


has developed considerably for the reason that early days of Google Translate in 2007. Nonetheless, NMT programs nonetheless hallucinate like some other mannequin — particularly relating to low-resource domains or when translating between uncommon language pairs.
When Google Translate offers a outcome, you see solely the output textual content, not the likelihood distributions or uncertainty metrics for every phrase or sentence. Even for those who don’t want this data, data of the place the mannequin is assured and the place it isn’t might be actually beneficial for inside functions. As an example, easy components might be fed to a quick and low-cost mannequin, whereas extra sources might be allotted for tough ones.
However how can we assess and, most significantly, “calibrate” this uncertainty? The very first thing that involves thoughts is to guage the distribution of output possibilities for every token, for instance, by calculating its entropy. That is computationally easy, common throughout mannequin architectures, and, as might be seen beneath, truly correlates with instances the place the NMT mannequin is unsure.
Nonetheless, the restrictions of this strategy are apparent:
- First, the mannequin could also be selecting between a number of synonyms and, from the token choice perspective, be unsure.
- Second, and extra importantly, that is only a black-box technique that explains nothing concerning the nature of the uncertainty. Maybe the mannequin actually hasn’t seen something comparable throughout coaching. Or maybe it merely hallucinated a non-existent phrase or a grammatical building.
Current approaches tackle this drawback moderately effectively, however all have their nuances:
- Semantic Entropy [1] clusters mannequin outputs by semantic that means, however requires producing 5–10 outputs for a single enter, which is computationally costly (and admittedly, after I tried to breed this on my labelled dataset, the noticed semantic similarity of phrases in these clusters was questionable).
- Metrics like xCOMET [2] obtain SOTA-level QE on the token degree, however require fine-tuning 3.5 billion parameters of an XLM-R mannequin on costly quality-annotated knowledge and, except for that, perform as a black field.
- Mannequin introspection [3] by means of saliency evaluation seems fascinating but in addition has interpretation points.
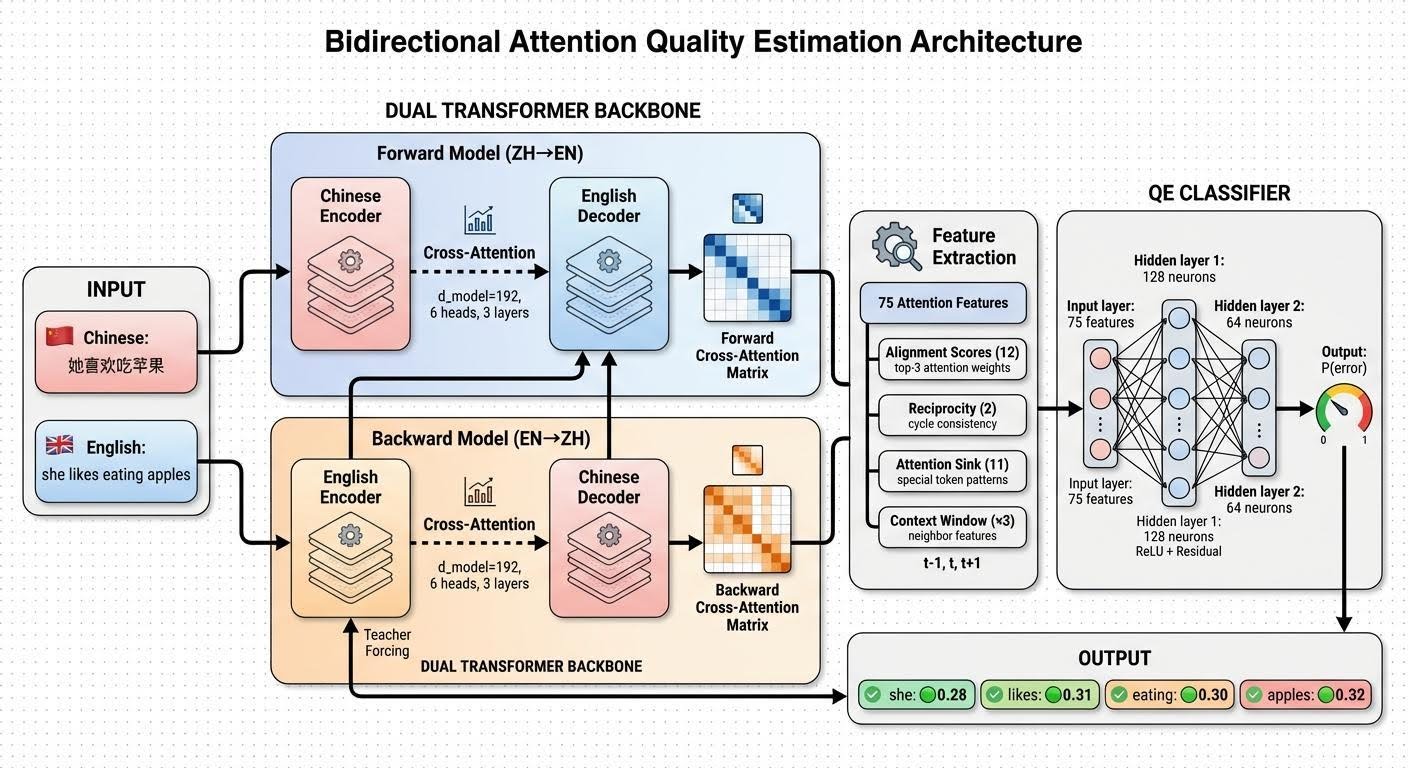
The tactic proposed beneath could make uncertainty computation environment friendly. Since most NMT setups have already got two fashions — a ahead mannequin (language1 → language2) and a backward mannequin (language2 → language1) — we will leverage them to compute interpretable uncertainty indicators.
After producing a translation with the ahead mannequin, we will “place” the inverted translation-source pair into the backward mannequin utilizing instructor forcing (as if it generated it itself), then extract the transposed cross-attention map and evaluate it with the corresponding map from the ahead mannequin. The outcomes beneath present that this strategy permits acquiring interpretable indicators on the token degree normally.
Moreover, there isn’t any have to retrain a heavy NMT mannequin. It’s adequate to coach a light-weight classifier on options from the matrix comparability whereas preserving the principle mannequin’s weights frozen.
What does proper and unsuitable appear like
Let’s begin with a easy French → English translation instance the place every part is obvious simply from the visualization.
“Elle aime manger des pommes → She likes to eat apples”

Now let’s evaluate this with a damaged NMT translation:
“La femme dont je t’ai parlé travaille à cette université” (appropriate translation: “The girl I informed you about works at this college”)
What the mannequin produced:
“The girl whose spouse I informed you about that college”
The place did this additional “spouse” come from?

Bidirectional Cross-Verify
Computation of bidirectional consideration. Please be aware that the backward mannequin makes use of instructor forcing. It receives the pre-generated English translation and checks whether or not it matches again to the unique French supply, whereas no new French sentence is generated. That is an alignment verification, not a round-trip translation.
def get_bidirectional_attention(dual_model, src_tensor, tgt_tensor):
"""Extract ahead/backward cross-attention and reciprocal map."""
dual_model.eval()
with torch.no_grad():
fwd_attn, bwd_attn = dual_model.get_cross_attention(src_tensor, tgt_tensor)
# Align to full goal/supply lengths for element-wise comparability
B, T = tgt_tensor.form
S = src_tensor.form[1]
fwd_aligned = torch.zeros(B, T, S, gadget=src_tensor.gadget)
bwd_aligned = torch.zeros(B, T, S, gadget=src_tensor.gadget)
if T > 1:
fwd_aligned[:, 1:T, :] = fwd_attn
if S > 1:
bwd_aligned[:, :, 1:S] = bwd_attn.transpose(1, 2)
reciprocal = fwd_aligned * bwd_aligned
return fwd_aligned, bwd_aligned, reciprocalAll reproducible code is accessible by way of the undertaking’s GitHub repository.
Originally of my work on the subject, I attempted utilizing direct round-trip translation. Nonetheless, because of the poor efficiency of single-GPU-trained fashions and in addition due to the interpretation ambiguity, it was tough to match the supply and round-trip outcome on the token degree, as sentences might utterly lose their that means. Furthermore, evaluating the eye matrices of the again and ahead fashions for 3 completely different sentences — the supply, the interpretation, and the reproduced supply from the round-trip — would have been expensive.
When Patterns Are Much less Apparent: Chinese language → English
For language pairs with comparable construction (like French↔English), the “1-to-1 token sample” is intuitive. However what about typologically distant languages?
Chinese language → English includes:
- Versatile phrase order. Chinese language is SVO like English, however permits topicalization and pro-drop.
- No areas between phrases. Tokenizers should phase earlier than subword splitting.
- Logographic writing system. Characters map to morphemes, not phonemes.
The eye maps turn into more durable to interpret simply by wanting on the image, nonetheless the discovered options nonetheless handle to seize alignment high quality.
Let’s take a look at this instance of a semantic inversion error:
这家公司的产品质量越来越差客户都很不满意 (appropriate translation: This firm’s product high quality is getting worse, clients are very dissatisfied)
The mannequin output:
The standard of merchandise of the corporate is more and more happy with the client.
The phrase “不满意” means “dissatisfied”, however what the mannequin had produced is precisely reverse. Not even mentioning that the entire translation result’s nonsense.

Regardless of the sample being considerably much less visually noticeable, a trainable QE classifier remains to be capable of seize it. That is exactly why we extract 75 consideration alignment–primarily based options of assorted sorts, as defined in additional element beneath.
Experimental Setup
The NMT core is deliberately stored undertrained for the setup. A near-perfect translator produces few errors to detect. However, to construct a top quality estimation system, we’d like translations that generally (and even usually) fail, and embody omissions, hallucinations, grammatical errors, and mistranslations.
Whereas a fully rubbish mannequin would make no sense, just because there can be no reference for the classifier on what is correct, the mannequin used on this setup (~0.25–0.4 BLEU over a validation a part of the dataset) ensures a gradual provide of numerous error varieties, thereby creating an honest coaching sign for the QE.
The structure makes use of easy scaled dot-product consideration as an alternative of extra superior choices (linear consideration, GQA, and many others.). This retains the eye weights interpretable: every weight represents the likelihood mass assigned to a supply place, with out approximations or kernel tips that might even be good to think about — however but out of the scope of this experiment. Discovering methods to enhance the strategy for extra optimized consideration construction is an efficient ahead level to go.
Knowledge and Annotation
| ZH→EN | FR→EN | |
|---|---|---|
| Typological distance | Excessive | Low |
| Anticipated error varieties | Alignment & phrase order errors | Lexical & tense errors |
| Coaching pairs | 100k sentences | 100k sentences |
| QE annotation set | 15k translations | 15k translations |
Token-level binary high quality labels had been annotated by way of “LLM-as-a-judge” strategy utilizing Gemini 2.5 Flash. The annotation immediate had clear and strict guidelines:
- BAD: mistranslations, unsuitable tense/type, hallucinated content material, incorrect syntax, UNK tokens.
- OK: appropriate that means, legitimate synonyms, pure paraphrasing.
Every translation was tokenized, and the judging mannequin created labels for each token. It additionally offered a reference translation and a minimal post-edit. In whole, this gave approx. 150,000 labeled tokens with 15–20% “BAD” fee.
Coaching Pipeline
Step 1: Prepare bidirectional NMTs. Ahead (src→tgt) and backward (tgt→src) fashions had been skilled collectively on parallel knowledge. Each share the identical structure however separate parameters.
class DualTransformerNMT(nn.Module):
"""Bidirectional translator used for QE characteristic extraction."""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model,
n_heads, n_layers, d_ff, max_length):
tremendous().__init__()
self.zh2en = TransformerNMT(src_vocab_size, tgt_vocab_size,
d_model, n_heads, n_layers, d_ff, max_length)
self.en2zh = TransformerNMT(tgt_vocab_size, src_vocab_size,
d_model, n_heads, n_layers, d_ff, max_length)
class QEClassifier(nn.Module):
"""Token-level BAD likelihood head."""
def __init__(self, input_dim=75, hidden_dim=128, dropout=0.2):
tremendous().__init__()
self.input_projection = nn.Linear(input_dim, hidden_dim)
self.hidden1 = nn.Linear(hidden_dim, hidden_dim)
self.hidden2 = nn.Linear(hidden_dim, hidden_dim // 2)
self.output = nn.Linear(hidden_dim // 2, 1)Step 2: Generate translations. The ahead mannequin translated the QE annotation set. These translations (with their pure errors) grew to become the coaching knowledge for high quality estimation.
Step 3: Extract consideration options. For every translated sentence, 75-dimensional characteristic vectors had been extracted per token place utilizing the strategy described beneath.
def extract_all_features(dual_model, src_tensor, tgt_tensor, attention_extractor):
"""Extract per-token QE options utilized in coaching/inference."""
# Bidirectional cross-attention
fwd_attn, bwd_attn = dual_model.get_cross_attention(src_tensor, tgt_tensor)
# 75 consideration options (25 base x context window [-1,0,+1])
attn_features = attention_extractor.extract(
fwd_attn, bwd_attn, src_tensor, tgt_tensor
)[0] # [T, 75]
# Non-compulsory entropy characteristic (top-k normalized output entropy)
entropy = compute_output_entropy(dual_model.zh2en, src_tensor, tgt_tensor)[0]
# Ultimate mixed vector utilized in ablation: [T, 76]
options = torch.cat([attn_features, entropy.unsqueeze(-1)], dim=-1)
return optionsStep 4: Prepare QE classifier. A small MLP classifier (128 → 64 → 1) was skilled on the extracted options with frozen translator weights.
# Freeze translator weights, prepare QE head solely
dual_model.freeze_translation_models()
n_bad = max(int(y_train.sum()), 1)
n_ok = max(int(len(y_train) - y_train.sum()), 1)
pos_weight = torch.tensor([n_ok / n_bad], gadget=gadget, dtype=torch.float32)
classifier = QEClassifier(input_dim=input_dim, hidden_dim=128, dropout=0.2).to(gadget)
optimizer = torch.optim.Adam(classifier.parameters(), lr=1e-3)
criterion = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
logits = classifier(batch_x.unsqueeze(1)).squeeze(1)
loss = criterion(logits, batch_y)
loss.backward()
optimizer.step()Alignment characteristic varieties
1. Focus (12 options) — The place is the mannequin wanting?

def extract_focus_features(fwd_attn, bwd_attn, tgt_pos, src_content_mask):
"""
Extract top-k alignment scores and their backward counterparts.
Args:
fwd_attn: [S] ahead consideration from goal place to all sources
bwd_attn: [S, T] backward consideration matrix
tgt_pos: present goal place index
src_content_mask: [S] boolean masks for content material (non-special) tokens
Returns:
options: [12] focus characteristic vector
"""
# Masks to solely think about content material supply tokens
fwd_scores = fwd_attn * src_content_mask
# Get top-3 attended supply positions
top_k = 3
top_fwd_scores, top_src_indices = torch.topk(fwd_scores, top_k)
options = torch.zeros(12)
options[0:3] = top_fwd_scores # Ahead top-1, top-2, top-3
# For every prime supply, verify backward alignment energy
for i, src_idx in enumerate(top_src_indices):
bwd_from_src = bwd_attn[src_idx, :] # [T] - how supply seems again
top_bwd_scores, _ = torch.topk(bwd_from_src, 3)
options[3 + i*3 : 3 + (i+1)*3] = top_bwd_scores
return optionsHallucinated tokens usually (but not at all times) have subtle consideration. The mannequin fails to floor the reality between the supply and the goal and tries to “look” all over the place. A assured translation usually focuses sharply on 1–2 supply positions or at the very least has a definite sample.
2. Reciprocity (2 options) — Does the alignment cycle again?

def extract_reciprocity_features(fwd_attn, bwd_attn, tgt_pos, src_content_mask):
"""
Verify if consideration alignment varieties a closed cycle.
Returns:
hard_reciprocal: 1.0 if actual match, 0.0 in any other case
soft_reciprocal: dot product overlap (steady measure)
"""
# Ahead: discover greatest supply place for this goal
fwd_scores = fwd_attn * src_content_mask
best_src = fwd_scores.argmax()
# Backward: does that supply level again to us?
bwd_from_best_src = bwd_attn[best_src, :] # [T]
best_tgt_from_src = bwd_from_best_src.argmax()
# Laborious reciprocity: actual place match
hard_reciprocal = 1.0 if (best_tgt_from_src == tgt_pos) else 0.0
# Comfortable reciprocity: consideration distribution overlap
# Excessive worth = ahead and backward "agree" on alignment
fwd_normalized = fwd_scores / (fwd_scores.sum() + 1e-9)
bwd_normalized = bwd_attn[:, tgt_pos] / (bwd_attn[:, tgt_pos].sum() + 1e-9)
soft_reciprocal = (fwd_normalized * bwd_normalized).sum()
return hard_reciprocal, soft_reciprocalFor instance, if “spouse” (from the instance above) attends to place 3 in French, however place 3 doesn’t attend again to “spouse,” the alignment is spurious.
3. Sink (11 options)

When unsure, transformers usually dump consideration onto “protected” particular tokens (SOS, EOS, PAD):
def extract_sink_features(fwd_attn, bwd_attn, src_tensor, tgt_tensor,
SOS=1, EOS=2, PAD=0):
"""
Extract consideration sink options - consideration mass on particular tokens.
"""
# Determine particular token positions in supply
src_is_sos = (src_tensor == SOS).float()
src_is_eos = (src_tensor == EOS).float()
src_is_pad = (src_tensor == PAD).float()
# Measure consideration mass going to every particular token sort
sink_sos = (fwd_attn * src_is_sos).sum() # Consideration to SOS
sink_eos = (fwd_attn * src_is_eos).sum() # Consideration to EOS
sink_pad = (fwd_attn * src_is_pad).sum() # Consideration to PAD
sink_total = sink_sos + sink_eos + sink_pad
# Backward sink: verify if best-aligned supply additionally reveals uncertainty
best_src = fwd_attn.argmax()
bwd_from_best = bwd_attn[best_src, :]
tgt_is_special = ((tgt_tensor == SOS) | (tgt_tensor == EOS) |
(tgt_tensor == PAD)).float()
bwd_sink = (bwd_from_best * tgt_is_special).sum()
# Asymmetry: disagreement in uncertainty ranges
sink_asymmetry = abs(sink_total - bwd_sink)
# Prolonged options: entropy-based measures
content_mask = 1.0 - src_is_sos - src_is_eos - src_is_pad
fwd_content = fwd_attn * content_mask
fwd_content_norm = fwd_content / (fwd_content.sum() + 1e-9)
max_content = fwd_content.max() # Peak consideration to content material
focus = max_content / (fwd_content.sum() + 1e-9) # How peaked?
return {
'sink_total': sink_total,
'sink_sos': sink_sos,
'sink_eos': sink_eos,
'sink_pad': sink_pad,
'bwd_sink': bwd_sink,
'sink_asymmetry': sink_asymmetry,
'max_content': max_content,
'focus': focus,
# ... plus entropy options
}Why Context Issues
Translation errors create a cascade, the place a dropped phrase impacts neighbors. By together with options from positions t-1 and t+1, we enable the classifier to detect these ripple patterns. That is clearly not the overwhelming sign (particularly when the actual semantic “neighbor” might be situated distantly within the sentence), however it’s already sturdy sufficient to deliver the worth. Combining it with “topological” token-linking strategies might make these options much more significant.
Token-Stage Comparability: What Every Sign Sees
Now let’s take a look at a extra detailed breakdown – if attention-alignment might be matched along with output distribution entropy scores. Are they carrying the identical data or might doubtlessly increase one another?
“Entropy” column beneath is the normalized top-k output entropy values (okay=20) of the ahead mannequin’s softmax distribution, leading to 0–1 scale. A price close to 0 means the mannequin is assured in a single token; a worth close to 1 means likelihood is unfold evenly throughout different candidates.
French: “spouse” hallucination
Supply: La femme dont je t’ai parlé… → MT: “the lady whose spouse i informed you about…”

Chinese language: “happy” semantic inversion
Supply: 这家公司的产品质量越来越差客户都很不满意 → MT: “the standard of merchandise of the corporate is more and more happy with the client”


Repetition Errors: How Consideration Catches Poor Mannequin Artifacts
Supply: Il est évident que cette approche ne fonctionne pas correctement (It’s apparent that this strategy doesn’t work correctly)
MT: “it’s apparent that this strategy doesn’t work correctly function correctly”

What “Assured Translation” Appears to be like Like
Supply: Le rapport mentionne uniquement trois incidents, pas quatre
MT: “the report mentions solely three incidents, not 4”

Scaling up
Now let’s discover how the strategy works at scale. For this, I did a fast ablation verify, which had the aim to look at the impression of attention-based options. Might it’s that they carry nothing worthy of further calculations, in contrast with a easy output entropy?
Methodology: the dataset was break up on the sentence degree into 70% coaching, 15% validation, and 15% take a look at units. The most effective epoch was chosen utilizing validation ROC-AUC for threshold independence, and the classification threshold was tuned on validation F1(BAD). The ultimate metrics had been reported on the held-out take a look at set solely.
Function Contributions
| Options | ZH→EN ROC-AUC | ZH→EN PR-AUC | ZH→EN F1 (BAD) | FR→EN ROC-AUC | FR→EN PR-AUC | FR→EN F1 (BAD) |
|---|---|---|---|---|---|---|
| Entropy solely (1) | 0.663 | 0.380 | 0.441 | 0.797 | 0.456 | 0.470 |
| Consideration solely (75) | 0.730 | 0.486 | 0.488 | 0.796 | 0.441 | 0.457 |
| Mixed (76) | 0.750 | 0.506 | 0.505 | 0.849 | 0.546 | 0.530 |
Prolonged Metrics for Mixed options (entropy+consideration)
| Pair | Precision (BAD) | Recall (BAD) | Specificity (OK) | Balanced Acc. | MCC |
|---|---|---|---|---|---|
| ZH→EN | 0.405 | 0.672 | 0.689 | 0.680 | 0.315 |
| FR→EN | 0.462 | 0.623 | 0.877 | 0.750 | 0.443 |
When mixed, options work higher than every sign alone throughout each language pairs, doubtless as a result of they seize complementary error varieties.
Ultimate ideas
Might the identical strategy be used for duties past translation? Entropy captures “The mannequin doesn’t know what to generate,” whereas consideration captures “The mannequin isn’t grounded within the enter.” For RAG programs, this implies combining perplexity-based detection along with consideration evaluation over retrieved paperwork. For summarization — constructing grounded hyperlinks between supply textual content tokens and people within the abstract.
Limitations
Computation price. Operating the backward mannequin primarily will increase inference time.
It’s a glassbox mannequin solely. You want entry to consideration weights and, due to this fact, it received’t work on API-based fashions. Nonetheless, if in case you have entry — you received’t have to switch the core mannequin’s weights. You possibly can plug in any pretrained encoder-decoder, freeze it, and prepare solely the QE head.
Uncertainty doesn’t imply errors. It simply implies that the mannequin is uncertain. The mannequin generally flags appropriate paraphrases as errors as a result of consideration patterns differ from these which the mannequin met throughout coaching — much like how a human translator is perhaps uncertain if that they had by no means encountered something prefer it earlier than.
Strive It Your self
All code, fashions, and the annotated dataset are open supply:
# Clone the repository
git clone https://github.com/algapchenko/nmt-quality-estimation
cd nmt-quality-estimation
pip set up -r necessities.txt
# Run interactive demo (downloads fashions routinely)
python inference/demo.py --lang zh-en --interactive
# Or use programmatically:
from inference.demo import QEDemo
# Initialize (downloads fashions from HuggingFace routinely)
demo = QEDemo(lang_pair='zh-en')
# Translate with high quality estimation
outcome = demo.translate_with_qe("她喜欢吃苹果")
print(outcome['translation']) # "she likes consuming apples"
print(outcome['tokens']) # ['she', 'likes', 'eating', 'apples']
print(outcome['probs']) # (P(BAD) per token)
print(outcome['tags'])
# Highlighted output
print(demo.format_output(outcome))
# Translation: she likes consuming apples
# QE: she likes consuming apples
# BAD tokens: 0/4Assets
References
[1] S. Farquhar, J. Kossen, L. Kuhn, Y. Gal, Detecting Hallucinations in Massive Language Fashions Utilizing Semantic Entropy (2024), https://www.nature.com/articles/s41586-024-07421-0
[2] COMET, GitHub repository, https://github.com/Unbabel/COMET
[3] W. Xu, S. Agrawal, E. Briakou, M. J. Martindale, M. Carpuat, Understanding and Detecting Hallucinations in Neural Machine Translation by way of Mannequin Introspection (2023), https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00563/















{kind=link}