




Picture by Editor
# Introduction
ChatGPT, Claude, Gemini. the names. However here is a query: what if you happen to ran your individual mannequin as an alternative? It sounds formidable. It is not. You may deploy a working massive language mannequin (LLM) in underneath 10 minutes with out spending a greenback.
This text breaks it down. First, we’ll determine what you really need. Then we’ll have a look at actual prices. Lastly, we’ll deploy TinyLlama on Hugging Face without spending a dime.
Earlier than you launch your mannequin, you in all probability have numerous questions in your thoughts. As an illustration, what duties am I anticipating my mannequin to carry out?
Let’s attempt answering this query. In case you want a bot for 50 customers, you don’t want GPT-5. Or in case you are planning on doing sentiment evaluation on 1,200+ tweets a day, chances are you’ll not want a mannequin with 50 billion parameters.
Let’s first have a look at some widespread use instances and the fashions that may carry out these duties.
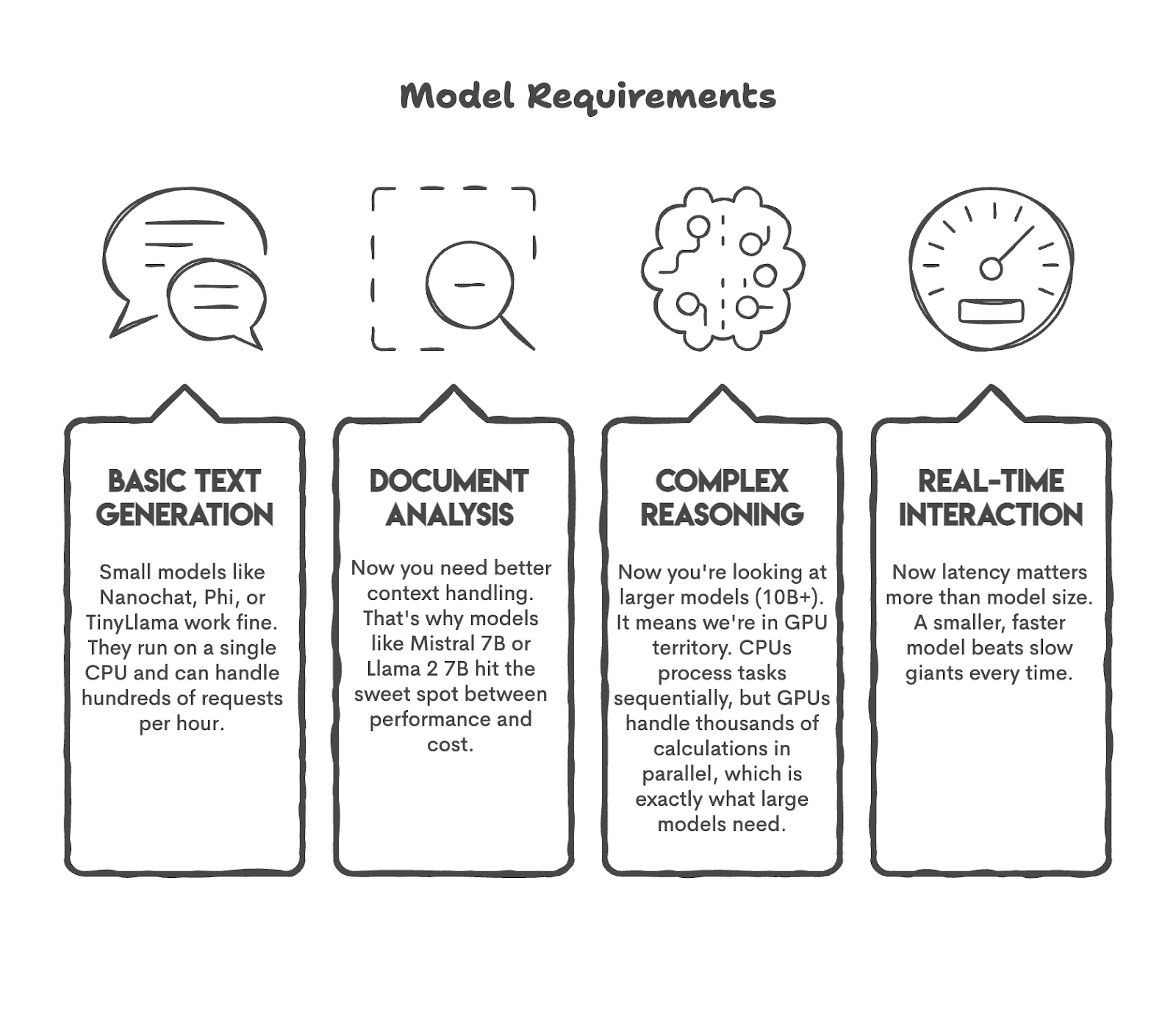
As you possibly can see, we matched the mannequin to the duty. That is what it is best to do earlier than starting.
# Breaking Down the Actual Prices of Internet hosting an LLM
Now that you realize what you want, let me present you ways a lot it prices. Internet hosting a mannequin is not only concerning the mannequin; it is usually about the place this mannequin runs, how regularly it runs, and the way many individuals work together with it. Let’s decode the precise prices.
// Compute: The Largest Value You’ll Face
In case you run a Central Processing Unit (CPU) 24/7 on Amazon Net Providers (AWS) EC2, that might price round $36 per thirty days. Nevertheless, if you happen to run a Graphics Processing Unit (GPU) occasion, it could price round $380 per thirty days — greater than 10x the associated fee. So watch out about calculating the price of your massive language mannequin, as a result of that is the principle expense.
(Calculations are approximate; to see the true worth, please verify right here: AWS EC2 Pricing).
// Storage: Small Value Except Your Mannequin Is Large
Let’s roughly calculate the disk area. A 7B (7 billion parameter) mannequin takes round 14 Gigabytes (GB). Cloud storage bills are round $0.023 per GB per thirty days. So the distinction between a 1GB mannequin and a 14GB mannequin is simply roughly $0.30 per thirty days. Storage prices will be negligible if you happen to do not plan to host a 300B parameter mannequin.
// Bandwidth: Low cost Till You Scale Up
Bandwidth is vital when your information strikes, and when others use your mannequin, your information strikes. AWS costs $0.09 per GB after the primary GB, so you’re looking at pennies. However if you happen to scale to thousands and thousands of requests, it is best to calculate this intently too.
(Calculations are approximate; to see the true worth, please verify right here: AWS Information Switch Pricing).
// Free Internet hosting Choices You Can Use As we speak
Hugging Face Areas permits you to host small fashions without spending a dime with CPU. Render and Railway supply free tiers that work for low-traffic demos. In case you’re experimenting or constructing a proof-of-concept, you may get fairly far with out spending a cent.
# Decide a Mannequin You Can Truly Run
Now we all know the prices, however which mannequin do you have to run? Every mannequin has its benefits and drawbacks, after all. As an illustration, if you happen to obtain a 100-billion-parameter mannequin to your laptop computer, I assure it will not work except you have got a top-notch, particularly constructed workstation.
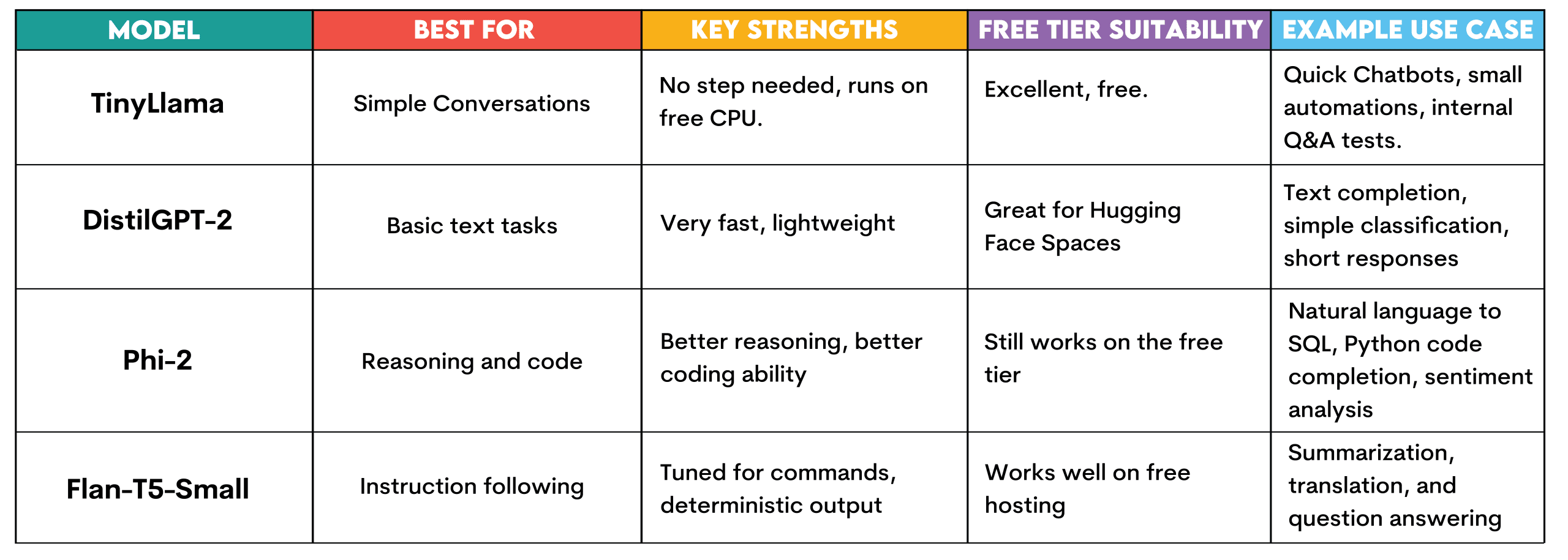
Let’s see the totally different fashions out there on Hugging Face so you possibly can run them without spending a dime, as we’re about to do within the subsequent part.
TinyLlama: This mannequin requires no setup and runs utilizing the free CPU tier on Hugging Face. It’s designed for easy conversational duties, answering easy questions, and textual content technology.
It may be used to construct rapidly and take a look at chatbots, run fast automation experiments, or create inner question-answering techniques for testing earlier than increasing into an infrastructure funding.
DistilGPT-2: It is also swift and light-weight. This makes it good for Hugging Face Areas. Okay for finishing textual content, quite simple classification duties, or quick responses. Appropriate for understanding how LLMs operate with out useful resource constraints.
Phi-2: A small mannequin developed by Microsoft that proves fairly efficient. It nonetheless runs on the free tier from Hugging Face however provides improved reasoning and code technology. Make use of it for pure language-to-SQL question technology, easy Python code completion, or buyer evaluation sentiment evaluation.
Flan-T5-Small: That is the instruction-tuning mannequin from Google. Created to answer instructions and supply solutions. Helpful for technology once you need deterministic outputs on free internet hosting, corresponding to summarization, translation, or question-answering.
# Deploy TinyLlama in 5 Minutes
Let’s construct and deploy TinyLlama by utilizing Hugging Face Areas without spending a dime. No bank card, no AWS account, no Docker complications. Only a working chatbot you possibly can share with a hyperlink.
// Step 1: Go to Hugging Face Areas
Head to huggingface.co/areas and click on “New Area”, like within the screenshot under.
Identify the area no matter you need and add a brief description.
You may go away the opposite settings as they’re.
Click on “Create Area”.
// Step 2: Write the app.py
Now, click on on “create the app.py” from the display screen under.
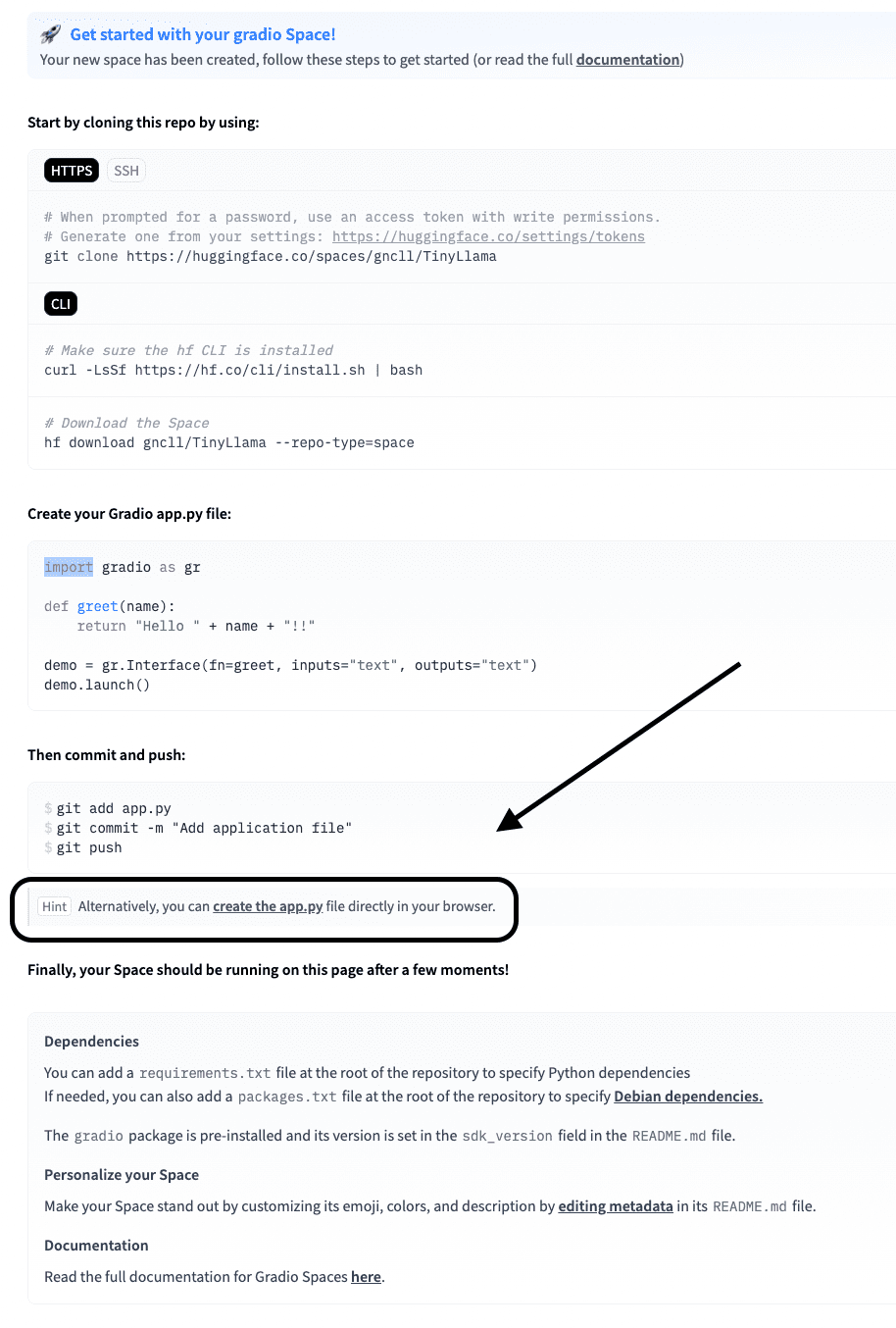
Paste the code under inside this app.py.
This code hundreds TinyLlama (with the construct recordsdata out there at Hugging Face), wraps it in a chat operate, and makes use of Gradio to create an internet interface. The chat() technique codecs your message appropriately, generates a response (as much as a most of 100 tokens), and returns solely the reply from the mannequin (it doesn’t embrace repeats) to the query you requested.
Right here is the web page the place you possibly can learn to write code for any Hugging Face mannequin.
Let’s have a look at the code.
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
mannequin = AutoModelForCausalLM.from_pretrained(model_name)
def chat(message, historical past):
# Put together the immediate in Chat format
immediate = f"<|person|>n{message}n<|assistant|>n"
inputs = tokenizer(immediate, return_tensors="pt")
outputs = mannequin.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0][inputs['input_ids'].form[1]:], skip_special_tokens=True)
return response
demo = gr.ChatInterface(chat)
demo.launch()
After pasting the code, click on on “Commit the brand new file to most important.” Please verify the screenshot under for instance.
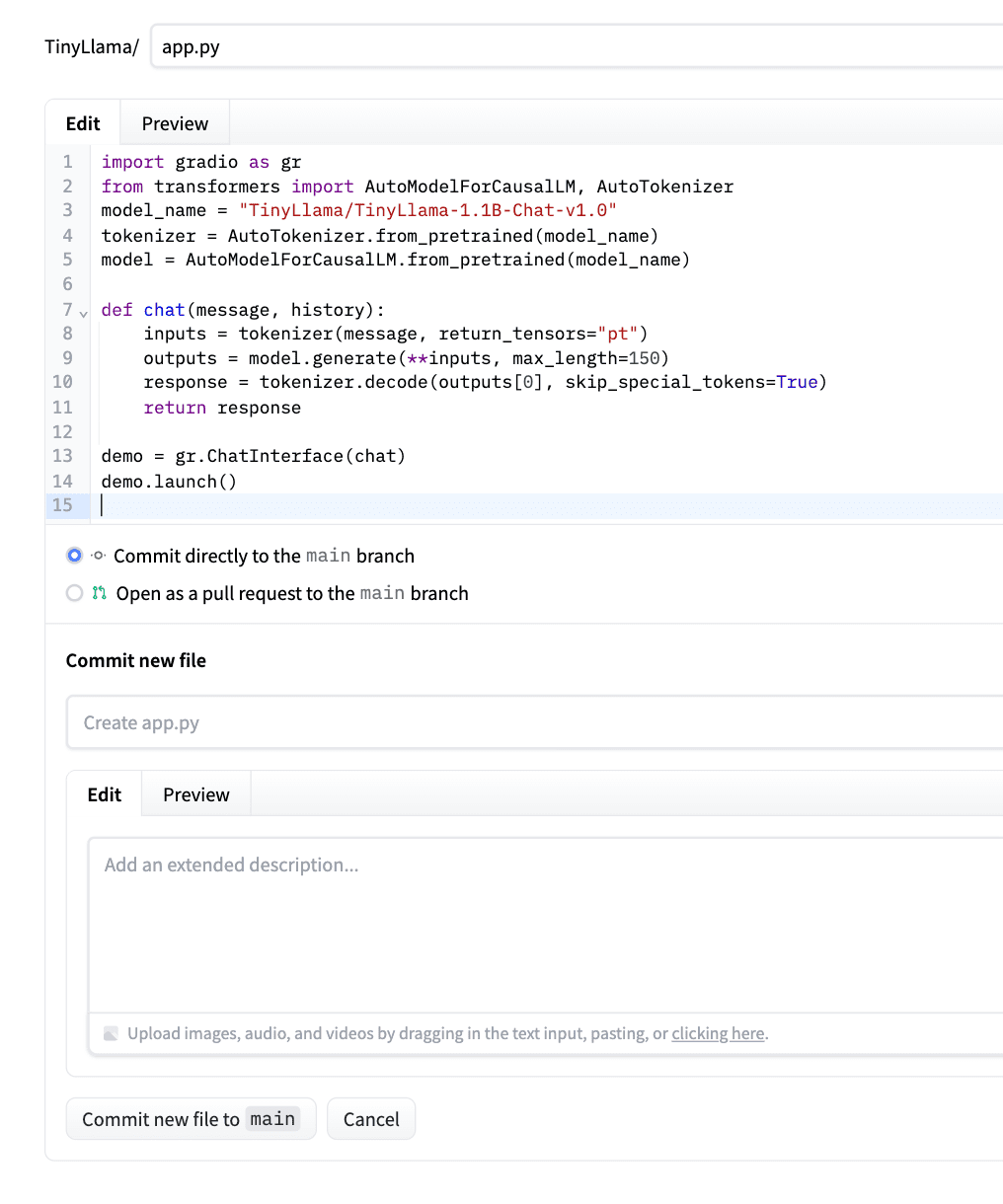
Hugging Face will robotically detect it, set up dependencies, and deploy your app.

Throughout that point, create a necessities.txt file otherwise you’ll get an error like this.

// Step 3: Create the Necessities.txt
Click on on “Information” within the higher proper nook of the display screen.

Right here, click on on “Create a brand new file,” like within the screenshot under.

Identify the file “necessities.txt” and add 3 Python libraries, as proven within the following screenshot (transformers, torch, gradio).
Transformers right here hundreds the mannequin and offers with the tokenization. Torch runs the mannequin because it offers the neural community engine. Gradio creates a easy internet interface so customers can chat with the mannequin.

// Step 4: Run and Check Your Deployed Mannequin
If you see the inexperienced gentle “Working”, which means you’re executed.

Now let’s take a look at it.
You may take a look at it by first clicking on the app from right here.

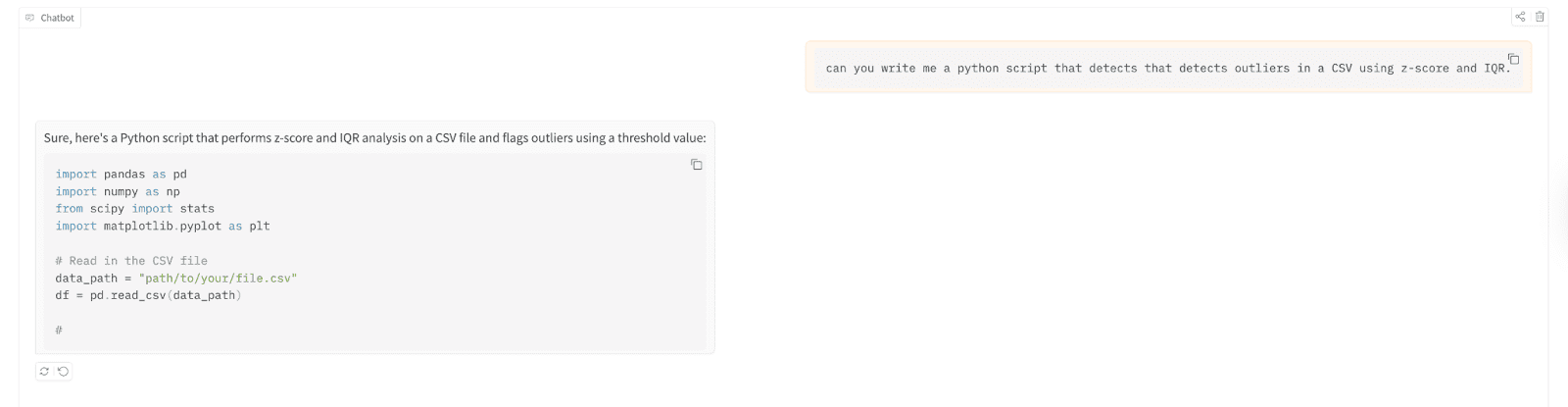
Let’s use it to write down a Python script that detects outliers in a comma-separated values (CSV) file utilizing z-score and Interquartile Vary (IQR).
Listed here are the take a look at outcomes;
// Understanding the Deployment You Simply Constructed
The result’s that you’re now in a position to spin up a 1B+ parameter language mannequin and by no means have to the touch a terminal, arrange a server, or spend a greenback. Hugging Face takes care of internet hosting, the compute, and the scaling (to a level). A paid tier is accessible for extra site visitors. However for the needs of experimentation, that is splendid.
The easiest way to be taught? Deploy first, optimize later.
# The place to Go Subsequent: Enhancing and Increasing Your Mannequin
Now you have got a working chatbot. However TinyLlama is only the start. In case you want higher responses, attempt upgrading to Phi-2 or Mistral 7B utilizing the identical course of. Simply change the mannequin title in app.py and add a bit extra compute energy.
For quicker responses, look into quantization. You can even join your mannequin to a database, add reminiscence to conversations, or fine-tune it by yourself information, so the one limitation is your creativeness.
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from high corporations. Nate writes on the most recent tendencies within the profession market, offers interview recommendation, shares information science tasks, and covers every part SQL.
















{kind=link}