


a query that retains arising in funds work: can an LLM agent substitute a gradient-boosted scorer on the synchronous cost authorization path? The query has an affordable form. Brokers are dealing with investigation queues that used to want a senior analyst and 5 dashboards, so it appears like a pure match for scoring the transaction too.
I constructed a small benchmark to reply it. The benchmark runs on a laptop computer. It wants no GPU, no API key, and no cloud account. The supply code is on GitHub at github.com/sandeepmb/fraud-agents-benchmark. Each determine and quantity on this article comes out of the identical Python repo, so you may rerun it and examine the work.
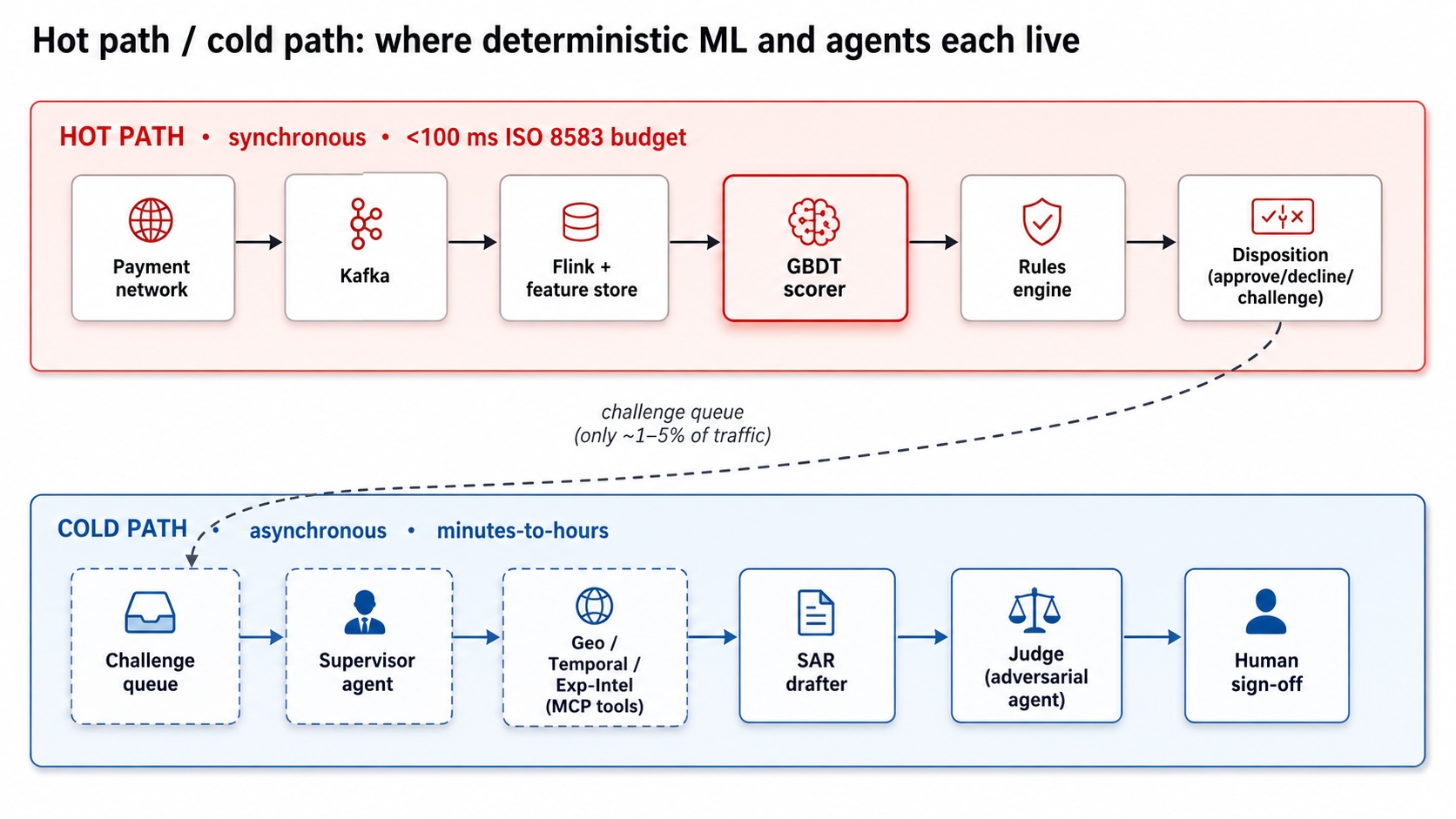
The quick reply is that classical ML nonetheless owns the synchronous sizzling path, and brokers belong within the asynchronous chilly path. The remainder of this text explains the three measurements that draw the road between these two layers, and the hybrid structure I ended up recommending.
TL;DR
- On a single CPU core, the gradient-boosted scorer hits p99 latency of 0.15 ms. A calibrated LLM-latency simulator (not a dwell API) places an LLM scorer at p99 round 1,200 ms. The ISO 8583 authorization finances is roughly 100 ms.
- At 50,000 transactions per second for one hour, the GBDT scorer prices about $54. A gpt-4o-mini-class mannequin prices $16,200. A frontier mannequin (Claude Sonnet 4.6) prices $351,000. These figures assume naked scoring. Agentic reasoning multiplies them.
- On 500 calls with the bit-identical enter, the GBDT returns 1 distinct rating. A non-deterministic LLM returns 498. Hosted LLM inference can keep non-deterministic even when temperature is about to 0, which makes a hot-path scorer onerous to validate in a regulated authorization resolution.
- Brokers do helpful work on the asynchronous chilly path: SAR drafting, proof gathering by MCP-typed instruments, and an agent-as-a-judge cross earlier than human sign-off.
Scope and Limits
4 trustworthy boundaries earlier than the outcomes.
This isn’t a declare that LLMs can not assist fraud groups. The second half of this text is about the place they clearly do. Additionally it is not a comparability towards fine-tuned tabular transformers or deep-learning tabular fashions. The comparability is between a deterministic gradient-boosted scorer and LLM-style scoring in synchronous authorization.
The GBDT path is measured on a neighborhood CPU. The LLM latency path is simulated from a calibrated distribution, not measured towards a dwell API. The price figures are calculated from printed per-token pricing. Determinism is proven two methods: measured domestically for the GBDT, and for the LLM reproduced by the simulator and supported by exterior proof.
| Part | Measured, simulated, or calculated | Why |
| GBDT latency | Measured | Native single-core CPU benchmark |
| LLM latency | Simulated | Calibrated log-normal, no API or GPU dependency |
| Value | Calculated | Printed Might-2026 per-token pricing |
| Determinism | Measured (GBDT) and cited proof (LLM) | Native benchmark plus |
The Setup
I wished a benchmark anybody may rerun with out an A100 or an OpenAI API key. That meant three design selections.
The information is artificial and ISO 8583-shaped. Twenty options per transaction, the sorts of fields a card-not-present hot-path scorer truly sees: quantity, MCC threat, machine age, geo-distance, velocity counters at one-hour and twenty-four-hour home windows, chargeback historical past, and a handful of binary flags. Fraud charge is 1.5%. The generator features a stealth-fraud charge parameter in order that about 15% of fraud rows are drawn from the legit-class distribution. This mirrors subtle mimicry and provides the benchmark an irreducible Bayes-optimal error flooring. With out it, a tree ensemble lands at PR-AUC round 0.999, which might make the entire train look pretend.
# src/fraud_benchmark/knowledge.py (abridged)
def generate(n_rows, fraud_rate=0.015, seed=42, stealth_rate=0.15):
rng = np.random.default_rng(seed)
n_fraud = int(spherical(n_rows * fraud_rate))
n_stealth = int(spherical(n_fraud * stealth_rate))
legit = _draw_class(rng, n_rows - n_fraud, is_fraud=False)
overt = _draw_class(rng, n_fraud - n_stealth, is_fraud=True)
stealth = _draw_class(rng, n_stealth, is_fraud=False) # mimicry
...After coaching a HistGradientBoostingClassifier on 200,000 rows of this distribution, the mannequin lands at PR-AUC 0.847 and ROC-AUC 0.931 on a 50,000-row holdout. These are credible numbers for a manufacturing card-not-present scorer.
The scorer itself makes use of a quick batch=1 path. Calling sklearn’s predict_proba on a single row takes round 14 ms on this laptop computer, dominated by Python validation overhead. That quantity is unrepresentative of XGBoost or LightGBM in manufacturing, so for a good comparability I extracted the educated mannequin’s inner bushes into per-field numpy arrays and wrote a decent traversal. It matches sklearn to float64 precision and runs about 100 instances sooner.
The LLM scorer is simulated. That is the one place the place working every little thing on a laptop computer required calibration moderately than measurement. The simulator samples per-call latency from a log-normal distribution with a 540 ms median and σ =0.35. The calibration attracts on three public sources: NVIDIA Triton’s printed time-to-first-token figures for Llama-3-8B this fall on an A10, vLLM benchmarks for Qwen2.5-7B on an RTX 4090, and the p50 and p99 numbers OpenAI and Anthropic publish for his or her hosted APIs. The simulator additionally produces non-deterministic rating outputs on equivalent inputs, which is what we’d like for the determinism experiment.
With that setup, three experiments.
Break #1: Inference Sits Exterior the ISO 8583 Finances
5 thousand single-transaction calls to the GBDT scorer on one CPU core at batch measurement 1. 4 hundred attracts from the calibrated LLM latency distribution.

The complete measured GBDT distribution sits to the left of the 100 ms ISO 8583 inference finances. The complete sampled LLM distribution sits to the precise. There isn’t any overlap. The p99 of the classical scorer is 0.15 ms. The p99 drawn from the LLM-latency simulator is 1,212 ms. That’s about 8,000 instances the classical p99 and 12 instances the whole authorization finances.
The numbers cease being stunning when you stare at them. A gradient-boosted tree ensemble is doing just a few hundred branching integer comparisons on a numeric characteristic vector. An autoregressive transformer is working a prefill cross on a immediate after which decoding output tokens one by one, with each token requiring a full ahead cross by billions of parameters. These are totally different computational regimes. Quantization and distillation can slim the hole, however they don’t erase the class distinction between a numeric tree traversal and autoregressive token era.
ISO 8583 is the worldwide commonplace for card-originated transaction messaging. It’s synchronous. When a point-of-sale terminal pushes an authorization request, it expects a solution inside a window measured in milliseconds, and most of that window is consumed by issues that aren’t inference.

Community transit, message unpack, feature-store lookup, rules-engine analysis, response meeting. Inference is the one stage that varies by mannequin alternative. Swap a GBDT for an LLM and the spherical journey takes 563 ms as an alternative of 32 ms. That could be a 5x overrun on a finances that was already tight.
The standard response from the LLM camp is “we’ll batch.” You can’t. Synchronous cost authorization means every transaction arrives asynchronously from the community and needs to be scored the moment it exhibits up. Steady batching, the approach that offers trendy GPU inference its throughput, is determined by having many requests in flight that the runtime can coalesce. When each batch accommodates precisely one request, the GPU sits idle many of the cycle and the financial argument collapses too.
Which brings us to the second factor that breaks.
Break #2: The Value Hole Is 200x to six,500x
Fifty thousand transactions per second is an affordable peak determine for a big acquirer throughout a significant retail occasion. I stored the price mannequin intentionally auditable. The LLM tiers are printed per-token pricing instances a set token finances, so each greenback determine reproduces from first rules.
requests/hour = TPS × 3600
price/hour = requests/hour × (prompt_tokens × input_price
+ response_tokens × output_price) / 1,000,000The assumptions are 50,000 TPS, a 400-token immediate, and a 50-token approve/decline reply per scoring name. The small tier is OpenAI gpt-4o-mini at $0.15 per 1M enter tokens and $0.60 per 1M output tokens. The frontier tier is Anthropic Claude Sonnet 4.6 at $3 and $15 respectively. Each at Might-2026 printed costs. The tabular scorers are priced from amortized CPU infrastructure (a c7i.4xlarge spot occasion), not tokens.

LightGBM on commodity CPU runs about $54 per hour. XGBoost is $72. The gpt-4o-mini tier is $16,200. The Claude Sonnet 4.6 tier is $351,000. Even on the small-model flooring, the LLM invoice is roughly 225 instances the tabular price. On the frontier tier it’s about 6,500 instances.
These are the optimistic numbers. Actual agentic reasoning, with device calls, chain-of-thought tokens, and multi-step deliberation, multiplies the output finances by 10 to 50, and the invoice with it. One full agentic investigation per transaction would put the frontier tier within the hundreds of thousands of {dollars} per hour.
The envelope additionally assumes batch=1, which is what synchronous authorization truly seems to be like. GPU economics rely on steady batching throughout many requests in flight. A hosted API amortizes that throughout all of its tenants, however you continue to pay the per-token invoice on the client finish.
That is the place the place the dialog with a vendor stops being about know-how and begins being about arithmetic. A big card issuer processing a billion transactions a day would see its day by day inference invoice go from just a few hundred {dollars} to anyplace from tens of 1000’s to a few million, with no accuracy enchancment. The underlying knowledge is tabular, numeric, and well-structured, which isn’t knowledge {that a} language mannequin has any pure benefit on. Tree ensembles have dominated structured knowledge for years, for causes that haven’t modified.
Break #3: Equivalent Inputs Produce Completely different Outputs
The third break is the one that truly decides whether or not a financial institution can deploy this within the sizzling path, no matter how the primary two evolve.
Financial institution model-risk regulation is constructed on reproducibility. The 2011 Federal Reserve and OCC model-risk steerage (SR 11-7) was outmoded in April 2026 by the interagency Revised Steering on Mannequin Threat Administration, SR 26-2. It requires that fashions driving customer-impacting or examiner-reviewable selections, together with declines, holds, account restrictions, and alert escalation, be independently validated. Meaning examined by goal reviewers who confirm the mannequin’s assumptions and reproduce its outputs on demand. A mannequin that returns totally different solutions to equivalent inputs can not produce that reproducible validation proof.
# src/fraud_benchmark/benchmark.py: determinism experiment
def determinism(scorer, n=500, seed=7):
score_fn = getattr(scorer, "score_only", scorer.score_one)
x = single_payload(seed=seed)
outputs = np.array([float(score_fn(x)) for _ in range(n)])
rounded = np.spherical(outputs, 6)
return DeterminismSummary(
distinct_count=int(np.distinctive(rounded).measurement),
unfold=float(outputs.max() - outputs.min()),
std=float(outputs.std()),
n=n, outputs=outputs,
)5 hundred calls to every scorer with the bit-for-bit equivalent characteristic vector. The GBDT returns the identical float64 rating all 500 instances. The simulated LLM returns 498 distinct outputs with a ramification of 0.51 and a typical deviation of 0.077.

This isn’t a few temperature setting. Set temperature to zero, set the seed, pin the mannequin model, and in a typical hosted or high-throughput deployment you continue to get totally different solutions. The trigger sits beneath the API. Floating-point associativity in GPU kernels is determined by discount order. Steady batching reorders consideration throughout requests. Tensor-parallel collectives use non-deterministic AllReduce on most cluster configurations. The Pondering Machines Lab writeup from September 2025 is the clearest current therapy. It stories dozens of distinct completions from equivalent greedy-decoded requests, and it additionally exhibits the drift may be eradicated with batch-invariant kernels at a throughput price. I decide up that thread on the finish of the article.
For a regulated fraud scorer, that is the center of the issue. If an examiner asks why a selected transaction bought declined, the establishment wants at hand over a reproducible hint. A versioned tree mannequin with a set characteristic vector provides validators a deterministic rating, a rule hint, and a TreeSHAP attribution. That could be a reproducible audit bundle they will regenerate on demand. A non-deterministic LLM output doesn’t give them something they will hand again.
The place Brokers Earn Their Preserve: The Chilly Path
If the recent path belongs to deterministic tree ensembles, what concerning the chilly path, which means the asynchronous work that occurs after a transaction is flagged?
Proof gathering, case triage, narrative writing, SAR submitting, human overview. Latency there may be measured in minutes to hours, not milliseconds. The determinism constraints are softer as a result of a human indicators off earlier than any adversarial motion is taken. The price constraints are totally different as a result of just one to 5 % of transactions ever attain this layer.
That is the form of labor brokers are good at.

The structure I ended up recommending has two bodily separated layers. The recent path is a streaming pipeline. It runs Kafka ingestion, Flink characteristic hydration from an internet characteristic retailer, a GBDT scorer that emits a chance and a TreeSHAP attribution, and a guidelines engine that converts the rating and purpose codes into one in all three selections: approve, decline, or problem. Each transaction passes by this layer. Each resolution is deterministic, auditable, and mathematically reproducible.
Transactions that land within the problem bucket cross to the chilly path by a queue. That’s the place the brokers dwell. A supervisor picks up the alert and dispatches specialists. A geo analyst queries machine and IP historical past by an MCP-typed device. A temporal analyst pulls the account’s velocity baseline. An external-intelligence analyst queries a consortium threat feed. A drafter synthesizes a SAR-ready narrative obeying FinCEN’s 5W+H construction. An adversarial decide cross-references each declare within the draft towards the uncooked proof ledger earlier than the human ever sees it. A human operator indicators off.
In manufacturing, every agent is an LLM name, every MCP device is a typed JSON-RPC consumer towards an actual backend, and the decide cross produces its personal audit path. That path is a documented, impartial overview of each declare, which is the sort of validation proof model-risk steerage expects. The benchmark repository ships a stdlib-only sketch of this orchestration in roughly 200 strains of code, so the form is legible with out standing up an actual LangGraph runtime.
The Decide: Catching Hallucinations Earlier than a Human Sees Them
A very powerful agent within the chilly path is just not the drafter. It’s the decide.
# scripts/cold_path_demo.py (abridged)
def decide(draft, proof, alert):
points = []
evidence_dict = proof.as_dict()
for declare in draft.claims:
resolved = _resolve(evidence_dict, declare.source_key)
if resolved is None:
points.append(f"unresolved source_key {declare.source_key!r}")
proceed
if not _claim_cites_value(declare.textual content, resolved):
points.append(f"declare doesn't cite {resolved!r} from {declare.source_key!r}")
return JudgeVerdict(authorized=len(points) == 0, points=points)The drafter produces a story plus an inventory of structured Declare objects. Every declare carries a dotted source_key like geo.distance_km or exterior.consortium_risk that resolves into the proof ledger the supervisor produced. The decide walks each declare, seems to be up the worth, and refuses approval if both of two issues is fallacious. Both the source_key references proof that was by no means gathered, or the declare textual content doesn’t truly cite the worth it claims to be sourced from.
The benchmark’s check suite crops two flavors of hallucination and verifies the decide catches each. The primary is an unresolved supply key. A declare cites exterior.offshore_bank_flag when no such area exists within the proof dict. The second is worth drift. A declare’s source_key resolves appropriately, however the textual content fabricates a quantity (“99 km aside” when the resolved worth is 7,843 km). Each are blocked. The deliberation log between drafter and decide is itself discoverable proof of the impartial overview that model-risk examiners search for.
That is the agent-as-a-judge sample translated right into a regulated workflow. The sample is common and works for any cold-path agent that has to supply structured output an examiner would possibly later audit. It’s particularly load-bearing right here as a result of the choice is asking analysts to confirm each line of each LLM-drafted SAR by hand. SAR drafting at present consumes hours to days of analyst time per case. A judge-validated agent pipeline compresses that considerably, and the decide is the half that makes the compression secure.
What I Received Incorrect on the Begin
Once I began the benchmark I assumed the case towards brokers on the recent path could be largely about price. Latency and reproducibility turned out to be the larger structural points, and they’re larger as a result of they don’t transfer the best way price does.
Value is a quantity you may transfer. In 2022, 1,000,000 enter tokens on a frontier mannequin price about $30. In 2026, on a comparable frontier mannequin, it prices round $4. One other two orders of magnitude is believable earlier than the tip of the last decade. The hole within the benchmark would shrink. It will not disappear, as a result of the batch=1 constraint neutralizes most GPU economies, however it might shrink.
Latency is tougher to maneuver however not unimaginable. Speculative decoding, Medusa heads, mixture-of-experts pruning, and specialised inference accelerators all chip away at time-to-first-token. A devoted chip working a small distilled fraud-specific mannequin in 30 ms is conceivable inside just a few years.
Reproducibility is the toughest of the three to maneuver in mainstream hosted and high-throughput inference. It’s a property of how GPU arithmetic works on the bare-metal stage and of the software program stack on prime of it. The Pondering Machines Lab work exhibits it’s fixable by deterministic kernels, fastened batching orders, and restricted collectives. The fixes carry an actual throughput price, no hosted API supplier has shipped them by default, and working them your self on-prem erases a significant fraction of the compute effectivity you purchased GPUs for within the first place.
The regulatory image is extra attention-grabbing than a easy prohibition. When the US interagency model-risk steerage was revised in April 2026 (SR 26-2), it explicitly positioned generative and agentic AI exterior its scope, on the grounds that they’re “novel and quickly evolving”. That’s not a inexperienced mild. It means there is no such thing as a settled supervisory playbook for validating a non-deterministic mannequin in a customer-impacting resolution. An establishment that places an LLM on the authorization sizzling path is deploying forward of its personal examiners, whereas nonetheless owing them the identical solutions a tree mannequin may give and an LLM can not. Clarify this decline. Reproduce this rating. Present the validation proof. The EU AI Act factors the identical manner and classifies credit score scoring as a high-risk use of AI, with a particular carve-out for fraud detection. The throughline throughout each regimes is reproducible, independently reviewable mannequin conduct.
My prediction, corresponding to it’s. Latency and value will maintain enhancing for LLM inference, and the authorization-path argument based mostly on these will get weaker 12 months by 12 months. The reproducibility argument is the sturdy one. Placing a non-deterministic scorer in entrance of a customer-impacting resolution in a regulated workflow is difficult to defend. Not as a result of a single rule forbids it, however as a result of the whole model-risk regime is organized round reproducing and independently difficult mannequin outputs, and that’s the one factor a non-deterministic mannequin can not supply. The steerage will maintain evolving to cowl generative and agentic techniques. Reproducibility will nonetheless be the query it asks.
What to Do If You’re Going through This Resolution
Preserve the deterministic scorer on the recent path. XGBoost, LightGBM, or CatBoost educated on tabular options and served from an internet characteristic retailer. Measure your p99 towards a tough finances. If the finances is an issue, spend money on ONNX Runtime or a C++ inference service earlier than you spend money on anything.
Route edge instances to a chilly path. Design the queue as a first-class piece of the structure, not an afterthought. Assume one to 5 % of authorizations will find yourself there.
Construct the chilly path round brokers from day one. Supervisor-plus-specialists with MCP instruments provides you composable proof gathering. Add an agent-as-a-judge cross earlier than something ever reaches a human.
Deal with SAR narrative era because the highest-value first-deployment goal. It’s hours per case of analyst time recovered, the format is well-specified, and the regulator’s standards for acceptable output are specific.
Don’t wire the cold-path brokers into the hot-path resolution. The problem flag is a queue message, not a callback. Preserve the authorization layer bodily impartial.
Instrument the decide cross. The deliberation logs are discoverable proof of impartial overview, and they’re low cost to maintain.
If you wish to rerun the numbers on this article, the repository is at github.com/sandeepmb/fraud-agents-benchmark. Two instructions, python scripts/run_benchmark.py and python scripts/generate_diagrams.py, reproduce each determine on a laptop computer in underneath a minute. The cold-path orchestration sketch is in scripts/cold_path_demo.py. Sixty-four checks cowl the information generator, the quick scorer, the benchmark harness, the figures, and the decide. By yourself {hardware} the hole will look comparable.
All figures created by the writer. The 4 knowledge plots are generated by scripts/generate_diagrams.py within the linked benchmark repository; the structure diagram was designed by the writer in Figma.















{kind=link}