


the quantity of Knowledge rising exponentially in the previous few years, one of many largest challenges has turn out to be discovering essentially the most optimum method to retailer numerous knowledge flavors. Not like within the (not to date) previous, when relational databases have been thought of the one method to go, organizations now wish to carry out evaluation over uncooked knowledge – consider social media sentiment evaluation, audio/video recordsdata, and so forth – which often couldn’t be saved in a standard (relational) manner, or storing them in a standard manner would require vital time and effort, which enhance the general time-for-analysis.
One other problem was to someway follow a standard strategy to have knowledge saved in a structured manner, however with out the need to design complicated and time-consuming ETL workloads to maneuver this knowledge into the enterprise knowledge warehouse. Moreover, what if half of the info professionals in your group are proficient with, let’s say, Python (knowledge scientists, knowledge engineers), and the opposite half (knowledge engineers, knowledge analysts) with SQL? Would you insist that “Pythonists” be taught SQL? Or, vice-versa?
Or, would you like a storage possibility that may play to the strengths of your complete knowledge workforce? I’ve excellent news for you – one thing like this has already existed since 2013, and it’s referred to as Apache Parquet!
Parquet file format in a nutshell
Earlier than I present you the ins and outs of the Parquet file format, there are (not less than) 5 primary explanation why Parquet is taken into account a de facto commonplace for storing knowledge these days:
- Knowledge compression – by making use of numerous encoding and compression algorithms, Parquet file offers diminished reminiscence consumption
- Columnar storage – that is of paramount significance in analytic workloads, the place quick knowledge learn operation is the important thing requirement. However, extra on that later within the article…
- Language agnostic – as already talked about beforehand, builders might use completely different programming languages to govern the info within the Parquet file
- Open-source format – that means, you aren’t locked with a selected vendor
- Help for complicated knowledge varieties
Row-store vs Column-store
We’ve already talked about that Parquet is a column-based storage format. Nevertheless, to grasp the advantages of utilizing the Parquet file format, we first want to attract the road between the row-based and column-based methods of storing the info.
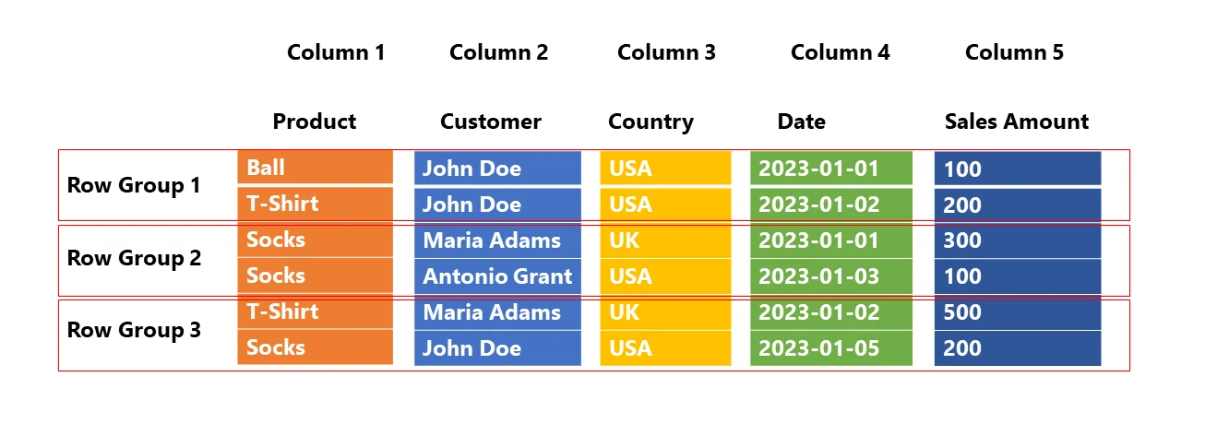
In conventional, row-based storage, the info is saved as a sequence of rows. One thing like this:

Now, after we are speaking about OLAP situations, among the widespread questions that your customers might ask are:
- What number of balls did we promote?
- What number of customers from the USA purchased a T-shirt?
- What’s the whole quantity spent by buyer Maria Adams?
- What number of gross sales did we now have on January 2nd?
To have the ability to reply any of those questions, the engine should scan every row from the start to the very finish! So, to reply the query: what number of customers from the USA purchased T-shirt, the engine has to do one thing like this:

Basically, we simply want the knowledge from two columns: Product (T-Shirts) and Nation (USA), however the engine will scan all 5 columns! This isn’t essentially the most environment friendly answer – I believe we are able to agree on that…
Column retailer
Let’s now look at how the column retailer works. As chances are you’ll assume, the strategy is 180 levels completely different:

On this case, every column is a separate entity – that means, every column is bodily separated from different columns! Going again to our earlier enterprise query: the engine can now scan solely these columns which might be wanted by the question (Product and nation), whereas skipping scanning the pointless columns. And, typically, this could enhance the efficiency of the analytical queries.
Okay, that’s good, however the column retailer existed earlier than Parquet and it nonetheless exists exterior of Parquet as properly. So, what’s so particular concerning the Parquet format?
Parquet is a columnar format that shops the info in row teams
Wait, what?! Wasn’t it difficult sufficient even earlier than this? Don’t fear, it’s a lot simpler than it sounds 🙂
Let’s return to our earlier instance and depict how Parquet will retailer this identical chunk of knowledge:

Let’s cease for a second and clarify the illustration above, as that is precisely the construction of the Parquet file (some extra issues have been deliberately omitted, however we are going to come quickly to elucidate that as properly). Columns are nonetheless saved as separate items, however Parquet introduces extra buildings, referred to as Row group.
Why is this extra construction tremendous vital?
You’ll want to attend for a solution for a bit :). In OLAP situations, we’re primarily involved with two ideas: projection and predicate(s). Projection refers to a SELECT assertion in SQL language – which columns are wanted by the question. Again to our earlier instance, we want solely the Product and Nation columns, so the engine can skip scanning the remaining ones.
Predicate(s) consult with the WHERE clause in SQL language – which rows fulfill standards outlined within the question. In our case, we’re inquisitive about T-Shirts solely, so the engine can utterly skip scanning Row group 2, the place all of the values within the Product column equal socks!

Let’s rapidly cease right here, as I would like you to understand the distinction between numerous forms of storage by way of the work that must be carried out by the engine:
- Row retailer – the engine must scan all 5 columns and all 6 rows
- Column retailer – the engine must scan 2 columns and all 6 rows
- Column retailer with row teams – the engine must scan 2 columns and 4 rows
Clearly, that is an oversimplified instance, with solely 6 rows and 5 columns, the place you’ll undoubtedly not see any distinction in efficiency between these three storage choices. Nevertheless, in actual life, once you’re coping with a lot bigger quantities of knowledge, the distinction turns into extra evident.
Now, the truthful query could be: how does Parquet “know” which row group to skip/scan?
Parquet file comprises metadata
Which means each Parquet file comprises “knowledge about knowledge” – data reminiscent of minimal and most values in a selected column inside a sure row group. Moreover, each Parquet file comprises a footer, which retains the details about the format model, schema data, column metadata, and so forth. You’ll find extra particulars about Parquet metadata varieties right here.
Essential: So as to optimize the efficiency and get rid of pointless knowledge buildings (row teams and columns), the engine first must “get acquainted” with the info, so it first reads the metadata. It’s not a gradual operation, nevertheless it nonetheless requires a sure period of time. Subsequently, in case you’re querying the info from a number of small Parquet recordsdata, question efficiency can degrade, as a result of the engine must learn metadata from every file. So, you need to be higher off merging a number of smaller recordsdata into one greater file (however nonetheless not too huge :)…
I hear you, I hear you: Nikola, what’s “small” and what’s “huge”? Sadly, there isn’t any single “golden” quantity right here, however for instance, Microsoft Azure Synapse Analytics recommends that the person Parquet file ought to be not less than a couple of hundred MBs in dimension.
What else is in there?
Here’s a simplified, high-level illustration of the Parquet file format:

Can it’s higher than this? Sure, with knowledge compression
Okay, we’ve defined how skipping the scan of the pointless knowledge buildings (row teams and columns) might profit your queries and enhance the general efficiency. However, it’s not solely about that – bear in mind after I informed you on the very starting that one of many primary benefits of the Parquet format is the diminished reminiscence footprint of the file? That is achieved by making use of numerous compression algorithms.
I’ve already written about numerous knowledge compression varieties in Energy BI (and the Tabular mannequin generally) right here, so possibly it’s a good suggestion to begin by studying this text.
There are two primary encoding varieties that allow Parquet to compress the info and obtain astonishing financial savings in area:
- Dictionary encoding – Parquet creates a dictionary of the distinct values within the column, and afterward replaces “actual” values with index values from the dictionary. Going again to our instance, this course of appears one thing like this:

You would possibly assume: why this overhead, when product names are fairly brief, proper? Okay, however now think about that you just retailer the detailed description of the product, reminiscent of: “Lengthy arm T-Shirt with utility on the neck”. And, now think about that you’ve got this product bought million occasions…Yeah, as a substitute of getting million occasions repeating worth “Lengthy arm…bla bla”, the Parquet will retailer solely the Index worth (integer as a substitute of textual content).
Can it’s higher than THIS?! Sure, with the Delta Lake file format
Okay, what the heck is now a Delta Lake format?! That is the article about Parquet, proper?
So, to place it in plain English: Delta Lake is nothing else however the Parquet format “on steroids”. After I say “steroids”, the primary one is the versioning of Parquet recordsdata. It additionally shops a transaction log to allow monitoring all modifications utilized to the Parquet file. That is often known as ACID-compliant transactions.
Because it helps not solely ACID transactions, but in addition helps time journey (rollbacks, audit trails, and so forth.) and DML (Knowledge Manipulation Language) statements, reminiscent of INSERT, UPDATE and DELETE, you received’t be flawed in case you consider the Delta Lake as a “knowledge warehouse on the info lake” (who mentioned: Lakehouse😉😉😉). Analyzing the professionals and cons of the Lakehouse idea is out of the scope of this text, however in case you’re curious to go deeper into this, I counsel you learn this text from Databricks.
Conclusion
We evolve! Identical as we, the info can also be evolving. So, new flavors of knowledge required new methods of storing it. The Parquet file format is likely one of the most effective storage choices within the present knowledge panorama, because it offers a number of advantages – each by way of reminiscence consumption, by leveraging numerous compression algorithms, and quick question processing by enabling the engine to skip scanning pointless knowledge.
Thanks for studying!

















{kind=link}