


On this article, you’ll find out how zero-shot textual content classification works and how one can apply it utilizing a pretrained transformer mannequin.
Matters we are going to cowl embody:
- The core thought behind zero-shot classification and the way it reframes labeling as a reasoning process.
- The best way to use a pretrained mannequin to categorise textual content with out task-specific coaching knowledge.
- Sensible methods equivalent to multi-label classification and speculation template tuning.
Let’s get began.
Getting Began with Zero-Shot Textual content Classification
Picture by Editor
Introduction
Zero-shot textual content classification is a option to label textual content with out first coaching a classifier by yourself task-specific dataset. As a substitute of gathering examples for each class you need, you present the mannequin with a bit of textual content and an inventory of attainable labels. The mannequin then decides which label matches finest based mostly on its common language understanding.
This makes zero-shot classification particularly helpful whenever you wish to check an thought rapidly, work with altering label units, or construct a light-weight prototype earlier than investing in supervised coaching. Relatively than studying a hard and fast mapping from textual content to label IDs, the mannequin makes use of language itself to cause about what every label means.
On this information, we are going to perceive the primary thought behind zero-shot classification and run sensible examples utilizing fb/bart-large-mnli.
How Zero-Shot Works
The core thought behind zero-shot classification is that the mannequin doesn’t deal with labels as easy class names. As a substitute, it turns every label into a brief natural-language assertion and checks whether or not that assertion is supported by the enter textual content. This makes it particularly helpful in sensible conditions the place you wish to classify textual content rapidly with out gathering and labeling coaching knowledge first, equivalent to routing help tickets, tagging articles, detecting person intent, or organizing inside paperwork.
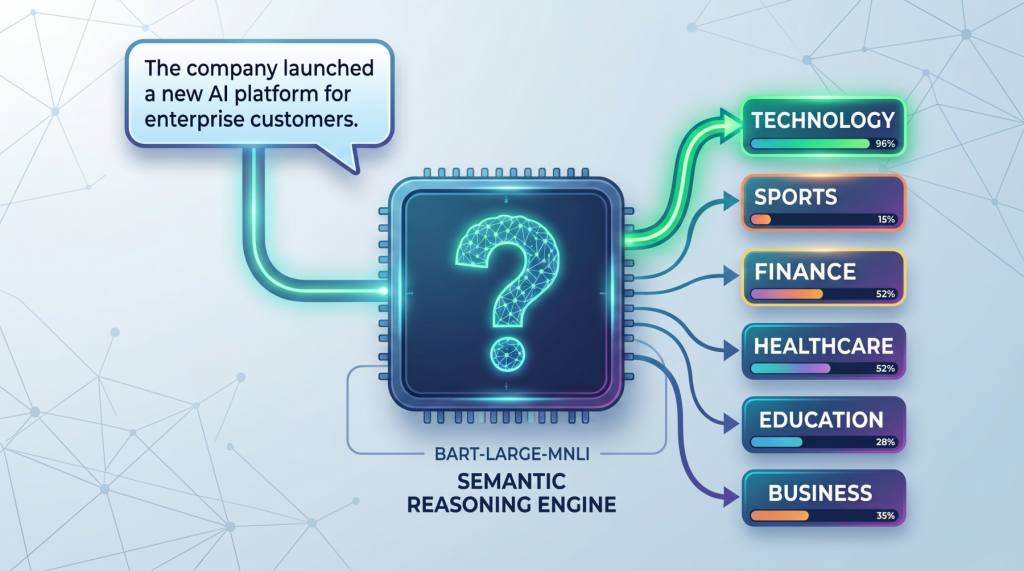
For instance, suppose the enter textual content is:
|
textual content = “The corporate launched a brand new AI platform for enterprise prospects.” |
And the candidate labels are:
|
labels = [“technology”, “sports”, “finance”] |
The mannequin conceptually turns these into statements like:
- This textual content is about know-how.
- This textual content is about sports activities.
- This textual content is about finance.
It then compares the unique textual content towards every of those statements and scores how effectively they match. The label with the strongest rating is ranked highest. The identical thought could be utilized to many actual duties.
As a substitute of broad subject labels, an organization would possibly use labels equivalent to billing difficulty, technical help, or refund request for customer support messages, or spam, harassment, and protected for moderation programs.
So the vital shift is that this: zero-shot classification just isn’t actually handled as a standard classification downside. It’s handled extra like a reasoning downside about whether or not a label description matches the textual content. That can also be why it really works effectively for quick prototyping, low-resource duties, and domains the place labeled knowledge doesn’t but exist.
This is the reason wording issues. A label like billing difficulty typically works higher than a imprecise label like cash, as a result of the mannequin has extra semantic which means to work with. In actual use instances, clearer labels often result in higher efficiency, whether or not you’re classifying information subjects, buyer intents, moderation classes, or enterprise workflows.
Seeing the Zero-Shot Mannequin in Motion
On this part, we are going to learn to load a zero-shot classifier, run a primary instance, check multi-label predictions, and enhance outcomes with a customized speculation template.
1. Load the Zero-Shot Classification Pipeline
First, set up the required libraries:
|
pip set up torch transformers |
Now load the pipeline:
|
from transformers import pipeline
classifier = pipeline( “zero-shot-classification”, mannequin=“fb/bart-large-mnli” ) |
Loading the Transformers pipeline
Right here, the pipeline offers you a simple manner to make use of a pretrained zero-shot mannequin with out writing lower-level inference code your self. The mannequin used right here, fb/bart-large-mnli, is often used for zero-shot classification as a result of it’s educated to find out whether or not one piece of textual content helps one other.
2. Run a Easy Zero-Shot Instance
Let’s begin with a primary instance:
|
textual content = “This tutorial explains how transformer fashions are utilized in NLP.” candidate_labels = [“technology”, “health”, “sports”, “finance”] outcome = classifier(textual content, candidate_labels) print(f“High prediction: {outcome[‘labels’][0]} ({outcome[‘scores’][0]:.2%})”) |
Output:
|
High prediction: know-how (96.52%) |
This reveals the mannequin deciding on the label that finest matches the which means of the textual content. Because the sentence discusses transformer fashions and pure language processing, know-how is the strongest semantic match among the many candidate labels.
3. Classifying Textual content into A number of Labels
Typically a textual content belongs to a couple of class. In that case, you may allow multi_label=True:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
textual content = “The corporate launched a well being app and introduced sturdy enterprise development.”
candidate_labels = [“technology”, “healthcare”, “business”, “travel”]
outcome = classifier( textual content, candidate_labels, multi_label=True )
threshold = 0.50
top_labels = [ (label, score) for label, score in zip(result[“labels”], outcome[“scores”]) if rating >= threshold ]
print(“High labels:”, “, “.be a part of(f“{label} ({rating:.2%})” for label, rating in top_labels)) |
Output:
|
High labels: healthcare (99.41%), know-how (99.06%), enterprise (98.15%) |
That is helpful when a number of labels can apply to the identical enter. On this instance, the sentence just isn’t solely about know-how but in addition about healthcare and enterprise, so the mannequin assigns sturdy scores to all three labels.
4. Customizing the Speculation Template
It’s also possible to change the speculation template. The pipeline makes use of a default phrasing internally, however a clearer or extra pure template can typically enhance outcomes:
|
textual content = “The person can not entry their account and retains seeing a login error.”
candidate_labels = [“technical support”, “billing issue”, “feature request”]
outcome = classifier( textual content, candidate_labels, hypothesis_template=“This textual content is about {}.” )
for label, rating in zip(outcome[“labels”], outcome[“scores”]): print(f“{label}: {rating:.4f}”) |
Output:
|
technical help: 0.7349 characteristic request: 0.1683 billing difficulty: 0.0968 |
That is particularly useful when your labels are extra particular to an actual process. speculation template offers the mannequin a clearer assertion to guage, which might enhance how effectively it matches the textual content to the meant label.
Remaining Ideas
Zero-shot textual content classification is highly effective as a result of it removes the necessity for task-specific classifier coaching in lots of early-stage workflows. As a substitute of gathering labeled knowledge instantly, you may typically get helpful outcomes just by selecting clear candidate labels and letting the mannequin cause about them.
The important thing thought is simple: the mannequin just isn’t immediately predicting labels within the common classifier sense. It’s checking whether or not every label, written as a brief speculation, is supported by the textual content. That’s the reason MNLI-trained fashions like fb/bart-large-mnli work so effectively for this process.
In observe, the standard of your outcomes relies upon closely on how clearly you outline your labels. Sturdy label wording and a smart speculation template typically make a noticeable distinction. Whereas zero-shot classification is a superb start line, it really works finest whenever you think twice in regards to the semantics of the classes you need the mannequin to decide on between.
On this article, you’ll find out how zero-shot textual content classification works and how one can apply it utilizing a pretrained transformer mannequin.
Matters we are going to cowl embody:
- The core thought behind zero-shot classification and the way it reframes labeling as a reasoning process.
- The best way to use a pretrained mannequin to categorise textual content with out task-specific coaching knowledge.
- Sensible methods equivalent to multi-label classification and speculation template tuning.
Let’s get began.
Getting Began with Zero-Shot Textual content Classification
Picture by Editor
Introduction
Zero-shot textual content classification is a option to label textual content with out first coaching a classifier by yourself task-specific dataset. As a substitute of gathering examples for each class you need, you present the mannequin with a bit of textual content and an inventory of attainable labels. The mannequin then decides which label matches finest based mostly on its common language understanding.
This makes zero-shot classification particularly helpful whenever you wish to check an thought rapidly, work with altering label units, or construct a light-weight prototype earlier than investing in supervised coaching. Relatively than studying a hard and fast mapping from textual content to label IDs, the mannequin makes use of language itself to cause about what every label means.
On this information, we are going to perceive the primary thought behind zero-shot classification and run sensible examples utilizing fb/bart-large-mnli.
How Zero-Shot Works
The core thought behind zero-shot classification is that the mannequin doesn’t deal with labels as easy class names. As a substitute, it turns every label into a brief natural-language assertion and checks whether or not that assertion is supported by the enter textual content. This makes it particularly helpful in sensible conditions the place you wish to classify textual content rapidly with out gathering and labeling coaching knowledge first, equivalent to routing help tickets, tagging articles, detecting person intent, or organizing inside paperwork.
For instance, suppose the enter textual content is:
|
textual content = “The corporate launched a brand new AI platform for enterprise prospects.” |
And the candidate labels are:
|
labels = [“technology”, “sports”, “finance”] |
The mannequin conceptually turns these into statements like:
- This textual content is about know-how.
- This textual content is about sports activities.
- This textual content is about finance.
It then compares the unique textual content towards every of those statements and scores how effectively they match. The label with the strongest rating is ranked highest. The identical thought could be utilized to many actual duties.
As a substitute of broad subject labels, an organization would possibly use labels equivalent to billing difficulty, technical help, or refund request for customer support messages, or spam, harassment, and protected for moderation programs.
So the vital shift is that this: zero-shot classification just isn’t actually handled as a standard classification downside. It’s handled extra like a reasoning downside about whether or not a label description matches the textual content. That can also be why it really works effectively for quick prototyping, low-resource duties, and domains the place labeled knowledge doesn’t but exist.
This is the reason wording issues. A label like billing difficulty typically works higher than a imprecise label like cash, as a result of the mannequin has extra semantic which means to work with. In actual use instances, clearer labels often result in higher efficiency, whether or not you’re classifying information subjects, buyer intents, moderation classes, or enterprise workflows.
Seeing the Zero-Shot Mannequin in Motion
On this part, we are going to learn to load a zero-shot classifier, run a primary instance, check multi-label predictions, and enhance outcomes with a customized speculation template.
1. Load the Zero-Shot Classification Pipeline
First, set up the required libraries:
|
pip set up torch transformers |
Now load the pipeline:
|
from transformers import pipeline
classifier = pipeline( “zero-shot-classification”, mannequin=“fb/bart-large-mnli” ) |
Loading the Transformers pipeline
Right here, the pipeline offers you a simple manner to make use of a pretrained zero-shot mannequin with out writing lower-level inference code your self. The mannequin used right here, fb/bart-large-mnli, is often used for zero-shot classification as a result of it’s educated to find out whether or not one piece of textual content helps one other.
2. Run a Easy Zero-Shot Instance
Let’s begin with a primary instance:
|
textual content = “This tutorial explains how transformer fashions are utilized in NLP.” candidate_labels = [“technology”, “health”, “sports”, “finance”] outcome = classifier(textual content, candidate_labels) print(f“High prediction: {outcome[‘labels’][0]} ({outcome[‘scores’][0]:.2%})”) |
Output:
|
High prediction: know-how (96.52%) |
This reveals the mannequin deciding on the label that finest matches the which means of the textual content. Because the sentence discusses transformer fashions and pure language processing, know-how is the strongest semantic match among the many candidate labels.
3. Classifying Textual content into A number of Labels
Typically a textual content belongs to a couple of class. In that case, you may allow multi_label=True:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
textual content = “The corporate launched a well being app and introduced sturdy enterprise development.”
candidate_labels = [“technology”, “healthcare”, “business”, “travel”]
outcome = classifier( textual content, candidate_labels, multi_label=True )
threshold = 0.50
top_labels = [ (label, score) for label, score in zip(result[“labels”], outcome[“scores”]) if rating >= threshold ]
print(“High labels:”, “, “.be a part of(f“{label} ({rating:.2%})” for label, rating in top_labels)) |
Output:
|
High labels: healthcare (99.41%), know-how (99.06%), enterprise (98.15%) |
That is helpful when a number of labels can apply to the identical enter. On this instance, the sentence just isn’t solely about know-how but in addition about healthcare and enterprise, so the mannequin assigns sturdy scores to all three labels.
4. Customizing the Speculation Template
It’s also possible to change the speculation template. The pipeline makes use of a default phrasing internally, however a clearer or extra pure template can typically enhance outcomes:
|
textual content = “The person can not entry their account and retains seeing a login error.”
candidate_labels = [“technical support”, “billing issue”, “feature request”]
outcome = classifier( textual content, candidate_labels, hypothesis_template=“This textual content is about {}.” )
for label, rating in zip(outcome[“labels”], outcome[“scores”]): print(f“{label}: {rating:.4f}”) |
Output:
|
technical help: 0.7349 characteristic request: 0.1683 billing difficulty: 0.0968 |
That is particularly useful when your labels are extra particular to an actual process. speculation template offers the mannequin a clearer assertion to guage, which might enhance how effectively it matches the textual content to the meant label.
Remaining Ideas
Zero-shot textual content classification is highly effective as a result of it removes the necessity for task-specific classifier coaching in lots of early-stage workflows. As a substitute of gathering labeled knowledge instantly, you may typically get helpful outcomes just by selecting clear candidate labels and letting the mannequin cause about them.
The important thing thought is simple: the mannequin just isn’t immediately predicting labels within the common classifier sense. It’s checking whether or not every label, written as a brief speculation, is supported by the textual content. That’s the reason MNLI-trained fashions like fb/bart-large-mnli work so effectively for this process.
In observe, the standard of your outcomes relies upon closely on how clearly you outline your labels. Sturdy label wording and a smart speculation template typically make a noticeable distinction. Whereas zero-shot classification is a superb start line, it really works finest whenever you think twice in regards to the semantics of the classes you need the mannequin to decide on between.














{kind=link}