


GPUs function the elemental computational engines for AI. Nonetheless, In large-scale coaching environments, general efficiency shouldn’t be restricted by processing pace, however by the pace of the community communication between them.
Giant language fashions are skilled on 1000’s of GPUs, which creates an enormous quantity of cross-GPU visitors. In these methods, even the smallest delays compound. A microsecond lag when GPUs share information could cause a sequence response that provides hours to the coaching job. Subsequently, these methods require a specialised community that’s designed to switch giant quantities of information with minimal delay.
The standard method of routing GPU information via the CPU created a extreme bottleneck at scale. To repair this bottleneck, applied sciences like RDMA and GPUDirect had been invented to basically construct a bypass across the CPU. This creates a direct path for GPUs to speak to 1 one other.
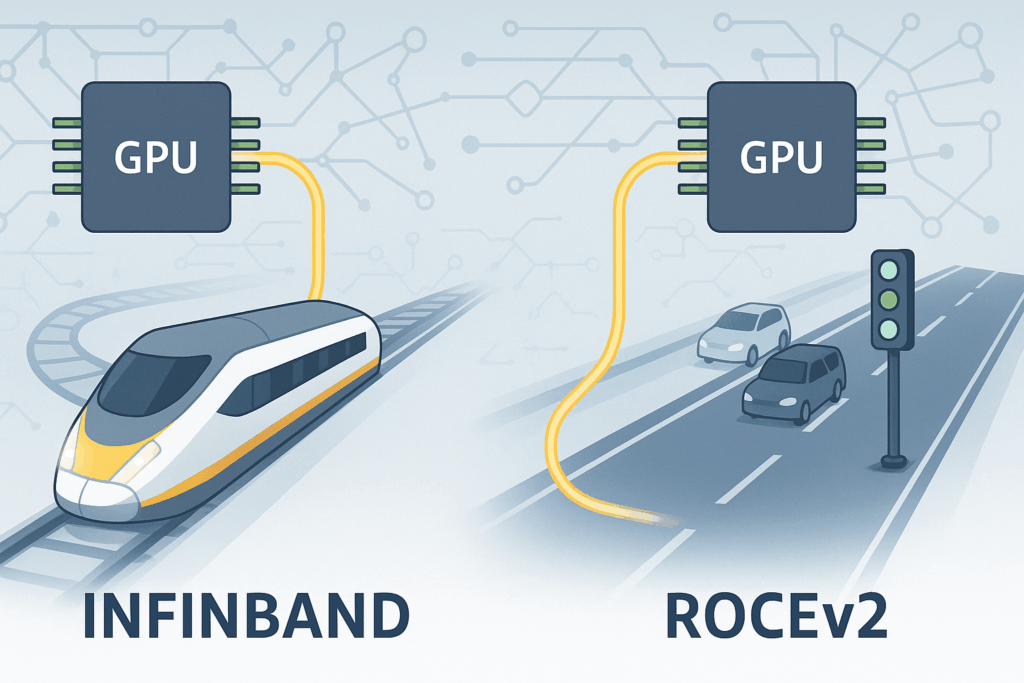
This direct communication methodology wants a community that may deal with the pace. The 2 major decisions obtainable right this moment to supply this are InfiniBand and RoCEv2.
So, how do you select between InfiniBand and RoCEv2? It’s a giant deal, forcing you to stability uncooked pace towards price range and the way a lot hands-on tuning you’re prepared to do.
Let’s take a more in-depth have a look at every expertise to see its strengths and weaknesses.
Fundamental Ideas
Earlier than we examine InfiniBand and RoCEv2, let’s first perceive how conventional communication works and introduce some fundamental ideas like RDMA and GPU Direct.
Conventional Communication
In conventional methods, a lot of the information motion between machines is dealt with by the CPU. When a GPU finishes its computation and must ship information to a distant node, it follows the next steps –

- The GPU writes the information to the system (host) reminiscence
- The CPU copies that information right into a buffer utilized by the community card
- The NIC (Community Interface Card) sends the information over the community
- On the receiving node, the NIC delivers the information to the CPU
- The CPU writes it into system reminiscence
- The GPU reads it from system reminiscence
This method works properly for small methods, however it doesn’t scale for AI workloads. As extra information will get copied round, the delays begin to add up, and the community struggles to maintain up.
RDMA
Distant Direct Reminiscence Entry (RDMA) allows an area machine to entry the reminiscence of a distant machine instantly with out involving the CPU within the information switch course of. On this structure, the community interface card handles all reminiscence operations independently, permitting it to learn from or write to distant reminiscence areas with out creating intermediate copies of the information. This direct reminiscence entry functionality eliminates the normal bottlenecks related to CPU-mediated information transfers and reduces general system latency.
RDMA proves significantly worthwhile in AI coaching environments the place 1000’s of GPUs should share gradient info effectively. By bypassing working system overhead and community delays, RDMA allows the high-throughput, low-latency communication important for distributed machine studying operations.
GPUDirect RDMA
GPUDirect is NVIDIA’s method of letting GPUs discuss on to different {hardware} via PCIe connections. Usually, when a GPU must switch information to a different system, it has to take the great distance round. The information goes from GPU reminiscence to system reminiscence first, then the receiving system grabs it from there. GPUDirect skips the CPU completely. Knowledge strikes instantly from one GPU to a different.
GPUDirect RDMA extends this to community transfers by permitting the NIC to entry GPU reminiscence instantly utilizing PCIe.

Now that we perceive ideas like RDMA and GPUDirect, let’s look into the infrastructure applied sciences InfiniBand and RoCEv2 that assist GPUDirect RDMA.
InfiniBand
InfiniBand is a high-performance networking expertise designed particularly for information facilities and supercomputing environments. Whereas Ethernet was constructed to deal with common visitors, InfiniBand is designed to fulfill excessive pace and low latency for AI workloads.
It’s like a high-speed bullet prepare the place each the prepare and the tracks are designed to keep up the pace. InfiniBand follows the identical idea, all the pieces together with the cables, community playing cards, and switches are designed to maneuver information quick and keep away from any delays.
How does it work?
InfiniBand works utterly otherwise from common Ethernet. It doesn’t use the common TCP/IP protocol. As an alternative, it depends by itself light-weight transport layers designed for pace and low latency.
On the core of InfiniBand is RDMA, which permits one server to instantly entry the reminiscence of one other with out involving the CPU. InfiniBand helps RDMA in {hardware}, so the community card, referred to as a Host Channel Adapter or HCA, handles information transfers instantly with out interrupting the working system or creating further copies of information.
InfiniBand additionally makes use of a lossless communication mannequin. It avoids dropping packets even below heavy visitors through the use of credit-based stream management. The sender transmits information solely when the receiver has sufficient buffer area obtainable.
In giant GPU clusters, InfiniBand switches transfer information between nodes with extraordinarily low latency, usually below one microsecond. And since the complete system is constructed for this function, all the pieces from the {hardware} to the software program works collectively to ship constant, high-throughput communication.
Let’s perceive a easy GPU-to-GPU communication utilizing the next diagram -

- GPU 1 fingers off information to its HCA, skipping the CPU
- The HCA initiates an RDMA write to the distant GPU
- Knowledge is transferred over the InfiniBand swap
- The receiving HCA writes the information on to GPU 2’s reminiscence
Energy
- Quick and predictable – InfiniBand delivers ultra-low latency and excessive bandwidth, preserving giant GPU clusters working effectively with out hiccups.
- Constructed for RDMA – It handles RDMA in {hardware} and makes use of credit-based stream management to keep away from packet drops, even below heavy load.
- Scalable – Since all components of the system are designed to work collectively, efficiency shouldn’t be impacted if extra nodes are added to the cluster.
Weaknesses
- Costly – {Hardware} is dear and principally tied to NVIDIA, which limits flexibility.
- Tougher to handle – Setup and tuning require specialised abilities. It’s not as easy as Ethernet.
- Restricted interoperability – It doesn’t play properly with customary IP networks, making it much less versatile for general-purpose environments.
RoceV2
RoCEv2 (RDMA over Converged Ethernet model 2) brings the advantages of RDMA to straightforward Ethernet networks. RoCEv2 takes a unique method than InfiniBand. As an alternative of needing customized community {hardware}, it simply makes use of your common IP community with UDP for transport.
Consider it like upgrading a daily freeway with an categorical lane only for crucial information. You don’t should rebuild the complete street system. You simply want to order the quick lane and tune the visitors alerts. RoCEv2 makes use of the identical idea, it delivers high-speed and low-latency communication utilizing the present Ethernet system.
How does it work?
RoCEv2 brings RDMA to straightforward Ethernet by working over UDP and IP. It really works throughout common Layer 3 networks while not having a devoted cloth. It makes use of commodity switches and routers, making it extra accessible and cost-effective.
Like InfiniBand, RoCEv2 allows direct reminiscence entry between machines. The important thing distinction is that whereas InfiniBand handles stream management and congestion in a closed, tightly managed setting, RoCEv2 depends on enhancements to Ethernet, resembling –
Precedence Stream Management(PFC) – Prevents packet loss by pausing visitors on the Ethernet layer based mostly on precedence.
Specific Congestion Notification(ECN) – Mark packets as an alternative of dropping them when congestion is detected.
Knowledge Middle Quantized Congestion Notification(DCQCN) – A congestion management protocol that reacts to ECN alerts to handle visitors extra easily.
To make RoCEv2 work properly, the underlying Ethernet community must be lossless or near it. In any other case, RDMA efficiency drops. This requires cautious configuration of switches, queues, and stream management mechanisms all through the information heart.
Let’s perceive a easy GPU-to-GPU communication utilizing the next diagram with RoCEv2 –

- GPU 1 fingers off information to its NIC, skipping the CPU.
- The NIC wraps the RDMA write in UDP/IP and sends it over Ethernet.
- Knowledge flows via customary Ethernet switches configured with PFC and ECN.
- The receiving NIC writes the information on to GPU 2’s reminiscence.
Energy
Value-effective – RoCEv2 runs on customary Ethernet {hardware}, so that you don’t want a specialised community cloth or vendor-locked parts.
Simpler to deploy – Because it makes use of acquainted IP-based networking, it’s simpler for groups already managing Ethernet information facilities to undertake.
Versatile integration – RoCEv2 works properly in combined environments and integrates simply with current Layer 3 networks.
Weaknesses
Requires tuning – To keep away from packet loss, RoCEv2 is determined by cautious configuration of PFC, ECN, and congestion management. Poor tuning can damage efficiency.
Much less deterministic – In contrast to InfiniBand’s tightly managed setting, Ethernet-based networks can introduce variability in latency and jitter.
Complicated at scale – As clusters develop, sustaining a lossless Ethernet cloth with constant conduct turns into more and more troublesome.
Conclusion
In a large-scale GPU cluster, compute energy is nugatory if the community can’t deal with the load. Community efficiency turns into simply as important because the GPUs as a result of it holds the entire system collectively. Applied sciences like RDMA and GPUDirect RDMA assist lower out the same old slowdowns by eliminating pointless interruptions and CPU copying, letting GPUs discuss instantly to one another.
Each InfiniBand and RoCEv2 pace up GPU-to-GPU communication, however they take totally different approaches. InfiniBand builds its personal devoted community setup. It gives wonderful pace and low latency, however at a really excessive price. RoCEv2 gives extra flexibility through the use of the present Ethernet setup. It’s simpler on the price range, however it wants correct tuning of PFC and ECN to make it work.
On the finish of the day, it’s a basic trade-off. Go together with InfiniBand in case your high precedence is getting the best possible efficiency attainable, and price range is much less of a priority. However if you’d like a extra versatile answer that works together with your current community gear and prices much less upfront, RoCEv2 is the best way to go.














{kind=link}