



Ms don’t deserve the basic playbook. Article 3 mentioned there isn’t a THE RAG method. You continue to have to choose one. This text is the diagnostic that tells you which ones.
Most groups constructing RAG programs attain for a similar playbook: parse the doc into chunks, embed each chunk, drop them in a vector retailer, embed the query, retrieve the top-k by cosine similarity, hand the outcome to an LLM. Name it the basic RAG playbook. Each tutorial teaches it. Each demo runs on it.
The precise issues range far more than the playbook suggests. A number of actual instances.
Three instances at three totally different extremes.
Templated, high-volume paperwork. Insurance coverage certificates, KYC kinds, regulatory filings, month-to-month brokerage statements. The identical software program writes the identical structure on each doc. 100 traces of regex extract the fields in microseconds. The basic playbook runs right here too however it pays an LLM to do what the structure gave you without cost.
Similar form throughout industries: payroll stubs, financial institution statements, lab take a look at experiences, tax filings, compliance attestations, provider invoices from one ERP. Wherever one piece of software program writes each doc, the structure is a contract.
Sarcasm in customer-service transcripts. “Discover each sarcastic comment on this month’s name recordings.” Customary sentiment scoring (anger, frustration, pleasure) is essentially solved by a sentiment lexicon: unacceptable, ridiculous, pissed off all flag clearly. Sarcasm is the canonical exception. “Oh, incredible service, solely needed to wait 45 minutes” scores optimistic on each lexicon, and the embedding clusters it with the honest model as a result of the floor phrases are practically the identical. The one trustworthy technique is an LLM that reads every name in full and judges the hole between what is alleged and what’s meant.
Similar form throughout features: HR exit interviews on the lookout for hidden frustration, internal-chat archives on the lookout for cultural crimson flags earlier than an M&A detailed, earnings-call transcripts on the lookout for locations the CFO hedged, sales-call recordings on the lookout for guarantees the contract didn’t authorise. Tone and intent, no anchor within the textual content.
Engineering schematics (a distinct axis altogether). Drawings, slides the place information lives within the chart, technical specs with embedded pictures. Pure-text RAG returns the caption and misses the schematic. Imaginative and prescient fashions match right here, and solely right here.
Similar form: architectural blueprints, scanned handwritten data, slide decks the place information lives within the chart, lab pocket book pages, medical imaging experiences. Wherever the which means lives within the pixels.
The basic playbook is overkill on templated paperwork (regex would do), dimensionally improper on name transcripts (no anchor exists), and modality-blind on schematics (imaginative and prescient is required). It matches a center band of issues and ships as if it lined all the things. That center band is actual and Part 3.3 catalogues it; the price of mismatch on the remainder is what this text exists to stop.
This text is the diagnostic. Three steps, so as.
- Establish the 2 axes: RAG issues aren’t a single downside. They sit on an image with two axes: how structured your paperwork are, and the way managed your questions are. Every mixture requires a distinct stack.
- Establish the methods per area: Every area of the image has its personal stack: regex, part retrieval, hybrid retrieval (lexical search + embedding similarity), imaginative and prescient, SQL aggregation. A 3rd axis (the agentic dimension, part 2.4) sits on prime of those and decides how a lot runtime management the LLM will get. The catalog later within the article maps every area to its method zone.
- Find your individual case: The place do your paperwork sit on the complexity axis? The place do your questions sit on the management axis? The intersection factors to a area, and to the methods that match it.
You’re not right here to construct all the things. You’re right here to search out the place you sit, then learn the elements of the collection that match. Most readers will skip half of it.
A word earlier than the article will get technical. Most enterprise RAG is in two shapes: extracting fields from templated paperwork (the regex case within the opener), or answering free-form questions on heterogeneous paperwork like contracts and experiences (the place the remainder of the collection spends most of its time). Conversational transcripts are an actual third form, widespread in customer support, HR, and compliance; sarcasm is the toughest query they increase. Pure imaginative and prescient content material (schematics, slide decks) and corpus-scale questions (Half IV) come up much less typically. It’s possible you’ll meet one or two of those. The grid under allows you to find your case on sight.
This diagnostic is one piece of a bigger framing: Enterprise Doc Intelligence Quantity 1 builds enterprise RAG brick by brick, and the areas of the grid this text maps level to the articles within the collection the place every method will get constructed.

1. Two axes: doc complexity and query management
Each downside we’ll meet on this collection sits someplace on two axes:
- Doc complexity: How redundant is the construction throughout your paperwork? Can a parser deal with fields by place, by heading, or do you want a mannequin that sees the web page?
- Query management: Who frames the query? An engineer writing a set immediate, or a person typing freely right into a chat field, presumably with no thought what to ask?
These two axes are nearly unbiased. The one coupling: a fixed-template doc (Tier 1, under) often forces engineer-templated questions (Tier A), because the person by no means sorts a query. Outdoors that nook, any doc tier can pair with any query tier.
1.1 Doc axis: from a set template to a imaginative and prescient mannequin
Quantity 1 stays contained in the PDF scope. Multi-format paperwork (Phrase, Excel, PowerPoint, mail) are Quantity 2’s territory; all the things under describes one PDF at a time.
Paperwork range in structural redundancy: how a lot of their structure is shared throughout the corpus. 5 tiers cowl most enterprise conditions.

Tier 1: Mounted template: Each doc has the identical construction, the identical fields in the identical place, typically produced by the identical software program: insurance coverage certificates from a single dealer, KYC kinds, tax filings, inner compliance attestations. The construction is so predictable which you could deal with fields by their coordinates on the web page. Method: regex or coordinate-based extraction, no mannequin.
Tier 2: Household of templates: Paperwork comply with a recognizable sample with variations (totally different vendor, totally different software program, totally different 12 months): invoices throughout suppliers, leases throughout landlords, employment contracts throughout corporations in the identical authorized framework. Method: a regex per template plus a few-shot LLM as fallback when the template drifts.
Tier 3: Heterogeneous structured: Every doc has its personal construction (sections, headings, tables of contents) however the buildings don’t repeat throughout paperwork: customized authorized contracts, technical manuals from totally different distributors, monetary experiences. Method: parse the construction, retrieve through the doc’s personal desk of contents.
Tier 4: Unstructured / OCR’d: Scanned PDFs, photographs of paper, emails, free-form notes: the textual content is there however the structure is degraded or absent. Method: OCR with confidence scoring, then hybrid retrieval (lexical + embeddings) over the noisy textual content.
Tier 5: Visually wealthy: Paperwork the place the which means lives within the visuals: schematics, dense information tables embedded as pictures, slide decks with charts, engineering drawings. A pure-text parse loses the reply. Method: a vision-capable mannequin on the web page picture, typically mixed with text-side RAG.
The additional down this axis you sit, the extra you pay per doc. The suitable transfer is to push each downside as far up as trustworthy evaluation permits. A workforce that decides their corpus is “too advanced for regex” with out checking the structural redundancy is selecting the costly reply by default.
1.2 Query axis: from a set immediate to a multi-turn chatbot
The query axis is the one most groups skip. Two questions can look an identical syntactically but require fully totally different stacks. The dimension that issues is who controls the query and the way a lot.

Tier A: Engineer-templated: The query is a parameter of the system: “Extract the efficient date.”, “What’s the coverage quantity?”. The engineer wrote the immediate, calibrated it, examined it on a thousand paperwork. The person, if any, doesn’t even sort a query. Method: area extraction, structured output, no question-parsing step wanted.
Tier B: Consumer fills slots: The query is a template with user-supplied values: “Present me the clause about {subject} on this contract.” The person picks the subject from a listing, or sorts a tag. The form of the question is fastened, just one slot varies. Method: part retrieval, lookup in opposition to a recognized taxonomy.
Tier C: Free person question, one-shot: The person sorts no matter they need, the system solutions in a single go: “Why does this contract differ from final 12 months’s?”. That is the basic chat-with-your-document setup, the place the pipeline should parse the query, determine what to retrieve, and reply. Method: single-document RAG with query parsing.
Tier D: Free question plus clarification. Similar as C, however the system can ask the person again when the query is ambiguous: “Which web page do you imply? Did you imply the sub-tenant or the primary tenant?” That is what actual chatbots do, and it dramatically widens the vary of questions a system can serve. Method: query parsing plus a clarification loop.
A small instance to make the clarification thought concrete. Think about a person asks: “What’s the deductible?” on a single insurance coverage contract that mentions deductibles in three sections (house, auto, journey protection). A naive pipeline retrieves one thing believable and returns a assured improper reply. A system that can ask again (“Which protection: house, auto, or journey?”) fixes the issue on the supply.
This pushes a constraint upstream into parsing. To detect that the person talked about “web page 3” or “the second appendix”, your parser should have preserved web page numbers, part indices, and heading textual content as metadata on each chunk. The web page quantity sounds trivial while you take a look at any single doc, however it’s the easiest instance of a parsing choice that the query aspect is determined by. Article 5 covers this intimately.
Query scale is a separate query, not a tier on this axis. “What number of PDFs are in your corpus, and are they homogeneous or heterogeneous?” is a data-side concern, picked up by part 3.2 of the diagnostic and developed in Half IV (Articles 14-17). Mixing it into the query axis blurs two various things, so it stays out.
1.3 From case to method zone
Cross the 2 axes and each single-PDF RAG downside lands someplace on the image. Every area requires a distinct stack. Most groups construct for one or two areas and faux the remainder don’t exist. The grid under is a considering instrument, not a strict taxonomy: actual issues typically sit between two instances, and the boundaries between zones are fuzzy on goal.

The top-left nook (rows 1-2, columns A-B) is deterministic territory. Mounted templates, managed questions. No LLM is required for the sector extraction itself; the LLM seems at most as a fallback when the template drifts. That is the place the insurance-broker mistake from the opening lives. Most enterprise doc workflows fall right here, and most of them are over-engineered. The dealer case from the opening is the canonical instance: an LLM stack at sixty thousand euros a 12 months when a hundred-line regex would do.
The center band (rows 2-4, columns C-D) is single-document RAG. The chat-with-your-PDF use case each vendor demo exhibits. It’s actual, it’s laborious, and the remainder of the collection spends most of its time right here. Chunking (splitting the doc into searchable items), retrieval (choosing the right ones), reranking (a precision move on the shortlist), and analysis (realizing it really works) all matter when the doc is heterogeneous and the query is open.
The backside row (row 5, all columns) is imaginative and prescient territory. Charts, schematics, dense tables. A textual content parser loses the reply no matter how intelligent the retrieval is. Imaginative and prescient fashions match right here, and solely right here. Article 10 discusses when the imaginative and prescient step is value its value and when it isn’t.
Corpus-scale instances sit off the grid, because the grid is one PDF at a time. When the query targets many PDFs without delay (“discover each provider contract with a legal responsibility cap under a million”), the diagnostic routes to Half IV (Articles 14-17): classification at ingestion, structured fields, SQL on the structured aspect, RAG on the residual unstructured questions.
The grid isn’t a recipe. It’s a sanity verify. Find your downside, take a look at the method zone, and ask whether or not the system you’re constructing matches. In case you’re constructing deeper than the case requires, you’re paying for nothing. In case you’re constructing shallower, you’ll uncover the hole in manufacturing.
2. The methods per case, and what isn’t a way
When you’ve positioned your downside on the grid, you recognize roughly which household of methods applies. The remainder of the collection develops every method intimately.

The deterministic household (regex, part anchors that find a heading by title, coordinate-based extraction that pulls a area from a set bounding field on the web page) doesn’t have its personal article. It’s the baseline each engineer ought to already know. Each engineer studying this collection ought to already know methods to write a regex. The purpose of together with it on the map is to remind you that it’s an possibility. When the construction of your enter is fastened, it’s the choice.
The one-document RAG household is what Components II and III of the collection are about. Structure-aware parsing (Article 5), query parsing and calibration (Article 6), retrieval as scope choice (Article 7), era as managed execution (Article 8), hybrid retrieval and TOC routing (Article 9), adaptive parsing together with imaginative and prescient (Article 10), cross-references (Article 11), itemizing and synthesis (Article 12), composite pipelines with suggestions loops (Article 13). Every of those is a way you’ll attain for within the central band of the grid.
The corpus-scale household is Half IV. The corpus downside (Article 14), getting ready a queryable corpus from a folder of PDFs (Article 15), the corpus ontology (Article 16), querying with SQL filter first and retrieval second (Article 17). These are available in while you go from one PDF to a corpus of PDFs.
In case your downside is within the top-left nook of the grid, you’ll be able to cease studying the collection after Article 5 (parsing) and skip forward to Article 15 (getting ready a queryable corpus). In case your downside sits within the center band, you’ll want Components II and III. In case your downside is corpus-scale, you’ll want Half IV on prime of the muse. The map tells you which ones.
2.1 Choose the only method that works
The intuition of each engineering workforce is to construct probably the most highly effective pipeline they’ll justify. That intuition is improper right here. The suitable intuition is to choose the least highly effective method that solves the precise downside. Three causes:
- Price: At two million docs a 12 months, a regex on a VM is a rounding error; an LLM per doc is sixty thousand euros.
- Latency: Microseconds vs seconds, the distinction between “feels instantaneous” and “appears like ready”.
- Reliability: A regex both matches or it doesn’t and the engineer can learn the rule; an LLM produces solutions which are typically subtly improper with failure modes more durable to detect, which disqualifies it for audit-grade extraction.
Most manufacturing doc workflows land on a hybrid: a deterministic core dealing with the majority cleanly, with an LLM fallback for the instances the place the format breaks. That hybrid is nearly all the time the appropriate form, and nearly by no means what groups construct first.
2.2 Lengthy context isn’t a method out
Each few months somebody proclaims that “RAG is useless” as a result of context home windows simply received larger. The argument: dump the entire doc within the immediate and let the mannequin determine it out.
This works for one doc and one person. It doesn’t work in manufacturing for 4 causes:
- Wasteful: A typical query doesn’t want the entire doc. The efficient date of a contract sits on one web page; sending the opposite thirty-nine pays for tokens that received’t be used.
- Misses info: Transformers reliably learn what’s at the beginning and finish of a protracted context and routinely skip what’s within the center, so the related web page may by no means be learn even when it’s within the immediate.
- Doesn’t scale: Actual use instances contain many paperwork. No context window will ever maintain a company archive; at any significant scale you must select what to ship, and that alternative is retrieval.
- No grounded reply: With out specific retrieval and quotation, you’ll be able to’t inform which a part of the doc the reply got here from, you’ll be able to’t confirm it, you’ll be able to’t audit it. For any enterprise use case the place the reply must be traceable, that’s disqualifying.
Lengthy contexts are helpful as a instrument, particularly for single-document deep evaluation. They’re not an alternative choice to retrieval. Anybody telling you in any other case is promoting one thing.
2.3 Fancy methods are often key phrase work in disguise
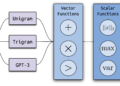
Methods offered as “superior” typically grow to be key phrase work in one other kind, and infrequently the improper kind. HyDE (Hypothetical Doc Embeddings, Gao et al., 2022) is the clearest instance. The protocol asks an LLM to put in writing the hypothetical doc that might reply the question, then retrieves in opposition to the embedding of that hypothetical. The pitch is that the hypothetical carries the vocabulary an actual reply would use, widening the cosine margin.
The companion pocket book checks this on the Consideration paper: ask why multi-head consideration, let HyDE generate its passage, examine in opposition to the precise vocabulary of part 3.2.2. The 2 lists overlap on precisely one phrase, the part title. HyDE writes ML-textbook vocabulary (semantic relationships, contextual dependencies, parallel processing, consideration patterns); the paper writes operational vocabulary (consideration layers, encoder-decoder consideration, totally different positions, linear transformations).
HyDE understood the query. It by no means learn the doc. In enterprise the key phrases exist someplace on the web page and the area professional who has learn the web page is aware of them. HyDE pays per question to invent vocabulary that usually doesn’t even land on the web page. The professional dictionary (Article 6), a curated record of the corpus’s precise vocabulary constructed as soon as with the area professional, will get the identical job achieved at a fraction of the associated fee, reused throughout each future query.
2.4 Letting the LLM decide the case
Every mixture of doc tier and query tier is an elementary case, with one matching method. In Quantity 1, the engineer picks the case at compile-time and ships the method. The dispatcher (Article 13) encodes the workforce’s routing knowledge in Python; the LLM critiques outputs inside fastened loops; each brick is auditable. That’s sufficient for the overwhelming majority of enterprise RAG.
A pure extension has the LLM itself decide the case at runtime, wanting on the query, classifying it right into a case, and selecting the method to use. That’s what 2026 trade calls agentic RAG. Quantity 3 (Agentic Bricks) builds that runtime-pick layer on prime of the bricks Quantity 1 produces. The shift is about who decides when, not in regards to the bricks themselves: agentic stacks nonetheless attain for a similar parsing, retrieval, and era primitives that Quantity 1 audits and checks.
3. Find your case, in observe
3.1 Place the system across the professional who exists
The diagnostic under wants one enter most groups skip: who’s the person of this technique?
For nearly all enterprise RAG, the reply is the professional who already is aware of the paperwork. Not an open-domain person typing any query. Not a curious browser exploring a public archive. The lawyer studying a contract. The underwriter checking a quote. The compliance officer auditing a clause. Somebody who has learn paperwork like these for years, and who is aware of the vocabulary, the instances the place one time period means two issues, and the failure modes to look at for.
The job of the system is then clear: amplify that professional, not exchange them. Codify their vocabulary, their disambiguations, their year-by-year heuristics. Let the pipeline deal with the quantity; let the professional keep the supply of fact.
This issues earlier than the grid, as a result of it adjustments which instances are real looking. A workforce that claims “anybody can ask something throughout the entire archive” is selecting the bottom-right case by default: open query, combined corpus, the toughest one. A workforce that claims “our underwriter checks a recognized area on a recognized doc sort” is selecting the top-left, typically regex territory.
The framing isn’t a property of the paperwork or the questions. It’s a alternative the workforce makes. Most groups inherit it from client chatbots with out noticing. First, place the system across the professional who’s already there. Then learn the case on the grid the reply factors to.
3.2 The diagnostic questions
Earlier than writing any code, work by these questions. Out loud, in entrance of a whiteboard, with the area specialists within the room.
Concerning the paperwork: How alike are they throughout the corpus? Native textual content or OCR? What number of PDFs do you’ve got, and are they homogeneous or heterogeneous? (that is the place corpus-scale considerations enter the diagnostic — they path to Half IV). Static or day by day ingestion? The place on the doc axis do they sit?
Concerning the questions: Who frames them? An engineer at design time, or a person at run time? Is the system one-shot or can it ask again for clarification? Is the reply all the time in a single doc, or distributed throughout a number of? What does no reply imply: acceptable, or unacceptable? The place on the query axis do they sit?
Concerning the constraints: Does the reply must be traceable to the supply? How exact (best-effort, or audit-grade: each quotation traceable to a supply line, each reply replayable)? What’s the associated fee finances per doc? Generally the distinction between regex and LLM is the distinction between worthwhile and never.
The solutions level you to a case on the grid. The case factors you to a way zone. The method zone factors you to the articles in the remainder of the collection you’ll want.
3.3 Widespread enterprise instances on the grid
A handful of patterns present up repeatedly in actual engagements. Most readers will acknowledge themselves in certainly one of these.
Subject extraction from a fixed-template kind. Suppose insurance coverage certificates from one dealer, KYC kinds from one financial institution, tax filings from one administration: the identical software program writes the identical structure on each web page. Case: doc tier 1, query A, top-left nook. Stack: regex on coordinate-addressable fields, with an LLM fallback for the uncommon drift. The basic playbook is overkill right here, and that’s the most typical mistake we meet in actual initiatives.
Subject extraction throughout template variants. Suppose invoices throughout a whole lot of suppliers, leases throughout landlords, employment contracts throughout corporations in the identical authorized framework: each doc follows certainly one of a handful of recognizable patterns. Case: doc tier 2, query A or B. Stack: a regex per acknowledged template, plus a few-shot LLM extraction when the doc doesn’t match something within the registry. Classification earlier than extraction.
Q&A on a protracted customized contract: Every contract is structured in another way, sections range, ten-page glossaries don’t repeat. The person asks free-form questions in regards to the contract in entrance of them. Case: doc tier 3, query C or D, center band. Stack: full single-document RAG with TOC routing, hybrid retrieval, schema-driven era. That is the place the 4 bricks of the collection every carry their very own weight.
Studying a slide deck or a schematic: Suppose engineering drawings, monetary decks the place information lives within the chart, technical specs with embedded pictures: pure-text parsing loses the reply outright. Case: doc tier 5, any query column, backside row. Stack: vision-capable mannequin on the web page picture, mixed with text-side RAG for the prose across the visuals.
Off the grid – corpus territory: “Discover each provider contract with a legal responsibility cap under a million” on a whole lot or 1000’s of contracts. The one-PDF grid stops being the appropriate body; the query targets the corpus, not one doc. Stack: area extraction at ingestion, structured fields saved in a database, SQL on the structured aspect, RAG solely as a fallback for the residual unstructured questions. Articles 14-17 (Half IV) develop this.
Off the grid – no construction to anchor on: a novel, an intent classification, sarcasm detection. The doc has no construction, the vocabulary has no attribute phrases, and the query requires understanding tone or intent reasonably than finding a passage. Stack: an LLM that scans the entire textual content paragraph by paragraph, deciding what to flag. Not a RAG downside in Quantity 1’s sense; part 2.4 hints at the place this type of runtime decision-making belongs (Quantity 3).
In case your case doesn’t fairly match any of those, stroll the diagnostic in part 3.2 and the outcome will let you know which of the patterns above is closest.
4. Conclusion
Run the diagnostic by yourself corpus earlier than writing code, ideally with the area specialists within the room. The output is the record of articles in the remainder of the collection it is advisable learn, and the record you’ll be able to skip. Groups that get RAG to ship in manufacturing are those that positioned their downside on the grid first. Groups nonetheless tuning six months in are often those that began constructing earlier than they did.
The subsequent article opens Half II with the primary brick: doc parsing. Every part misplaced there can’t be recovered later, regardless of how intelligent the retrieval.
5. Sources and additional studying
The 2-axis grid is a map of the place every strategy matches throughout doc complexity and query management on a single PDF. The long-context-doesn’t-replace-retrieval declare the grid leans on is grounded by Liu et al. (Misplaced within the Center, TACL 2024) and Lee et al. (long-context benchmark, 2024). The imaginative and prescient row maps to Faysse et al. (ColPali, 2024). The HyDE demo makes use of the method from Gao et al. (HyDE, 2022). The agentic extension hinted at in part 2.4 (the LLM choosing the case at runtime) is the route Quantity 3 develops on prime of the bricks constructed right here.
Similar route because the article:
- Liu et al., Misplaced within the Center: How Language Fashions Use Lengthy Contexts, TACL 2024 (arXiv:2307.03172). Fashions systematically miss info mid-input. Helps the declare that lengthy context just isn’t a method out.
- Lee et al., Can Lengthy-Context Language Fashions Subsume Retrieval, RAG, SQL, and Extra?, 2024 (arXiv:2406.13121). Concrete information on the place long-context replaces retrieval and the place it breaks.
- Faysse et al., ColPali: Environment friendly Doc Retrieval with Imaginative and prescient Language Fashions, 2024 (arXiv:2407.01449). Imaginative and prescient-language retrieval on the web page picture itself. Anchors the visible row of the grid.
- Gao et al., Exact Zero-Shot Dense Retrieval with out Relevance Labels (HyDE), 2022 (arXiv:2212.10496). The hypothetical-document-embedding method examined in part 2.3.
Totally different angle, totally different context:
- Yao et al., ReAct: Synergizing Reasoning and Appearing in Language Fashions, ICLR 2023 (arXiv:2210.03629). Founding paper of the LLM-picks-tools-at-runtime line. Quantity 3 develops this on prime of the bricks Quantity 1 builds.
- Schick et al., Toolformer: Language Fashions Can Train Themselves to Use Instruments, NeurIPS 2023 (arXiv:2302.04761). Similar route as ReAct.
- Gao et al., Retrieval-Augmented Era for Massive Language Fashions: A Survey, 2024 (arXiv:2312.10997). RAG survey; treats RAG as one paradigm with shared considerations (retriever high quality, generator faithfulness).














{kind=link}