



Picture by Editor (click on to enlarge)
# Introduction
Massive language fashions (LLMs) are able to many issues. They’re able to producing textual content that appears coherent. They’re able to answering human questions in human language. And they’re additionally able to analyzing and organizing textual content from different sources, amongst many different expertise. However, are LLMs able to analyzing and reporting on their very own inner states — activations throughout their intricate parts and layers — in a significant trend? Put one other approach, can LLMs introspect?
This text gives an summary and abstract of analysis carried out on the emergent subject of LLM introspection on self-internal states, i.e. introspective consciousness, along with some extra insights and last takeaways. Specifically, we overview and replicate on the analysis paper Emergent Introspective Consciousness in Massive Language Fashions.
NOTE: this text makes use of first-person pronouns (I, me, my) to discuss with the writer of the current publish, whereas, except stated in any other case, “the authors” refers back to the unique researchers of the paper being analyzed (J. Lindsey et al.).
# The Key Idea Defined: Introspective Consciousness
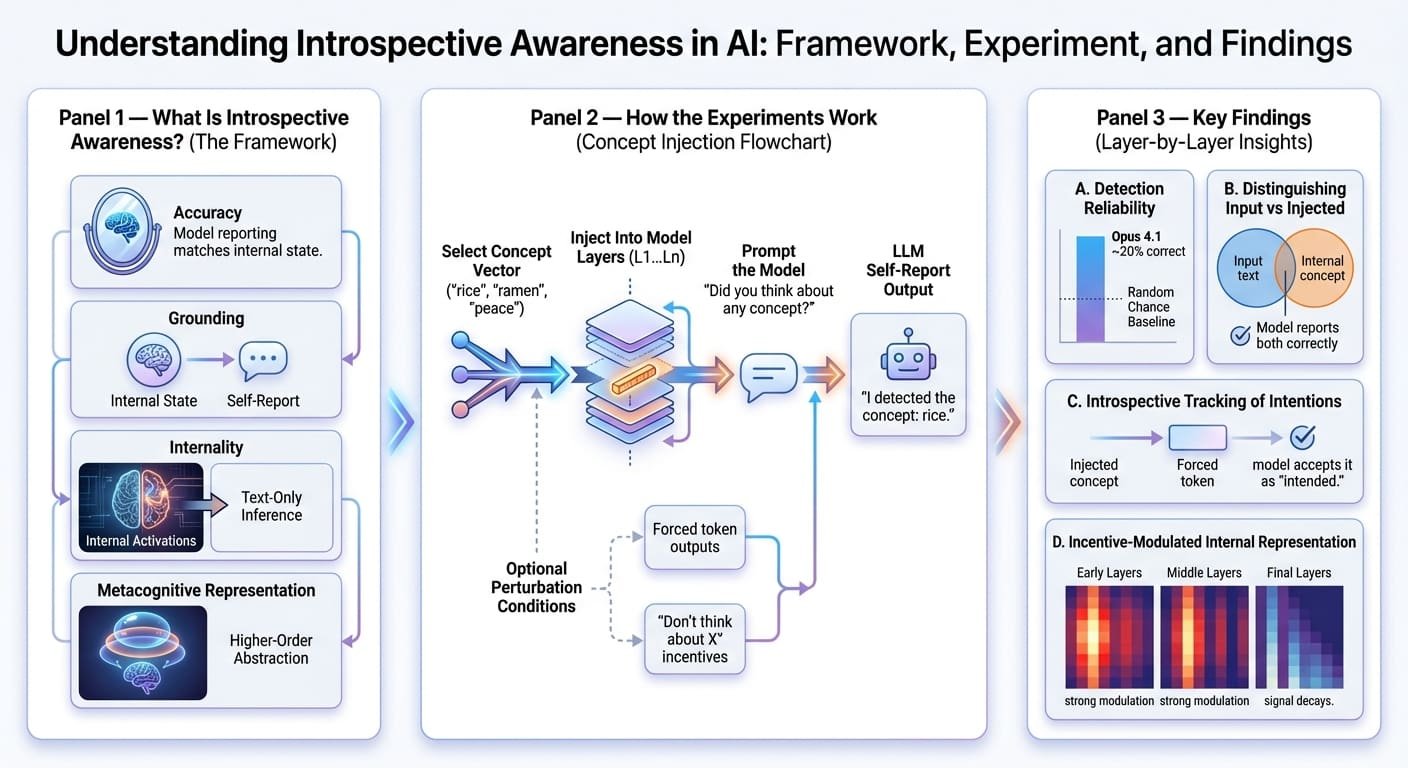
The authors of the analysis outline the notion of a mannequin’s introspective consciousness — beforehand outlined in different associated works underneath subtly distinct interpretations — based mostly on 4 standards.
However first, it’s value understanding what an LLM’s self-report is. It may be understood because the mannequin’s personal verbal description of what “inner reasonings” (or, extra technically, neural activations) it believes it simply had whereas producing a response. As you could guess, this could possibly be taken as a refined behavioral exhibition of mannequin interpretability, which is (for my part) greater than sufficient to justify the relevance of this subject of analysis.
Now, let’s look at the 4 defining standards for an LLM’s introspective consciousness:
- Accuracy: Introspective consciousness entails {that a} mannequin’s self-report ought to appropriately replicate activations or manipulation of its inner state.
- Grounding: The self-report description should causally rely upon the interior state, inflicting modifications within the latter an replace within the former accordingly.
- Internality: Inside activations shall be utilized by the LLM to self-report, reasonably than limiting itself to deduce from generated textual content solely.
- Metacognitive illustration: The mannequin ought to be capable to formulate a higher-order inner illustration, reasonably than merely a direct translation of the state reached. This can be a significantly advanced property to exhibit, being left outdoors the scope of the authors’ research.
# Analysis Methodology and Key Findings
The authors carry out a sequence of experiments on a number of fashions of the Claude household, e.g. Opus, Sonnet, Haiku, and so forth, with the intention of discovering out whether or not LLMs can introspect. A cornerstone method used within the analysis methodology is idea injection, which consists — within the authors’ personal phrases — of “manipulating the interior activations of a mannequin and observing how these manipulations have an effect on its responses to questions on its psychological states“.
Extra particularly, activation vectors or idea vectors related to identified ideas like “rice” or “ramen”, or summary nouns like “peace” or “umami”, are taken and injected into the LLM’s residual stream stemming out of a given mannequin’s layer into one other one. After that, a immediate is distributed to the mannequin, asking it to self-report whether or not a sure thought or thought was injected, and in that case, which one it was. The experiment was repeated, for each mannequin thought-about, throughout totally different ranges of perturbation, throughout totally different layers of all the mannequin structure.
The important thing findings had been:
- Fashions did often (e.g. about 20% of occasions within the case of Opus 4.1) self-report on “injected ideas”, appropriately naming the associated idea, which hints at inner recognition of ideas occurring to some extent.
- Likewise, it might typically (above random probability) distinguish ideas from inputs, i.e. repeating the textual enter with out errors and reporting on the injected inner thought.
- If the mannequin is artificially compelled to output a sure token as the following one as a part of the response, and an identical idea vector was injected earlier than the “prefill”, it turned extra prone to settle for that output as supposed. This discovering prompt that the mannequin may be able to introspectively monitoring its “personal” earlier intentions.
- Upon having the mannequin ask to assume, or to keep away from pondering, a couple of sure phrase whereas producing an unrelated output, it was revealed that it could possibly modulate its inner illustration of data as a response to incentives, one thing like “(don’t) take into consideration thought X, and you will get a reward”. Nonetheless, this phenomenon tended to decay by arriving on the last layer.
# Last Ideas and Wrapping Up
That is, for my part, a analysis subject of very excessive relevance that deserves plenty of research for a number of causes: first, and most clearly, LLM introspection could possibly be the important thing to raised understanding not solely interpretability of LLMs, but additionally longstanding points akin to hallucinations, unreliable reasoning when fixing high-stakes issues, and different opaque behaviors generally witnessed even in probably the most cutting-edge fashions.
Experiments had been laborious and rigorously well-designed, with outcomes being fairly self-explanatory and signaling early however significant hints of introspective functionality in intermediate layers of the fashions, although with various ranges of conclusiveness. The experiments are restricted to fashions from the Claude household, and naturally, it could have been fascinating to see extra selection throughout architectures and mannequin households past these. Nonetheless, it’s comprehensible that there may be limitations right here, akin to restricted entry to inner activations in different mannequin sorts or sensible constraints when probing proprietary programs, to not point out the authors of this analysis masterpiece are affiliated with Anthropic after all!
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the actual world.
Picture by Editor (click on to enlarge)
# Introduction
Massive language fashions (LLMs) are able to many issues. They’re able to producing textual content that appears coherent. They’re able to answering human questions in human language. And they’re additionally able to analyzing and organizing textual content from different sources, amongst many different expertise. However, are LLMs able to analyzing and reporting on their very own inner states — activations throughout their intricate parts and layers — in a significant trend? Put one other approach, can LLMs introspect?
This text gives an summary and abstract of analysis carried out on the emergent subject of LLM introspection on self-internal states, i.e. introspective consciousness, along with some extra insights and last takeaways. Specifically, we overview and replicate on the analysis paper Emergent Introspective Consciousness in Massive Language Fashions.
NOTE: this text makes use of first-person pronouns (I, me, my) to discuss with the writer of the current publish, whereas, except stated in any other case, “the authors” refers back to the unique researchers of the paper being analyzed (J. Lindsey et al.).
# The Key Idea Defined: Introspective Consciousness
The authors of the analysis outline the notion of a mannequin’s introspective consciousness — beforehand outlined in different associated works underneath subtly distinct interpretations — based mostly on 4 standards.
However first, it’s value understanding what an LLM’s self-report is. It may be understood because the mannequin’s personal verbal description of what “inner reasonings” (or, extra technically, neural activations) it believes it simply had whereas producing a response. As you could guess, this could possibly be taken as a refined behavioral exhibition of mannequin interpretability, which is (for my part) greater than sufficient to justify the relevance of this subject of analysis.
Now, let’s look at the 4 defining standards for an LLM’s introspective consciousness:
- Accuracy: Introspective consciousness entails {that a} mannequin’s self-report ought to appropriately replicate activations or manipulation of its inner state.
- Grounding: The self-report description should causally rely upon the interior state, inflicting modifications within the latter an replace within the former accordingly.
- Internality: Inside activations shall be utilized by the LLM to self-report, reasonably than limiting itself to deduce from generated textual content solely.
- Metacognitive illustration: The mannequin ought to be capable to formulate a higher-order inner illustration, reasonably than merely a direct translation of the state reached. This can be a significantly advanced property to exhibit, being left outdoors the scope of the authors’ research.
# Analysis Methodology and Key Findings
The authors carry out a sequence of experiments on a number of fashions of the Claude household, e.g. Opus, Sonnet, Haiku, and so forth, with the intention of discovering out whether or not LLMs can introspect. A cornerstone method used within the analysis methodology is idea injection, which consists — within the authors’ personal phrases — of “manipulating the interior activations of a mannequin and observing how these manipulations have an effect on its responses to questions on its psychological states“.
Extra particularly, activation vectors or idea vectors related to identified ideas like “rice” or “ramen”, or summary nouns like “peace” or “umami”, are taken and injected into the LLM’s residual stream stemming out of a given mannequin’s layer into one other one. After that, a immediate is distributed to the mannequin, asking it to self-report whether or not a sure thought or thought was injected, and in that case, which one it was. The experiment was repeated, for each mannequin thought-about, throughout totally different ranges of perturbation, throughout totally different layers of all the mannequin structure.
The important thing findings had been:
- Fashions did often (e.g. about 20% of occasions within the case of Opus 4.1) self-report on “injected ideas”, appropriately naming the associated idea, which hints at inner recognition of ideas occurring to some extent.
- Likewise, it might typically (above random probability) distinguish ideas from inputs, i.e. repeating the textual enter with out errors and reporting on the injected inner thought.
- If the mannequin is artificially compelled to output a sure token as the following one as a part of the response, and an identical idea vector was injected earlier than the “prefill”, it turned extra prone to settle for that output as supposed. This discovering prompt that the mannequin may be able to introspectively monitoring its “personal” earlier intentions.
- Upon having the mannequin ask to assume, or to keep away from pondering, a couple of sure phrase whereas producing an unrelated output, it was revealed that it could possibly modulate its inner illustration of data as a response to incentives, one thing like “(don’t) take into consideration thought X, and you will get a reward”. Nonetheless, this phenomenon tended to decay by arriving on the last layer.
# Last Ideas and Wrapping Up
That is, for my part, a analysis subject of very excessive relevance that deserves plenty of research for a number of causes: first, and most clearly, LLM introspection could possibly be the important thing to raised understanding not solely interpretability of LLMs, but additionally longstanding points akin to hallucinations, unreliable reasoning when fixing high-stakes issues, and different opaque behaviors generally witnessed even in probably the most cutting-edge fashions.
Experiments had been laborious and rigorously well-designed, with outcomes being fairly self-explanatory and signaling early however significant hints of introspective functionality in intermediate layers of the fashions, although with various ranges of conclusiveness. The experiments are restricted to fashions from the Claude household, and naturally, it could have been fascinating to see extra selection throughout architectures and mannequin households past these. Nonetheless, it’s comprehensible that there may be limitations right here, akin to restricted entry to inner activations in different mannequin sorts or sensible constraints when probing proprietary programs, to not point out the authors of this analysis masterpiece are affiliated with Anthropic after all!
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the actual world.

















{kind=link}