


Section Something Mannequin 3 (SAM3) despatched a shockwave via the pc imaginative and prescient neighborhood. Social media feeds had been rightfully flooded with reward for its efficiency. SAM3 isn’t simply an incremental replace; it introduces Promptable Idea Segmentation (PCS), a imaginative and prescient language structure that permits customers to section objects utilizing pure language prompts. From its 3D capabilities (SAM3D) to its native video monitoring, it’s undeniably a masterpiece of normal function AI.
Nevertheless, on this planet of manufacturing grade AI, pleasure can usually blur the road between zero-shot functionality and sensible dominance. Following the discharge, many claimed that coaching in home detectors is now not needed. As an engineer who has spent years deploying fashions within the area, I felt a well-known skepticism. Whereas a basis mannequin is the final word Swiss Military Knife, you don’t use it to chop down a forest when you could have a chainsaw. This text investigates a query that’s usually implied in analysis papers however not often examined towards the constraints of a manufacturing atmosphere.
Can a small, task-specific mannequin skilled with restricted knowledge and a 6-hour compute price range outperform an enormous, general-purpose large like SAM3 in a totally autonomous setting?
To these within the trenches of Pc Imaginative and prescient, the instinctive reply is Sure. However in an trade pushed by knowledge, intuition isn’t sufficient therefore, I made a decision to show it.
What’s New in SAM3?

Earlier than diving into the benchmarks, we have to perceive why SAM3 is taken into account such a leap ahead. SAM3 is a heavyweight basis mannequin, packing 840.50975 million parameters. This scale comes with a value, inference is computationally costly. On a NVIDIA P100 GPU, it runs at roughly ~1100 ms per picture.
Whereas the predecessor SAM centered on The place (interactive clicks, packing containers, and masks), SAM3 introduces a Imaginative and prescient–Language element that allows What reasoning via text-driven, open-vocabulary prompts.
In brief, SAM3 transforms from an interactive assistant right into a zero shot system. It doesn’t want a predefined label record; it operates on the fly. This makes it a dream software for picture enhancing and guide annotation. However the query stays, does this huge, normal function mind truly outperform a lean specialist when the duty is slender and the atmosphere is autonomous?
Benchmarks
To pit SAM3 towards domain-trained fashions, I chosen a complete of 5 datasets spanning throughout three domains: Object Detection, Occasion Segmentation, and Saliency Object Detection. To maintain the comparability truthful and grounded in actuality I outlined the next standards for the coaching course of.
- Honest Grounds for SAM3: The dataset classes must be detectable by SAM3 out of the field. We need to check SAM3 at its strengths. For instance SAM3 can precisely determine a shark versus a whale. Nevertheless, asking it to tell apart between a blue whale and a fin whale could be unfair.
- Minimal Hyperparameter Tuning: I used preliminary guesses for many parameters with little to no fine-tuning. This simulates a fast begin state of affairs for an engineer.
- Strict Compute Finances: The specialist fashions had been skilled inside a most window of 6 hours. This satisfies the situation of utilizing minimal and accessible computing sources.
- Immediate Power: For each dataset I examined the SAM3 prompts towards 10 randomly chosen photos. I solely finalized a immediate as soon as I used to be happy that SAM3 was detecting the objects correctly on these samples. In case you are skeptical, you possibly can decide random photos from these datasets and check my prompts within the SAM3 demo to substantiate this unbiased strategy.
The next desk exhibits the weighted common of particular person metrics for every case. In case you are in a rush, this desk gives the high-level image of the efficiency and pace trade-offs. You possibly can see all of the WandDB runs right here.

Let’s discover the nuances of every use case and see why the numbers look this manner.
Object Detection
On this use case we benchmark datasets utilizing solely bounding packing containers. That is the commonest activity in manufacturing environments.
For our analysis metrics, we use the usual COCO metrics computed with bounding field primarily based IoU. To find out an general winner throughout completely different datasets, I take advantage of a weighted sum of those metrics. I assigned the very best weight to mAP (imply Common Precision) because it gives probably the most complete snapshot of a mannequin’s precision and recall steadiness. Whereas the weights assist us decide an general winner you possibly can see how every mannequin festivals towards the opposite in each particular person class.
1. International Wheat Detection
The primary publish I noticed on LinkedIn concerning SAM3 efficiency was truly about this dataset. That particular publish sparked my thought to conduct a benchmark somewhat than basing my opinion on a couple of anecdotes.
This dataset holds a particular place for me as a result of it was the primary competitors I participated in again in 2020. On the time I used to be a inexperienced engineer recent off Andrew Ng’s Deep Studying Specialization. I had extra motivation than coding ability and I foolishly determined to implement YOLOv3 from scratch. My implementation was a catastrophe with a recall of ~10% and I did not make a single profitable submission. Nevertheless, I realized extra from that failure than any tutorial might educate me. Selecting this dataset once more was a pleasant journey down reminiscence lane and a measurable technique to see how far I’ve grown.
For the prepare val cut up I randomly divided the offered knowledge right into a 90-10 ratio to make sure each fashions had been evaluated on the very same photos. The ultimate rely was 3035 photos for coaching and 338 photos for validation.
I used Ultralytics YOLOv11-Massive and offered COCO pretrained weights as a place to begin and skilled the mannequin for 30 epochs with default hyperparameters. The coaching course of was accomplished in simply 2 hours quarter-hour.
The uncooked knowledge exhibits SAM3 trailing YOLO by 17% general, however the visible outcomes inform a extra complicated story. SAM3 predictions are generally tight, binding carefully to the wheat head.
In distinction, the YOLO mannequin predicts barely bigger packing containers that embody the awns (the hair bristles). As a result of the dataset annotations embrace these awns, the YOLO mannequin is technically extra appropriate in keeping with the use case, which explains why it leads in excessive IoU metrics. This additionally explains why SAM3 seems to dominate YOLO within the Small Object class (an 132% lead). To make sure a good comparability regardless of this bounding field mismatch, we must always have a look at AP50. At a 0.5 IoU threshold, SAM3 loses by 12.4%.
Whereas my YOLOv11 mannequin struggled with the smallest wheat heads, a difficulty that might be solved by including a P2 excessive decision detection head The specialist mannequin nonetheless received nearly all of classes in an actual world utilization state of affairs.
| Metric | yolov11-large | SAM3 | % Change |
|---|---|---|---|
| AP | 0.4098 | 0.315 | -23.10 |
| AP50 | 0.8821 | 0.7722 | -12.40 |
| AP75 | 0.3011 | 0.1937 | -35.60 |
| AP small | 0.0706 | 0.0649 | -8.00 |
| AP medium | 0.4013 | 0.3091 | -22.90 |
| AP massive | 0.464 | 0.3592 | -22.50 |
| AR 1 | 0.0145 | 0.0122 | -15.90 |
| AR 10 | 0.1311 | 0.1093 | -16.60 |
| AR 100 | 0.479 | 0.403 | -15.80 |
| AR small | 0.0954 | 0.2214 | +132 |
| AR medium | 0.4617 | 0.4002 | -13.30 |
| AR massive | 0.5661 | 0.4233 | -25.20 |
On the hidden competitors check set the specialist mannequin outperformed SAM3 by vital margins as effectively.
| Mannequin | Public LB Rating | Non-public LB Rating |
|---|---|---|
| yolov11-large | 0.677 | 0.5213 |
| SAM3 | 0.4647 | 0.4507 |
| Change | -31.36 | -13.54 |
Execution Particulars:
2. CCTV Weapon Detection
I selected this dataset to benchmark SAM3 on surveillance model imagery and to reply a important query: Does a basis mannequin make extra sense when knowledge is extraordinarily scarce?
The dataset consists of solely 131 photos captured from CCTV cameras throughout six completely different places. As a result of photos from the identical digicam feed are extremely correlated I made a decision to separate the info on the scene stage somewhat than the picture stage. This ensures the validation set comprises completely unseen environments which is a greater check of a mannequin’s robustness. I used 4 scenes for coaching and two for validation leading to 111 coaching photos and 30 validation photos.
For this activity I used YOLOv11-Medium. To forestall overfitting on such a tiny pattern dimension I made a number of particular engineering selections:
- Spine Freezing: I froze your complete spine to protect the COCO pretrained options. With solely 111 photos unfreezing the spine would probably corrupt the weights and result in unstable coaching.
- Regularization: I elevated weight decay and used extra intensive knowledge augmentation to power the mannequin to generalize.
- Studying Charge Adjustment: I lowered each the preliminary and last studying charges to make sure the head of the mannequin converged gently on the brand new options.
The whole coaching course of took solely 8 minutes for 50 epochs. Although I structured this experiment as a probable win for SAM3 the outcomes had been shocking. The specialist mannequin outperformed SAM3 in each single class shedding to YOLO by 20.50% general.
| Metric | yolov11-medium | SAM3 | Change |
|---|---|---|---|
| AP | 0.4082 | 0.3243 | -20.57 |
| AP50 | 0.831 | 0.5784 | -30.4 |
| AP75 | 0.3743 | 0.3676 | -1.8 |
| AP_small | – | – | – |
| AP_medium | 0.351 | 0.24 | -31.64 |
| AP_large | 0.5338 | 0.4936 | -7.53 |
| AR_1 | 0.448 | 0.368 | -17.86 |
| AR_10 | 0.452 | 0.368 | -18.58 |
| AR_100 | 0.452 | 0.368 | -18.58 |
| AR_small | – | – | – |
| AR_medium | 0.4059 | 0.2941 | -27.54 |
| AR_large | 0.55 | 0.525 | -4.55 |
This implies that for particular excessive stakes duties like weapon detection even a handful of area particular photos can present higher baseline than an enormous normal function mannequin.
Execution Particulars:
Occasion Segmentation
On this use case we benchmark datasets with instance-level segmentation masks and polygons. For our analysis, we use the usual COCO metrics computed with masks primarily based IoU. Just like the thing detection part I take advantage of a weighted sum of those metrics to find out the ultimate rankings.
A major hurdle in benchmarking occasion segmentation is that many prime quality datasets solely present semantic masks. To create a good check for SAM3 and YOLOv11, I chosen datasets the place the objects have clear spatial gaps between them. I wrote a preprocessing pipeline to transform these semantic masks into occasion stage labels by figuring out particular person related parts. I then formatted these as a COCO Polygon dataset. This allowed us to measure how effectively the fashions distinguish between particular person issues somewhat than simply figuring out stuff.
1. Concrete Crack Segmentation
I selected this dataset as a result of it represents a major problem for each fashions. Cracks have extremely irregular shapes and branching paths which might be notoriously troublesome to seize precisely. The ultimate cut up resulted in 9603 photos for coaching and 1695 photos for validation.
The unique labels for the cracks had been extraordinarily effective. To coach on such skinny buildings successfully, I might have wanted to make use of a really excessive enter decision which was not possible inside my compute price range. To resolve this, I utilized a morphological transformation to thicken the masks. This allowed the mannequin to study the crack buildings at a decrease decision whereas sustaining acceptable outcomes. To make sure a good comparability I utilized the very same transformation to the SAM3 output. Since SAM3 performs inference at excessive decision and detects effective particulars, thickening its masks ensured we had been evaluating apples to apples throughout analysis.
I skilled a YOLOv11-Medium-Seg mannequin for 30 epochs. I maintained default settings for many hyperparameters which resulted in a complete coaching time of 5 hours 20 minutes.
The specialist mannequin outperformed SAM 3 with an general rating distinction of 47.69%. Most notably, SAM 3 struggled with recall, falling behind the YOLO mannequin by over 33%. This implies that whereas SAM 3 can determine cracks in a normal sense, it lacks the area particular sensitivity required to map out exhaustive fracture networks in an autonomous setting.
Nevertheless, visible evaluation suggests we must always take this dramatic 47.69% hole with a grain of salt. Even after publish processing, SAM 3 produces thinner masks than the YOLO mannequin and SAM3 is probably going being penalized for its effective segmentations. Whereas YOLO would nonetheless win this benchmark, a extra refined masks adjusted metric would probably place the precise efficiency distinction nearer to 25%.
| Metric | yolov11-medium | SAM3 | Change |
|---|---|---|---|
| AP | 0.2603 | 0.1089 | -58.17 |
| AP50 | 0.6239 | 0.3327 | -46.67 |
| AP75 | 0.1143 | 0.0107 | -90.67 |
| AP_small | 0.06 | 0.01 | -83.28 |
| AP_medium | 0.2913 | 0.1575 | -45.94 |
| AP_large | 0.3384 | 0.1041 | -69.23 |
| AR_1 | 0.2657 | 0.1543 | -41.94 |
| AR_10 | 0.3281 | 0.2119 | -35.41 |
| AR_100 | 0.3286 | 0.2192 | -33.3 |
| AR_small | 0.0633 | 0.0466 | -26.42 |
| AR_medium | 0.3078 | 0.2237 | -27.31 |
| AR_large | 0.4626 | 0.2725 | -41.1 |
Execution Particulars:
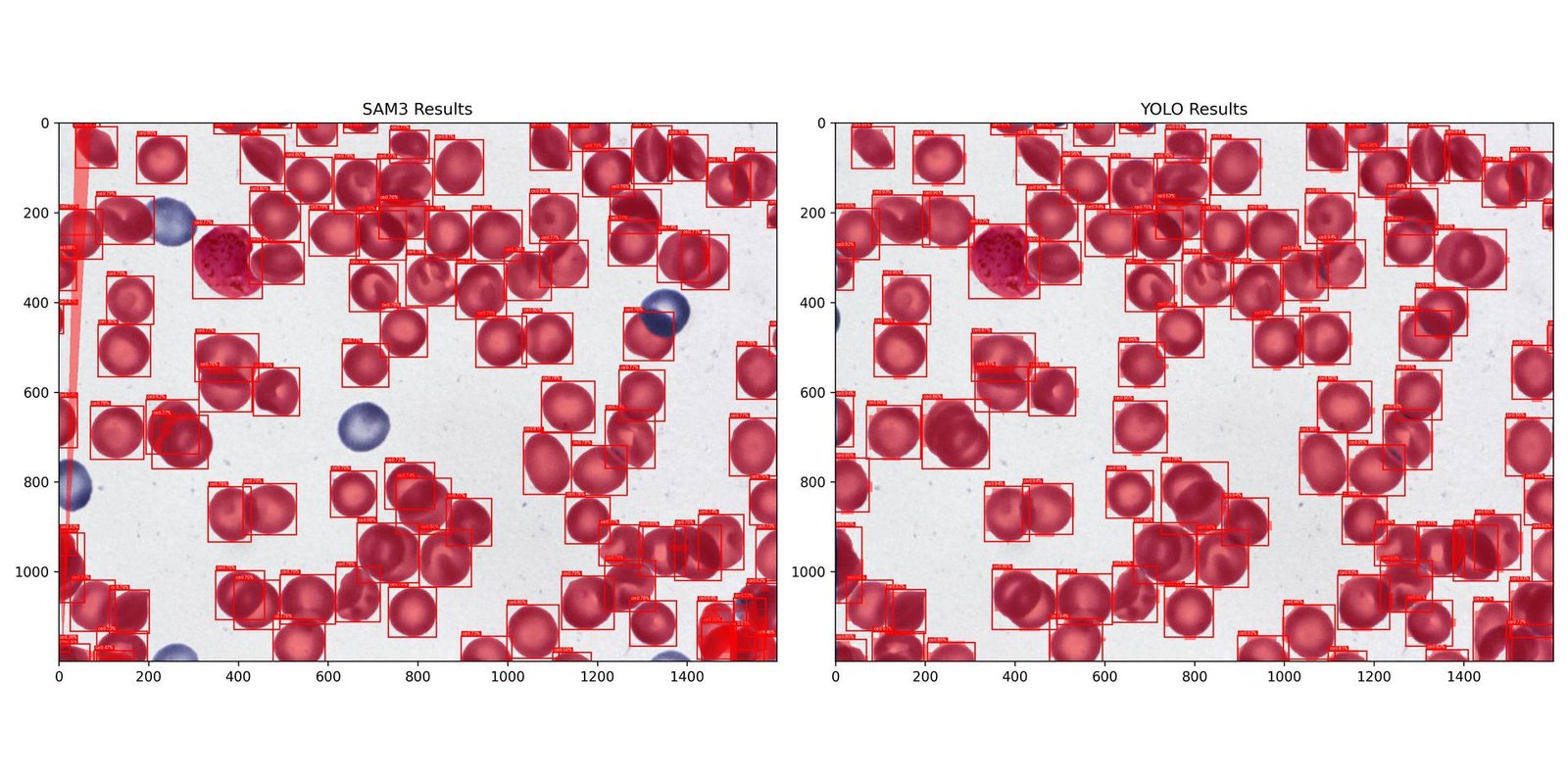
2. Blood Cell Segmentation
I included this dataset to check the fashions within the medical area. On the floor this felt like a transparent benefit for SAM3. The pictures don’t require complicated excessive decision patching and the cells usually have distinct clear edges which is strictly the place basis fashions often shine. Or not less than that was my speculation.
Just like the earlier activity I needed to convert semantic masks right into a COCO model occasion segmentation format. I initially had a priority concerning touching cells. If a number of cells had been grouped right into a single masks blob my preprocessing would deal with them as one occasion. This might create a bias the place the YOLO mannequin learns to foretell clusters whereas SAM3 accurately identifies particular person cells however will get penalized for it. Upon nearer inspection I discovered that the dataset offered effective gaps of some pixels between adjoining cells. Through the use of contour detection I used to be capable of separate these into particular person cases. I deliberately averted morphological dilation right here to protect these gaps and I ensured the SAM3 inference pipeline remained similar. The dataset offered its personal cut up with 1169 coaching photos and 159 validation photos.
I skilled a YOLOv11-Medium mannequin for 30 epochs. My solely vital change from the default settings was growing the weight_decay to supply extra aggressive regularization. The coaching was extremely environment friendly, taking solely 46 minutes.
Regardless of my preliminary perception that this could be a win for SAM3 the specialist mannequin once more outperformed the inspiration mannequin by 23.59% general. Even when the visible guidelines appear to favor a generalist the specialised coaching permits the smaller mannequin to seize the area particular nuances that SAM3 misses. You possibly can see from the outcomes above SAM3 is lacking numerous cases of cells.
| Metric | yolov11-Medium | SAM3 | Change |
|---|---|---|---|
| AP | 0.6634 | 0.5254 | -20.8 |
| AP50 | 0.8946 | 0.6161 | -31.13 |
| AP75 | 0.8389 | 0.5739 | -31.59 |
| AP_small | – | – | – |
| AP_medium | 0.6507 | 0.5648 | -13.19 |
| AP_large | 0.6996 | 0.4508 | -35.56 |
| AR_1 | 0.0112 | 0.01 | -10.61 |
| AR_10 | 0.1116 | 0.0978 | -12.34 |
| AR_100 | 0.7002 | 0.5876 | -16.09 |
| AR_small | – | – | – |
| AR_medium | 0.6821 | 0.6216 | -8.86 |
| AR_large | 0.7447 | 0.5053 | -32.15 |
Execution Particulars:
Saliency Object Detection / Picture Matting
On this use case we benchmark datasets that contain binary segmentation with foreground and background separation segmentation masks. The first software is picture enhancing duties like background elimination the place correct separation of the topic is important.
The Cube coefficient is our main analysis metric. In observe Cube scores rapidly attain values round 0.99 as soon as the mannequin segments nearly all of the area. At this stage significant variations seem within the slender 0.99 to 1.0 vary. Small absolute enhancements right here correspond to visually noticeable positive factors particularly round object boundaries.
We think about two metrics for our general comparability:
- Cube Coefficient: Weighted at 3.0
- MAE (Imply Absolute Error): Weighted at 0.01
Notice: I had additionally added F1-Rating however later realized that F1-Rating and Cube Coefficient are mathematically similar, Therefore I omitted it right here. Whereas specialised boundary centered metrics exist I excluded them to keep up our novice engineer persona. We need to see if somebody with fundamental expertise can beat SAM3 utilizing commonplace instruments.
Within the Weights & Biases (W&B) logs the specialist mannequin outputs might look objectively unhealthy in comparison with SAM3. This can be a visualization artifact brought on by binary thresholding. Our ISNet mannequin predicts a gradient alpha matte which permits for easy semi-transparent edges. To sync with W&B I used a hard and fast threshold of 0.5 to transform these to binary masks. In a manufacturing atmosphere tuning this threshold or utilizing the uncooked alpha matte would yield a lot greater visible high quality. Since SAM3 produces a binary masks of the field its outputs look nice in WandB. I recommend referring to the outputs given in pocket book’s output’s part.
Engineering the Pipeline :
For this activity I used ISNet, I utilized the mannequin code and pretrained weights from the official repository however carried out a customized coaching loop and dataset courses. To optimize the method I additionally carried out:
- Synchronized Transforms: I prolonged the torchvision transforms to make sure masks transformations (like rotation or flipping) had been completely synchronized with the picture.
- Combined Precision Coaching: I modified the mannequin class and loss operate to help combined precision. I used BCEWithLogitsLoss for numerical stability.
1. EasyPortrait Dataset
I wished to incorporate a excessive stakes background elimination activity particularly for selfie/portrait photos. That is arguably the most well-liked software of Saliency Object Detection immediately. The primary problem right here is hair segmentation. Human hair has excessive frequency edges and transparency which might be notoriously troublesome to seize. Moreover topics put on numerous clothes that may usually mix into the background colours.
The unique dataset gives 20,000 labeled face photos. Nevertheless the offered check set was a lot bigger than the validation set. Operating SAM3 on such a big check set would have exceeded the Kaggle GPU quota that week, I wanted that quota for different stuff. So I swapped the 2 units leading to a extra manageable analysis pipeline
- Practice Set: 14,000 photos
- Val Set: 4,000 photos
- Take a look at Set: 2,000 photos
Strategic Augmentations:
To make sure the mannequin could be helpful in actual world workflows somewhat than simply over becoming the validation set I carried out a sturdy augmentation pipeline, You possibly can see the augmentation above, however this was my considering behind augmentations
- Side Ratio Conscious Resize: I first resized the longest dimension after which took a hard and fast dimension random crop. This prevented the squashed face impact widespread with commonplace resizing.
- Perspective Transforms: Because the dataset consists principally of individuals wanting straight on the digicam I added sturdy perspective shifts to simulate angled seating or aspect profile pictures.
- Coloration Jitter: I diversified brightness and distinction to deal with lighting from underexposed to overexposed however stored the hue shift at zero to keep away from unnatural pores and skin tones.
- Affine Reworks: Added rotation to deal with numerous digicam tilts.

Because of compute limits I skilled at a decision of 640×640 for 16 epochs. This was a major drawback since SAM3 operates and was probably skilled at 1024×1024 decision, the coaching took 4 hours 45 minutes.
Even with the decision drawback and minimal coaching, the specialist mannequin outperformed SAM3 by 0.25% general. Nevertheless, the numerical outcomes masks an enchanting visible commerce off:
- The Edge High quality: Our mannequin’s predictions are at the moment noisier as a result of brief coaching length. Nevertheless, when it hits, the sides are naturally feathered, good for mixing.
- The SAM3 Boxiness: SAM3 is extremely constant however its edges usually appear to be excessive level polygons somewhat than natural masks. It produces a boxy, pixelated boundary that appears synthetic.
- The Hair Win: Our mannequin outperforms SAM3 in hair areas. Regardless of the noise, our mannequin captures the natural circulation of hair, whereas SAM3 usually approximates these areas. That is mirrored within the Imply Absolute Error (MAE), the place SAM3 is 27.92% weaker.
- The Clothes Wrestle: Conversely, SAM3 excels at segmenting clothes, the place the boundaries are extra geometric. Our mannequin nonetheless struggles with fabric textures and shapes.
| Mannequin | MAE | Cube Coefficient |
|---|---|---|
| ISNet | 0.0079 | 0.992 |
| SAM3 | 0.0101 | 0.9895 |
| Change | -27.92 | -0.25 |
The truth that a handicapped mannequin (decrease decision, fewer epochs) can nonetheless beat a basis mannequin on its strongest metric (MAE/Edge precision) is a testomony to area particular coaching. If scaled to 1024px and skilled longer, this specialist mannequin would probably present additional positive factors over SAM3 for this particular use case.
Execution Particulars:
Conclusion
Based mostly on this multi area benchmark, the info suggests a transparent strategic path for manufacturing stage Pc Imaginative and prescient. Whereas basis fashions like SAM3 characterize an enormous leap in functionality, they’re greatest utilized as improvement accelerators somewhat than everlasting manufacturing staff.
- Case 1: Fastened Classes & Obtainable labelled Knowledge (~500+ samples) Practice a specialist mannequin. The accuracy, reliability, and 30x sooner inference speeds far outweigh the small preliminary coaching time.
- Case 2: Fastened Classes however No labelled Knowledge Use SAM3 as an interactive labeling assistant (not automated). SAM3 is unmatched for bootstrapping a dataset. After you have ~500 prime quality frames, transition to a specialist mannequin for deployment.
- Case 3: Chilly Begin (No Photos, No labelled Knowledge) Deploy SAM3 in a low site visitors shadow mode for a number of weeks to gather actual world imagery. As soon as a consultant corpus is constructed, prepare and deploy a website particular mannequin. Use SAM3 to hurry up the annotation workflows.
Why does the Specialist Win in Manufacturing?
1. {Hardware} Independence and Price Effectivity
You do not want an H100 to ship prime quality imaginative and prescient. Specialist fashions like YOLOv11 are designed for effectivity.
- GPU serving: A single Tesla T4 (which prices peanuts in comparison with an H100) can serve a big consumer base with sub 50ms latency. It may be scaled horizontal as per the necessity.
- CPU Viability: For a lot of workflows, CPU deployment is a viable, excessive margin choice. Through the use of a robust CPU pod and horizontal scaling, you possibly can handle latency ~200ms whereas holding infrastructure complexity at a minimal.
- Optimization: Specialist fashions will be pruned and quantized. An optimized YOLO mannequin on a CPU can ship unbeatable worth at quick inference speeds.
2. Whole Possession and Reliability
Whenever you personal the mannequin, you management the answer. You possibly can retrain to handle particular edge case failures, handle hallucinations, or create atmosphere particular weights for various purchasers. Operating a dozen atmosphere tuned specialist fashions is usually cheaper and predictable than one huge, basis mannequin.
The Future Function of SAM3
SAM3 must be considered as a Imaginative and prescient Assistant. It’s the final software for any use case the place classes are usually not mounted resembling:
- Interactive Picture Enhancing: The place a human is driving the segmentation.
- Open Vocabulary Search: Discovering any object in an enormous picture/video database.
- AI Assisted Annotation: Reducing guide labeling time.
Meta’s staff has created a masterpiece with SAM3, and its idea stage understanding is a sport changer. Nevertheless, for an engineer seeking to construct a scalable, price efficient, and correct product immediately, the specialised Skilled mannequin stays the superior alternative. I sit up for including SAM4 to the combo sooner or later to see how this hole evolves.
Are you seeing basis fashions substitute your specialist pipelines, or is the fee nonetheless too excessive? Let’s talk about within the feedback. Additionally, in case you bought any worth out of this, I might respect a share!














{kind=link}