


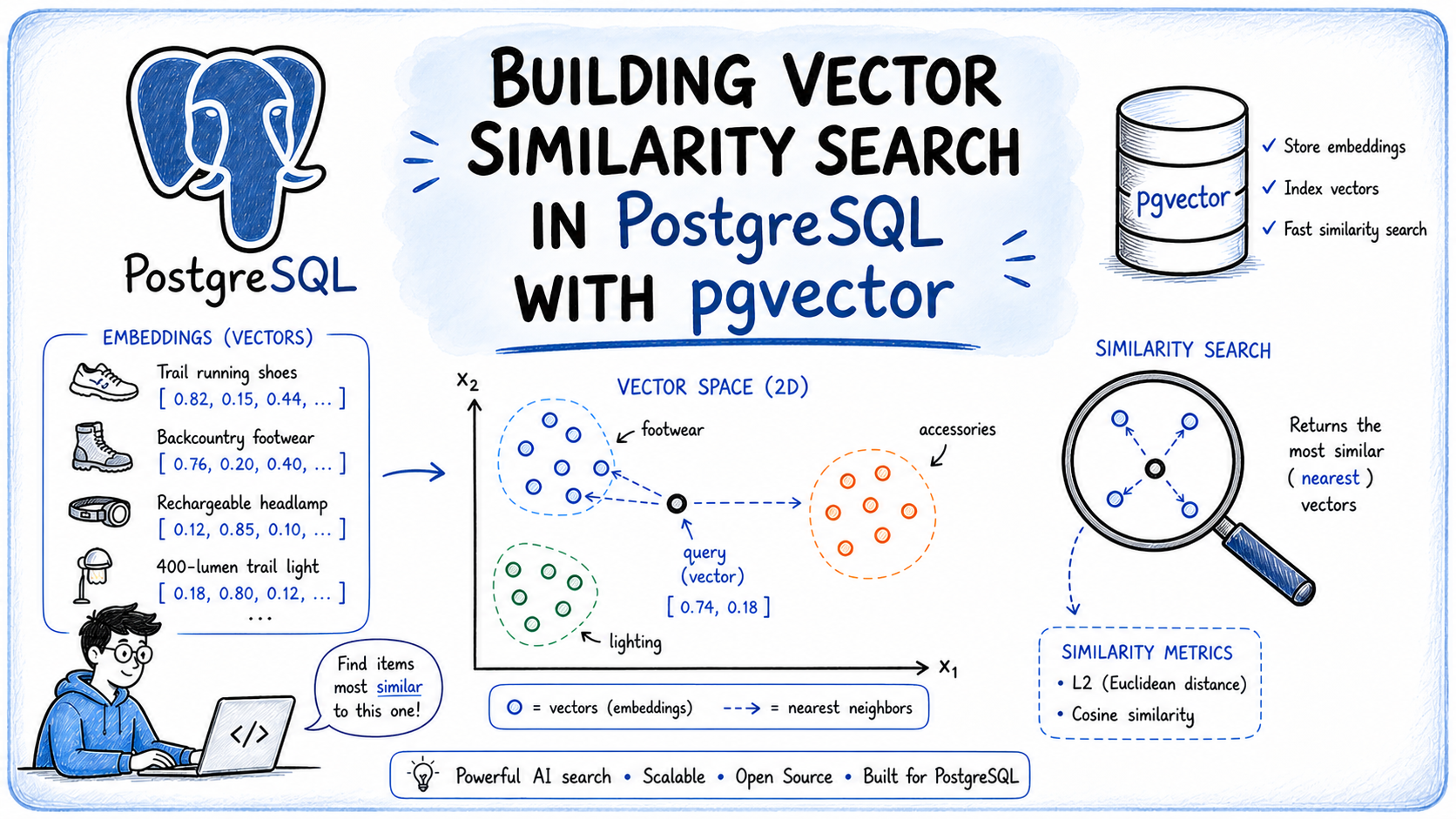
On this article, you’ll learn to implement vector similarity search in PostgreSQL utilizing the pgvector extension, permitting you to seek out semantically comparable outcomes based mostly on which means moderately than key phrase matching.
Matters we are going to cowl embody:
- What vector embeddings are and the way they allow semantic similarity search.
- The right way to set up and configure pgvector, retailer embeddings in PostgreSQL, and question them utilizing SQL distance operators.
- How to decide on the proper distance metric and index kind on your workload, and methods to mix similarity search with customary SQL filters.
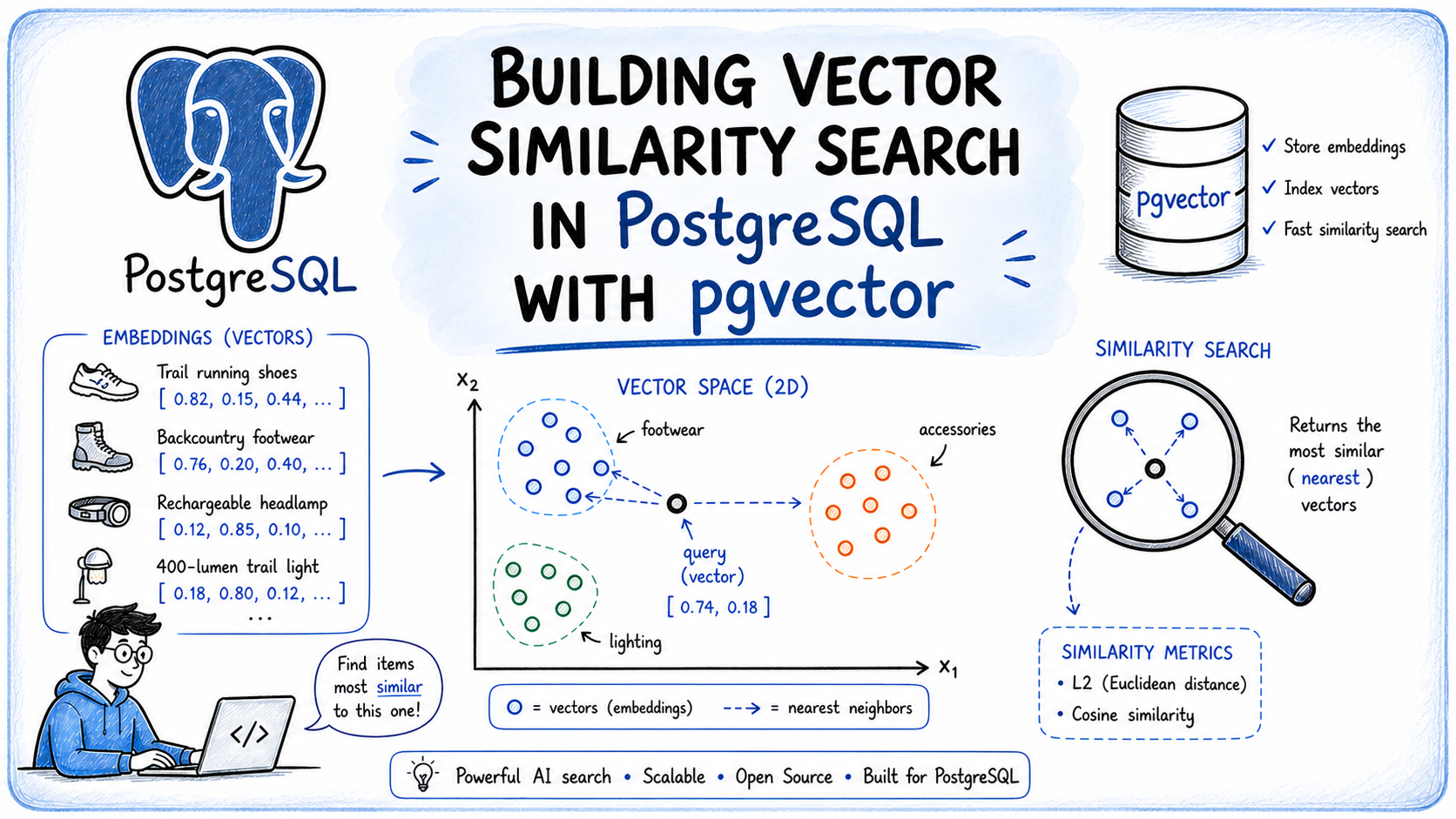
Constructing Vector Similarity Search in PostgreSQL with pgvector
Introduction
Search works nicely when customers know precisely what they’re on the lookout for, nevertheless it breaks down when intent is described in pure language. A person looking for “one thing heat and breathable for high-altitude trekking” will get poor outcomes from a key phrase index, as a result of the phrases in that question hardly ever align with the phrases in your information.
That is the place similarity search turns into helpful. As an alternative of matching key phrases, it finds outcomes based mostly on which means — connecting person intent to related data even when the wording differs completely.
This text reveals methods to implement similarity search in PostgreSQL utilizing pgvector. You’ll learn to arrange the extension, retailer vector embeddings in your database, and run similarity queries utilizing plain SQL with no separate vector database.
What Is a Vector Embedding?
A vector embedding is an inventory of floating-point numbers that represents the which means of a chunk of information, not its characters or key phrases. The numbers are produced by a machine studying mannequin skilled to position semantically comparable content material shut collectively in a high-dimensional numeric house. Two sentences that discuss the identical idea will produce embeddings which might be numerically shut, even when they share no phrases.
Think about these two phrases:
- “Light-weight path runners for long-distance mountaineering”
- “Trainers constructed for backcountry endurance”
An embedding mannequin would place their vectors close to one another in that house. That proximity is what makes similarity search work: you embed the person’s question, discover the saved vectors closest to it, and return these rows.
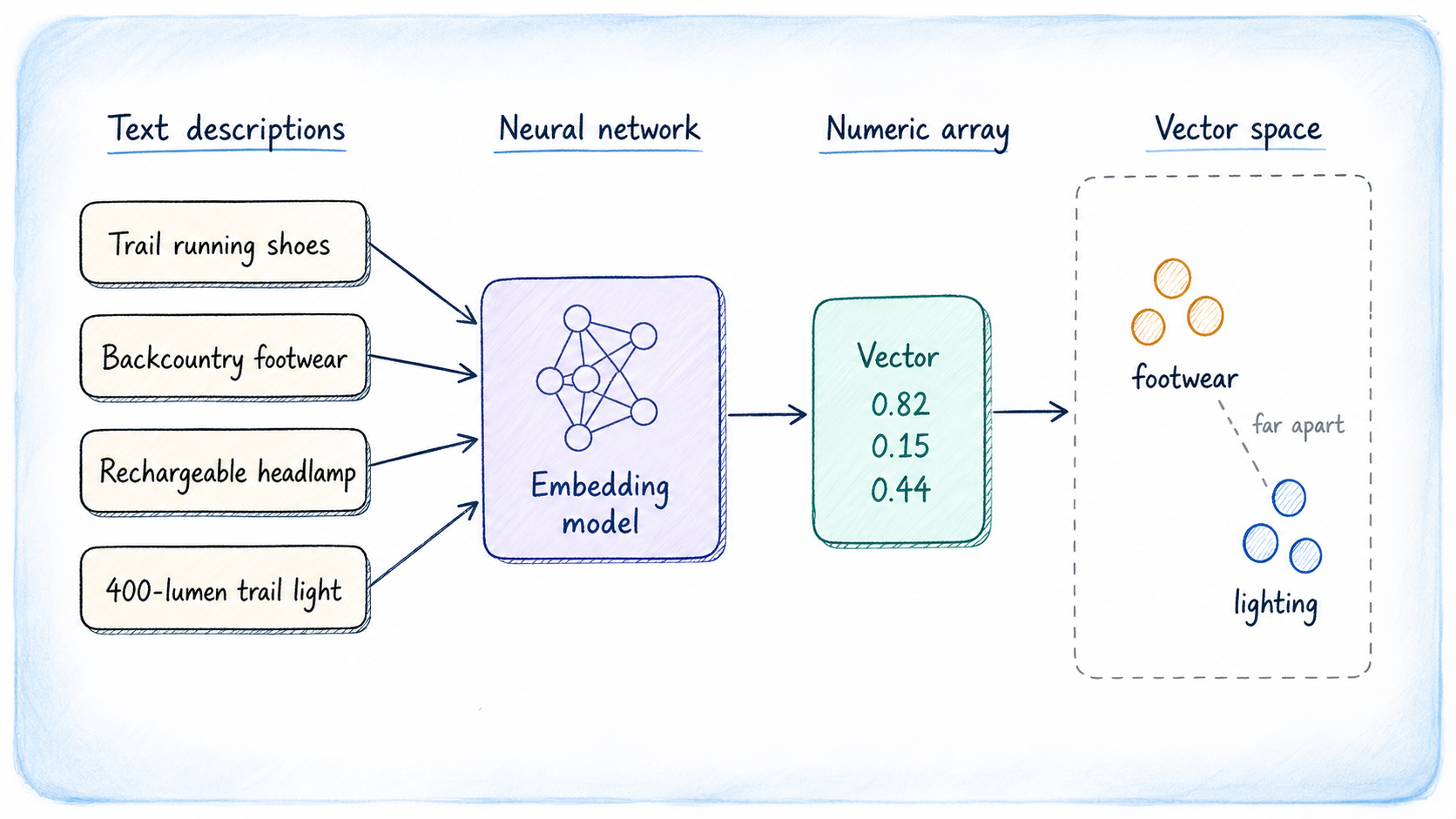
Producing Embeddings
The vector dimension relies on which mannequin you employ. You possibly can select from a number of choices; the commonest ones to attempt are:
- OpenAI text-embedding-3-small / text-embedding-3-large: 1536 and 3072 dimensions respectively.
- Cohere Embed v4: Multilingual and multimodal, masking textual content and pictures in a shared vector house.
- EmbeddingGemma: A 308M parameter open mannequin from Google constructed on Gemma 3, producing 768-dimensional vectors with Matryoshka truncation assist, protection of 100+ languages, and absolutely on-device inference.
- BAAI/BGE-M3: Open-source and self-hostable, supporting over 1,000 languages and sequences as much as 8,192 tokens. Additionally out there on Hugging Face.
- Sentence Transformers: Light-weight open-source fashions that run on CPU, appropriate for native improvement the place retrieval accuracy is secondary to hurry.
The MTEB Leaderboard is a typical reference for evaluating embedding fashions. One rule applies no matter your selection: the dimension configured in your PostgreSQL column should precisely match the dimension the mannequin produces.
What Is pgvector?
pgvector is an open-source PostgreSQL extension that provides native vector search to your present database. Moderately than transferring your embeddings to a devoted vector retailer, pgvector retains them alongside your relational information, preserving PostgreSQL’s transactional ensures, JOIN semantics, point-in-time restoration, and the complete SQL question language.
The extension provides a vector information kind for storing embeddings, SQL distance operators for ordering question outcomes by similarity, and two index sorts — HNSW and IVFFlat — for accelerating nearest-neighbor lookups at scale. It additionally helps half-precision, binary, and sparse vector sorts.
Putting in pgvector
pgvector helps PostgreSQL 13 and newer. The set up information within the repository covers each platform intimately; the commonest paths are proven beneath.
On Linux
On Debian and Ubuntu, the APT bundle is the quickest route. Change 18 along with your PostgreSQL main model:
|
sudo apt set up postgresql–18–pgvector |
To compile from supply as an alternative, which works on any Linux distribution, use:
|
cd /tmp git clone —department v0.8.2 https://github.com/pgvector/pgvector.git cd pgvector make make set up |
On macOS
If you happen to’re on a Mac, Homebrew is the only choice:
The supply compilation steps above work identically on macOS with Xcode Command Line Instruments put in.
For Home windows, Docker, and conda-forge, see the set up notes within the repository. As soon as put in, allow the extension in your goal database. You solely want to do that as soon as per database:
|
CREATE EXTENSION IF NOT EXISTS vector; |
Making a Desk with a Vector Column
We’ll construct a product catalog for an outside gear retailer. Every product has a textual content description, and we are going to retailer an embedding of that description so customers can search by which means.
|
CREATE TABLE merchandise ( id SERIAL PRIMARY KEY, identify TEXT NOT NULL, class TEXT, description TEXT, worth NUMERIC(8,2), embedding vector(1536) ); |
The vector(1536) column holds one embedding per row. That quantity should match the output dimension of your mannequin; regulate it accordingly should you use a unique one.
For this text we’ll use a smaller check desk with three-dimensional vectors to maintain the examples readable:
|
CREATE TABLE gear ( id SERIAL PRIMARY KEY, identify TEXT NOT NULL, class TEXT, description TEXT, embedding vector(3) ); |
Inserting Pattern Knowledge
In apply you’ll name an embedding API on every product description at insert time and retailer the returned vector. Right here we use hand-crafted three-dimensional values that higher clarify the clustering precept: footwear gadgets share comparable first-component values, lighting gadgets cluster across the second, and backpacks share comparable third-component values. Embeddings from a mannequin behave the identical manner.
|
INSERT INTO gear (identify, class, description, embedding) VALUES (‘Merrell Moab 3 GTX’, ‘Footwear’, ‘Waterproof mountaineering boot for all-day path consolation’, ‘[0.82, 0.15, 0.44]’), (‘Salomon Speedcross 6’, ‘Footwear’, ‘Aggressive path runner for muddy and technical terrain’, ‘[0.79, 0.21, 0.38]’), (‘Black Diamond Spot 400’, ‘Lighting’, ‘Rechargeable headlamp with 400 lumens and waterproofing’, ‘[0.11, 0.88, 0.22]’), (‘Petzl ACTIK CORE’, ‘Lighting’, ‘Light-weight headlamp for mountaineering and tenting’, ‘[0.09, 0.91, 0.19]’), (‘Osprey Atmos AG 65’, ‘Backpacks’, ‘Anti-gravity backpack for multi-day backcountry journeys’, ‘[0.55, 0.30, 0.77]’), (‘Gregory Baltoro 75’, ‘Backpacks’, ‘Excessive-volume pack for prolonged wilderness expeditions’, ‘[0.58, 0.28, 0.81]’); |
Working a Question
Now we are able to seek for merchandise much like a question vector. Think about a person asks for “path footwear for tough terrain.” Your utility embeds that phrase, and let’s say it receives [0.80, 0.19, 0.40] again from the mannequin. Right here is how you discover the closest neighbors:
|
SELECT identify, class, description, embedding <-> ‘[0.80, 0.19, 0.40]’ AS distance FROM gear ORDER BY distance LIMIT 3; |
Output:
|
identify | class | distance ———————————+—————–+————— Salomon Speedcross 6 | Footwear | 0.0300 Merrell Moab 3 GTX | Footwear | 0.0600 Osprey Atmos AG 65 | Backpacks | 0.4599 (3 rows) |
The <-> operator computes L2 distance — the straight-line distance between two factors in vector house. Decrease values imply nearer, and subsequently extra comparable. The 2 footwear gadgets rank on the prime, which is what we’d count on.
Selecting a Distance Metric
pgvector helps a number of distance operators, every suited to totally different information traits. Selecting the improper one provides you outcomes that look legitimate however are subtly incorrect on your use case.
| Operator | Metric | Notes |
|---|---|---|
<-> |
L2 (Euclidean) distance | Straight-line hole between two vectors |
<=> |
Cosine distance | Angle between vectors; ignores magnitude |
<#> |
Destructive inside product | Negate the end result to get similarity |
<+> |
L1 (Manhattan) distance | Sum of absolute per-dimension variations |
<~> |
Hamming distance | Binary vectors solely |
<%> |
Jaccard distance | Binary vectors solely |
The 2 distance operators you’ll use most frequently are L2 and cosine, and choosing the proper one immediately impacts retrieval high quality.
- L2 distance treats vectors as factors in house and measures the geometric distance between them. It really works greatest when vector magnitude carries significant info.
- Cosine distance is
1 - cosine similarityand measures the angle between vectors moderately than their size. This makes it the popular selection for textual content embeddings generated by language fashions.
Most LLM-based embedding APIs produce normalized or near-normalized vectors, the place semantic which means is encoded in path, not magnitude. Due to this, cosine distance usually delivers extra correct semantic rankings for search and retrieval workloads.
Right here is similar question rewritten with cosine distance:
|
SELECT identify, embedding <=> ‘[0.80, 0.19, 0.40]’ AS cosine_distance FROM gear ORDER BY cosine_distance LIMIT 3; |
Past L2 and cosine distance, pgvector additionally helps a number of specialised operators designed for particular use circumstances:
- Inside product is beneficial in advice techniques, the place embeddings are skilled in order that dot merchandise immediately symbolize similarity. As a result of PostgreSQL solely helps ascending index scans on operators, pgvector returns the unfavourable inside product, so you need to negate the end result to get the precise similarity rating.
- L1 distance weights every dimension equally with out squaring the variations, giving it gentle robustness to outliers in comparison with L2.
- Hamming and Jaccard apply solely to binary vectors, used for memory-efficient quantized representations.
Including an Index for Efficiency
With out an index, each similarity question performs a full sequential scan: PostgreSQL computes the gap between the question vector and each row within the desk. That’s acceptable at ten thousand rows. At 1,000,000 rows, question latency turns into a major problem.
pgvector supplies two index sorts for approximate nearest-neighbor search, and every makes a unique set of trade-offs.
Hierarchical Navigable Small Worlds (HNSW) constructs a multi-layer graph the place every node connects to a bounded variety of neighbors throughout a number of ranges of decision. Queries navigate this graph by getting into on the coarsest layer and descending towards the closest neighbors at rising granularity. As a result of the graph is constructed incrementally, there isn’t any coaching step, which means you may create an HNSW index on an empty desk and add rows over time with out rebuilding. HNSW provides the perfect speed-to-recall ratio of the 2 choices, however establishing the graph requires extra reminiscence and takes longer than IVFFlat.
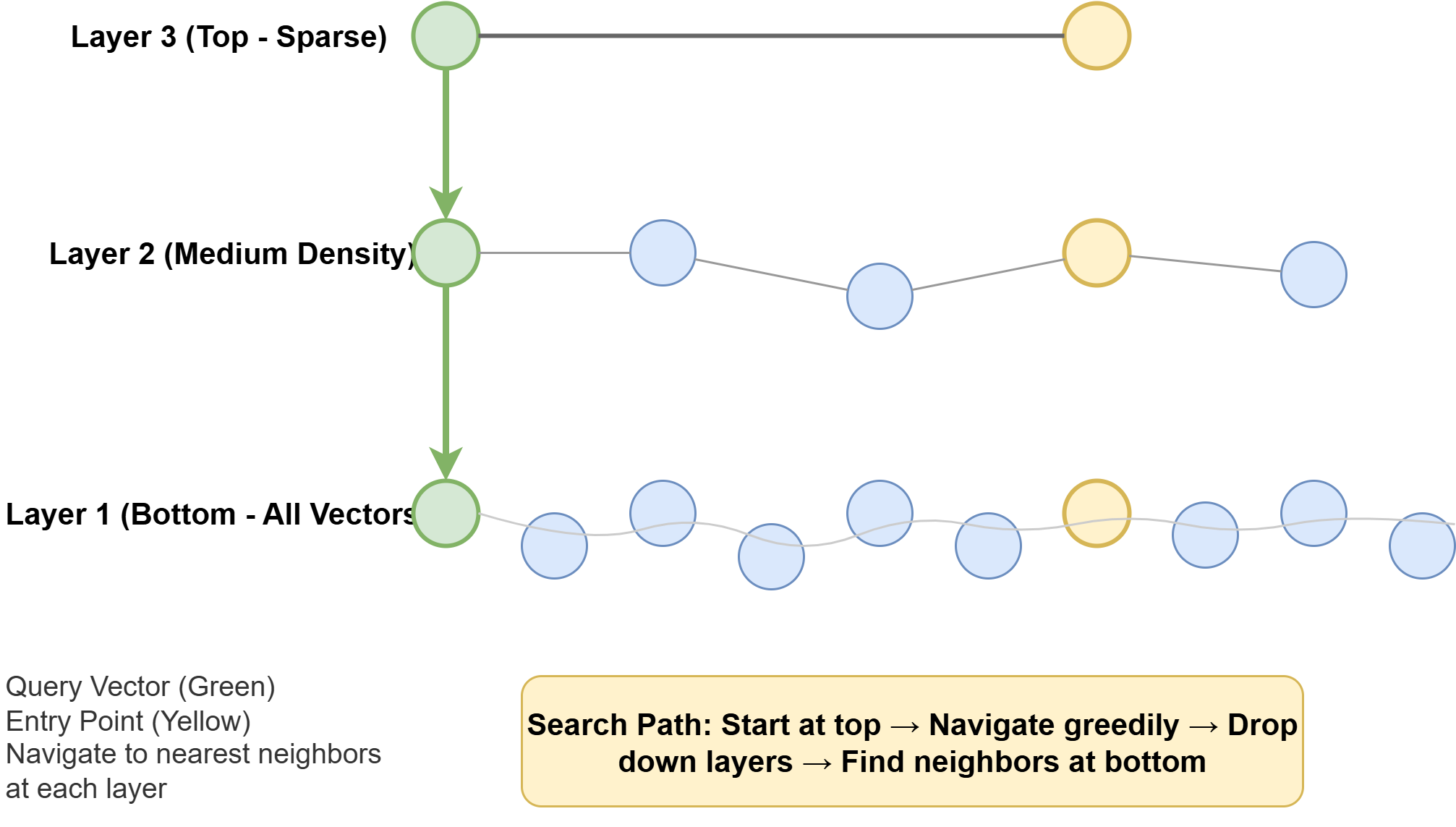
How HNSW Works
Inverted File Flat (IVFFlat) works in a different way: it partitions the vector house into a hard and fast variety of clusters throughout index development, then at question time searches solely the clusters closest to the question vector. It builds sooner and makes use of much less reminiscence, however these cluster boundaries are mounted at construct time. Rows added after development could land in poorly matched clusters, which might erode recall over time.
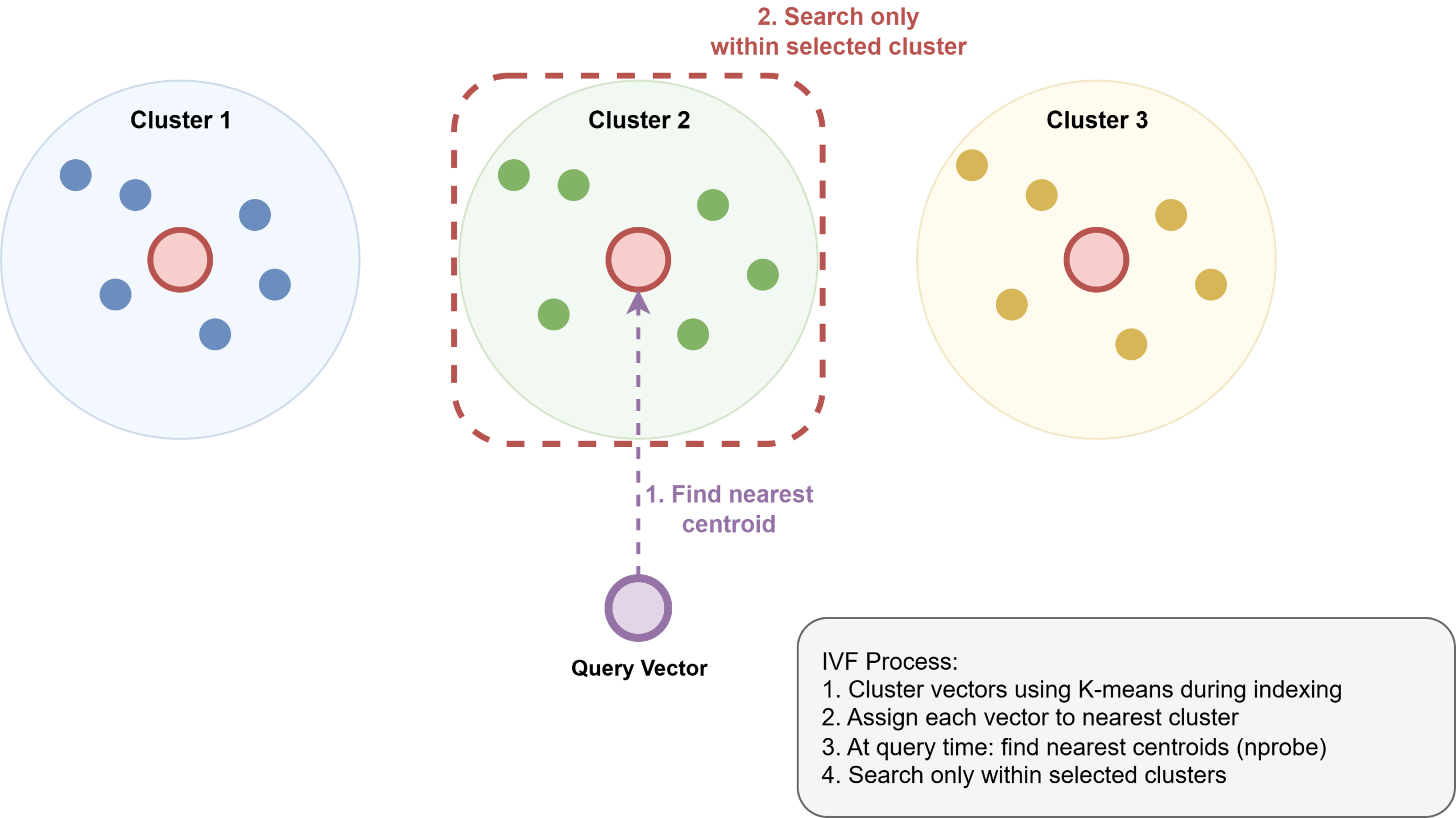
How Inverted File Index Works
Right here is methods to create an HNSW index for cosine distance:
|
CREATE INDEX ON gear USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); |
m units the utmost connections per node within the graph. ef_construction controls the dimensions of the candidate checklist throughout graph development. Each default to smart values and solely want tuning if recall degrades measurably at scale.
The operator class in your index should match the gap operator in your queries. The mapping is:
| Question Operator | Index Operator Class |
|---|---|
<-> |
vector_l2_ops |
<=> |
vector_cosine_ops |
<#> |
vector_ip_ops |
<+> |
vector_l1_ops |
<~> |
bit_hamming_ops |
<%> |
bit_jaccard_ops |
If these don’t match, PostgreSQL falls again to a sequential scan. At all times confirm with EXPLAIN that the index is getting used when wanted.
Placing It Collectively: Filtered Similarity Search
Similarity search turns into extra helpful when mixed with strange SQL filters. pgvector integrates immediately with PostgreSQL’s question planner, so you may mix vector ordering with WHERE clauses, JOINs, and aggregations with out studying a separate question language.
Right here we discover the 2 most comparable footwear merchandise to our question, proscribing the search to a single class:
|
SELECT identify, class, embedding <-> ‘[0.80, 0.19, 0.40]’ AS distance FROM gear WHERE class = ‘Footwear’ ORDER BY distance LIMIT 2; |
Output:
|
identify | class | distance ———————————+—————+————— Salomon Speedcross 6 | Footwear | 0.0004 Merrell Moab 3 GTX | Footwear | 0.0016 (2 rows) |
Abstract & Subsequent Steps
In apply, many of the complexity comes down to a few key choices:
- Select your embedding mannequin earlier than writing any schema, as a result of the vector dimension is baked into the column definition and altering it later means re-embedding your total dataset.
- Match your distance metric to your mannequin’s output. Cosine distance works nicely for many LLM-generated embeddings.
- Make sure the operator class in your index matches the operator in your queries, as a result of a mismatch produces no error — solely a silent regression to full-table scans.
Every thing else works precisely because it does in some other PostgreSQL desk. The following step is wiring in an actual embedding mannequin: name your chosen API on every row’s textual content at insert time, retailer the returned vector, and repeat the identical name for every person question at runtime. The SQL stays similar to what you may have seen right here. Blissful exploring!
On this article, you’ll learn to implement vector similarity search in PostgreSQL utilizing the pgvector extension, permitting you to seek out semantically comparable outcomes based mostly on which means moderately than key phrase matching.
Matters we are going to cowl embody:
- What vector embeddings are and the way they allow semantic similarity search.
- The right way to set up and configure pgvector, retailer embeddings in PostgreSQL, and question them utilizing SQL distance operators.
- How to decide on the proper distance metric and index kind on your workload, and methods to mix similarity search with customary SQL filters.
Constructing Vector Similarity Search in PostgreSQL with pgvector
Introduction
Search works nicely when customers know precisely what they’re on the lookout for, nevertheless it breaks down when intent is described in pure language. A person looking for “one thing heat and breathable for high-altitude trekking” will get poor outcomes from a key phrase index, as a result of the phrases in that question hardly ever align with the phrases in your information.
That is the place similarity search turns into helpful. As an alternative of matching key phrases, it finds outcomes based mostly on which means — connecting person intent to related data even when the wording differs completely.
This text reveals methods to implement similarity search in PostgreSQL utilizing pgvector. You’ll learn to arrange the extension, retailer vector embeddings in your database, and run similarity queries utilizing plain SQL with no separate vector database.
What Is a Vector Embedding?
A vector embedding is an inventory of floating-point numbers that represents the which means of a chunk of information, not its characters or key phrases. The numbers are produced by a machine studying mannequin skilled to position semantically comparable content material shut collectively in a high-dimensional numeric house. Two sentences that discuss the identical idea will produce embeddings which might be numerically shut, even when they share no phrases.
Think about these two phrases:
- “Light-weight path runners for long-distance mountaineering”
- “Trainers constructed for backcountry endurance”
An embedding mannequin would place their vectors close to one another in that house. That proximity is what makes similarity search work: you embed the person’s question, discover the saved vectors closest to it, and return these rows.
Producing Embeddings
The vector dimension relies on which mannequin you employ. You possibly can select from a number of choices; the commonest ones to attempt are:
- OpenAI text-embedding-3-small / text-embedding-3-large: 1536 and 3072 dimensions respectively.
- Cohere Embed v4: Multilingual and multimodal, masking textual content and pictures in a shared vector house.
- EmbeddingGemma: A 308M parameter open mannequin from Google constructed on Gemma 3, producing 768-dimensional vectors with Matryoshka truncation assist, protection of 100+ languages, and absolutely on-device inference.
- BAAI/BGE-M3: Open-source and self-hostable, supporting over 1,000 languages and sequences as much as 8,192 tokens. Additionally out there on Hugging Face.
- Sentence Transformers: Light-weight open-source fashions that run on CPU, appropriate for native improvement the place retrieval accuracy is secondary to hurry.
The MTEB Leaderboard is a typical reference for evaluating embedding fashions. One rule applies no matter your selection: the dimension configured in your PostgreSQL column should precisely match the dimension the mannequin produces.
What Is pgvector?
pgvector is an open-source PostgreSQL extension that provides native vector search to your present database. Moderately than transferring your embeddings to a devoted vector retailer, pgvector retains them alongside your relational information, preserving PostgreSQL’s transactional ensures, JOIN semantics, point-in-time restoration, and the complete SQL question language.
The extension provides a vector information kind for storing embeddings, SQL distance operators for ordering question outcomes by similarity, and two index sorts — HNSW and IVFFlat — for accelerating nearest-neighbor lookups at scale. It additionally helps half-precision, binary, and sparse vector sorts.
Putting in pgvector
pgvector helps PostgreSQL 13 and newer. The set up information within the repository covers each platform intimately; the commonest paths are proven beneath.
On Linux
On Debian and Ubuntu, the APT bundle is the quickest route. Change 18 along with your PostgreSQL main model:
|
sudo apt set up postgresql–18–pgvector |
To compile from supply as an alternative, which works on any Linux distribution, use:
|
cd /tmp git clone —department v0.8.2 https://github.com/pgvector/pgvector.git cd pgvector make make set up |
On macOS
If you happen to’re on a Mac, Homebrew is the only choice:
The supply compilation steps above work identically on macOS with Xcode Command Line Instruments put in.
For Home windows, Docker, and conda-forge, see the set up notes within the repository. As soon as put in, allow the extension in your goal database. You solely want to do that as soon as per database:
|
CREATE EXTENSION IF NOT EXISTS vector; |
Making a Desk with a Vector Column
We’ll construct a product catalog for an outside gear retailer. Every product has a textual content description, and we are going to retailer an embedding of that description so customers can search by which means.
|
CREATE TABLE merchandise ( id SERIAL PRIMARY KEY, identify TEXT NOT NULL, class TEXT, description TEXT, worth NUMERIC(8,2), embedding vector(1536) ); |
The vector(1536) column holds one embedding per row. That quantity should match the output dimension of your mannequin; regulate it accordingly should you use a unique one.
For this text we’ll use a smaller check desk with three-dimensional vectors to maintain the examples readable:
|
CREATE TABLE gear ( id SERIAL PRIMARY KEY, identify TEXT NOT NULL, class TEXT, description TEXT, embedding vector(3) ); |
Inserting Pattern Knowledge
In apply you’ll name an embedding API on every product description at insert time and retailer the returned vector. Right here we use hand-crafted three-dimensional values that higher clarify the clustering precept: footwear gadgets share comparable first-component values, lighting gadgets cluster across the second, and backpacks share comparable third-component values. Embeddings from a mannequin behave the identical manner.
|
INSERT INTO gear (identify, class, description, embedding) VALUES (‘Merrell Moab 3 GTX’, ‘Footwear’, ‘Waterproof mountaineering boot for all-day path consolation’, ‘[0.82, 0.15, 0.44]’), (‘Salomon Speedcross 6’, ‘Footwear’, ‘Aggressive path runner for muddy and technical terrain’, ‘[0.79, 0.21, 0.38]’), (‘Black Diamond Spot 400’, ‘Lighting’, ‘Rechargeable headlamp with 400 lumens and waterproofing’, ‘[0.11, 0.88, 0.22]’), (‘Petzl ACTIK CORE’, ‘Lighting’, ‘Light-weight headlamp for mountaineering and tenting’, ‘[0.09, 0.91, 0.19]’), (‘Osprey Atmos AG 65’, ‘Backpacks’, ‘Anti-gravity backpack for multi-day backcountry journeys’, ‘[0.55, 0.30, 0.77]’), (‘Gregory Baltoro 75’, ‘Backpacks’, ‘Excessive-volume pack for prolonged wilderness expeditions’, ‘[0.58, 0.28, 0.81]’); |
Working a Question
Now we are able to seek for merchandise much like a question vector. Think about a person asks for “path footwear for tough terrain.” Your utility embeds that phrase, and let’s say it receives [0.80, 0.19, 0.40] again from the mannequin. Right here is how you discover the closest neighbors:
|
SELECT identify, class, description, embedding <-> ‘[0.80, 0.19, 0.40]’ AS distance FROM gear ORDER BY distance LIMIT 3; |
Output:
|
identify | class | distance ———————————+—————–+————— Salomon Speedcross 6 | Footwear | 0.0300 Merrell Moab 3 GTX | Footwear | 0.0600 Osprey Atmos AG 65 | Backpacks | 0.4599 (3 rows) |
The <-> operator computes L2 distance — the straight-line distance between two factors in vector house. Decrease values imply nearer, and subsequently extra comparable. The 2 footwear gadgets rank on the prime, which is what we’d count on.
Selecting a Distance Metric
pgvector helps a number of distance operators, every suited to totally different information traits. Selecting the improper one provides you outcomes that look legitimate however are subtly incorrect on your use case.
| Operator | Metric | Notes |
|---|---|---|
<-> |
L2 (Euclidean) distance | Straight-line hole between two vectors |
<=> |
Cosine distance | Angle between vectors; ignores magnitude |
<#> |
Destructive inside product | Negate the end result to get similarity |
<+> |
L1 (Manhattan) distance | Sum of absolute per-dimension variations |
<~> |
Hamming distance | Binary vectors solely |
<%> |
Jaccard distance | Binary vectors solely |
The 2 distance operators you’ll use most frequently are L2 and cosine, and choosing the proper one immediately impacts retrieval high quality.
- L2 distance treats vectors as factors in house and measures the geometric distance between them. It really works greatest when vector magnitude carries significant info.
- Cosine distance is
1 - cosine similarityand measures the angle between vectors moderately than their size. This makes it the popular selection for textual content embeddings generated by language fashions.
Most LLM-based embedding APIs produce normalized or near-normalized vectors, the place semantic which means is encoded in path, not magnitude. Due to this, cosine distance usually delivers extra correct semantic rankings for search and retrieval workloads.
Right here is similar question rewritten with cosine distance:
|
SELECT identify, embedding <=> ‘[0.80, 0.19, 0.40]’ AS cosine_distance FROM gear ORDER BY cosine_distance LIMIT 3; |
Past L2 and cosine distance, pgvector additionally helps a number of specialised operators designed for particular use circumstances:
- Inside product is beneficial in advice techniques, the place embeddings are skilled in order that dot merchandise immediately symbolize similarity. As a result of PostgreSQL solely helps ascending index scans on operators, pgvector returns the unfavourable inside product, so you need to negate the end result to get the precise similarity rating.
- L1 distance weights every dimension equally with out squaring the variations, giving it gentle robustness to outliers in comparison with L2.
- Hamming and Jaccard apply solely to binary vectors, used for memory-efficient quantized representations.
Including an Index for Efficiency
With out an index, each similarity question performs a full sequential scan: PostgreSQL computes the gap between the question vector and each row within the desk. That’s acceptable at ten thousand rows. At 1,000,000 rows, question latency turns into a major problem.
pgvector supplies two index sorts for approximate nearest-neighbor search, and every makes a unique set of trade-offs.
Hierarchical Navigable Small Worlds (HNSW) constructs a multi-layer graph the place every node connects to a bounded variety of neighbors throughout a number of ranges of decision. Queries navigate this graph by getting into on the coarsest layer and descending towards the closest neighbors at rising granularity. As a result of the graph is constructed incrementally, there isn’t any coaching step, which means you may create an HNSW index on an empty desk and add rows over time with out rebuilding. HNSW provides the perfect speed-to-recall ratio of the 2 choices, however establishing the graph requires extra reminiscence and takes longer than IVFFlat.
How HNSW Works
Inverted File Flat (IVFFlat) works in a different way: it partitions the vector house into a hard and fast variety of clusters throughout index development, then at question time searches solely the clusters closest to the question vector. It builds sooner and makes use of much less reminiscence, however these cluster boundaries are mounted at construct time. Rows added after development could land in poorly matched clusters, which might erode recall over time.
How Inverted File Index Works
Right here is methods to create an HNSW index for cosine distance:
|
CREATE INDEX ON gear USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 64); |
m units the utmost connections per node within the graph. ef_construction controls the dimensions of the candidate checklist throughout graph development. Each default to smart values and solely want tuning if recall degrades measurably at scale.
The operator class in your index should match the gap operator in your queries. The mapping is:
| Question Operator | Index Operator Class |
|---|---|
<-> |
vector_l2_ops |
<=> |
vector_cosine_ops |
<#> |
vector_ip_ops |
<+> |
vector_l1_ops |
<~> |
bit_hamming_ops |
<%> |
bit_jaccard_ops |
If these don’t match, PostgreSQL falls again to a sequential scan. At all times confirm with EXPLAIN that the index is getting used when wanted.
Placing It Collectively: Filtered Similarity Search
Similarity search turns into extra helpful when mixed with strange SQL filters. pgvector integrates immediately with PostgreSQL’s question planner, so you may mix vector ordering with WHERE clauses, JOINs, and aggregations with out studying a separate question language.
Right here we discover the 2 most comparable footwear merchandise to our question, proscribing the search to a single class:
|
SELECT identify, class, embedding <-> ‘[0.80, 0.19, 0.40]’ AS distance FROM gear WHERE class = ‘Footwear’ ORDER BY distance LIMIT 2; |
Output:
|
identify | class | distance ———————————+—————+————— Salomon Speedcross 6 | Footwear | 0.0004 Merrell Moab 3 GTX | Footwear | 0.0016 (2 rows) |
Abstract & Subsequent Steps
In apply, many of the complexity comes down to a few key choices:
- Select your embedding mannequin earlier than writing any schema, as a result of the vector dimension is baked into the column definition and altering it later means re-embedding your total dataset.
- Match your distance metric to your mannequin’s output. Cosine distance works nicely for many LLM-generated embeddings.
- Make sure the operator class in your index matches the operator in your queries, as a result of a mismatch produces no error — solely a silent regression to full-table scans.
Every thing else works precisely because it does in some other PostgreSQL desk. The following step is wiring in an actual embedding mannequin: name your chosen API on every row’s textual content at insert time, retailer the returned vector, and repeat the identical name for every person question at runtime. The SQL stays similar to what you may have seen right here. Blissful exploring!














{kind=link}