


to remodel a small text-only language mannequin and reward it the ability of imaginative and prescient. This text is to summarize all my learnings, and take a deeper take a look at the community architectures behind fashionable Imaginative and prescient Language Fashions.
The code is open-source, you possibly can take a look at the GitHub hyperlink on the finish of the article. There may be additionally a 30-minute companion YouTube video that explains the entire article in a visually wealthy format.
Additionally, until in any other case talked about, all photos on this article are produced by the creator.
Wait, are you actually going to be “coaching from scratch”?
Sure… I imply no… it’s a bit nuanced.
Analysis labs in 2026 don’t practice multimodal fashions from “scratch” anymore. It is just too costly to show a mannequin imaginative and prescient and (textual) language on the identical time! It requires extra information, compute, time, and cash. Additionally, it typically results in poorer outcomes.
As an alternative, labs take current pretrained text-only language fashions, and finetune it to provide “imaginative and prescient capabilities”. In principle (and observe), that is far more compute-efficient.

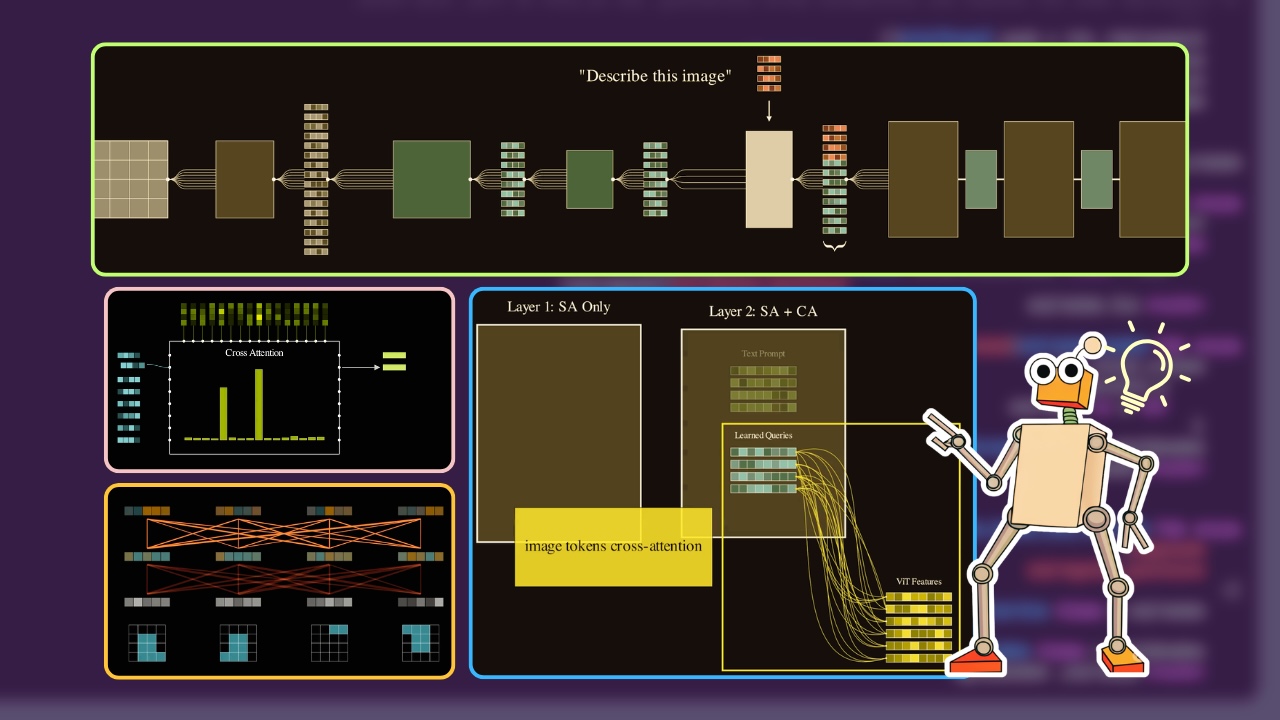
The usual structure
Though it’s much less data-intensive, finetuning text-only LMs to abruptly begin seeing photos would certainly open its personal can of worms.
- how can we embed the picture, i.e. convert it into numerical representations {that a} neural community can perceive?
- how can we tune the picture embeddings to be suitable with textual content?
- how can we modify the weights of the textual content mannequin in order that it retains it’s earlier world information, but in addition generate textual content from picture embeddings?

These modules are:
- The Picture Spine: A mannequin that converts uncooked photos into embeddings.
- The Adapter Layer: These are fashions that convert the picture embeddings right into a “text-compatible” embedding. That is the principle difficult half – what architectures to make use of, what loss features, and so on.
- The Language Layer: The language mannequin we are going to practice to enter the tailored embeddings and generate textual content from it.
Let’s talk about them one after the other.
1. The Picture Spine
The objective of your picture spine is easy:
Enter: A uncooked 2D pixel map/picture.
Output: A sequence of vector embeddings representing the picture
Basically, we simply use an off-the-shelf picture mannequin that has been pretrained with huge corpus of photos, typically on self-supervised duties.
You should use a Convolutional Neural Community (like a ResNet) to make use of as a picture spine. However fashionable state-of-the-art VLMs have nearly fully shifted to ViTs as a result of they scale higher with information and are extra versatile for multimodal fusion.

Do I practice the picture spine or maintain it frozen?
In most VLM analysis, there’s a clear pattern towards retaining backbones static (frozen) to avoid wasting prices. Additionally, vision-language coaching typically wants paired image-text datasets. Since these datasets are all the time a lot smaller than the VIT’s pretraining dataset, finetuning the spine typically results in overfitting and degraded efficiency.
By retaining these weights frozen, we’re principally transferring the possession of vision-language studying to latter components of the community (i.e. the adapter layer and the textual content spine).
In my experiments, I used the ViT-Base mannequin. This mannequin takes the picture enter, splits it into patches of 16×16 photos and applies self-attention on them to generate an embedding sequence of 197 vectors. Every vector is 768 dimesnions lengthy (the embedding dimension of the VIT).
2. The Adapter Layer
That is the place we’re going to spend nearly all of our time. We now have transformed photos into embeddings already, however these embeddings are fully text-unaware.
Imaginative and prescient Transformers are pre-trained purely on picture pixels. Not on their captions, or any native textual options. The position of the adapter is to floor the pixel-based-image-embeddings right into a (typically shorter sequence of) text-based-image-embeddings.
There are lots of methods to do that, like utilizing CLIP fashions, however we’re going to take a look at one of many extra common approaches — the Question Former of the Q-Former.
Q-Former
Alright — so what’s a Q-Former? A Q-Former or the Question-Former was launched within the BLIP-2 paper.

How do I practice a Q-Former?
Commonplace Q-Formers may be educated utilizing any multimodal image-text pair dataset. For instance, you need to use the Conceptual Captions dataset, which is an enormous corpus of photos and their corresponding captions. In my venture, I took simply 50,000 pairs to coach the Q-Former.
You possibly can practice a Q-Former from scratch, however the BLIP-2 suggestion is to make use of an pretrained BERT mannequin. In order that’s what we are going to do.
At a excessive degree, right here is our primary gameplan:
- Prepare a multi-modal joint embedding area. An area the place textual content and pictures “know” one another.
- Mainly, we are going to enter pairs of picture and captions — and embed each of them in the identical joint area.
- Photographs and incompatible captions might be mapped in separate locations on this new embedding area, and suitable captions might be mapped shut to one another.


Establishing cross-attention layers
There’s an issue — BERT fashions are purely textual content fashions. They do not know what a picture is.
So, our goal is to first introduce new cross-attention layers to marry the imaginative and prescient embeddings popping out of the VIT and the textual content embeddings from BERT. Let’s break down step-by-step how we convert BERT right into a Q-Former:
- Pattern a picture and textual content pair from the dataset
- Cross the picture by means of the frozen VIT mannequin to transform the picture into picture embeddings, formed [197, 768]
- Initialize “learnable question embeddings”. These are (say 32) vector embeddings that we are going to use to transform the picture embedding sequence right into a text-grounded token embedding sequence. Discover that 32 is way decrease than the unique VIT embedding sequence size (197).
- We enter the textual content caption embeddings and the question embeddings into the primary BERT layer. The layer applies self-attention on these inputs.
For now, let’s assume that the question tokens solely attend amongst themselves and the textual content tokens amongst themselves (i.e. the question tokens and the textual content tokens don’t see one another).
- Within the 2nd layer of the BERT, one thing INTERESTING occurs. The 2 units of embeddings undergo one other self-attention layer like earlier than. However this time, we additionally use a cross-attention layer to contextualize the question embeddings with the ViT picture embeddings we calculated earlier.
After all, regular BERT doesn’t have any cross-attention layers, so we introduce these multi-headed cross-attention layers ourselves.
- Similar to this, we alternate between a pure self-attention layer (the place queries and textual content independently self-attend amongst themselves) adopted by a cross-attention layer (the place the question embeddings attend to the frozen VIT embeddings).
- Within the ultimate layer, we select a joint embedding coaching loss, like ITC (Picture Textual content Contrastive Loss) or ITM (Picture Textual content Matching Loss) or ITG (Picture Textual content Era Loss and so on). Extra on this later.
What does cross-attention do?
It contextualizes the picture content material with the question embeddings. You possibly can think about every question is making an attempt to match a selected embedding sample in opposition to the 197 VIT embeddings.
For instance, if a question has a excessive match with a single picture vector, it can seize that characteristic very prominently. If the question matches with a mixture of vectors, it will likely be a mean of these embeddings, and so forth.
Keep in mind we educated 32 of those question embeddings, so you’re permitting the Q-Former to study a number of completely different co-activations throughout the picture embeddings. Because of the nature of coaching, these coactivations are inspired to maximise alignment between picture and textual content.
As we practice the Q-Former, each the preliminary question embeddings and the cross-attention weights might be optimized so we are able to extract related options from the VIT picture tokens.
The question former embeddings should not making an attempt to seize each element of those 197 embeddings — as a substitute they’re making an attempt to discover ways to mix them right into a compact 32 token sequence.
Observe that after the Q-Former is educated, we gained’t really use the textual content a part of the Q-Former for something. We’ll merely move the query-embeddings by means of the Q-former and alternatively run self-attention and cross-attention solely on them.
Loss features for coaching Q-Formers
How the Q-Former mannequin is educated is definitely carefully associated to how we attend between question and textual content tokens all through the layers.
- Picture-Textual content-Contrastive Loss (our setup)
For this activity, we use a unimodal self-attention masks. Question tokens attend amongst one another, textual content token amongst one another.The loss operate may be any commonplace CLIP-like contrastive loss operate. We’ll align the picture and textual content in the identical embedding area. Mainly, we take the output of the queries and the output of the textual content encoder and compute their similarity. If a picture and a caption belong collectively, we would like their vectors to be as shut as attainable.
This forces the queries to extract a “world” visible illustration that matches the final theme of the textual content with out really wanting on the phrases but.
- Picture-Textual content Matching Loss (ITM)
This makes use of a bi-directional self-attention masks. Right here, each question token is allowed to see each textual content token, and each textual content token can see each question!For the loss fucntion, we use a binary classification activity the place the mannequin has to foretell: “Is that this picture and this textual content a match—Sure or No?”. Binary cross-entropy loss.
As a result of the modalities are absolutely blended, the mannequin can do fine-grained comparisons. The queries can take a look at particular objects within the picture (by way of the cross-attention) and confirm in the event that they correspond to particular phrases within the textual content. That is rather more detailed than the contrastive loss and ensures the 32 tokens are capturing localized particulars.
- Picture-Textual content Era Loss (ITG)
Lastly, we’ve got the generative activity. For this, we use a multimodal causal masks. The queries can nonetheless see one another, however the textual content tokens are actually handled like a sequence. Every textual content token can see all 32 question tokens – which act as a visible prefix. However they’ll solely see the textual content tokens that got here earlier than it.For the loss operate, we simply practice the mannequin to foretell the following token within the caption. By forcing the mannequin to actually “write” the outline primarily based on the queries, we make sure that these 32 tokens comprise each little bit of visible info vital for a language mannequin to grasp the scene.
For my venture, I simply used the best — ITC. For a small dataset like I used to be utilizing, this was the simplest approach! BLIP-2 recommends to make use of a combination of all these coaching strategies. The github repo shared on the finish of the article gives the recipe to make use of any of the above consideration schemes.

Within the subsequent part, we are going to do the ultimate step — coaching the VLM!
3. The Language Layer
Now comes the ultimate step. We’ll use the VIT and the Q-Former to make a language mannequin right into a imaginative and prescient mannequin. I picked one of many smallest instruction-tuned language fashions — the SmolLM2-135M. Fortunately, this half isn’t as difficult because the Q-Former coaching.
We now have the picture embeddings (coming from the VIT and the Q-Former), and we’ve got the textual content tokens (coming from the SmolLM tokenizer). Let’s see some particulars.

- We pattern a picture and a caption from our dataset
- We randomly decide from an inventory of straightforward system prompts, just like: “You’re a useful assistant. Reply honestly to the consumer.”
We additionally decide the consumer question from an inventory of prompts, for instance: “What do you see on this picture?“
We tokenize the output captions sampled from the dataset as nicely.
These 3 issues kind the textual content tokens. We tokenize all of them utilizing the SmolLM2 tokenizer, however we aren’t going to insert it into the LLM simply but — we should course of the picture first.
- We move the picture by means of the frozen VIT, then by means of the Q-Former (once more, notice that the textual content captions should not handed into the Q-Former, solely the picture pipeline is executed)
- We introduce a small MLP layer that converts the Q-Former output into new embeddings which can be of the identical form because the LLM’s anticipated embedding dimension. As we practice, this MLP layer will map the Q-Former embedding into the LLM embedding area.
- Now that we’ve got the textual content tokens sequence and the brand new picture embeddings (VIT -> Q-Former -> MLP). We’ll move the textual content tokens by means of the LLM’s native embedding layer. We sandwich the textual content and picture embeddings within the following sequence:
- Why that particular sequence? Since autoregressive LLMs use causal masking, we are going to basically be coaching fashions to generate the output (caption) sequence given your complete prefix (system immediate, consumer immediate, and the picture embeddings).
- We add LoRA adapters (Low-Rank Adaptation Matrices) as a substitute of coaching your complete LLM from scratch. By wrapping our LLM with LoRA, we freeze the unique thousands and thousands of parameters and solely practice tiny, low-rank matrices injected into the eye layers. This makes the mannequin trainable on client {hardware} whereas retaining all that pre-existing intelligence intact.
- And that’s it! We move these stitched embeddings and labels into the LLM. The mannequin attends to the textual content instruction and the visible tokens concurrently, and due to LoRA, it learns tips on how to replace its inside wiring to grasp this new visible language. Solely the Q-Former layers, the MLP layer, and the LORA adapters are educated. All the things else is stored frozen.

After coaching this for just some hours on a small subset of knowledge, the educated VLM can now see the pictures and generate textual content about it. Machine Studying is so stunning when it really works.
In abstract
Yow will discover the complete github repository right here:
https://github.com/avbiswas/vlm
And watch the youtube video right here:
Let’s summarize all of the modules in Imaginative and prescient Language pipelines.
- A imaginative and prescient spine (just like the VIT) that takes picture enter and converts it into embeddings
- An adapter layer (just like the Q-Former) that grounds the picture with textual content
- An LLM that we practice to consolidate the textual content and picture embeddings to study the language of imaginative and prescient
My Patreon:
https://www.patreon.com/NeuralBreakdownwithAVB
My YouTube channel:
https://www.youtube.com/@avb_fj
Comply with me on Twitter:
https://x.com/neural_avb
I’m constructing Paper Breakdown, a spot to review analysis papers
https://paperbreakdown.com
Learn my articles:
https://towardsdatascience.com/creator/neural-avb/
















{kind=link}