply including specialised information.
You don’t want a group of PhD researchers or huge computing clusters. You want a developer with Python expertise, some instance information out of your area, and some hours of GPU time. The barrier to entry is far decrease than most individuals assume.
Why SLMs Matter in 2026
Three forces are driving SLM adoption: value, latency, and privateness.
Value: Cloud API pricing for big fashions runs $0.01 to $0.10 per 1,000 tokens. At scale, this provides up quick. A buyer assist system dealing with 100,000 queries per day can rack up $30,000+ month-to-month in API prices. An SLM working on a single GPU server prices the identical {hardware} whether or not it processes 10,000 or 10 million queries. The economics flip solely.
Latency: Once you name a cloud API, you’re ready for community round-trips plus inference time. SLMs working domestically reply in 50 to 200 milliseconds. For purposes like coding assistants or interactive chatbots, customers really feel this distinction instantly.
Privateness: Regulated industries (healthcare, finance, authorized) can’t ship delicate information to exterior APIs. SLMs let these organizations deploy AI whereas retaining information on-premise. No exterior API calls means no information leaves your infrastructure.
LLMs vs SLMs: Understanding the Commerce-offs
The choice between an LLM and an SLM is determined by matching functionality to necessities. The variations come all the way down to scale, deployment mannequin, and the character of the duty.
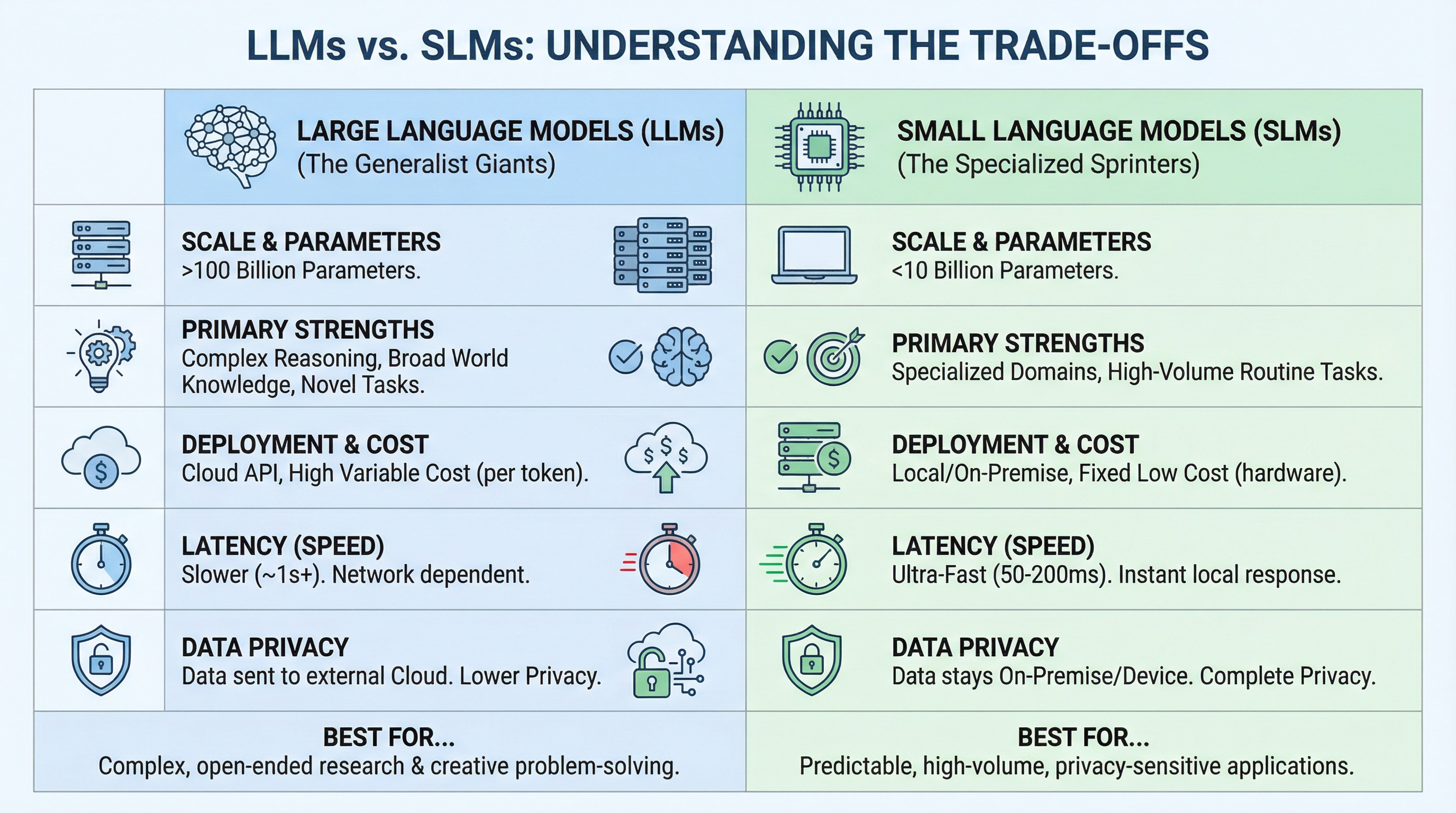
The comparability reveals a sample: LLMs are designed for breadth and unpredictability, whereas SLMs are constructed for depth and repetition. In case your activity requires dealing with any query about any subject, you want an LLM’s broad information. However in case you’re fixing the identical sort of downside hundreds of occasions, an SLM fine-tuned for that particular area can be sooner, cheaper, and infrequently extra correct.
Right here’s a concrete instance. In case you’re constructing a authorized doc analyzer, an LLM can deal with any authorized query from company regulation to worldwide treaties. However in case you’re solely processing employment contracts, a fine-tuned 7B mannequin can be sooner, cheaper, and extra correct on that particular activity.
Most groups are touchdown on a hybrid strategy: use SLMs for 80% of queries (the predictable ones), escalate to LLMs for the advanced 20%. This “router” sample combines the very best of each worlds.
How SLMs Obtain Their Edge
SLMs aren’t simply “small LLMs.” They use particular methods to ship excessive efficiency at low parameter counts.
Data Distillation trains smaller “scholar” fashions to imitate bigger “trainer” fashions. The coed learns to duplicate the trainer’s outputs with no need the identical huge structure. Microsoft’s Phi-3 sequence was distilled from a lot bigger fashions, retaining 90%+ of the aptitude at 5% of the scale.
Excessive-High quality Coaching Information issues extra for SLMs than sheer information amount. Whereas LLMs are skilled on trillions of tokens from all the web, SLMs profit from curated, high-quality datasets. Phi-3 was skilled on “textbook-quality” artificial information, fastidiously filtered to take away noise and redundancy.
Quantization compresses mannequin weights from 16-bit or 32-bit floating level to 4-bit or 8-bit integers. A 7B parameter mannequin in 16-bit precision requires 14GB of reminiscence. Quantized to 4-bit, it matches in 3.5GB (sufficiently small to run on a laptop computer). Trendy quantization methods like GGUF keep 95%+ of mannequin high quality whereas reaching 75% measurement discount.
Architectural Optimizations like sparse consideration scale back computational overhead. As an alternative of each token attending to each different token, fashions use methods like sliding-window consideration or grouped-query consideration to focus computation the place it issues most.
Manufacturing Use Instances
SLMs are already working manufacturing programs throughout industries.
Buyer Help: A serious e-commerce platform changed GPT-3.5 API calls with a fine-tuned Mistral 7B for tier-1 assist queries. They noticed a 90% value discount, 3× sooner response occasions, and equal or higher accuracy on frequent questions. Complicated queries nonetheless escalate to GPT-4, however 75% of tickets are dealt with by the SLM.
Code Help: Growth groups run Llama 3.2 3B domestically for code completion and easy refactoring. Builders get immediate recommendations with out sending proprietary code to exterior APIs. The mannequin was fine-tuned on the corporate’s codebase, so it understands inner patterns and libraries.
Doc Processing: A healthcare supplier makes use of Phi-3 Mini to extract structured information from medical information. The mannequin runs on-premise, HIPAA-compliant, processing hundreds of paperwork per hour on commonplace server {hardware}. Beforehand, they prevented AI solely on account of privateness constraints.
Cell Functions: Translation apps now embed 1B parameter fashions instantly within the app. Customers get immediate translations with out web connectivity. Battery life is best than cloud API calls, and translations work on flights or in distant areas.
When to not use SLMs: Open-ended analysis questions, artistic writing requiring novelty, duties needing broad information, or advanced multi-step reasoning. An SLM gained’t write a novel screenplay or remedy novel physics issues. However for well-defined, repeated duties, they’re ideally suited.
Getting Began with SLMs
In case you’re new to SLMs, begin right here.
Run a fast take a look at. Set up Ollama and run Llama 3.2 3B or Phi-3 Mini in your laptop computer. Spend a day testing it in your precise use circumstances. You’ll instantly perceive the velocity distinction and functionality boundaries.
Establish your use case. Take a look at your AI workloads. What share are predictable, repeated duties versus novel queries? If greater than 50% are predictable, you’ve a robust SLM candidate.
Nice-tune if wanted. Acquire 500 to 1,000 examples of your particular activity. Nice-tuning takes hours, not days, and the efficiency enchancment may be important. Instruments like Hugging Face’s Transformers library and platforms like Google Colab make this accessible to builders with fundamental Python expertise.
Deploy domestically or on-premise. Begin with a single GPU server or perhaps a beefy laptop computer. Monitor value, latency, and high quality. Examine in opposition to your present cloud API spend. Most groups discover ROI throughout the first month.
Scale with a hybrid strategy. When you’ve confirmed the idea, add a router that sends easy queries to your SLM and sophisticated ones to a cloud LLM. This works properly for each value and functionality.
Key Takeaways
The pattern in AI isn’t simply “greater fashions.” It’s smarter deployment. As SLM architectures enhance and quantization methods advance, the hole between small and enormous fashions narrows for specialised duties.
In 2026, profitable AI deployments aren’t measured by which mannequin you employ. They’re measured by how properly you match fashions to duties. SLMs offer you that flexibility: the flexibility to deploy succesful AI the place you want it, on {hardware} you management, at prices that scale with your enterprise.
For many manufacturing workloads, the query isn’t whether or not to make use of SLMs. It’s which duties to start out with first.
On this article, you’ll study what small language fashions are, why they matter in 2026, and tips on how to use them successfully in actual manufacturing programs.
Subjects we are going to cowl embrace:
- What defines small language fashions and the way they differ from giant language fashions.
- The price, latency, and privateness benefits driving SLM adoption.
- Sensible use circumstances and a transparent path to getting began.
Let’s get straight to it.
Introduction to Small Language Fashions: The Full Information for 2026
Picture by Writer
Introduction
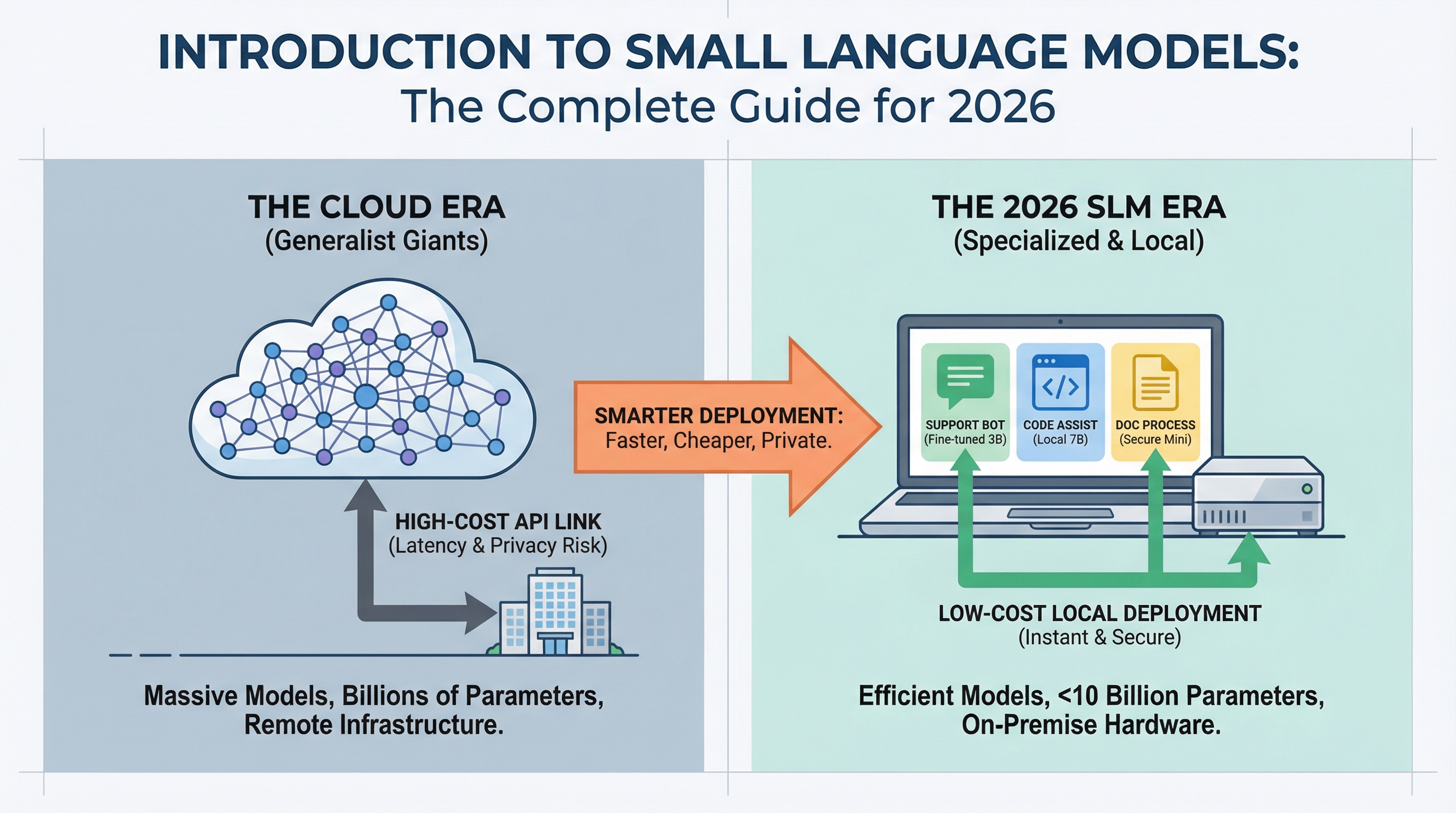
AI deployment is altering. Whereas headlines deal with ever-larger language fashions breaking new benchmarks, manufacturing groups are discovering that smaller fashions can deal with most on a regular basis duties at a fraction of the price.
In case you’ve deployed a chatbot, constructed a code assistant, or automated doc processing, you’ve in all probability paid for cloud API calls to fashions with a whole lot of billions of parameters. However most practitioners working in 2026 are discovering that for 80% of manufacturing use circumstances, a mannequin you possibly can run on a laptop computer works simply as properly and prices 95% much less. If you wish to soar straight into hands-on choices, our information to the Prime 7 Small Language Fashions You Can Run on a Laptop computer covers the very best fashions accessible right now and tips on how to get them working domestically.
Small language fashions (SLMs) make this doable. This information covers what they’re, when to make use of them, and the way they’re altering the economics of AI deployment.
What Are Small Language Fashions?
Small language fashions are language fashions with fewer than 10 billion parameters, normally starting from 1 billion to 7 billion.
Parameters are the “knobs and dials” inside a neural community. Every parameter is a numerical worth the mannequin makes use of to remodel enter textual content into predictions about what comes subsequent. Once you see “GPT-4 has over 1 trillion parameters,” which means the mannequin has 1 trillion of those adjustable values working collectively to know and generate language. Extra parameters usually imply extra capability to study patterns, however in addition they imply extra computational energy, reminiscence, and price to run.
The dimensions distinction is important. GPT-4 has over 1 trillion parameters, Claude Opus has a whole lot of billions, and even Llama 3.1 70B is taken into account “giant.” SLMs function at a very completely different scale.
However “small” doesn’t imply “easy.” Trendy SLMs like Phi-3 Mini (3.8B parameters), Llama 3.2 3B, and Mistral 7B ship efficiency that rivals fashions 10× their measurement on many duties. The actual distinction is specialization.
The place giant language fashions are skilled to be generalists with broad information spanning each subject conceivable, SLMs excel when fine-tuned for particular domains. A 3B mannequin skilled on buyer assist conversations will outperform GPT-4 in your particular assist queries whereas working on {hardware} you already personal.
You Don’t Construct Them From Scratch
Adopting an SLM doesn’t imply constructing one from the bottom up. Even “small” fashions are far too advanced for people or small groups to coach from scratch. As an alternative, you obtain a pre-trained mannequin that already understands language, then train it your particular area via fine-tuning.
It’s like hiring an worker who already speaks English and coaching them in your firm’s procedures, slightly than educating a child to talk from delivery. The mannequin arrives with normal language understanding in-built. You’re simply including specialised information.
You don’t want a group of PhD researchers or huge computing clusters. You want a developer with Python expertise, some instance information out of your area, and some hours of GPU time. The barrier to entry is far decrease than most individuals assume.
Why SLMs Matter in 2026
Three forces are driving SLM adoption: value, latency, and privateness.
Value: Cloud API pricing for big fashions runs $0.01 to $0.10 per 1,000 tokens. At scale, this provides up quick. A buyer assist system dealing with 100,000 queries per day can rack up $30,000+ month-to-month in API prices. An SLM working on a single GPU server prices the identical {hardware} whether or not it processes 10,000 or 10 million queries. The economics flip solely.
Latency: Once you name a cloud API, you’re ready for community round-trips plus inference time. SLMs working domestically reply in 50 to 200 milliseconds. For purposes like coding assistants or interactive chatbots, customers really feel this distinction instantly.
Privateness: Regulated industries (healthcare, finance, authorized) can’t ship delicate information to exterior APIs. SLMs let these organizations deploy AI whereas retaining information on-premise. No exterior API calls means no information leaves your infrastructure.
LLMs vs SLMs: Understanding the Commerce-offs
The choice between an LLM and an SLM is determined by matching functionality to necessities. The variations come all the way down to scale, deployment mannequin, and the character of the duty.
The comparability reveals a sample: LLMs are designed for breadth and unpredictability, whereas SLMs are constructed for depth and repetition. In case your activity requires dealing with any query about any subject, you want an LLM’s broad information. However in case you’re fixing the identical sort of downside hundreds of occasions, an SLM fine-tuned for that particular area can be sooner, cheaper, and infrequently extra correct.
Right here’s a concrete instance. In case you’re constructing a authorized doc analyzer, an LLM can deal with any authorized query from company regulation to worldwide treaties. However in case you’re solely processing employment contracts, a fine-tuned 7B mannequin can be sooner, cheaper, and extra correct on that particular activity.
Most groups are touchdown on a hybrid strategy: use SLMs for 80% of queries (the predictable ones), escalate to LLMs for the advanced 20%. This “router” sample combines the very best of each worlds.
How SLMs Obtain Their Edge
SLMs aren’t simply “small LLMs.” They use particular methods to ship excessive efficiency at low parameter counts.
Data Distillation trains smaller “scholar” fashions to imitate bigger “trainer” fashions. The coed learns to duplicate the trainer’s outputs with no need the identical huge structure. Microsoft’s Phi-3 sequence was distilled from a lot bigger fashions, retaining 90%+ of the aptitude at 5% of the scale.
Excessive-High quality Coaching Information issues extra for SLMs than sheer information amount. Whereas LLMs are skilled on trillions of tokens from all the web, SLMs profit from curated, high-quality datasets. Phi-3 was skilled on “textbook-quality” artificial information, fastidiously filtered to take away noise and redundancy.
Quantization compresses mannequin weights from 16-bit or 32-bit floating level to 4-bit or 8-bit integers. A 7B parameter mannequin in 16-bit precision requires 14GB of reminiscence. Quantized to 4-bit, it matches in 3.5GB (sufficiently small to run on a laptop computer). Trendy quantization methods like GGUF keep 95%+ of mannequin high quality whereas reaching 75% measurement discount.
Architectural Optimizations like sparse consideration scale back computational overhead. As an alternative of each token attending to each different token, fashions use methods like sliding-window consideration or grouped-query consideration to focus computation the place it issues most.
Manufacturing Use Instances
SLMs are already working manufacturing programs throughout industries.
Buyer Help: A serious e-commerce platform changed GPT-3.5 API calls with a fine-tuned Mistral 7B for tier-1 assist queries. They noticed a 90% value discount, 3× sooner response occasions, and equal or higher accuracy on frequent questions. Complicated queries nonetheless escalate to GPT-4, however 75% of tickets are dealt with by the SLM.
Code Help: Growth groups run Llama 3.2 3B domestically for code completion and easy refactoring. Builders get immediate recommendations with out sending proprietary code to exterior APIs. The mannequin was fine-tuned on the corporate’s codebase, so it understands inner patterns and libraries.
Doc Processing: A healthcare supplier makes use of Phi-3 Mini to extract structured information from medical information. The mannequin runs on-premise, HIPAA-compliant, processing hundreds of paperwork per hour on commonplace server {hardware}. Beforehand, they prevented AI solely on account of privateness constraints.
Cell Functions: Translation apps now embed 1B parameter fashions instantly within the app. Customers get immediate translations with out web connectivity. Battery life is best than cloud API calls, and translations work on flights or in distant areas.
When to not use SLMs: Open-ended analysis questions, artistic writing requiring novelty, duties needing broad information, or advanced multi-step reasoning. An SLM gained’t write a novel screenplay or remedy novel physics issues. However for well-defined, repeated duties, they’re ideally suited.
Getting Began with SLMs
In case you’re new to SLMs, begin right here.
Run a fast take a look at. Set up Ollama and run Llama 3.2 3B or Phi-3 Mini in your laptop computer. Spend a day testing it in your precise use circumstances. You’ll instantly perceive the velocity distinction and functionality boundaries.
Establish your use case. Take a look at your AI workloads. What share are predictable, repeated duties versus novel queries? If greater than 50% are predictable, you’ve a robust SLM candidate.
Nice-tune if wanted. Acquire 500 to 1,000 examples of your particular activity. Nice-tuning takes hours, not days, and the efficiency enchancment may be important. Instruments like Hugging Face’s Transformers library and platforms like Google Colab make this accessible to builders with fundamental Python expertise.
Deploy domestically or on-premise. Begin with a single GPU server or perhaps a beefy laptop computer. Monitor value, latency, and high quality. Examine in opposition to your present cloud API spend. Most groups discover ROI throughout the first month.
Scale with a hybrid strategy. When you’ve confirmed the idea, add a router that sends easy queries to your SLM and sophisticated ones to a cloud LLM. This works properly for each value and functionality.
Key Takeaways
The pattern in AI isn’t simply “greater fashions.” It’s smarter deployment. As SLM architectures enhance and quantization methods advance, the hole between small and enormous fashions narrows for specialised duties.
In 2026, profitable AI deployments aren’t measured by which mannequin you employ. They’re measured by how properly you match fashions to duties. SLMs offer you that flexibility: the flexibility to deploy succesful AI the place you want it, on {hardware} you management, at prices that scale with your enterprise.
For many manufacturing workloads, the query isn’t whether or not to make use of SLMs. It’s which duties to start out with first.
















{kind=link}