


about constructing your individual AI brokers? Are you continually overwhelmed by all of the buzzwords round brokers? You’re not alone; I’ve additionally been there. There are quite a few instruments out there, and even determining which one to decide on can really feel like a venture in itself. Moreover, there’s uncertainty surrounding the price and infrastructure. Will I eat too many tokens? How and the place can I deploy my answer?
For some time, I additionally hesitated to construct one thing by myself. I wanted to grasp the fundamentals first, see a couple of examples to grasp how issues work, after which attempt some hands-on expertise to deliver these ideas to life. After plenty of analysis, I lastly landed on CrewAI — and it turned out to be the proper place to begin. There are two nice programs provided by DeepLearning.AI: Multi AI Agent Programs with crewAI & Sensible Multi AI Brokers and Superior Use Circumstances with crewAI. Within the course, the trainer has very clearly defined every part that you must learn about AI brokers to get began. There are greater than 10 case research with codes offered within the course which serves as an excellent place to begin.
It’s not sufficient to simply study stuff anymore. When you have not utilized what you’ve realized, you’re prone to neglect the fundamentals with time. If I simply re-rerun the use instances from the course, it’s probably not “making use of”. I needed to construct one thing and implement it for myself. I made a decision to construct a use case that was intently associated to what I work with. As a knowledge analyst and engineer, I largely work with Python and SQL. I believed to myself how cool it will be if I may construct an assistant that will generate SQL queries primarily based on pure language. I agree there are already loads of out-of-box options out there available in the market. I’m not attempting to reinvent the wheel right here. With this POC, I wish to learn the way such programs are constructed and what are their potential limitations. What I’m attempting to uncover here’s what it takes to construct such an assistant.

On this publish, I’ll stroll you thru how I used CrewAI & Streamlit to construct a Multi-Agent SQL Assistant. It lets customers question a SQLite database utilizing pure language. To have extra management over the complete course of, I’ve additionally included a human-in-loop test plus I show the LLM utilization prices for each question. As soon as a question is generated by the assistant, the person can have 3 choices: settle for and proceed if the question seems good, ask the assistant to attempt once more if the question appears off, or abort the entire course of if it’s not working nicely. Having this checkpoint makes an enormous distinction — it offers extra energy to the person, avoids executing dangerous queries, and likewise helps in saving LLM prices in the long term.
You’ll find the complete code repository right here. Under is the whole venture construction:
SQL Assistant Crew Challenge Construction
===================================
.
├── app.py (Streamlit UI)
├── most important.py (terminal)
├── crew_setup.py
├── config
│ ├── brokers.yaml
│ └── duties.yaml
├── information
│ └── sample_db.sqlite
├── utils
│ ├── db_simulator.py
│ └── helper.py
The Agent Structure (my CrewAI workforce)
For my SQL Assistant system, I wanted at the least 3 fundamental brokers to deal with the complete course of effectively:
- Question Generator Agent would convert the pure language questions by the person right into a SQL question utilizing the database schema as context.
- Question Reviewer Agent would take the SQL question generated by the generator agent and optimizes it additional for accuracy and effectivity.
- Compliance Checker Agent would test the question for potential PII publicity and submit a verdict of whether or not the question is compliant or not.
Each agent will need to have 3 core attributes — a job (what the agent is meant to be), a objective (what’s the agent’s mission), and a backstory (set the character of the agent to information the way it ought to behave). I’ve enabled verbose=“True” to view the Agent’s inner thought course of. I’m utilizing the openai/gpt-4o-mini because the underlying language mannequin for all my brokers. After loads of trial and error, I set the temperature=0.2 to cut back the hallucinations of the brokers. Decrease temperatures make the mannequin extra deterministic and supply predictable outputs (like SQL queries in my case). There are a lot of different parameters which are out there to tune like max_tokens (set limits for the size of response), top_p (for nucleus sampling), allow_delegation (to delegate the duty to different brokers), and many others. If you’re utilizing another LLMs, you possibly can merely specify the LLM mannequin title right here. You possibly can set the identical LLM for all of the brokers or totally different ones as per your necessities.
Under is the yaml file which has the definitions of the brokers:
query_generator_agent:
function: Senior Information Analyst
objective: Translate pure language requests into correct and environment friendly SQL queries
backstory: >
You're an skilled analyst who is aware of SQL finest practices. You're employed with stakeholders to collect necessities
and switch their questions into clear, performant queries. You favor readable SQL with applicable filters and joins.
allow_delegation: False
verbose: True
mannequin: openai/gpt-4o-mini
temperature: 0.2
query_reviewer_agent:
function: SQL Code Reviewer
objective: Critically consider SQL for correctness, efficiency, and readability
backstory: >
You're a meticulous reviewer of SQL code. You establish inefficiencies, dangerous practices, and logical errors, and
present options to enhance the question's efficiency and readability.
allow_delegation: False
verbose: True
mannequin: openai/gpt-4o-mini
temperature: 0.2
compliance_checker_agent:
function: Information Privateness and Governance Officer
objective: Guarantee SQL queries observe information compliance guidelines and keep away from PII publicity
backstory: >
You're chargeable for guaranteeing queries don't leak or expose personally identifiable data (PII) or
violate firm insurance policies. You flag any unsafe or non-compliant practices.
allow_delegation: False
verbose: True
mannequin: openai/gpt-4o-mini
temperature: 0.2As soon as you’re carried out creating your brokers, the subsequent step is to outline the duties they need to carry out. Each process will need to have a transparent description of what the agent is meant to do. It’s extremely beneficial that you just additionally set the expected_output parameter to form the ultimate response of the LLM. It’s a approach of telling the LLM precisely the form of reply you expect — it might be a textual content, a quantity, a question, and even an article. The outline must be as detailed and concrete as doable. Having imprecise descriptions will solely lead to imprecise and even fully flawed outputs. I needed to modify the descriptions a number of instances throughout testing to regulate the standard of the response the agent was producing. One of many options I really like is the power to inject dynamic inputs into the duty descriptions by offering curly braces ({}). These placeholders might be person prompts, ideas, definitions, and even outputs of earlier brokers. All of those enable the LLMs to generate extra correct outcomes.
query_task:
description: |
You're an knowledgeable SQL assistant. Your job is to translate person requests into SQL queries utilizing ONLY the tables and columns listed under.
SCHEMA:
{db_schema}
USER REQUEST:
{user_input}
IMPORTANT:
- First, checklist which tables and columns from the schema you'll use to reply the request.
- Then, write the SQL question.
- Solely use the tables and columns from the schema above.
- If the request can't be glad with the schema, return a SQL remark (beginning with --) explaining why.
- Do NOT invent tables or columns.
- Be certain that the question matches the person's intent as intently as doable.
expected_output: First, a listing of tables and columns to make use of. Then, a syntactically appropriate SQL question utilizing applicable filters, joins, and groupings.
review_task:
description: |
Evaluate the next SQL question for correctness, efficiency, and readability: {sql_query} and confirm that the question suits the schema: {db_schema}
Be sure that solely tables and columns from the offered schema are used.
IMPORTANT:
- First, solely evaluation the SQL question offered for correctness, efficiency, or readability
- Do NOT invent new tables or columns.
- If the Question is already appropriate, return it unchanged.
- If the Question shouldn't be appropriate and can't be mounted, return a SQL remark (beginning with --) explaining why.
expected_output: An optimized or verified SQL question
compliance_task:
description: >
Evaluate the next SQL question for compliance violations, together with PII entry, unsafe utilization, or coverage violations.
Checklist any points discovered, or state "No points discovered" if the question is compliant.
SQL Question: {reviewed_sqlquery}
expected_output: >
A markdown-formatted compliance report itemizing any flagged points, or stating that the question is compliant. Embrace a transparent verdict on the high (e.g., "Compliant" or "Points discovered")It’s an excellent apply to have the agent and process definitions in separate YAML recordsdata. For those who ever wish to make any updates to the definitions of brokers or duties, you solely want to switch the YAML recordsdata and never contact the codebase in any respect. Within the crew_setup.py file, every part comes collectively. I learn and loaded the agent and process configurations from their respective YAML recordsdata. I additionally created the definitions for all of the anticipated outputs utilizing Pydantic fashions to present them construction and validate what the LLM ought to return. I then assign the brokers with their respective duties and assemble my crew. There are a number of methods to construction your crew relying on the use case. A single crew of brokers can carry out duties in sequence or parallel. Alternatively, you possibly can create a number of crews, every chargeable for a selected a part of your workflow. For my use case, I selected to construct a number of crews to have extra management on the execution move by inserting a human-in-loop checkpoint and management price.
from crewai import Agent, Process, Crew
from pydantic import BaseModel, Area
from typing import Checklist
import yaml
# Outline file paths for YAML configurations
recordsdata = {
'brokers': 'config/brokers.yaml',
'duties': 'config/duties.yaml',
}
# Load configurations from YAML recordsdata
configs = {}
for config_type, file_path in recordsdata.objects():
with open(file_path, 'r') as file:
configs[config_type] = yaml.safe_load(file)
# Assign loaded configurations to particular variables
agents_config = configs['agents']
tasks_config = configs['tasks']
class SQLQuery(BaseModel):
sqlquery: str = Area(..., description="The uncooked sql question for the person enter")
class ReviewedSQLQuery(BaseModel):
reviewed_sqlquery: str = Area(..., description="The reviewed sql question for the uncooked sql question")
class ComplianceReport(BaseModel):
report: str = Area(..., description="A markdown-formatted compliance report with a verdict and any flagged points.")
# Creating Brokers
query_generator_agent = Agent(
config=agents_config['query_generator_agent']
)
query_reviewer_agent = Agent(
config=agents_config['query_reviewer_agent']
)
compliance_checker_agent = Agent(
config=agents_config['compliance_checker_agent']
)
# Creating Duties
query_task = Process(
config=tasks_config['query_task'],
agent=query_generator_agent,
output_pydantic=SQLQuery
)
review_task = Process(
config=tasks_config['review_task'],
agent=query_reviewer_agent,
output_pydantic=ReviewedSQLQuery
)
compliance_task = Process(
config=tasks_config['compliance_task'],
agent=compliance_checker_agent,
context=[review_task],
output_pydantic=ComplianceReport
)
# Creating Crew objects for import
sql_generator_crew = Crew(
brokers=[query_generator_agent],
duties=[query_task],
verbose=True
)
sql_reviewer_crew = Crew(
brokers=[query_reviewer_agent],
duties=[review_task],
verbose=True
)
sql_compliance_crew = Crew(
brokers=[compliance_checker_agent],
duties=[compliance_task],
verbose=True
)I arrange a neighborhood SQLite database with some pattern information to simulate the real-life database interactions for my POC. I fetch the database schema which contains all of the tables and column names current within the system. I later fed this schema as context to the LLM together with the unique person question to assist the LLM generate a SQL question with the unique tables and columns from the schema offered and never invent one thing by itself. As soon as the Generator agent creates a SQL question, it goes for a evaluation by the Reviewer agent adopted by a compliance test from the Compliance agent. Solely after these critiques, do I enable the reviewed question to be executed on the database to point out the ultimate outcomes to the person through the streamlit interface. By including validation and security checks, I guarantee solely high-quality queries are executed on the database minimising pointless token utilization and compute prices for the long term.
import sqlite3
import pandas as pd
DB_PATH = "information/sample_db.sqlite"
def setup_sample_db():
conn = sqlite3.join(DB_PATH)
cursor = conn.cursor()
# Drop tables in the event that they exist (for repeatability in dev)
cursor.execute("DROP TABLE IF EXISTS order_items;")
cursor.execute("DROP TABLE IF EXISTS orders;")
cursor.execute("DROP TABLE IF EXISTS merchandise;")
cursor.execute("DROP TABLE IF EXISTS prospects;")
cursor.execute("DROP TABLE IF EXISTS workers;")
cursor.execute("DROP TABLE IF EXISTS departments;")
# Create richer instance tables
cursor.execute("""
CREATE TABLE merchandise (
product_id INTEGER PRIMARY KEY,
product_name TEXT,
class TEXT,
value REAL
);
""")
cursor.execute("""
CREATE TABLE prospects (
customer_id INTEGER PRIMARY KEY,
title TEXT,
e mail TEXT,
nation TEXT,
signup_date TEXT
);
""")
cursor.execute("""
CREATE TABLE orders (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER,
order_date TEXT,
total_amount REAL,
FOREIGN KEY(customer_id) REFERENCES prospects(customer_id)
);
""")
cursor.execute("""
CREATE TABLE order_items (
order_item_id INTEGER PRIMARY KEY,
order_id INTEGER,
product_id INTEGER,
amount INTEGER,
value REAL,
FOREIGN KEY(order_id) REFERENCES orders(order_id),
FOREIGN KEY(product_id) REFERENCES merchandise(product_id)
);
""")
cursor.execute("""
CREATE TABLE workers (
employee_id INTEGER PRIMARY KEY,
title TEXT,
department_id INTEGER,
hire_date TEXT
);
""")
cursor.execute("""
CREATE TABLE departments (
department_id INTEGER PRIMARY KEY,
department_name TEXT
);
""")
# Populate with mock information
cursor.executemany("INSERT INTO merchandise VALUES (?, ?, ?, ?);", [
(1, 'Widget A', 'Widgets', 25.0),
(2, 'Widget B', 'Widgets', 30.0),
(3, 'Gadget X', 'Gadgets', 45.0),
(4, 'Gadget Y', 'Gadgets', 50.0),
(5, 'Thingamajig', 'Tools', 15.0)
])
cursor.executemany("INSERT INTO prospects VALUES (?, ?, ?, ?, ?);", [
(1, 'Alice', '[email protected]', 'USA', '2023-10-01'),
(2, 'Bob', '[email protected]', 'Canada', '2023-11-15'),
(3, 'Charlie', '[email protected]', 'USA', '2024-01-10'),
(4, 'Diana', '[email protected]', 'UK', '2024-02-20')
])
cursor.executemany("INSERT INTO orders VALUES (?, ?, ?, ?);", [
(1, 1, '2024-04-03', 100.0),
(2, 2, '2024-04-12', 150.0),
(3, 1, '2024-04-15', 120.0),
(4, 3, '2024-04-20', 180.0),
(5, 4, '2024-04-28', 170.0)
])
cursor.executemany("INSERT INTO order_items VALUES (?, ?, ?, ?, ?);", [
(1, 1, 1, 2, 25.0),
(2, 1, 2, 1, 30.0),
(3, 2, 3, 2, 45.0),
(4, 3, 4, 1, 50.0),
(5, 4, 5, 3, 15.0),
(6, 5, 1, 1, 25.0)
])
cursor.executemany("INSERT INTO workers VALUES (?, ?, ?, ?);", [
(1, 'Eve', 1, '2022-01-15'),
(2, 'Frank', 2, '2021-07-23'),
(3, 'Grace', 1, '2023-03-10')
])
cursor.executemany("INSERT INTO departments VALUES (?, ?);", [
(1, 'Sales'),
(2, 'Engineering'),
(3, 'HR')
])
conn.commit()
conn.shut()
def run_query(question):
attempt:
conn = sqlite3.join(DB_PATH)
df = pd.read_sql_query(question, conn)
conn.shut()
return df.head().to_string(index=False)
besides Exception as e:
return f"Question failed: {e}"
def get_db_schema(db_path):
conn = sqlite3.join(db_path)
cursor = conn.cursor()
schema = ""
cursor.execute("SELECT title FROM sqlite_master WHERE sort='desk';")
tables = cursor.fetchall()
for table_name, in tables:
cursor.execute(f"SELECT sql FROM sqlite_master WHERE sort='desk' AND title='{table_name}';")
create_stmt = cursor.fetchone()[0]
schema += create_stmt + ";nn"
conn.shut()
return schema
def get_structured_schema(db_path):
conn = sqlite3.join(db_path)
cursor = conn.cursor()
cursor.execute("SELECT title FROM sqlite_master WHERE sort='desk';")
tables = cursor.fetchall()
strains = ["Available tables and columns:"]
for table_name, in tables:
cursor.execute(f"PRAGMA table_info({table_name})")
columns = [row[1] for row in cursor.fetchall()]
strains.append(f"- {table_name}: {', '.be part of(columns)}")
conn.shut()
return 'n'.be part of(strains)
if __name__ == "__main__":
setup_sample_db()
print("Pattern database created.")LLM’s cost by tokens – easy textual content fragments. For any LLM on the market, there’s a pricing mannequin primarily based on the variety of enter and output tokens, usually billed per million tokens. For a whole pricing checklist of all OpenAI fashions, discuss with their official pricing web page right here. For gpt-4o-mini, the enter tokens price $0.15/M whereas the output tokens price $0.60/M. To course of the full prices for an LLM request, I created the under helper capabilities in helper.py to calculate the full price primarily based on the token utilization in a request.
import re
def extract_token_counts(token_usage_str):
immediate = completion = 0
prompt_match = re.search(r'prompt_tokens=(d+)', token_usage_str)
completion_match = re.search(r'completion_tokens=(d+)', token_usage_str)
if prompt_match:
immediate = int(prompt_match.group(1))
if completion_match:
completion = int(completion_match.group(1))
return immediate, completion
def calculate_gpt4o_mini_cost(prompt_tokens, completion_tokens):
input_cost = (prompt_tokens / 1000) * 0.00015
output_cost = (completion_tokens / 1000) * 0.0006
return input_cost + output_costThe app.py file creates a strong Streamlit software that may enable the person to immediate the SQLite database utilizing pure language. Behind the scenes, my set of CrewAI brokers is ready in movement. After the primary agent generates a SQL question, it’s displayed on the App for the person. The person can have three choices:
- Verify & Evaluate — if the person finds the question acceptable and desires to proceed
- Strive Once more — if the person shouldn’t be glad with the question and desires the agent to generate a brand new question once more
- Abort — if the person desires to cease the method right here
Together with the above choices, the LLM price incurred for this request is proven on the display. As soon as the person clicks the “Verify & Evaluate” button, the SQL question will undergo the subsequent two ranges of evaluation. The reviewer agent optimizes it for correctness and effectivity adopted by the compliance agent that checks for compliance. If the question is compliant, it is going to be executed on the SQLite database. The ultimate outcomes and the cumulative LLM prices incurred in the complete course of are displayed on the app interface. The person shouldn’t be solely in management in the course of the course of however can be cost-conscious.
import streamlit as st
from crew_setup import sql_generator_crew, sql_reviewer_crew, sql_compliance_crew
from utils.db_simulator import get_structured_schema, run_query
import sqlparse
from utils.helper import extract_token_counts, calculate_gpt4o_mini_cost
DB_PATH = "information/sample_db.sqlite"
# Cache the schema, however enable clearing it
@st.cache_data(show_spinner=False)
def load_schema():
return get_structured_schema(DB_PATH)
st.title("SQL Assistant Crew")
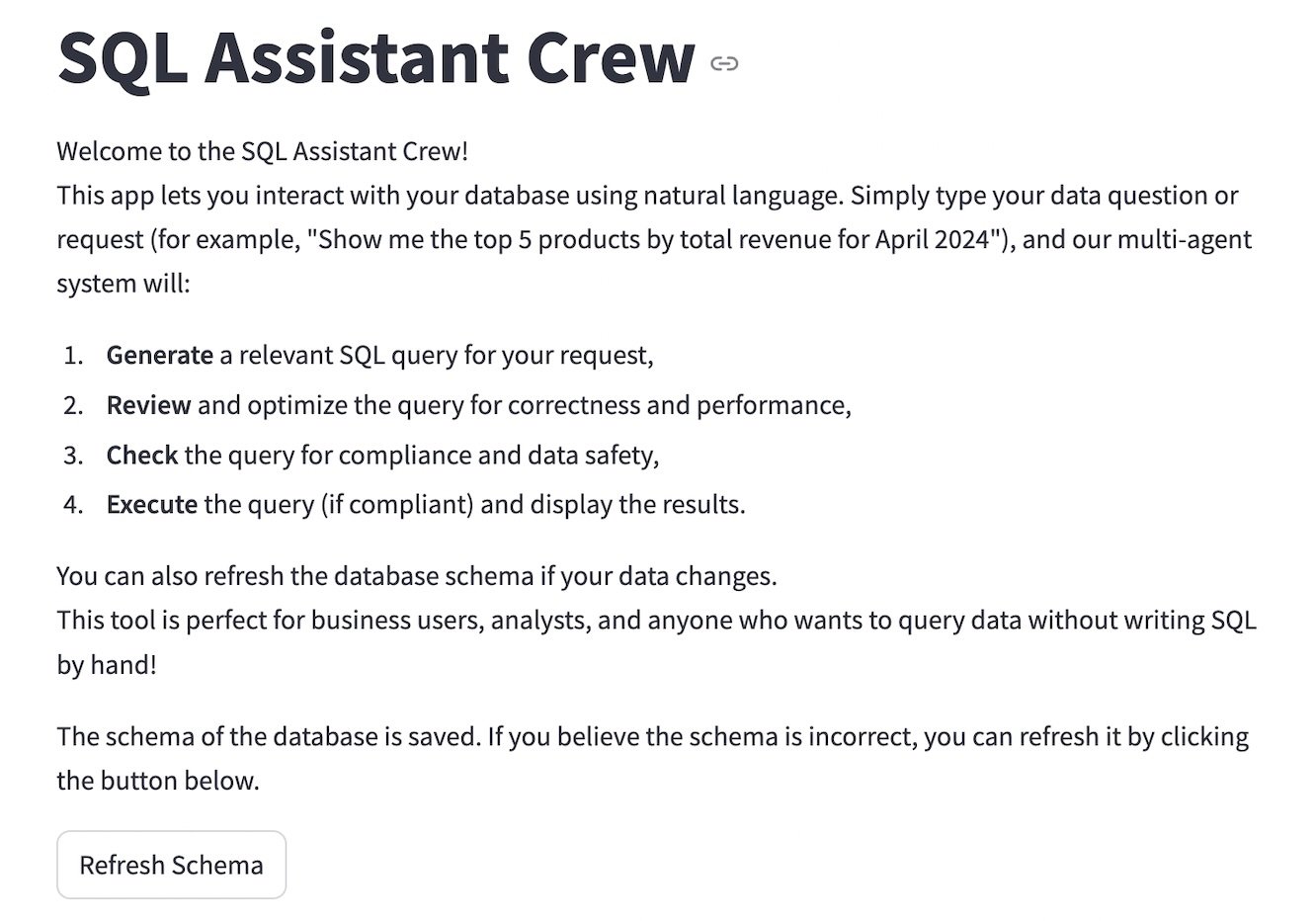
st.markdown("""
Welcome to the SQL Assistant Crew!
This app allows you to work together along with your database utilizing pure language. Merely sort your information query or request (for instance, "Present me the highest 5 merchandise by whole income for April 2024"), and our multi-agent system will:
1. **Generate** a related SQL question to your request,
2. **Evaluate** and optimize the question for correctness and efficiency,
3. **Test** the question for compliance and information security,
4. **Execute** the question (if compliant) and show the outcomes.
You may as well refresh the database schema in case your information modifications.
This software is ideal for enterprise customers, analysts, and anybody who desires to question information with out writing SQL by hand!
""")
st.write("The schema of the database is saved. For those who imagine the schema is wrong, you possibly can refresh it by clicking the button under.")
# Add a refresh button
if st.button("Refresh Schema"):
load_schema.clear() # Clear the cache so subsequent name reloads from DB
st.success("Schema refreshed from database.")
# At all times get the (presumably cached) schema
db_schema = load_schema()
with st.expander("Present database schema"):
st.code(db_schema)
st.write("Enter your request in pure language and let the crew generate, evaluation, and test compliance for the SQL question.")
if "generated_sql" not in st.session_state:
st.session_state["generated_sql"] = None
if "awaiting_confirmation" not in st.session_state:
st.session_state["awaiting_confirmation"] = False
if "reviewed_sql" not in st.session_state:
st.session_state["reviewed_sql"] = None
if "compliance_report" not in st.session_state:
st.session_state["compliance_report"] = None
if "query_result" not in st.session_state:
st.session_state["query_result"] = None
if "regenerate_sql" not in st.session_state:
st.session_state["regenerate_sql"] = False
if "llm_cost" not in st.session_state:
st.session_state["llm_cost"] = 0.0
user_prompt = st.text_input("Enter your request (e.g., 'Present me the highest 5 merchandise by whole income for April 2024'):")
# Mechanically regenerate SQL if 'Strive Once more' was clicked
if st.session_state.get("regenerate_sql"):
if user_prompt.strip():
attempt:
gen_output = sql_generator_crew.kickoff(inputs={"user_input": user_prompt, "db_schema": db_schema})
raw_sql = gen_output.pydantic.sqlquery
st.session_state["generated_sql"] = raw_sql
st.session_state["awaiting_confirmation"] = True
st.session_state["reviewed_sql"] = None
st.session_state["compliance_report"] = None
st.session_state["query_result"] = None
# LLM price monitoring
token_usage_str = str(gen_output.token_usage)
prompt_tokens, completion_tokens = extract_token_counts(token_usage_str)
price = calculate_gpt4o_mini_cost(prompt_tokens, completion_tokens)
st.session_state["llm_cost"] += price
st.data(f"Your LLM price up to now: ${st.session_state['llm_cost']:.6f}")
besides Exception as e:
st.error(f"An error occurred: {e}")
else:
st.warning("Please enter a immediate.")
st.session_state["regenerate_sql"] = False
# Step 1: Generate SQL
if st.button("Generate SQL"):
if user_prompt.strip():
attempt:
gen_output = sql_generator_crew.kickoff(inputs={"user_input": user_prompt, "db_schema": db_schema})
# st.write(gen_output) # Optionally hold for debugging
raw_sql = gen_output.pydantic.sqlquery
st.session_state["generated_sql"] = raw_sql
st.session_state["awaiting_confirmation"] = True
st.session_state["reviewed_sql"] = None
st.session_state["compliance_report"] = None
st.session_state["query_result"] = None
# LLM price monitoring
token_usage_str = str(gen_output.token_usage)
prompt_tokens, completion_tokens = extract_token_counts(token_usage_str)
price = calculate_gpt4o_mini_cost(prompt_tokens, completion_tokens)
st.session_state["llm_cost"] += price
besides Exception as e:
st.error(f"An error occurred: {e}")
else:
st.warning("Please enter a immediate.")
# Solely present immediate and generated SQL when awaiting affirmation
if st.session_state.get("awaiting_confirmation") and st.session_state.get("generated_sql"):
st.subheader("Generated SQL")
formatted_generated_sql = sqlparse.format(st.session_state["generated_sql"], reindent=True, keyword_case='higher')
st.code(formatted_generated_sql, language="sql")
st.data(f"Your LLM price up to now: ${st.session_state['llm_cost']:.6f}")
col1, col2, col3 = st.columns(3)
with col1:
if st.button("Verify and Evaluate"):
attempt:
# Step 2: Evaluate SQL
review_output = sql_reviewer_crew.kickoff(inputs={"sql_query": st.session_state["generated_sql"],"db_schema": db_schema})
reviewed_sql = review_output.pydantic.reviewed_sqlquery
st.session_state["reviewed_sql"] = reviewed_sql
# LLM price monitoring for reviewer
token_usage_str = str(review_output.token_usage)
prompt_tokens, completion_tokens = extract_token_counts(token_usage_str)
price = calculate_gpt4o_mini_cost(prompt_tokens, completion_tokens)
st.session_state["llm_cost"] += price
# Step 3: Compliance Test
compliance_output = sql_compliance_crew.kickoff(inputs={"reviewed_sqlquery": reviewed_sql})
compliance_report = compliance_output.pydantic.report
# LLM price monitoring for compliance
token_usage_str = str(compliance_output.token_usage)
prompt_tokens, completion_tokens = extract_token_counts(token_usage_str)
price = calculate_gpt4o_mini_cost(prompt_tokens, completion_tokens)
st.session_state["llm_cost"] += price
# Take away duplicate header if current
strains = compliance_report.splitlines()
if strains and features[0].strip().decrease().startswith("# compliance report"):
compliance_report = "n".be part of(strains[1:]).lstrip()
st.session_state["compliance_report"] = compliance_report
# Solely execute if compliant
if "compliant" in compliance_report.decrease():
consequence = run_query(reviewed_sql)
st.session_state["query_result"] = consequence
else:
st.session_state["query_result"] = None
st.session_state["awaiting_confirmation"] = False
st.data(f"Your LLM price up to now: ${st.session_state['llm_cost']:.6f}")
st.rerun()
besides Exception as e:
st.error(f"An error occurred: {e}")
with col2:
if st.button("Strive Once more"):
st.session_state["generated_sql"] = None
st.session_state["awaiting_confirmation"] = False
st.session_state["reviewed_sql"] = None
st.session_state["compliance_report"] = None
st.session_state["query_result"] = None
st.session_state["regenerate_sql"] = True
st.rerun()
with col3:
if st.button("Abort"):
st.session_state.clear()
st.rerun()
# After evaluation, solely present reviewed SQL, compliance, and consequence
elif st.session_state.get("reviewed_sql"):
st.subheader("Reviewed SQL")
formatted_sql = sqlparse.format(st.session_state["reviewed_sql"], reindent=True, keyword_case='higher')
st.code(formatted_sql, language="sql")
st.subheader("Compliance Report")
st.markdown(st.session_state["compliance_report"])
if st.session_state.get("query_result"):
st.subheader("Question Outcome")
st.code(st.session_state["query_result"])
# LLM price show on the backside
st.data(f"Your LLM price up to now: ${st.session_state['llm_cost']:.6f}")Here’s a fast demo of the app in motion. I requested it to show the highest merchandise primarily based on whole gross sales. The assistant generated a SQL question, and I clicked on “Verify and Evaluate”. The question was already nicely optimised so the Reviewer agent returned the identical question with none modifications. Subsequent, the Compliance Test agent reviewed the question and confirmed it was secure to run — no dangerous operations or publicity of delicate information. After passing the 2 critiques, the question was run in opposition to the pattern database and the outcomes have been displayed. For this complete course of, the LLM utilization price was simply $0.001349.

Right here’s one other instance the place I ask the app to establish which merchandise have essentially the most returns. Nevertheless, there isn’t a data within the schema about returns. Consequently, the assistant doesn’t generate a question and states the identical motive. Until this stage, the LLM price was $0.00853. Since there’s no level in reviewing or executing a non-existent question, I merely clicked “Abort” to finish the method gracefully.

CrewAI is extremely highly effective for constructing multi-agent programs. By pairing it with Streamlit, one can simply create a easy interactive UI on high to work with the system. On this POC, I explored the best way to add a human-in-loop component to take care of management and transparency all through the workflow. I additionally tracked what number of tokens have been consumed at every step serving to the person keep cost-conscious in the course of the course of. With the assistance of a compliance agent, I enforced some fundamental security measures by blocking dangerous or PII-exposure-related queries. I tuned the temperature of the mannequin and iteratively refined the duty descriptions to enhance the output high quality and scale back hallucinations. Is it excellent? The reply is not any. There are nonetheless some instances when the system hallucinates. If I implement this at scale, then the LLM price could be an even bigger concern. In actual life, the databases are advanced, and as such their schema may also be big. I must discover working with RAG (Retrieval Augmented Era) to feed solely related schema snippets to the LLM, optimizing agent reminiscence, and utilizing caching to keep away from redundant API calls.
Closing Ideas
This was a enjoyable venture that mixes the facility of LLMs, the practicality of Streamlit, and the modular intelligence of CrewAI. For those who’re all in favour of constructing clever brokers for information interplay, give it a attempt — or fork the repo and construct on it!
Earlier than you go…
Observe me so that you don’t miss any new posts I write in future; you will see extra of my articles on my profile web page. You may as well join with me on LinkedIn or X!















{kind=link}