



Picture by Creator | Canva
# Introduction
Conventional debugging with print() or logging works, however it’s sluggish and clunky with LLMs. Phoenix gives a timeline view of each step, immediate, and response inspection, error detection with retries, visibility into latency and prices, and a whole visible understanding of your app. Phoenix by Arize AI is a strong open-source observability and tracing software particularly designed for LLM purposes. It helps you monitor, debug, and hint every part taking place in your LLM pipelines visually. On this article, we’ll stroll by way of what Phoenix does and why it issues, how one can combine Phoenix with LangChain step-by-step, and how one can visualize traces within the Phoenix UI.
# What’s Phoenix?
Phoenix is an open-source observability and debugging software made for big language mannequin purposes. It captures detailed telemetry knowledge out of your LLM workflows, together with prompts, responses, latency, errors, and gear utilization, and presents this data in an intuitive, interactive dashboard. Phoenix permits builders to deeply perceive how their LLM pipelines behave contained in the system, establish and debug points with immediate outputs, analyze efficiency bottlenecks, monitor utilizing tokens and related prices, and hint any errors/retry logic throughout execution part. It helps constant integrations with well-liked frameworks like LangChain and LlamaIndex, and in addition provides OpenTelemetry help for extra personalized setups.
# Step-by-Step Setup
// 1. Putting in Required Libraries
Be sure to have Python 3.8+ and set up the dependencies:
pip set up arize-phoenix langchain langchain-together openinference-instrumentation-langchain langchain-community
// 2. Launching Phoenix
Add this line to launch the Phoenix dashboard:
import phoenix as px
px.launch_app()
This begins a neighborhood dashboard at http://localhost:6006.
// 3. Constructing the LangChain Pipeline with Phoenix Callback
Let’s perceive Phoenix utilizing a use case. We’re constructing a easy LangChain-powered chatbot. Now, we need to:
- Debug if the immediate is working
- Monitor how lengthy the mannequin takes to reply
- Observe immediate construction, mannequin utilization, and outputs
- See all this visually as an alternative of logging every part manually
// Step 1: Launch the Phoenix Dashboard within the Background
import threading
import phoenix as px
# Launch Phoenix app domestically (entry at http://localhost:6006)
def run_phoenix():
px.launch_app()
threading.Thread(goal=run_phoenix, daemon=True).begin()
// Step 2: Register Phoenix with OpenTelemetry & Instrument LangChain
from phoenix.otel import register
from openinference.instrumentation.langchain import LangChainInstrumentor
# Register OpenTelemetry tracer
tracer_provider = register()
# Instrument LangChain with Phoenix
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
// Step 3: Initialize the LLM (Collectively API)
from langchain_together import Collectively
llm = Collectively(
mannequin="meta-llama/Llama-3-8b-chat-hf",
temperature=0.7,
max_tokens=256,
together_api_key="your-api-key", # Substitute together with your precise API key
)
Please don’t overlook to switch the “your-api-key” together with your precise collectively.ai API key. You will get it utilizing this hyperlink.
// Step 4: Outline the Immediate Template
from langchain.prompts import ChatPromptTemplate
immediate = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
("human", "{question}"),
])
// Step 5: Mix Immediate and Mannequin right into a Chain
// Step 6: Ask A number of Questions and Print Responses
questions = [
"What is the capital of France?",
"Who discovered gravity?",
"Give me a motivational quote about perseverance.",
"Explain photosynthesis in one sentence.",
"What is the speed of light?",
]
print("Phoenix operating at http://localhost:6006n")
for q in questions:
print(f" Query: {q}")
response = chain.invoke({"query": q})
print(" Reply:", response, "n")
// Step 7: Preserve the App Alive for Monitoring
attempt:
whereas True:
move
besides KeyboardInterrupt:
print(" Exiting.")
# Understanding Phoenix Traces & Metrics
Earlier than seeing the output, we must always first perceive Phoenix metrics. You have to to first perceive what traces and spans are:
Hint: Every hint represents one full run of your LLM pipeline. For instance, every query like “What’s the capital of France?” generates a brand new hint.
Spans: Every hint is combined of a number of spans, every representing a stage in your chain:
- ChatPromptTemplate.format: Immediate formatting
- TogetherLLM.invoke: LLM name
- Any customized parts you add
Metrics Proven per Hint
| Metric | Which means & Significance |
|---|---|
| Latency (ms) | Measures complete time for full LLM chain execution, together with immediate formatting, LLM response, and post-processing. Helps establish efficiency bottlenecks and debug sluggish responses. |
| Enter Tokens | Variety of tokens despatched to the mannequin. Essential for monitoring enter measurement and controlling API prices, since most utilization is token-based. |
| Output Tokens | Variety of tokens generated by the mannequin. Helpful for understanding verbosity, response high quality, and price impression. |
| Immediate Template | Shows the complete immediate with inserted variables. Helps affirm whether or not prompts are structured and crammed in accurately. |
| Enter / Output Textual content | Exhibits each consumer enter and the mannequin’s response. Helpful for checking interplay high quality and recognizing hallucinations or incorrect solutions. |
| Span Durations | Breaks down the time taken by every step (like immediate creation or mannequin invocation). Helps establish efficiency bottlenecks inside the chain. |
| Chain Title |
Specifies which a part of the pipeline a span belongs to (e.g., immediate.format, TogetherLLM.invoke). Helps isolate the place points are occurring.
|
| Tags / Metadata | Further data like mannequin identify, temperature, and many others. Helpful for filtering runs, evaluating outcomes, and analyzing parameter impression. |
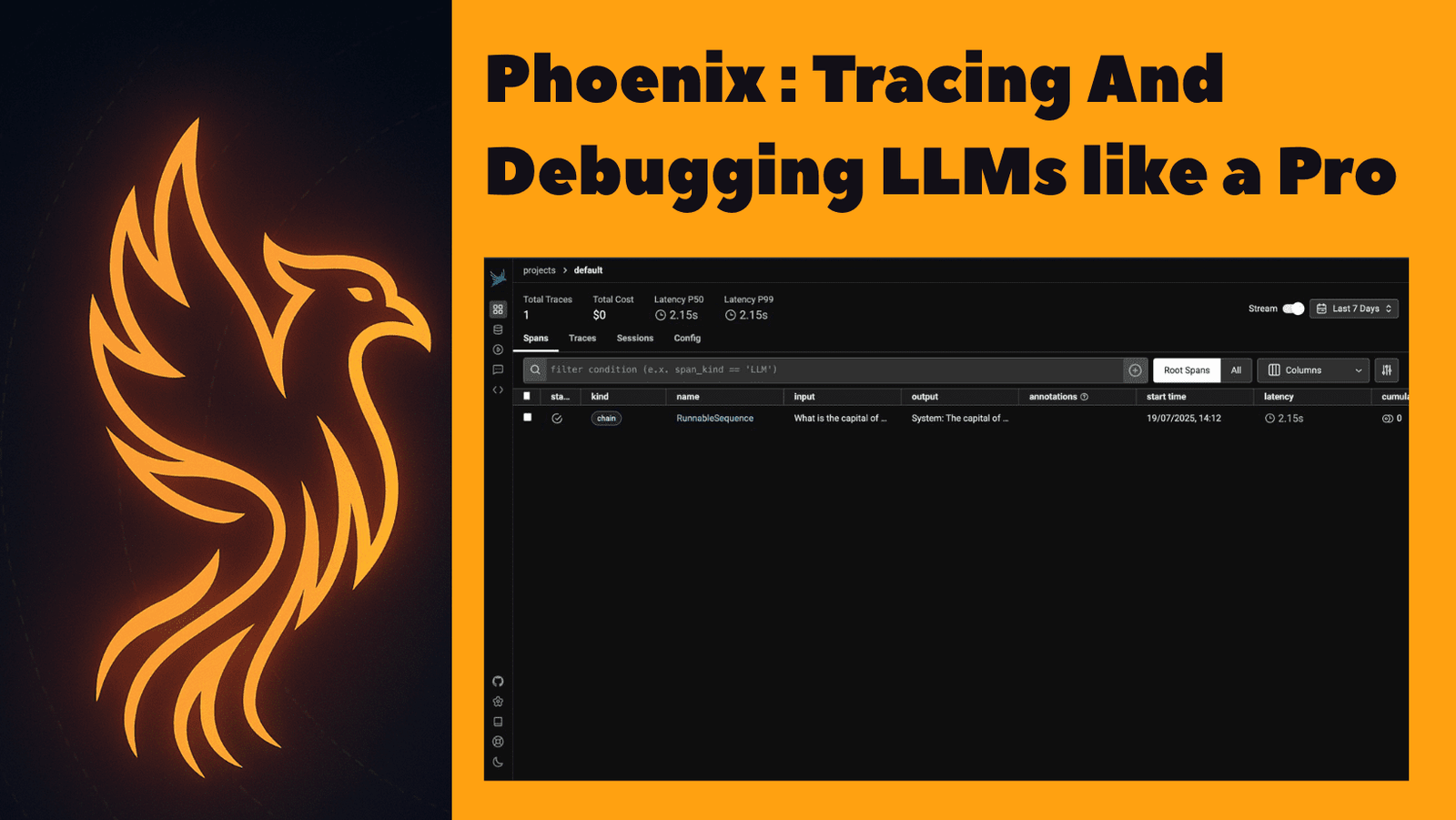
Now go to http://localhost:6006 to view the Phoenix dashboard. You will notice one thing like:

Open the primary hint to view its particulars.

# Wrapping Up
To wrap it up, Arize Phoenix makes it extremely straightforward to debug, hint, and monitor your LLM purposes. You don’t should guess what went fallacious or dig by way of logs. Every thing’s proper there: prompts, responses, timings, and extra. It helps you notice points, perceive efficiency, and simply construct higher AI experiences with approach much less stress.
Kanwal Mehreen is a machine studying engineer and a technical author with a profound ardour for knowledge science and the intersection of AI with drugs. She co-authored the book “Maximizing Productiveness with ChatGPT”. As a Google Era Scholar 2022 for APAC, she champions range and tutorial excellence. She’s additionally acknowledged as a Teradata Range in Tech Scholar, Mitacs Globalink Analysis Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having based FEMCodes to empower girls in STEM fields.
Picture by Creator | Canva
# Introduction
Conventional debugging with print() or logging works, however it’s sluggish and clunky with LLMs. Phoenix gives a timeline view of each step, immediate, and response inspection, error detection with retries, visibility into latency and prices, and a whole visible understanding of your app. Phoenix by Arize AI is a strong open-source observability and tracing software particularly designed for LLM purposes. It helps you monitor, debug, and hint every part taking place in your LLM pipelines visually. On this article, we’ll stroll by way of what Phoenix does and why it issues, how one can combine Phoenix with LangChain step-by-step, and how one can visualize traces within the Phoenix UI.
# What’s Phoenix?
Phoenix is an open-source observability and debugging software made for big language mannequin purposes. It captures detailed telemetry knowledge out of your LLM workflows, together with prompts, responses, latency, errors, and gear utilization, and presents this data in an intuitive, interactive dashboard. Phoenix permits builders to deeply perceive how their LLM pipelines behave contained in the system, establish and debug points with immediate outputs, analyze efficiency bottlenecks, monitor utilizing tokens and related prices, and hint any errors/retry logic throughout execution part. It helps constant integrations with well-liked frameworks like LangChain and LlamaIndex, and in addition provides OpenTelemetry help for extra personalized setups.
# Step-by-Step Setup
// 1. Putting in Required Libraries
Be sure to have Python 3.8+ and set up the dependencies:
pip set up arize-phoenix langchain langchain-together openinference-instrumentation-langchain langchain-community
// 2. Launching Phoenix
Add this line to launch the Phoenix dashboard:
import phoenix as px
px.launch_app()
This begins a neighborhood dashboard at http://localhost:6006.
// 3. Constructing the LangChain Pipeline with Phoenix Callback
Let’s perceive Phoenix utilizing a use case. We’re constructing a easy LangChain-powered chatbot. Now, we need to:
- Debug if the immediate is working
- Monitor how lengthy the mannequin takes to reply
- Observe immediate construction, mannequin utilization, and outputs
- See all this visually as an alternative of logging every part manually
// Step 1: Launch the Phoenix Dashboard within the Background
import threading
import phoenix as px
# Launch Phoenix app domestically (entry at http://localhost:6006)
def run_phoenix():
px.launch_app()
threading.Thread(goal=run_phoenix, daemon=True).begin()
// Step 2: Register Phoenix with OpenTelemetry & Instrument LangChain
from phoenix.otel import register
from openinference.instrumentation.langchain import LangChainInstrumentor
# Register OpenTelemetry tracer
tracer_provider = register()
# Instrument LangChain with Phoenix
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
// Step 3: Initialize the LLM (Collectively API)
from langchain_together import Collectively
llm = Collectively(
mannequin="meta-llama/Llama-3-8b-chat-hf",
temperature=0.7,
max_tokens=256,
together_api_key="your-api-key", # Substitute together with your precise API key
)
Please don’t overlook to switch the “your-api-key” together with your precise collectively.ai API key. You will get it utilizing this hyperlink.
// Step 4: Outline the Immediate Template
from langchain.prompts import ChatPromptTemplate
immediate = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
("human", "{question}"),
])
// Step 5: Mix Immediate and Mannequin right into a Chain
// Step 6: Ask A number of Questions and Print Responses
questions = [
"What is the capital of France?",
"Who discovered gravity?",
"Give me a motivational quote about perseverance.",
"Explain photosynthesis in one sentence.",
"What is the speed of light?",
]
print("Phoenix operating at http://localhost:6006n")
for q in questions:
print(f" Query: {q}")
response = chain.invoke({"query": q})
print(" Reply:", response, "n")
// Step 7: Preserve the App Alive for Monitoring
attempt:
whereas True:
move
besides KeyboardInterrupt:
print(" Exiting.")
# Understanding Phoenix Traces & Metrics
Earlier than seeing the output, we must always first perceive Phoenix metrics. You have to to first perceive what traces and spans are:
Hint: Every hint represents one full run of your LLM pipeline. For instance, every query like “What’s the capital of France?” generates a brand new hint.
Spans: Every hint is combined of a number of spans, every representing a stage in your chain:
- ChatPromptTemplate.format: Immediate formatting
- TogetherLLM.invoke: LLM name
- Any customized parts you add
Metrics Proven per Hint
| Metric | Which means & Significance |
|---|---|
| Latency (ms) | Measures complete time for full LLM chain execution, together with immediate formatting, LLM response, and post-processing. Helps establish efficiency bottlenecks and debug sluggish responses. |
| Enter Tokens | Variety of tokens despatched to the mannequin. Essential for monitoring enter measurement and controlling API prices, since most utilization is token-based. |
| Output Tokens | Variety of tokens generated by the mannequin. Helpful for understanding verbosity, response high quality, and price impression. |
| Immediate Template | Shows the complete immediate with inserted variables. Helps affirm whether or not prompts are structured and crammed in accurately. |
| Enter / Output Textual content | Exhibits each consumer enter and the mannequin’s response. Helpful for checking interplay high quality and recognizing hallucinations or incorrect solutions. |
| Span Durations | Breaks down the time taken by every step (like immediate creation or mannequin invocation). Helps establish efficiency bottlenecks inside the chain. |
| Chain Title |
Specifies which a part of the pipeline a span belongs to (e.g., immediate.format, TogetherLLM.invoke). Helps isolate the place points are occurring.
|
| Tags / Metadata | Further data like mannequin identify, temperature, and many others. Helpful for filtering runs, evaluating outcomes, and analyzing parameter impression. |
Now go to http://localhost:6006 to view the Phoenix dashboard. You will notice one thing like:
Open the primary hint to view its particulars.
# Wrapping Up
To wrap it up, Arize Phoenix makes it extremely straightforward to debug, hint, and monitor your LLM purposes. You don’t should guess what went fallacious or dig by way of logs. Every thing’s proper there: prompts, responses, timings, and extra. It helps you notice points, perceive efficiency, and simply construct higher AI experiences with approach much less stress.
Kanwal Mehreen is a machine studying engineer and a technical author with a profound ardour for knowledge science and the intersection of AI with drugs. She co-authored the book “Maximizing Productiveness with ChatGPT”. As a Google Era Scholar 2022 for APAC, she champions range and tutorial excellence. She’s additionally acknowledged as a Teradata Range in Tech Scholar, Mitacs Globalink Analysis Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having based FEMCodes to empower girls in STEM fields.

















{kind=link}