



reduce their AI inference invoice by greater than half final quarter. Eight weeks of fresh engineering work. It was the win the engineering workforce had been chasing all yr. It was additionally the mistaken optimization. Three months later, buyer satisfaction was dropping, churn was ticking up, and the price financial savings have been structurally tied to the standard loss. We had not gained. We had simply moved the price someplace we weren’t measuring.
That is the sample I anticipate to see throughout manufacturing AI deployments over the subsequent six months. The 2026 dialog round AI economics has produced a consensus playbook. Route easy queries to low cost fashions. Maintain costly queries on succesful fashions. Reduce the invoice, hold the standard. Each CFO has seen the mathematics. Each engineering workforce has constructed it or is constructing it.
The mathematics is actual. The Pareto entice can also be actual.
The piece under is what I informed the workforce after we ran the autopsy. It describes the structure they constructed, the failure mode they walked into, the detection methodology that will have caught it earlier, and the architectural sample they need to have constructed as a substitute. It additionally covers two different deployments I audited after this one, through which the identical sample appeared throughout completely different industries. The mixed proof is that cost-optimization routing layers, within the form the consensus playbook prescribes, are structurally fragile in manufacturing.
What we constructed
The workforce operated a buyer help AI agent for a SaaS product with roughly 4 million month-to-month energetic customers. The agent ran on a single succesful mannequin, the highest-tier reasoning mannequin of their stack on the time of the construct. Inference quantity was excessive sufficient that the month-to-month invoice from their mannequin supplier had grown into six figures and was monitoring upward as adoption scaled.
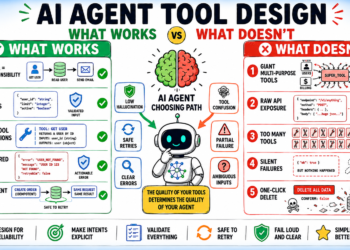
The routing layer was conceptually clear. A small classifier mannequin, custom-trained on roughly 200,000 historic customer-support queries with high quality labels, sat in entrance of the principle agent and labeled every incoming question as both “easy” or “complicated.” Easy queries are routed to a less expensive mannequin in the identical supplier household. Advanced queries continued to path to the succesful mannequin. The classifier itself was a fine-tuned encoder, gentle sufficient to run in underneath 30 milliseconds with negligible price overhead.
The classification taxonomy was constructed from manufacturing commentary. Easy queries have been what the workforce had repeatedly seen: account lookups, billing standing questions, password resets, order monitoring, and hours-of-operation questions. Advanced queries have been those that had traditionally required nuanced, multi-step reasoning: refund disputes, plan-change trade-offs, integration troubleshooting, and billing-cycle anomalies. The cut up appeared like about 65 p.c easy and 35 p.c complicated throughout a consultant week of manufacturing site visitors.
The cheaper mannequin the workforce chosen was a couple of quarter of the per-token price of the succesful mannequin. For the straightforward queries the classifier despatched to it, side-by-side analysis towards the succesful mannequin confirmed equal reply high quality throughout 94 p.c of a 5,000-query holdout set. The 6 p.c hole was seen, however the workforce judged it acceptable given the price discount. They monitored the cheaper mannequin’s high quality by means of their current analysis pipeline, which sampled manufacturing responses for human evaluation at roughly half a p.c of site visitors.
The construct took eight weeks. Three engineers, one ML practitioner, partial allocation. They added schema validation between the classifier and the downstream fashions, instrumentation on the routing determination, and a fallback path in case the classifier itself failed. The deployment was gradual. 5 p.c of site visitors for the primary week, then ten, then twenty-five, then fifty, then full rollout over six weeks. Every rollout step held high quality metrics within the inexperienced vary. Latency stayed inside their current goal. Value decreased in keeping with the routing share.
By the top of week eight, the month-to-month inference invoice had dropped to roughly 40% of its earlier stage. The engineering workforce introduced the work on the firm’s all-hands. The CFO despatched a thank-you observe to the AI workforce. Adoption metrics contained in the agent stayed flat to barely constructive. The workforce moved on to the subsequent quarterly precedence.
The work was stable. The structure was affordable. The monitoring was in place. The workforce had carried out what each current piece on AI price optimization had beneficial. Every particular person determination was defensible. The mixed system, nonetheless, had created a top quality hole that the present measurement structure couldn’t see.
That hole took three months to floor in enterprise metrics and one other month to be accurately attributed. By the point they understood what was occurring, 4 months had elapsed, and the client impression was already within the room.
What we measured (and what we didn’t)
The workforce’s analysis structure earlier than the routing layer was constructed on the idea that they have been working a single mannequin. The standard sign got here from three sources. A day by day human-review pattern of about 200 responses, scored for accuracy and helpfulness. An offline regression suite of roughly 12,000 labeled queries is run weekly towards the manufacturing mannequin. And a satisfaction sign from the agent’s in-product suggestions widget, the place customers might price responses with a thumbs-up or thumbs-down.
When the routing layer went stay, the workforce prolonged the human-review pattern to take care of the identical whole of about 200 day by day evaluations however didn’t separate it by routing tier. They added the cheaper mannequin to the offline regression suite, the place it scored inside their acceptance threshold. They left the in-product suggestions widget unchanged as a result of it had no approach to decide which mannequin had served the response.
On reflection, these three measurement selections have been the seed of the issue. The mixture human-review pattern confirmed high quality holding at roughly the pre-routing baseline. The offline regression suite confirmed the cheaper mannequin passing on its sub-tier. The suggestions widget mixture stayed inside historic variance. Every part they may see was inexperienced.
What they weren’t seeing confirmed up at three completely different layers.
The human-review pattern, taken with out tier-aware sampling, was successfully a weighted common, with 65 p.c of the evaluations on a budget mannequin and 35 p.c on the succesful mannequin. As a result of a budget mannequin was equal within the straightforward instances (the high-volume middle of the simple-query distribution), it pulled the combination up. High quality points on the tougher fringe of the simple-query distribution have been diluted to the purpose of invisibility within the mixture.
The offline regression suite examined each fashions towards curated question units, however the curation was static. It had been constructed six months earlier than deployment, when the workforce had no notion of routing. The suite mirrored an idealized distribution fairly than the precise manufacturing distribution that a budget mannequin now needed to deal with. A budget mannequin handed the static suite however degraded on the stay edge.
The in-product suggestions widget had a structural downside that the workforce had recognized about for over a yr however had not prioritized fixing. Buyer suggestions was sparse. A typical session generated zero rankings. Clients thumbed down responses about 3 instances per 1,000 interactions, and people thumbs-down votes have been skewed towards clients who have been already pissed off about one thing else solely. The signal-to-noise ratio on the widget was too low to detect any change smaller than a significant regression.
None of those failures was particular to the routing layer. They have been latent within the measurement structure. The routing layer merely uncovered them. So long as the system ran on a single mannequin, the measurement gaps didn’t produce false-positive readings, as a result of there was just one high quality distribution to measure. The routing layer launched two high quality distributions, however the current structure couldn’t observe them individually.
The standard drift on the cheap-model tier started in week three after the complete rollout. By week six, the drift was measurable within the regression suite, however the workforce interpreted the small regression as model-version drift from their supplier fairly than routing-related, as a result of they weren’t segmenting their evaluation by tier. By week ten, the cumulative impression on buyer satisfaction was evident in product metrics. By week 13, churn was monitoring measurably above the prior baseline.
That was the purpose at which the workforce referred to as me.
What broke and the way we discovered it
The analysis took two weeks. We reconstructed the routing choices from the instrumentation log, joined them with the in-product suggestions occasions, and constructed a per-tier high quality view that the workforce had not beforehand seen.
The sample surfaced instantly on the cheap-model tier. A budget mannequin was performing properly on roughly 80 p.c of the queries the classifier despatched to it, which matched the equivalent-quality discovering from the unique 5,000-query holdout. However the different 20 p.c in manufacturing have been structurally completely different from the holdout in methods the classifier couldn’t detect at determination time.
The clearest instance was billing queries. The classifier had been educated to acknowledge patterns resembling “the place is my cost from” or “I obtained billed twice” as easy queries, on the idea that account lookup plus bill retrieval was a dependable downstream sample. In holdout testing, this was true. In manufacturing, a nontrivial portion of these billing queries hid extra complicated intents. A person asking “the place is my cost from” was typically asking about an precise fraudulent cost, typically a couple of delayed reconciliation between two techniques, and typically a couple of billing-cycle change that they had not been notified about. The succesful mannequin had been quietly dealing with these nested intents accurately as a result of it had the headroom to comply with the dialog into the complexity. A budget mannequin handled every of them because the surface-level intent and answered a query the client was not truly asking.
The shoppers who obtained these mistaken solutions didn’t at all times thumb down. Lots of them simply disengaged from the agent and referred to as the help line as a substitute. The thumbs-down sign, due to this fact, underrepresented the failure. The price of the failure was shifted to the human help workforce, who dealt with the identical question a second time, with the human price paid out of a distinct price range. The mixture impact was that the AI agent’s measured deflection price remained regular whereas the precise human-handled help quantity started to climb.
The workforce had not linked the rise in human-handled quantity to the routing layer as a result of the 2 groups operated in several price facilities, and the connection was not seen in any single dashboard.
The cumulative impression on buyer satisfaction was tougher to measure cleanly, however it will definitely confirmed up in two methods. First, the cohort of shoppers who interacted with the agent throughout the routing-layer rollout interval confirmed measurably decrease satisfaction scores on the 90-day post-interaction follow-up survey, in comparison with a baseline cohort from earlier than the rollout. Second, buyer retention on the 6-month mark trended downward towards the prior baseline, with the steepest drop in segments most uncovered to the failing routing patterns.
Once we ran the numbers collectively, the inferred price impression of the standard loss was conservatively 4 to 5 instances the price financial savings from the routing layer. The workforce had reduce inference prices by about $100,000 per 30 days and incurred buyer retention and help prices of between $400,000 and $500,000 per 30 days. The mathematics, as soon as seen in full, was unambiguous.
That is the structural property of the Pareto entice. Value financial savings on the inference layer are measured by the workforce that constructed the routing system. The price of high quality loss is borne by the client expertise, the human help workforce, and the retention operate, none of that are owned by the workforce that did the optimization. Every workforce optimizes its personal price range. The mixed optimization is detrimental.
The workforce rolled the routing layer again to a way more conservative setting in week sixteen. By week twenty, the customer-satisfaction development was reversing. By week twenty-eight the retention numbers have been again to baseline. The overall elapsed price of the experiment, between price financial savings recovered and buyer impression incurred, was roughly two quarters of web detrimental product worth.
Why low cost fashions break within the lengthy tail
The rationale this sample is structural fairly than situational is value slowing down on. It isn’t concerning the particular mannequin the workforce selected, the precise supplier, or the precise classifier they educated. It’s concerning the geometry of the issue house.
Buyer queries in any manufacturing AI deployment comply with a power-law distribution of issue. A big mass of queries clusters across the straightforward middle. A smaller mass extends into a protracted tail of tougher, extra ambiguous, extra context-dependent queries. Frontier fashions are over-provisioned for the simple middle. They’ve way more functionality than is required to reply “what time do you open?” That over-provisioning is precisely why the cost-optimization alternative is actual. Routing the simple middle to a less expensive mannequin can yield actual financial savings with out sacrificing high quality on these queries.
The issue is that classifiers can not reliably separate the simple middle from the lengthy tail at determination time. The classifier sees the floor type of a question. The lengthy tail is hidden beneath floor kinds that look straightforward. A question that reads as “the place is my cost from” could be a trivial account lookup or the opening line of a fraud investigation that requires cautious, multi-step reasoning. The classifier sees the identical phrases. A budget mannequin provides the identical floor reply. The shopper within the fraud case receives an incorrect reply to a query they weren’t asking.
That is the long-tail compression downside. Floor type is a poor predictor of the depth of intent for the queries that matter most. The queries the place floor type is most dependable are the simple ones, that are additionally those the place mannequin selection issues least. The queries the place floor type is least dependable are the laborious ones, the place mannequin selection issues most. The classifier is well-calibrated precisely the place it doesn’t have to be, and poorly calibrated precisely the place it does.
There’s a second mechanism. Frontier fashions are likely to have recoverable failure modes. They are going to typically hedge, ask for clarification, or floor their uncertainty in ways in which immediate a human to step in. Smaller fashions usually fail confidently. They produce an entire, believable, surface-coherent response that’s mistaken concerning the precise intent. The mistaken response is tougher for the client to acknowledge as mistaken than a hedged response would have been, which suggests the failure goes unflagged longer.
The third mechanism is drift. Manufacturing question distributions evolve. New merchandise launch. New buyer cohorts are on board. New failure modes emerge. The classifier educated on six months of historic site visitors step by step misroutes a rising share of queries because the distribution shifts away from its coaching set. The fee financial savings stay secure as a result of the routing layer continues to ship site visitors to the cheaper mannequin on the similar price. The standard price grows quietly, as a result of the classifier is more and more mistaken about which queries are literally easy.
The mixed geometry is unforgiving. A budget-model tier handles the simple bulk properly, fails opaquely on the hidden lengthy tail, and degrades additional because the distribution drifts. The financial savings are seen on a dashboard. The fee is paid downstream by individuals who can not see the routing determination.
That is what makes routing layers a Pareto entice fairly than only a noisy optimization. The geometry is structural.
Two different groups I audited after this
After we labored by means of this case, I began searching for the identical sample in different AI deployments I had visibility into. Two surfaced shortly.
The primary was a mid-market SaaS firm with a customer-success AI assistant. Smaller scale than the primary workforce, month-to-month inference spend within the low 5 figures fairly than six. Similar architectural sample. That they had constructed a routing layer 4 months prior that despatched easy queries (outlined by an embedding-similarity classifier fairly than a fine-tuned encoder) to a less expensive mannequin. Value financial savings have been on the order of fifty p.c. High quality metrics on their inner dashboard learn inexperienced.
Once we segmented their suggestions sign by routing tier, the cheap-model tier had a meaningfully decrease satisfaction rating for long-tail queries that the embedding classifier had labeled as easy. The workforce had been blind to the hole as a result of the combination dashboard rolled the 2 tiers right into a single quantity. They estimated the customer-trust impression at roughly two-and-a-half to 3 instances the price financial savings, though their measurement was much less exact than the primary workforce’s. They reverted the routing layer to a a lot smaller share inside a month of the audit.
The second was a regulated-industry case in fintech. Month-to-month inference spend is within the excessive six figures. That they had constructed a extra conservative routing layer that despatched solely what they thought-about “informational” queries (account stability, transaction historical past, primary product info) to a less expensive mannequin, retaining something that touched compliance or monetary choices on the succesful mannequin.
The sample confirmed up in a different way right here. Value financial savings have been decrease as a result of the routing share was extra conservative, at round 20%. However the long-tail failure on the cheap-model tier had compliance implications as a result of some queries that learn as informational truly carried regulatory weight. A buyer asking “what’s my rate of interest” typically had a follow-up query that relied on the primary reply being delivered with precision, which a budget mannequin couldn’t reliably present. The compliance workforce caught it by means of a guide audit earlier than it grew to become a regulatory challenge, however the shut name moved them to roll the routing again solely.
The fintech case was significantly clarifying. It made it apparent that the cost-quality tradeoff isn’t symmetric throughout industries. In buyer help, a mistaken reply is recoverable. In regulated industries, a mistaken reply could be a violation. The Pareto entice is amplified in any context the place long-tail prices are excessive or constrained.
Throughout the three instances, the sample was constant. Value financial savings have been actual and measurable. High quality loss was actual and never measurable by the present structure. The groups that caught the hole caught it months later, after enterprise metrics had absorbed the impression. The groups that didn’t catch it might have continued working net-negative optimizations towards their very own buyer base for so long as the dashboards stayed inexperienced.
Detecting the entice earlier than three months cross
The diagnostic methodology that will have caught any of those earlier is simple, but it surely requires altering the measurement structure earlier than the routing layer goes stay. Three concrete additions to the observability stack.
Per-tier high quality monitoring is the foundational one. Each high quality sign within the current structure should be cut up by routing tier, with the tier label propagated end-to-end by means of the instrumentation. Human-review samples needs to be stratified so that every tier receives proportional or oversampled evaluation. Offline regression suites needs to be cut up into tier-specific subsets and evaluated individually. In-product suggestions occasions needs to be joined with the routing determination log so satisfaction by tier turns into an aggregated dimension. The mixture high quality quantity, by itself, is structurally unable to disclose a tier-specific high quality drift.
Lengthy-tail satisfaction sampling is the second addition. As a result of the long-tail downside is invisible in mixture, the measurement structure has to oversample the lengthy tail to make it seen. This implies sampling extra closely from queries the classifier was least assured about, or from queries that lie outdoors the centroid of the classifier’s coaching distribution. The aim is to not bias the human-review pool towards straightforward queries, as naive sampling does. The aim is to over-weight the queries the place the mannequin selection truly issues.
Routing confidence drift is the third. The classifier itself is a supply of high quality sign that the majority groups don’t monitor. The distribution of confidence scores on manufacturing site visitors needs to be tracked towards the distribution noticed throughout coaching. When the manufacturing distribution shifts, the classifier operates outdoors its calibrated vary, and routing choices develop into more and more unreliable. The drift sign precedes the standard sign by weeks, which is the lead time the workforce must course-correct.
These three additions should not a guidelines to attain your self towards. They’re a measurement structure through which every element reveals a category of failure that the others can not see. Collectively, they make the Pareto entice seen in days fairly than months. The price of implementing them in engineering time is way decrease than the price of working an undetected high quality regression for 1 / 4.
Two notes for groups contemplating this. First, retroactively deploying these measurements is way tougher than constructing them in alongside the routing layer. Doing it earlier than launch prices maybe three engineer-weeks. Doing it after a top quality challenge has emerged usually requires reconstructing information that was not captured. Second, the measurement structure issues greater than the routing determination itself. A workforce with good per-tier observability can experiment safely with aggressive routing as a result of they’ll catch the drift. A workforce with out it can not safely function any routing layer at scale.
What the choice appears like
If the consensus playbook of pre-routing-by-classifier is a Pareto entice, the plain query is what the choice sample is. There’s one, and it’s meaningfully higher, although it carries its personal tradeoffs.
The sample is an uncertainty-routed cascade. As an alternative of pre-classifying a question as easy or complicated earlier than any mannequin touches it, each question begins on the cheaper mannequin. A budget mannequin produces a solution with a calibrated confidence rating, both by means of a built-in uncertainty estimate or by means of an specific self-evaluation step appended to the response. When confidence is excessive, the response goes immediately again to the person. When confidence falls under a threshold, the question is escalated to the succesful mannequin, and its response is delivered.
This sample inverts the failure mode. A budget mannequin now decides for itself fairly than being determined about by a classifier. The laborious queries, which a budget mannequin would have answered wrongly with confidence, as a substitute floor as low-confidence and set off escalation. The costly mannequin handles these instances. The fee profile depends upon a budget mannequin’s confidence distribution, however in our work-through of the customer-support case, the modeled financial savings landed in roughly the identical vary because the pre-routing method, with materially higher high quality within the lengthy tail.
Two enhancements compound with the cascade. Shadow scoring runs the succesful mannequin on a small share of manufacturing site visitors in parallel with a budget mannequin, even when a budget mannequin is assured, to detect drift in actual manufacturing circumstances. High quality-weighted routing incorporates noticed satisfaction sign again into the brink tuning over time, so the cascade adapts because the manufacturing distribution evolves.
The cascade has tradeoffs, the pre-routing method doesn’t. Latency on escalated queries is roughly the sum of cheap-model latency and capable-model latency, which is meaningfully worse than pre-routing would have been. Value is tougher to foretell prematurely as a result of it depends upon the manufacturing confidence distribution. Implementation complexity is reasonably increased as a result of calibrating a budget mannequin’s confidence is itself non-trivial.
These tradeoffs are actual and price weighing. However they’re tradeoffs towards the standard flooring that the cascade method maintains and the pre-routing method doesn’t. In manufacturing deployments the place the lengthy tail carries materials buyer price, the cascade sample is the architecturally trustworthy selection. For groups architecting AI brokers for enterprise automation at significant manufacturing scale, the cascade-with-observability sample is the one which survives 1 / 4 of actual site visitors.
The optimization layer issues greater than the optimization
The primary workforce I described on this piece ultimately obtained to a secure structure that mixed uncertainty-routed cascades with per-tier observability. Their month-to-month inference price settled at roughly 35% under the pre-optimization baseline, which is much less of a financial savings than the pre-routing method had achieved on paper. Their buyer satisfaction returned to pre-experiment ranges. The web product worth of the deployment, accounting for each layers, is meaningfully constructive.
The lesson the workforce took from the expertise was not that price optimization is mistaken. It was that price optimization is a selection about which layer of the system you belief to make the precise tradeoff. Pre-routing trusts a classifier that can’t see what issues. Cascades trusts the mannequin itself to know what it doesn’t know.
A budget optimization is the one which quietly breaks the product. The architecturally trustworthy optimization is the one which survives the lengthy tail. In manufacturing AI, the distinction is normally 1 / 4 of buyer satisfaction.
is Co-Founder and Head of Technique at Intuz. He has spent 18+ years deploying enterprise AI, IoT, and cloud platforms into manufacturing throughout 700+ initiatives. He writes on the economics of AI at scale for practitioners. What works, what fails, and the place the price range truly goes. Primarily based between San Francisco and Ahmedabad.















{kind=link}