


On this article, you’ll learn the way AI agent reminiscence works throughout working reminiscence, exterior reminiscence, and scalable reminiscence architectures for constructing brokers that enhance over time.
Subjects we’ll cowl embrace:
- The reminiscence drawback in stateless giant language model-based brokers.
- How in-context, episodic, semantic, and procedural reminiscence assist agent conduct.
- How retrieval, reminiscence writing, decay dealing with, and multi-agent consistency make reminiscence work at scale.
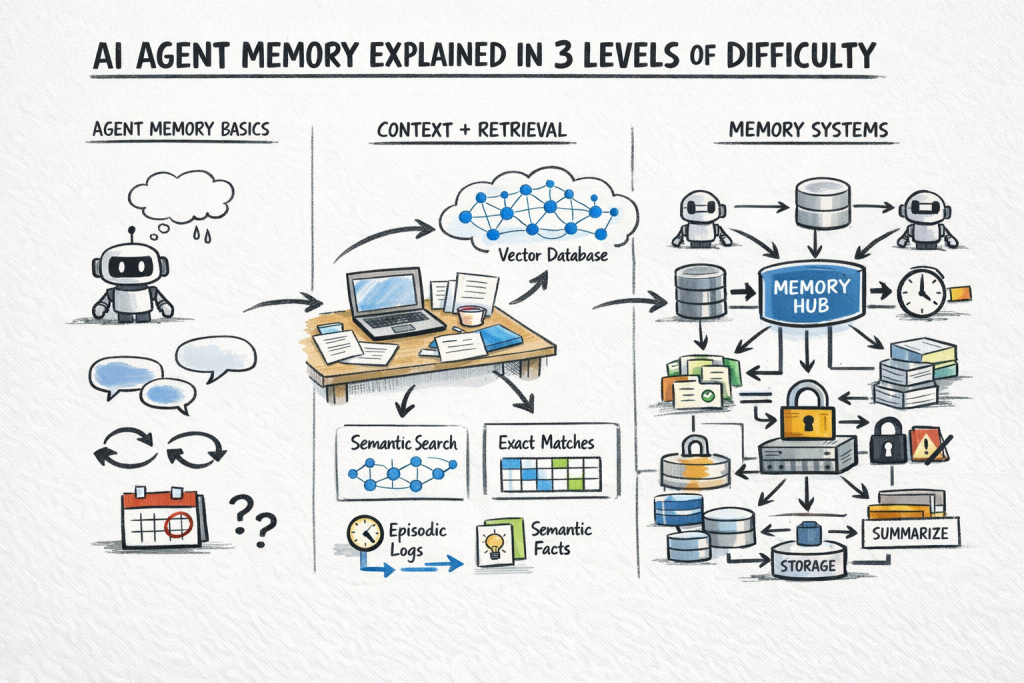
AI Agent Reminiscence Defined in 3 Ranges of Issue
Picture by Writer
Introduction
A stateless AI agent has no reminiscence of earlier calls. Each request begins from scratch. This works superb for remoted duties, nevertheless it turns into an issue when an agent wants to trace choices, bear in mind consumer preferences, or choose up the place it left off.
The problem is that reminiscence in AI brokers is a group of various mechanisms that serve completely different functions. These mechanisms additionally function at completely different timescales — some are scoped to a single dialog, whereas others persist indefinitely. The way you mix them determines whether or not your agent stays helpful throughout periods.
This text explains AI agent reminiscence at three ranges: what reminiscence means for an agent and why it’s arduous, how the principle reminiscence sorts work in observe, and eventually, the architectural patterns and retrieval methods that make persistent, dependable reminiscence work at scale.
Stage 1: Understanding The Reminiscence Downside In AI Brokers
A big language mannequin has no persistent state. Each name to the API is stateless: the mannequin receives a block of textual content, or context window, processes it, returns a response, and retains nothing. There isn’t a inner retailer being up to date between calls.
That is superb for answering a one-off query. It’s a elementary drawback for something agent-like: a system that takes multi-step actions, learns from suggestions, or coordinates work throughout many periods.
The next 4 questions make the reminiscence drawback concrete:
- What occurred earlier than? An agent that books calendar occasions must know what’s already scheduled. If it doesn’t bear in mind, it double-books.
- What does this consumer need? A writing assistant that doesn’t bear in mind your most well-liked tone and elegance resets to generic conduct each session.
- What has the agent already tried? A analysis agent that doesn’t bear in mind failed search queries will repeat the identical lifeless ends.
- What info has the agent amassed? An agent that discovers mid-task {that a} file is lacking must file that and issue it into future steps.
The reminiscence drawback is the issue of giving an inherently stateless system the power to behave as if it has persistent, queryable data concerning the previous.
Stage 2: The Sorts Of Agent Reminiscence
In-Context Reminiscence Or Working Reminiscence
The only type: every thing within the context window proper now. The dialog historical past, instrument name outcomes, system immediate, related paperwork — all of it will get handed to the mannequin as textual content on each name.
That is precise and rapid. The mannequin can motive over something in context with excessive constancy. There isn’t a retrieval step, no approximation, and no likelihood of pulling the flawed file. The constraint is context window dimension. Present fashions assist 128K to 1M tokens, however prices and latency scale with size, so you can not merely dump every thing in and name it finished.
In observe, in-context reminiscence works greatest for the energetic state of a job: the present dialog, current instrument outputs, and paperwork straight related to the rapid step.
Exterior Reminiscence
For info too giant, too previous, or too dynamic to maintain in context always, brokers question an exterior retailer and pull in what’s related when wanted. That is retrieval-augmented era (RAG) utilized to agent reminiscence.
Two retrieval patterns serve completely different wants:
Semantic search over a vector database finds data related in that means to the present question.
Precise lookup towards a relational or key-value retailer retrieves structured info by attribute — consumer preferences, job state, prior choices, and entity data.
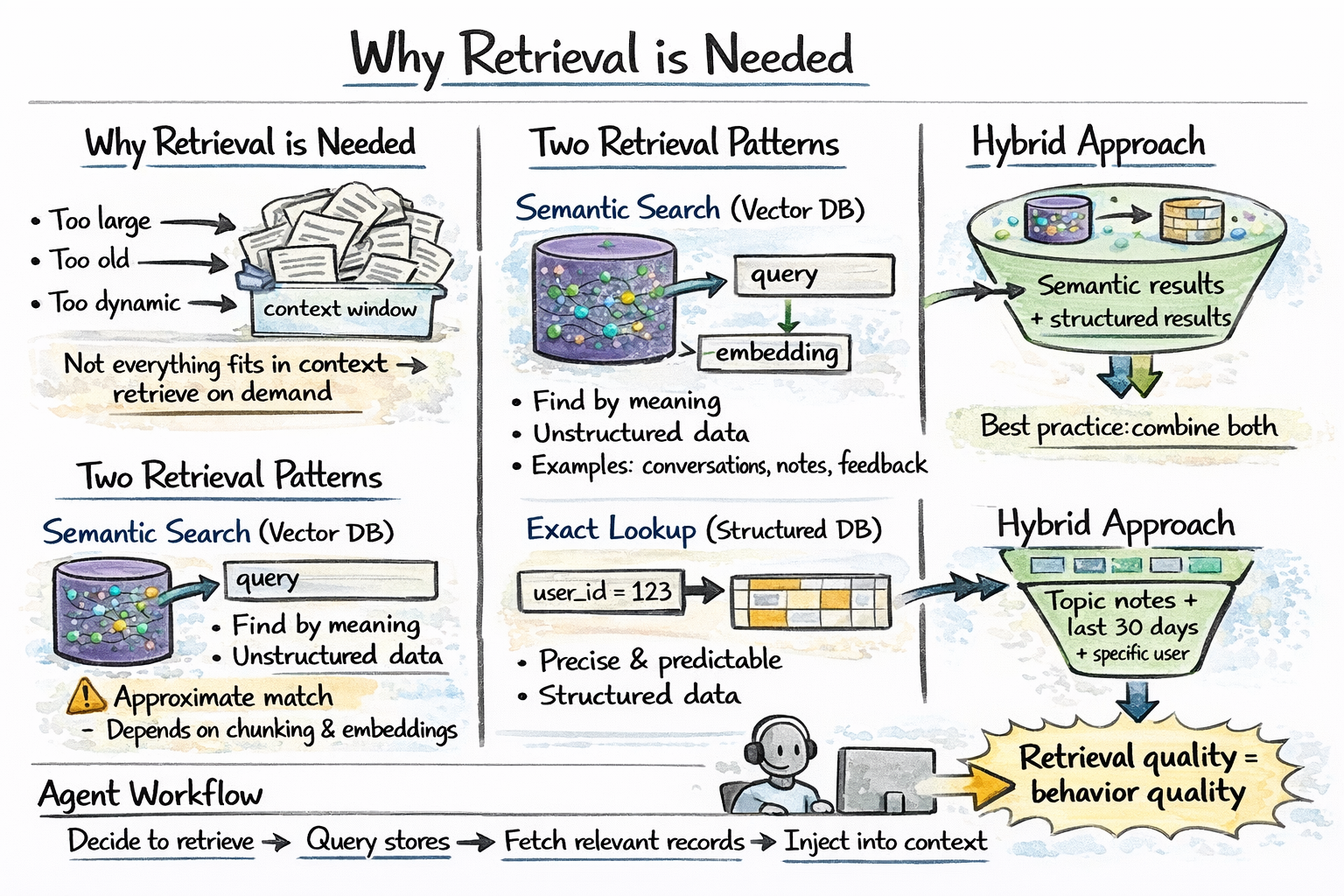
Agent reminiscence retrieval step
In observe, essentially the most sturdy agent reminiscence programs use each together: run a vector search and a structured question as wanted, then merge the outcomes.
Stage 3 focuses on making reminiscence programs work in real-world manufacturing. It goes past primary reminiscence sorts and tackles sensible challenges: construction reminiscence extra granularly, what info to retailer and when, reliably retrieve the precise information at scale, and deal with points like stale information or a number of brokers writing to the identical system.
Briefly, it’s concerning the structure and methods that guarantee reminiscence really improves an agent’s efficiency.
Stage 3: AI Agent Reminiscence Structure At Scale
What Wants To Be Saved
Not all info deserves the identical therapy, and it’s price being exact about what you’re really storing. Agent reminiscence naturally falls into a couple of classes:
Episodic reminiscence captures what occurred: particular occasions, instrument calls, and their outcomes.
Semantic reminiscence captures what’s true: info and preferences extracted from expertise.
Procedural reminiscence captures do issues. It encodes realized motion patterns, profitable methods, and identified failure modes.
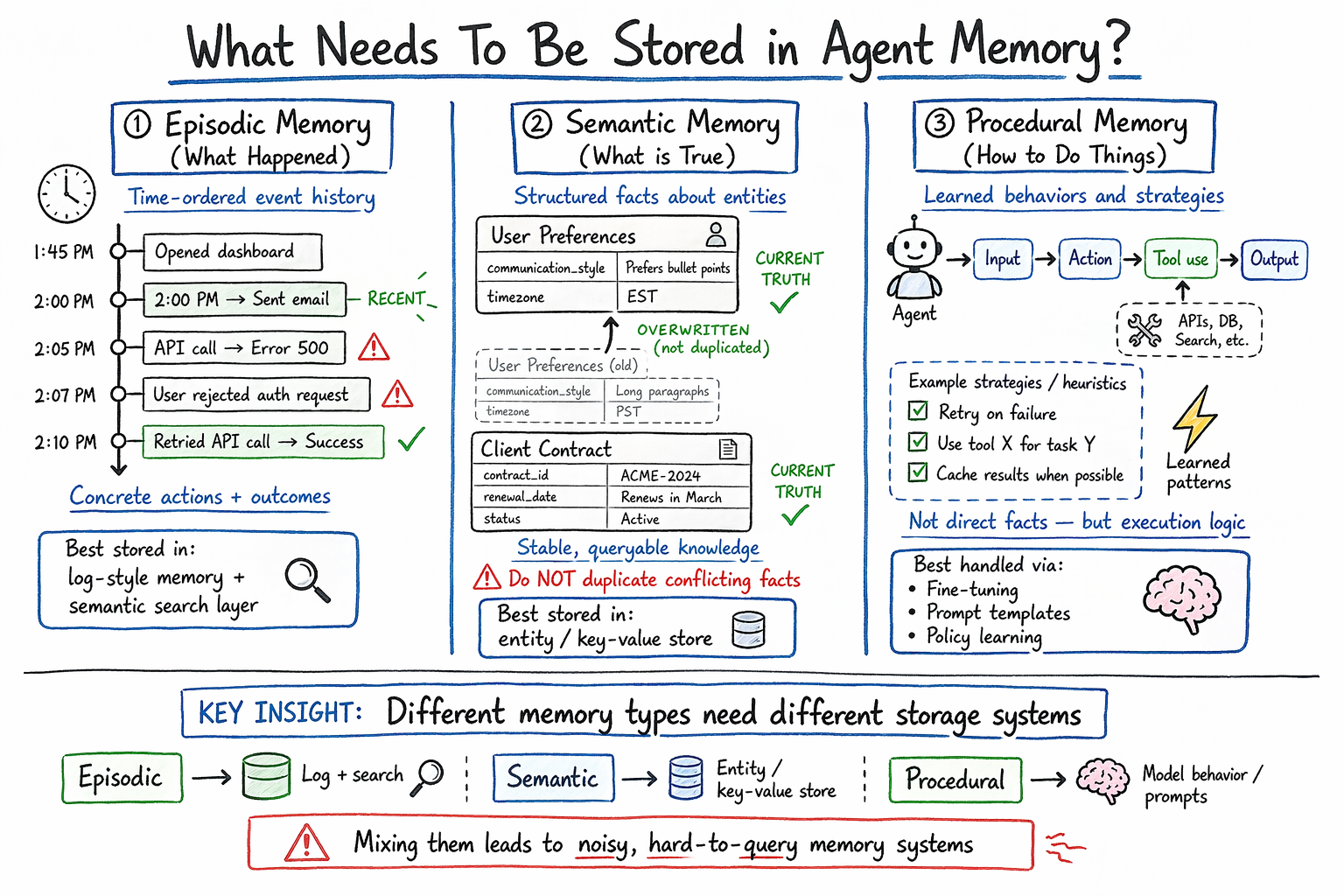
An summary of AI agent reminiscence sorts
Writing To Reminiscence: When And What To Retailer
An agent that writes each token of each interplay to reminiscence produces noise at scale. Reminiscence needs to be selective. The next are two widespread patterns:
Finish-of-session summarization: After every session, the agent or a devoted summarization step extracts salient info, choices, and outcomes and writes them as compact reminiscence data.
Occasion-triggered writes: Sure occasions explicitly set off reminiscence writes — consumer corrections, express choice statements, job completions, and error situations.
What to not retailer: uncooked transcripts at scale, intermediate reasoning traces that don’t have an effect on future conduct, or redundant duplicates of present data.
Retrieving From Reminiscence: Getting The Proper Context
Right here is an outline of the three predominant retrieval methods:
Vector similarity search queries the reminiscence retailer with an embedding of the present context and returns the top-Ok most semantically related data. That is quick, approximate, and works nicely for unstructured reminiscence. It additionally requires an embedding mannequin and a vector index like HNSW or IVF-based. High quality relies on chunking technique and embedding mannequin.
Structured question retrieves info by attribute — consumer ID, time vary, entity identify. Exact when you already know what you’re in search of. This doesn’t deal with semantic drift. Works with SQL or key-value lookups.
Hybrid retrieval combines each: run a vector search and a structured question in parallel and merge the outcomes. Helpful when reminiscences have each semantic content material and structured metadata, like discovering reminiscences about billing points from the final 30 days for this consumer.
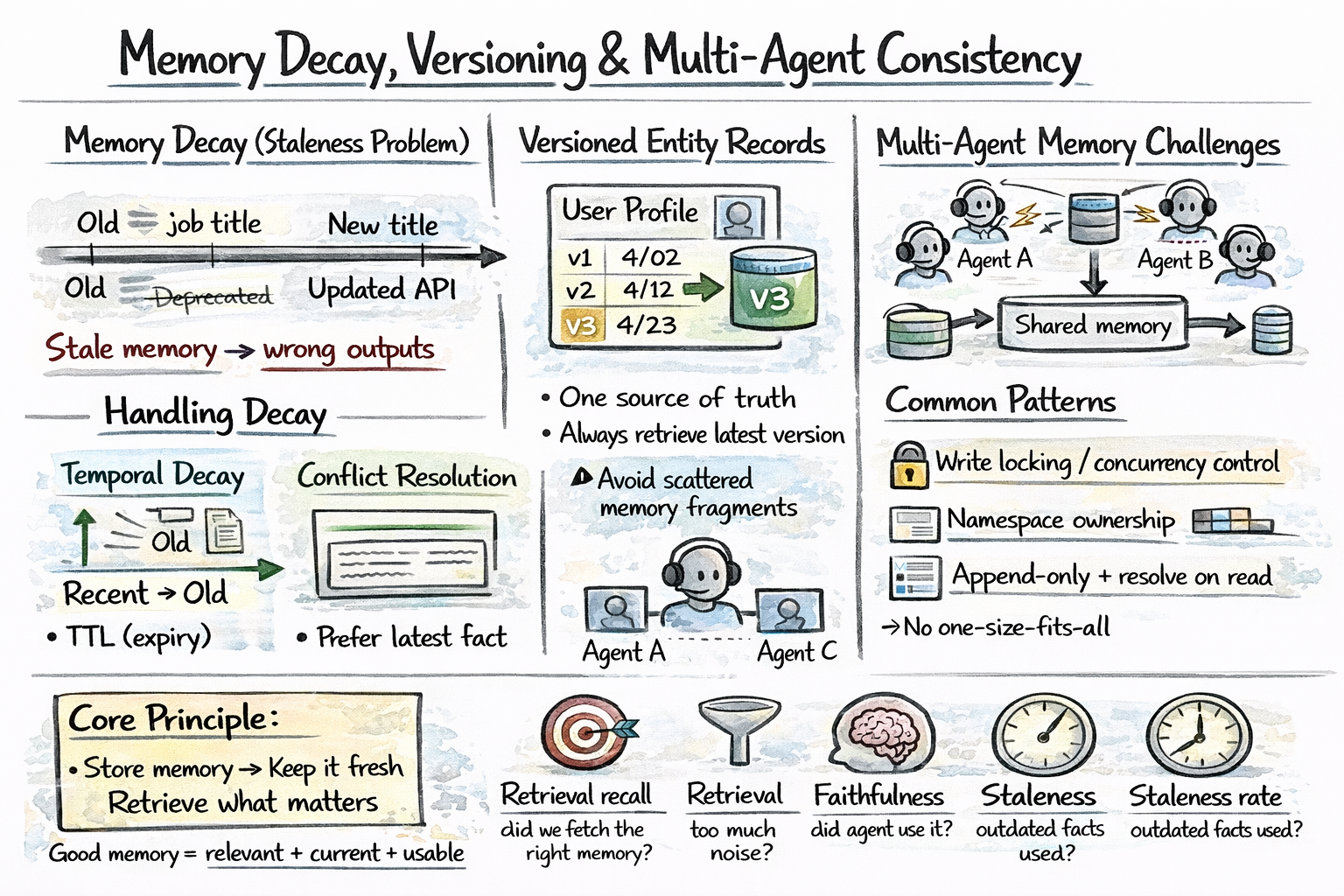
Reminiscence Decay And Versioning
Reminiscences grow to be stale. A consumer’s job title modifications. A beforehand right API endpoint will get deprecated. An agent that surfaces outdated reminiscences causes errors downstream. You want some methods to deal with it, and listed below are essentially the most related:
Temporal decay: Weight current reminiscences extra closely than previous ones.
Versioned entity data: Preserve a versioned entity retailer so updates overwrite prior values with timestamps.
Multi-Agent Reminiscence
When a number of brokers share reminiscence — a coordinator and a number of other subagents working in parallel — consistency turns into the arduous drawback. Listed below are widespread approaches:
- Central reminiscence: Use locking or optimistic concurrency to manage writes
- Namespaces: Every agent writes to its personal reminiscence area
- Append-only logs: Retailer all modifications and resolve conflicts at learn time
There’s no single greatest answer; it relies on how brokers run and share state. Learn Why Multi-Agent Methods Want Reminiscence Engineering to study extra.
Reminiscence decay, versioning, and multi-agent consistency
Analysis
Reminiscence programs usually fail silently. The agent retrieves one thing flawed, causes from it, and produces a plausible-sounding flawed reply. Listed below are some metrics price monitoring:
- Retrieval recall measures whether or not the system surfaces related reminiscence when it exists.
- Retrieval precision measures whether or not it additionally pulls in noise.
- Faithfulness measures whether or not the agent makes use of retrieved reminiscence in its reasoning.
- Staleness charge measures how usually the agent surfaces an outdated truth.
Efficient reminiscence administration, in essence, is all about storing info whereas preserving it related and retrievable.
Wrapping Up
Agent reminiscence capabilities like a stack. In-context reminiscence maintains present working state, whereas exterior retrieval brings in related historical past and info. The engineering problem lies in figuring out what to file, when to set off retrieval, and preserve a clear, helpful reminiscence because it grows.
Listed below are a couple of sources for additional studying:
Completely satisfied studying and constructing!
On this article, you’ll learn the way AI agent reminiscence works throughout working reminiscence, exterior reminiscence, and scalable reminiscence architectures for constructing brokers that enhance over time.
Subjects we’ll cowl embrace:
- The reminiscence drawback in stateless giant language model-based brokers.
- How in-context, episodic, semantic, and procedural reminiscence assist agent conduct.
- How retrieval, reminiscence writing, decay dealing with, and multi-agent consistency make reminiscence work at scale.
AI Agent Reminiscence Defined in 3 Ranges of Issue
Picture by Writer
Introduction
A stateless AI agent has no reminiscence of earlier calls. Each request begins from scratch. This works superb for remoted duties, nevertheless it turns into an issue when an agent wants to trace choices, bear in mind consumer preferences, or choose up the place it left off.
The problem is that reminiscence in AI brokers is a group of various mechanisms that serve completely different functions. These mechanisms additionally function at completely different timescales — some are scoped to a single dialog, whereas others persist indefinitely. The way you mix them determines whether or not your agent stays helpful throughout periods.
This text explains AI agent reminiscence at three ranges: what reminiscence means for an agent and why it’s arduous, how the principle reminiscence sorts work in observe, and eventually, the architectural patterns and retrieval methods that make persistent, dependable reminiscence work at scale.
Stage 1: Understanding The Reminiscence Downside In AI Brokers
A big language mannequin has no persistent state. Each name to the API is stateless: the mannequin receives a block of textual content, or context window, processes it, returns a response, and retains nothing. There isn’t a inner retailer being up to date between calls.
That is superb for answering a one-off query. It’s a elementary drawback for something agent-like: a system that takes multi-step actions, learns from suggestions, or coordinates work throughout many periods.
The next 4 questions make the reminiscence drawback concrete:
- What occurred earlier than? An agent that books calendar occasions must know what’s already scheduled. If it doesn’t bear in mind, it double-books.
- What does this consumer need? A writing assistant that doesn’t bear in mind your most well-liked tone and elegance resets to generic conduct each session.
- What has the agent already tried? A analysis agent that doesn’t bear in mind failed search queries will repeat the identical lifeless ends.
- What info has the agent amassed? An agent that discovers mid-task {that a} file is lacking must file that and issue it into future steps.
The reminiscence drawback is the issue of giving an inherently stateless system the power to behave as if it has persistent, queryable data concerning the previous.
Stage 2: The Sorts Of Agent Reminiscence
In-Context Reminiscence Or Working Reminiscence
The only type: every thing within the context window proper now. The dialog historical past, instrument name outcomes, system immediate, related paperwork — all of it will get handed to the mannequin as textual content on each name.
That is precise and rapid. The mannequin can motive over something in context with excessive constancy. There isn’t a retrieval step, no approximation, and no likelihood of pulling the flawed file. The constraint is context window dimension. Present fashions assist 128K to 1M tokens, however prices and latency scale with size, so you can not merely dump every thing in and name it finished.
In observe, in-context reminiscence works greatest for the energetic state of a job: the present dialog, current instrument outputs, and paperwork straight related to the rapid step.
Exterior Reminiscence
For info too giant, too previous, or too dynamic to maintain in context always, brokers question an exterior retailer and pull in what’s related when wanted. That is retrieval-augmented era (RAG) utilized to agent reminiscence.
Two retrieval patterns serve completely different wants:
Semantic search over a vector database finds data related in that means to the present question.
Precise lookup towards a relational or key-value retailer retrieves structured info by attribute — consumer preferences, job state, prior choices, and entity data.
Agent reminiscence retrieval step
In observe, essentially the most sturdy agent reminiscence programs use each together: run a vector search and a structured question as wanted, then merge the outcomes.
Stage 3 focuses on making reminiscence programs work in real-world manufacturing. It goes past primary reminiscence sorts and tackles sensible challenges: construction reminiscence extra granularly, what info to retailer and when, reliably retrieve the precise information at scale, and deal with points like stale information or a number of brokers writing to the identical system.
Briefly, it’s concerning the structure and methods that guarantee reminiscence really improves an agent’s efficiency.
Stage 3: AI Agent Reminiscence Structure At Scale
What Wants To Be Saved
Not all info deserves the identical therapy, and it’s price being exact about what you’re really storing. Agent reminiscence naturally falls into a couple of classes:
Episodic reminiscence captures what occurred: particular occasions, instrument calls, and their outcomes.
Semantic reminiscence captures what’s true: info and preferences extracted from expertise.
Procedural reminiscence captures do issues. It encodes realized motion patterns, profitable methods, and identified failure modes.
An summary of AI agent reminiscence sorts
Writing To Reminiscence: When And What To Retailer
An agent that writes each token of each interplay to reminiscence produces noise at scale. Reminiscence needs to be selective. The next are two widespread patterns:
Finish-of-session summarization: After every session, the agent or a devoted summarization step extracts salient info, choices, and outcomes and writes them as compact reminiscence data.
Occasion-triggered writes: Sure occasions explicitly set off reminiscence writes — consumer corrections, express choice statements, job completions, and error situations.
What to not retailer: uncooked transcripts at scale, intermediate reasoning traces that don’t have an effect on future conduct, or redundant duplicates of present data.
Retrieving From Reminiscence: Getting The Proper Context
Right here is an outline of the three predominant retrieval methods:
Vector similarity search queries the reminiscence retailer with an embedding of the present context and returns the top-Ok most semantically related data. That is quick, approximate, and works nicely for unstructured reminiscence. It additionally requires an embedding mannequin and a vector index like HNSW or IVF-based. High quality relies on chunking technique and embedding mannequin.
Structured question retrieves info by attribute — consumer ID, time vary, entity identify. Exact when you already know what you’re in search of. This doesn’t deal with semantic drift. Works with SQL or key-value lookups.
Hybrid retrieval combines each: run a vector search and a structured question in parallel and merge the outcomes. Helpful when reminiscences have each semantic content material and structured metadata, like discovering reminiscences about billing points from the final 30 days for this consumer.
Reminiscence Decay And Versioning
Reminiscences grow to be stale. A consumer’s job title modifications. A beforehand right API endpoint will get deprecated. An agent that surfaces outdated reminiscences causes errors downstream. You want some methods to deal with it, and listed below are essentially the most related:
Temporal decay: Weight current reminiscences extra closely than previous ones.
Versioned entity data: Preserve a versioned entity retailer so updates overwrite prior values with timestamps.
Multi-Agent Reminiscence
When a number of brokers share reminiscence — a coordinator and a number of other subagents working in parallel — consistency turns into the arduous drawback. Listed below are widespread approaches:
- Central reminiscence: Use locking or optimistic concurrency to manage writes
- Namespaces: Every agent writes to its personal reminiscence area
- Append-only logs: Retailer all modifications and resolve conflicts at learn time
There’s no single greatest answer; it relies on how brokers run and share state. Learn Why Multi-Agent Methods Want Reminiscence Engineering to study extra.
Reminiscence decay, versioning, and multi-agent consistency
Analysis
Reminiscence programs usually fail silently. The agent retrieves one thing flawed, causes from it, and produces a plausible-sounding flawed reply. Listed below are some metrics price monitoring:
- Retrieval recall measures whether or not the system surfaces related reminiscence when it exists.
- Retrieval precision measures whether or not it additionally pulls in noise.
- Faithfulness measures whether or not the agent makes use of retrieved reminiscence in its reasoning.
- Staleness charge measures how usually the agent surfaces an outdated truth.
Efficient reminiscence administration, in essence, is all about storing info whereas preserving it related and retrievable.
Wrapping Up
Agent reminiscence capabilities like a stack. In-context reminiscence maintains present working state, whereas exterior retrieval brings in related historical past and info. The engineering problem lies in figuring out what to file, when to set off retrieval, and preserve a clear, helpful reminiscence because it grows.
Listed below are a couple of sources for additional studying:
Completely satisfied studying and constructing!
















{kind=link}