


1. Introduction
Ever for the reason that introduction of the self-attention mechanism, Transformers have been the best choice in the case of Pure Language Processing (NLP) duties. Self-attention-based fashions are extremely parallelizable and require considerably fewer parameters, making them far more computationally environment friendly, much less vulnerable to overfitting, and simpler to fine-tune for domain-specific duties [1]. Moreover, the important thing benefit of transformers over previous fashions (like RNN, LSTM, GRU and different neural-based architectures that dominated the NLP area previous to the introduction of Transformers) is their potential to course of enter sequences of any size with out dropping context, by using the self-attention mechanism that focuses on completely different components of the enter sequence, and the way these components work together with different components of the sequence, at completely different instances [2]. Due to these qualities, Transformers has made it doable to coach language fashions of unprecedented dimension, with greater than 100B parameters, paving the best way for the present state-of-the-art superior fashions just like the Generative Pre-trained Transformer (GPT) and the Bidirectional Encoder Representations from Transformers (BERT) [1].
Nevertheless, within the discipline of laptop imaginative and prescient, convolutional neural networks or CNNs, stay dominant in most, if not all, laptop imaginative and prescient duties. Whereas there was an rising assortment of analysis work that makes an attempt to implement self-attention-based architectures to carry out laptop imaginative and prescient duties, only a few has reliably outperformed CNNs with promising scalability [3]. The principle problem with integrating the transformer structure with image-related duties is that, by design, the self-attention mechanism, which is the core part of transformers, has a quadratic time complexity with respect to sequence size, i.e. O(n2), as proven in Desk I and as mentioned additional in Half 2.1. That is often not an issue for NLP duties that use a comparatively small variety of tokens per enter sequence (e.g., a 1,000-word paragraph will solely have 1,000 enter tokens, or just a few extra if sub-word items are used as tokens as an alternative of full phrases). Nevertheless, in laptop imaginative and prescient, the enter sequence (the picture) can have a token dimension with orders of magnitude better than that of NLP enter sequences. For instance, a comparatively small 300 x 300 x 3 picture can simply have as much as 270,000 tokens and require a self-attention map with as much as 72.9 billion parameters (270,0002) when self-attention is utilized naively.

For that reason, a lot of the analysis work that try to make use of self-attention-based architectures to carry out laptop imaginative and prescient duties did so both by making use of self-attention domestically, utilizing transformer blocks together with CNN layers, or by solely changing particular parts of the CNN structure whereas sustaining the general construction of the community; by no means by solely utilizing a pure transformer [3]. The objective of Dr. Dosovitskiy, et. al. of their work, “An Picture is Value 16×16 Phrases: Transformers for Picture Recognition at Scale”, is to point out that it’s certainly doable to implement picture classification by making use of self-attention globally by using the fundamental Transformer encoder architure, whereas on the similar time requiring considerably much less computational assets to coach, and outperforming state-of-the-art convolutional neural networks like ResNet.
2. The Transformer
Transformers, launched within the paper titled “Consideration is All You Want” by Vaswani et al. in 2017, are a category of neural community architectures which have revolutionized varied pure language processing and machine studying duties. A excessive stage view of its structure is proven in Fig. 1.

and decoder parts (proper block) [2]
Since its introduction, transformers have served as the muse for a lot of state-of-the-art fashions in NLP; together with BERT, GPT, and extra. Basically, they’re designed to course of sequential information, reminiscent of textual content information, with out the necessity for recurrent or convolutional layers [2]. They obtain this by relying closely on a mechanism known as self-attention.
The self-attention mechanism is a key innovation launched within the paper that enables the mannequin to seize relationships between completely different components in a given sequence by weighing the significance of every component within the sequence with respect to different components [2]. Say as an illustration, you wish to translate the next sentence:
“The animal didn’t cross the road as a result of it was too drained.”
What does the phrase “it” on this explicit sentence check with? Is it referring to the road or the animal? For us people, this can be a trivial query to reply. However for an algorithm, this may be thought-about a posh activity to carry out. Nevertheless, by the self-attention mechanism, the transformer mannequin is ready to estimate the relative weight of every phrase with respect to all the opposite phrases within the sentence, permitting the mannequin to affiliate the phrase “it” with “animal” within the context of our given sentence [4].

2.1. The Self-Consideration Mechanism
A transformer transforms a given enter sequence by passing every component by an encoder (or a stack of encoders) and a decoder (or a stack of decoders) block, in parallel [2]. Every encoder block accommodates a self-attention block and a feed ahead neural community. Right here, we solely concentrate on the transformer encoder block as this was the part utilized by Dosovitskiy et al. of their Imaginative and prescient Transformer picture classification mannequin.
As is the case with normal NLP purposes, step one within the encoding course of is to show every enter phrase right into a vector utilizing an embedding layer which converts our textual content information right into a vector that represents our phrase within the vector house whereas retaining its contextual info. We then compile these particular person phrase embedding vectors right into a matrix X, the place every row i represents the embedding of every component i within the enter sequence. Then, we create three units of vectors for every component within the enter sequence; particularly, Key (Okay), Question (Q), and Worth (V). These units are derived by multiplying matrix X with the corresponding trainable weight matrices WQ, WK, and WV [2].

Afterwards, we carry out a matrix multiplication between Okay and Q, divide the consequence by the square-root of the dimensionality of Okay: ![]() …after which apply a softmax operate to normalize the output and generate weight values between 0 and 1 [2].
…after which apply a softmax operate to normalize the output and generate weight values between 0 and 1 [2].
We’ll name this middleman output the consideration issue. This issue, proven in Eq. 4, represents the load that every component within the sequence contributes to the calculation of the eye worth on the present place (phrase being processed). The thought behind the softmax operation is to amplify the phrases that the mannequin thinks are related to the present place, and attenuate those which can be irrelevant. For instance, in Fig. 3, the enter sentence “He later went to report Malaysia for one yr” is handed right into a BERT encoder unit to generate a heatmap that illustrates the contextual relationship of every phrase with one another. We will see that phrases which can be deemed contextually related produce increased weight values of their respective cells, visualized in a darkish pink coloration, whereas phrases which can be contextually unrelated have low weight values, represented in pale pink.

Lastly, we multiply the eye issue matrix to the worth matrix V to compute the aggregated self-attention worth matrix Z of this layer [2], the place every row i in Z represents the eye vector for phrase i in our enter sequence. This aggregated worth primarily bakes the “context” supplied by different phrases within the sentence into the present phrase being processed. The eye equation proven in Eq. 5 is usually additionally known as the Scaled Dot-Product Consideration.
2.2 The Multi-Headed Self-Consideration
Within the paper by Vaswani et. al., the self-attention block is additional augmented with a mechanism often called the “multi-headed” self-attention, proven in Fig 4. The thought behind that is as an alternative of counting on a single consideration mechanism, the mannequin employs a number of parallel consideration “heads” (within the paper, Vaswani et. al. used 8 parallel consideration layers), whereby every of those consideration heads learns completely different relationships and gives distinctive views on the enter sequence [2]. This improves the efficiency of the eye layer in two necessary methods:
First, it expands the power of the mannequin to concentrate on completely different positions inside the sequence. Relying on a number of variations concerned within the initialization and coaching course of, the calculated consideration worth for a given phrase (Eq. 5) will be dominated by different sure unrelated phrases or phrases and even by the phrase itself [4]. By computing a number of consideration heads, the transformer mannequin has a number of alternatives to seize the right contextual relationships, thus changing into extra strong to variations and ambiguities within the enter.Second, since every of our Q, Okay, V matrices are randomly initialized independently throughout all the eye heads, the coaching course of then yields a number of Z matrices (Eq. 5), which provides the transformer a number of illustration subspaces [4]. For instance, one head may concentrate on syntactic relationships whereas one other may attend to semantic meanings. By way of this, the mannequin is ready to seize extra various relationships inside the information.

3. The Imaginative and prescient Transformer
The elemental innovation behind the Imaginative and prescient Transformer (ViT) revolves round the concept photographs will be processed as sequences of tokens somewhat than grids of pixels. In conventional CNNs, enter photographs are analyzed as overlapping tiles by way of a sliding convolutional filter, that are then processed hierarchically by a collection of convolutional and pooling layers. In distinction, ViT treats the picture as a set of non-overlapping patches, that are handled because the enter sequence to a normal Transformer encoder unit.

derived from the Fig. 1 (proper)[3].
By defining the enter tokens to the transformer as non-overlapping picture patches somewhat than particular person pixels, we’re due to this fact capable of cut back the dimension of the eye map from ⟮𝐻 𝓍 𝑊⟯2 to ⟮𝑛𝑝ℎ 𝓍 𝑛𝑝𝑤 ⟯2 given 𝑛𝑝ℎ ≪𝐻 and 𝑛𝑝𝑤≪ 𝑊; the place 𝐻 and 𝑊 are the peak and width of the picture, and 𝑛𝑝ℎ and 𝑛𝑝𝑙 are the variety of patches within the corresponding axes. By doing so, the mannequin is ready to deal with photographs of various sizes with out requiring intensive architectural adjustments [3].
These picture patches are then linearly embedded into lower-dimensional vectors, just like the phrase embedding step that produces matrix X in Half 2.1. Since transformers don’t comprise recurrence nor convolutions, they lack the capability to encode positional info of the enter tokens and are due to this fact permutation invariant [2]. Therefore, as it’s performed in NLP purposes, a positional embedding is appended to every linearly encoded vector previous to enter into the transformer mannequin, with a view to encode the spatial info of the patches, making certain that the mannequin understands the place of every token relative to different tokens inside the picture. Moreover, an additional learnable classifier cls embedding is added to the enter. All of those (the linear embeddings of every 16 x 16 patch, the additional learnable classifier embedding, and their corresponding positional embedding vectors) are handed by a normal Transformer encoder unit as mentioned in Half 2. The output equivalent to the added learnable cls embedding is then used to carry out classification by way of a normal MLP classifer head [3].
4. The Outcome
Within the paper, the 2 largest fashions, ViT-H/14 and ViT-L/16, each pre-trained on the JFT-300M dataset, are in comparison with state-of-the-art CNNs—as proven in Desk II, together with Large Switch (BiT), which employs supervised switch studying with massive ResNets, and Noisy Scholar, a big EfficientNet skilled utilizing semi-supervised studying on ImageNet and JFT-300M with out labels [3]. On the time of this examine’s publication, Noisy Scholar held the state-of-the-art place on ImageNet, whereas BiT-L on the opposite datasets utilized within the paper [3]. All fashions have been skilled in TPUv3 {hardware}, and the variety of TPUv3-core-days that it took to coach every mannequin have been recorded.

We will see from the desk that Imaginative and prescient Transformer fashions pre-trained on the JFT-300M dataset outperforms ResNet-based baseline fashions on all datasets; whereas, on the similar time, requiring considerably much less computational assets (TPUv3-core-days) to pre-train. A secondary ViT-L/16 mannequin was additionally skilled on a a lot smaller public ImageNet-21k dataset, and is proven to additionally carry out comparatively effectively whereas requiring as much as 97% much less computational assets in comparison with state-of-the-art counter components [3].
Fig. 6 exhibits the comparability of the efficiency between the BiT and ViT fashions (measured utilizing the ImageNet Top1 Accuracy metric) throughout completely different pre-training datasets of various sizes. We see that the ViT-Massive fashions underperform in comparison with the bottom fashions on the small datasets like ImageNet, and roughly equal efficiency on ImageNet-21k. Nevertheless, when pre-trained on bigger datasets like JFT-300M, the ViT clearly outperforms the bottom mannequin [3].

Additional exploring how the dimensions of the dataset pertains to mannequin efficiency, the authors skilled the fashions on varied random subsets of the JFT dataset—9M, 30M, 90M, and the complete JFT-300M. Extra regularization was not added on smaller subsets with a view to assess the intrinsic mannequin properties (and never the impact of regularization) [3]. Fig. 7 exhibits that ViT fashions overfit greater than ResNets on smaller datasets. Knowledge exhibits that ResNets carry out higher with smaller pre-training datasets however plateau ahead of ViT; which then outperforms the previous with bigger pre-training. The authors conclude that on smaller datasets, convolutional inductive biases play a key position in CNN mannequin efficiency, which ViT fashions lack. Nevertheless, with massive sufficient information, studying related patterns straight outweighs inductive biases, whereby ViT excels [3].

Lastly, the authors analyzed the fashions’ switch efficiency from JFT-300M vs whole pre-training compute assets allotted, throughout completely different architectures, as proven in Fig. 8. Right here, we see that Imaginative and prescient Transformers outperform ResNets with the identical computational funds throughout the board. ViT makes use of roughly 2-4 instances much less compute to achieve related efficiency as ResNet [3]. Implementing a hybrid mannequin does enhance efficiency on smaller mannequin sizes, however the discrepancy vanishes for bigger fashions, which the authors discover stunning because the preliminary speculation is that the convolutional native characteristic processing ought to be capable to help ViT no matter compute dimension [3].

4.1 What does the ViT mannequin be taught?
To be able to perceive how ViT processes picture information, it is very important analyze its inside representations. In Half 3, we noticed that the enter patches generated from the picture are fed right into a linear embedding layer that initiatives the 16×16 patch right into a decrease dimensional vector house, and its ensuing embedded representations are then appended with positional embeddings. Fig. 9 exhibits that the mannequin certainly learns to encode the relative place of every patch within the picture. The authors used cosine similarity between the discovered positional embeddings throughout patches [3]. Excessive cosine similarity values emerge on related relative space inside the place embedding matrix equivalent to the patch; i.e., the highest proper patch (row 1, col 7) has a corresponding excessive cosine similarity worth (yellow pixels) on the top-right space of the place embedding matrix [3].

In the meantime, Fig. 10 (left) exhibits the highest principal parts of discovered embedding filters which can be utilized to the uncooked picture patches previous to the addition of the positional embeddings. What’s attention-grabbing for me is how related that is to the discovered hidden layer representations that you simply get from Convolutional neural networks, an instance of which is proven in the identical determine (proper) utilizing the AlexNet structure.

The primary layer of filters from AlexNet (proper) [6].
By design, the self-attention mechanism ought to enable ViT to combine info throughout all the picture, even on the lowest layer, successfully giving ViTs a world receptive discipline initially. We will one way or the other see this impact in Fig. 10 the place the discovered embedding filters captured decrease stage options like traces and grids, in addition to increased stage patterns combining traces and coloration blobs. This in distinction with CNNs whose receptive discipline dimension on the lowest layer may be very small (as a result of native utility of the convolution operation solely attends to the world outlined by the filter dimension), and solely widens in the direction of the deeper convolutions as additional purposes of convolutions extract context from the mixed info extracted from decrease layers. The authors additional examined this by measuring the consideration distance which is computed from the “common distance within the picture house throughout which info is built-in based mostly on the eye weights [3].” The outcomes are proven in Fig. 11.

From the determine, we will see that even at very low layers of the community, some heads attend to a lot of the picture already (as indicated by information factors with excessive imply consideration distance worth at decrease values of community depth); thus proving the power of the ViT mannequin to combine picture info globally, even on the lowest layers.
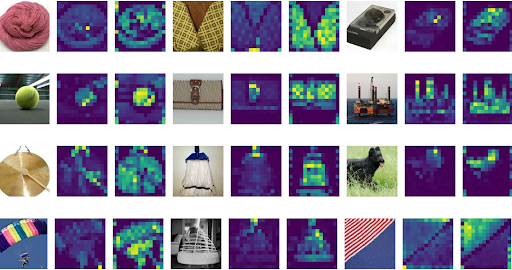
Lastly, the authors additionally calculated the eye maps from the output token to the enter house utilizing Consideration Rollout by averaging the eye weights of the ViT-L/16 throughout all heads after which recursively multiplying the load matrices of all layers. This leads to a pleasant visualization of what the output layer attends to previous to classification, proven in Fig. 12 [3].

5. So, is ViT the way forward for Pc Imaginative and prescient?
The Imaginative and prescient Transformer (ViT) launched by Dosovitskiy et. al. within the analysis examine showcased on this paper is a groundbreaking structure for laptop imaginative and prescient duties. Not like earlier strategies that introduce image-specific biases, ViT treats a picture as a sequence of patches and course of it utilizing a normal Transformer encoder, reminiscent of how Transformers are utilized in NLP. This simple but scalable technique, mixed with pre-training on intensive datasets, has yielded spectacular outcomes as mentioned in Half 4. The Imaginative and prescient Transformer (ViT) both matches or surpasses the state-of-the-art on quite a few picture classification datasets (Fig. 6, 7, and eight), all whereas sustaining cost-effectiveness in pre-training [3].
Nevertheless, like in any know-how, it has its limitations. First, with a view to carry out effectively, ViTs require a really great amount of coaching information that not everybody has entry to within the required scale, particularly when in comparison with conventional CNNs. The authors of the paper used the JFT-300M dataset, which is a limited-access dataset managed by Google [7]. The dominant method to get round that is to make use of the mannequin pre-trained on the big dataset, after which fine-tune it to smaller (downstream) duties. Nevertheless, second, there are nonetheless only a few pre-trained ViT fashions out there as in comparison with the out there pre-trained CNN fashions, which limits the supply of switch studying advantages for these smaller, far more particular laptop imaginative and prescient duties. Third, by design, ViTs course of photographs as sequences of tokens (mentioned in Half 3), which suggests they don’t naturally seize spatial info [3]. Whereas including positional embeddings do assist treatment this lack of spatial context, ViTs could not carry out in addition to CNNs in picture localization duties, given CNNs convolutional layers which can be glorious at capturing these spatial relationships.
Shifting ahead, the authors point out the necessity to additional examine scaling ViTs for different laptop imaginative and prescient duties reminiscent of picture detection and segmentation, in addition to different coaching strategies like self-supervised pre-training [3]. Future analysis could concentrate on making ViTs extra environment friendly and scalable, reminiscent of growing smaller and extra light-weight ViT architectures that may nonetheless ship the identical aggressive efficiency. Moreover, offering higher accessibility by creating and sharing a wider vary of pre-trained ViT fashions for varied duties and domains can additional facilitate the event of this know-how sooner or later.
References
- N. Pogeant, “Transformers - the NLP revolution,” Medium, https://medium.com/mlearning-ai/transformers-the-nlp-revolution-5c3b6123cfb4 (accessed Sep. 23, 2023).
- A. Vaswani, et. al. “Consideration is all you want.” NIPS 2017.
- A. Dosovitskiy, et. al. “An Picture is Value 16×16 Phrases: Transformers for Picture Recognition at Scale,” ICLR 2021.
- X. Wang, G. Chen, G. Qian, P. Gao, X.-Y. Wei, Y. Wang, Y. Tian, and W. Gao, “Massive-scale multi-modal pre-trained fashions: A complete survey,” Machine Intelligence Analysis, vol. 20, no. 4, pp. 447–482, 2023, doi: 10.1007/s11633-022-1410-8.
- H. Wang, “Addressing Syntax-Based mostly Semantic Complementation: Incorporating Entity and Smooth Dependency Constraints into Metonymy Decision”, Scientific Determine on ResearchGate. Out there from: https://www.researchgate.web/determine/Consideration-matrix-visualization-a-weights-in-BERT-Encoding-Unit-Entity-BERT-b_fig5_359215965 [accessed 24 Sep, 2023]
- A. Krizhevsky, et. al. “ImageNet Classification with Deep Convolutional Neural Networks,” NIPS 2012.
- C. Solar, et. al. “Revisiting Unreasonable Effectiveness of Knowledge in Deep Studying Period,” Google Analysis, ICCV 2017.
* ChatGPT, used sparingly to rephrase sure paragraphs for higher grammar and extra concise explanations. All concepts within the report belong to me until in any other case indicated. Chat Reference: https://chat.openai.com/share/165501fe-d06d-424b-97e0-c26a81893c69

















{kind=link}