


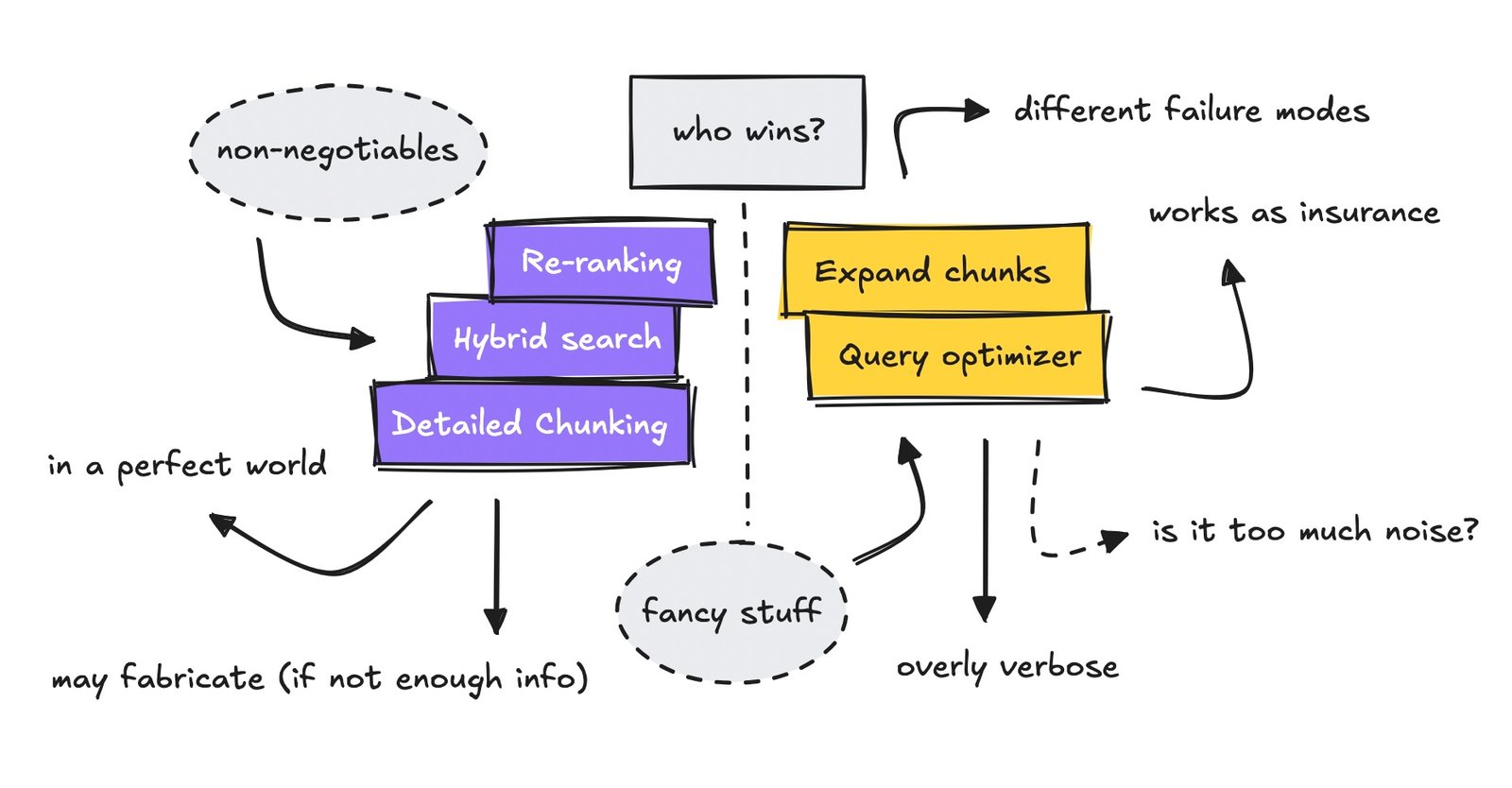
an article about overengineering a RAG system, including fancy issues like question optimization, detailed chunking with neighbors and keys, together with increasing the context.
The argument in opposition to this type of work is that for a few of these add-ons, you continue to find yourself paying 40–50% extra in latency and value.
So, I made a decision to take a look at each pipelines, one with question optimisation and neighbor enlargement, and one with out.
The primary take a look at I ran used easy corpus questions generated straight from the docs, and the outcomes have been lackluster. However then I continued testing it on messier questions and on random real-world questions, and it confirmed one thing totally different.
That is what we’ll discuss right here: the place options like neighbor enlargement can do properly, and the place the associated fee is probably not value it.
We’ll undergo the setup, the experiment design, three totally different analysis runs with totally different datasets, the right way to perceive the outcomes, and the associated fee/profit tradeoff.
Please be aware that this experiment is utilizing reference-free metrics and LLM judges, which you at all times need to be cautious about. You may see the whole breakdown in this excel doc.
If you happen to really feel confused at any time, there are two articles, right here and right here, that got here earlier than this one, although this one ought to stand by itself.
The intro
Individuals proceed so as to add complexity to their RAG pipelines, and there’s a motive for it. The general design is flawed, so we maintain patching on fixes to make one thing that’s extra sturdy.
Most individuals have launched hybrid search, BM25 and semantic, together with re-rankers of their RAG setups. This has turn out to be customary apply. However there are extra advanced options you possibly can add.

The pipeline we’re testing right here introduces two extra options, question optimization and neighbor enlargement, and checks their effectivity.
We’re utilizing LLM judges and totally different datasets to guage automated metrics like faithfulness, together with A/B checks on high quality, to see how the metrics transfer and alter for every.
The introduction will stroll via the setup and the experiment design.
The setup
Let’s first run via the setup, briefly protecting detailed chunking and neighbor enlargement, and what I outline as advanced versus naive for the aim of this text.
The pipeline I’ve run right here makes use of very detailed chunking strategies, for those who’ve learn my earlier article.
This implies parsing the PDFs accurately, respecting doc construction, utilizing sensible merging logic, clever boundary detection, numeric fragment dealing with, and document-level context (i.e. making use of headings for every chunk).
I made a decision to not budge on this half, although that is clearly the toughest a part of constructing a retrieval pipeline.
When processing, it additionally splits the sections after which references the chunk neighbors within the metadata. This enables us to broaden the content material so the LLM can see the place it comes from.
For this take a look at, we use the identical chunks, however we take away question optimization and context enlargement for the naive pipeline to see if the flowery add-ons are literally doing any good.

I must also point out that the use case for this was scientific RAG papers. It is a semi-difficult case, and as such, for simpler use circumstances this may occasionally not apply (however we’ll get to that later too).
You may see the papers this pipeline has ingested right here, and browse in regards to the use case right here.
To conclude: the setup makes use of the identical chunking, the identical reranker, and the identical LLM. The one distinction is optimizing the queries and increasing the chunks to neighbors.
The experiment design
We now have three totally different datasets that have been run via a number of automated metrics, then via a head-to-head choose, together with inspecting the outputs to validate and perceive the outcomes.
I began by making a dataset with 256 questions generated from the corpus. This implies questions corresponding to “What’s the primary objective of the Step-Audio 2 mannequin?”
This could be a good option to validate that your pipeline works, but when it’s too clear it can provide you a false sense of safety.
Be aware that I didn’t specify how the questions must be generated. This implies I didn’t ask it to generate questions that a complete part may reply, or that solely a single chunk may reply.

The second dataset was additionally generated from the corpus, however I deliberately requested the LLM to generate messy questions like “what are the plz three sorts of reward features utilized in eviomni?”
The third dataset, and a very powerful one, was the random dataset.
I requested an AI agent to analysis totally different RAG questions individuals had on-line, corresponding to “greatest rag eval benchmarks and why?” and “when does utilizing titles/abstracts beat full textual content retrieval.”
Keep in mind, the pipeline had solely ingested round 150 scientific papers from September/October that talked about RAG. So we don’t know if the corpus even has the solutions.
To run the primary evals, I used automated metrics corresponding to faithfulness (does the reply keep grounded within the context) and reply relevancy (does it reply the question) from RAGAS. I additionally added a number of metrics from DeepEval to have a look at context relevance, construction, and hallucinations.
If you wish to get an outline of those metrics, see my earlier article.
We ran each pipelines via the totally different datasets, after which via all of those metrics.
Then I added one other head-to-head choose to A/B take a look at the standard of every pipeline for every dataset. This choose didn’t see the context, solely the query, the reply, and the automated metrics.
Why not embrace the context within the analysis? As a result of you possibly can’t overload these judges with too many variables. That is additionally why evals can really feel tough. You have to perceive the one key metric you need to measure for each.
I ought to be aware that this may be an unreliable option to take a look at methods. If the hallucination rating is generally vibes, however we take away a knowledge level due to it earlier than sending it into the subsequent choose that checks high quality, we are able to find yourself with extremely unreliable knowledge as soon as we begin aggregating.
For the ultimate half, we checked out semantic similarity between the solutions and examined those with the most important variations, together with circumstances the place one pipeline clearly gained over the opposite.
Let’s now flip to working the experiment.
Operating the experiment
Since now we have a number of totally different datasets, we have to undergo the outcomes of every. The primary two datasets proved fairly lackluster, however they did present us one thing, so it’s value protecting them.
The random dataset confirmed essentially the most attention-grabbing outcomes thus far. This would be the primary focus, and I’ll dig into the outcomes a bit to point out the place it failed and the place it succeeded.
Keep in mind, I’m making an attempt to replicate actuality right here, which is usually quite a bit messier than individuals need it to be.
Clear questions from the corpus
The clear corpus confirmed fairly an identical outcomes on all metrics. The choose appeared to favor one over the opposite primarily based on shallow preferences, but it surely confirmed us the difficulty with counting on artificial datasets.
The primary run was on the corpus dataset. Keep in mind the clear questions that had been generated from the docs the pipeline had ingested.
The outcomes of the automated metrics have been eerily related.

Even context relevance was just about the identical, ~0.95 for each. I needed to double verify it a number of instances to verify. As I’ve had nice success with utilizing context enlargement, the outcomes made me a bit uneasy.
It’s fairly apparent although in hindsight, the questions are already properly formatted for retrieval, and one passage could reply the query.
I did have the thought on why context relevance didn’t lower for the expanded pipeline if one passage was ok. This was as a result of the additional contexts come from the identical part because the seed chunks, making them semantically associated and never thought of “irrelevant” by RAGAS.
The A/B take a look at for high quality we ran it via had related outcomes. Each gained for a similar causes: completeness, accuracy, readability.

For the circumstances the place naive gained, the choose favored the reply’s conciseness, readability, and focus. It penalized the advanced pipeline for extra peripheral particulars (edge circumstances, additional citations) that weren’t straight requested for.
When advanced gained, it favored the completeness/comprehensiveness of the reply over the naive one. This meant having particular numbers/metrics, step-by-step mechanisms, and “why” explanations, not simply “what.”
Nonetheless, these outcomes didn’t level to any failures. This was extra a choice factor relatively than about pure high quality variations, each did exceptionally properly.
So what did we study from this? In an ideal world, you don’t want any fancy RAG add-ons, and utilizing a take a look at set from the corpus is extremely unreliable.
Messy questions from the corpus
Subsequent up we examined the second dataset, which confirmed related outcomes as the primary one because it had been synthetically generated, but it surely began shifting in one other path, which was attention-grabbing.
Do not forget that I launched the messier questions generated from the corpus earlier. This dataset was generated the identical means as the primary one, however with messy phrasing (“can u clarify like how plz…”).
The outcomes from the automated metrics confirmed that the outcomes have been nonetheless very related, although context relevance began to drop within the advanced one whereas faithfulness began to rise barely.

For those that failed the metrics, there have been a number of RAGAS false positives.
However there have been additionally some failures for questions that had been formatted with out specificity within the artificial dataset, corresponding to “what number of posts tbh have been used for dataset?” or “what number of datasets did they take a look at on?”
There have been some questions that the question optimizer helped by eradicating noisy enter. However I noticed too late that the questions that had been generated have been too directed at particular passages.
This meant that pushing them in as they have been did properly on the retrieval facet. I.e., questions with particular names in them (like “how does CLAUSE evaluate…”) matched paperwork positive, and the question optimizer simply made issues worse.
There have been instances when the question optimization failed fully due to how the questions had been phrased.
Such because the query: “how does the btw pre-check part in ac-rag work & why is it essential?” the place direct search discovered the AC-RAG paper straight, because the query had been generated from there.
Operating it via the A/B choose, the outcomes favored the superior pipeline much more than they’d for the primary corpus.

The choose favored naive’s conciseness and brevity, whereas it favored the advanced pipeline for completeness and comprehensiveness.
The explanation we see the rise in wins for the advanced pipeline is that the choose more and more selected “full however verbose” over “temporary however probably lacking points” this time round.
That is once I had the thought how ineffective reply high quality is as a metric. These LLM judges run on vibes generally.
On this run, I didn’t suppose the solutions have been totally different sufficient to warrant the distinction in outcomes. So keep in mind, utilizing an artificial dataset like this can provide you some intel, however it may be fairly unreliable.
Random questions dataset
Lastly, we’ll undergo the outcomes from the random dataset, which confirmed much more attention-grabbing outcomes. Metrics began to maneuver with the next margin right here, which gave us one thing to dig into.
Up so far I had nothing to point out for this, however this final dataset lastly gave me one thing attention-grabbing to dig into.
See the outcomes from the random dataset under.

On random questions, we really noticed a drop in faithfulness and reply relevancy for the naive baseline. Context relevance was nonetheless increased, together with construction, however this we had already established for the advanced pipeline within the earlier article.
Noise will inevitably occur for the advanced one, as we’re speaking about 10x extra chunks. Quotation construction could also be more durable for the mannequin when the context will increase (or the choose has hassle judging the total context).
The A/B choose, although, gave it a really excessive rating in comparison with the opposite datasets.

I ran it twice to verify, and every time it favored the advanced one over the naive one by an enormous margin.
Why the change? This time there have been numerous questions that one passage couldn’t reply by itself.
Particularly, the advanced pipeline did properly on tradeoff and comparability questions. The choose reasoned “extra full/complete” in comparison with the naive pipeline.
An instance was the query “what are execs and cons of hybrid vs knowledge-graph RAG for obscure queries?” Naive had many unsupported claims (lacking GraphRAG, HybridRAG, EM/F1 metrics).
At this level, I wanted to grasp why it gained and why naive misplaced. This may give me intel on the place the flowery options have been really serving to.
Trying into the outcomes
Now, with out digging into the outcomes, you possibly can’t absolutely know why one thing is successful. For the reason that random dataset confirmed essentially the most attention-grabbing outcomes, that is the place I made a decision to place my focus.
First, the choose has actual points evaluating the fuller context. For this reason I may by no means create a choose to guage every context in opposition to the opposite. It might favor naive as a result of it’s cognitively simpler to guage. That is what made this so onerous.
Nonetheless, we are able to pinpoint among the actual failures.
Although the hallucination metric confirmed first rate outcomes, when digging into it, we may see that the naive pipeline fabricated info extra usually.
We may find this by trying on the low faithfulness scores.
To offer you an instance, for the query “how do I take a look at immediate injection dangers if the dangerous textual content is inside retrieved PDFs?” the naive pipeline crammed in gaps within the context to supply the reply.
Query: How do I take a look at immediate injection dangers if the dangerous textual content is inside retrieved PDFs?
Naive Response: Lists customary prompt-injection testing steps (PoisonedRAG, adaptive directions, multihop poisoning) however synthesizes a generic analysis recipe that isn't absolutely supported by the precise retrieved sections and implicitly fills gaps with prior information.
Complicated Response: Derives testing steps straight from the retrieved experiment sections and risk fashions, together with multihop-triggered assaults, single-text era bias measurement, adaptive immediate assaults, and success-rate reporting, staying inside what the cited papers really describe.
Faithfulness: Naive: 0.0 | Complicated: 0.83
What Occurred: Not like the naive reply, it isn't inventing assaults, metrics, or methods out of skinny air. PoisonedRAG, trigger-based assaults, Hotflip-style perturbations, multihop assaults, ASR, DACC/FPR/FNR, PC1–PC3 all seem within the offered paperwork. Nevertheless, the advanced pipeline is subtly overstepping and has a case of scope inflation.The expanded content material added the lacking analysis metrics, which bumped up the faithfulness rating by 87%.
Nonetheless, the advanced pipeline was subtly overstepping and had a case of scope inflation. This might be a difficulty with the LLM generator, the place we have to tune it to ensure that every declare is explicitly tied to a paper and to mark cross-paper synthesis as such.
For the query “how do I benchmark prompts that pressure the mannequin to record contradictions explicitly?” naive once more has only a few metrics and thus invents metrics, reverses findings, and collapses process boundaries.
Query: How do I benchmark prompts that pressure the mannequin to record contradictions explicitly?
Naive Response: Mentions MAGIC by title and vaguely gestures at “conflicts” and “benchmarking,” however lacks concrete mechanics. No clear description of battle era, no separation of detection vs localization, no precise analysis protocol. It fills gaps by inventing generic-sounding steps that aren't grounded within the offered contexts.
Complicated Response: Explicitly aligns with the MAGIC paper’s methodology. Describes KG-based battle era, single-hop vs multi-hop and 1 vs N conflicts, subgraph-level few-shot prompting, stepwise prompting (detect then localize), and the precise ID/LOC metrics used throughout a number of runs. Additionally accurately incorporates PC1–PC3 as auxiliary immediate parts and explains their position, in line with the cited sections.
Faithfulness: Naive: 0.35 | Complicated: 0.73
What Occurred: The advanced pipeline has much more floor space, however most of it's anchored to precise sections of the MAGIC paper and associated prompt-component work. Briefly: the naive reply hallucinates by necessity resulting from lacking context, whereas the advanced reply is verbose however materially supported. It over-synthesizes and over-prescribes, however largely stays throughout the factual envelope. The upper faithfulness rating is doing its job, even when it offends human endurance.For advanced, although, it over-synthesizes and over-prescribes, however stays throughout the factual info.
This sample reveals up in a number of examples. The naive pipeline lacks sufficient info for a few of these questions, so it falls again to prior information and sample completion. Whereas the advanced pipeline over-synthesizes underneath false coherence.
Basically, naive fails by making issues up, and sophisticated fails by saying true issues too broadly.
This take a look at was extra about determining if these fancy options assist, but it surely did level to us needing to work on declare scoping: forcing the mannequin to say “Paper A reveals X; Paper B reveals Y,” and so forth.
You may dig into a number of of those questions within the sheet right here.
Earlier than we transfer on to the associated fee/latency evaluation, we are able to attempt to isolate the question optimizer as properly.
How a lot did the question optimizer assist?
Since I didn’t take a look at every a part of the pipeline for every run, we had to have a look at various things to estimate whether or not the question optimizer was serving to or hurting.
First, we appeared on the seed chunk overlap for the advanced vs naive pipeline, which confirmed 8.3% semantic overlap within the random pipeline, versus greater than 50% overlap for the corpus pipeline.
We already know that the total pipeline gained on the random dataset, and now we may additionally see that it surfaced totally different paperwork due to the question optimizer.
Most paperwork have been totally different, so I couldn’t isolate whether or not the standard degraded when there was little overlap.
We additionally requested a choose to estimate the standard of the optimized queries in comparison with the unique ones, when it comes to preserving intent and being numerous sufficient, and it gained with an 8% margin.
A query that it excelled on was “why is everybody saying RAG doesn’t scale? how are individuals fixing that?”
Orginal: why is everybody saying RAG would not scale? how are individuals fixing that?
Optimized (1): RAG scalability challenges (hybrid)
Optimized (2): Options for RAG scalability (hybrid)Whereas a query that naive did properly by itself was “what retrieval settings assist cut back needle-in-a-haystack,” and different questions that have been very properly formatted from the beginning.
We may fairly deduce, although, that multi-questions and messier questions did higher with the optimizer, so long as they weren’t area particular. The optimizer was overkill for properly formatted questions.
It additionally did badly when the query would already be understood by the underlying paperwork, in circumstances the place somebody asks one thing area particular that the question optimizer gained’t perceive.
You may look via a number of examples within the Excel doc.
This teaches us how essential it’s to ensure that the optimizer is tuned properly to the questions that customers will ask. In case your customers maintain asking with area particular jargon that the optimizer is ignoring or filtering out, it gained’t carry out properly.
We will see right here that it’s rescuing some questions and failing others on the identical time, so it might want work for this use case.
Let’s focus on it
I’ve overloaded you with numerous knowledge, so now it’s time to undergo the associated fee/latency tradeoff, focus on what we are able to and can’t conclude, and the restrictions of this experiment.
The associated fee/latency tradeoff
When trying on the price and latency tradeoffs, the purpose right here is to place concrete numbers on what these options price and the place it really comes from.
The price of working this pipeline may be very slim. We’re speaking $0.00396 per run, and this doesn’t embrace caching. Eradicating the question optimizer and neighbor enlargement decreases prices by 41%.
It’s no more than that as a result of token inputs, the factor that will increase with added context, are fairly low-cost.
What really prices cash on this pipeline is the re-ranker from Cohere, which each the naive and the total pipeline use.
For the naive pipeline, the re-ranker accounts for 70% of the whole price. So it’s value taking a look at each a part of the pipeline to determine the place you would possibly implement smaller fashions to chop prices.
Nonetheless, at round 100k questions, you’d be paying $400.00 for the total pipeline and $280.00 for the naive one.
There may be additionally the case for latency.
We measured a +49% enhance in latency with the advanced pipeline, which quantities to about 6 seconds, largely pushed by the question optimizer utilizing GPT-5-mini. It’s attainable to make use of a sooner and smaller mannequin right here.
For neighbor enlargement, we measured the common enhance to be 2–3 seconds longer. Do be aware that this doesn’t scale linearly.
4.4x extra enter tokens solely added 24% extra time.
You may see the whole breakdown within the sheet right here.
What this reveals is that the associated fee distinction is actual however not excessive, whereas the latency distinction is way more noticeable. A lot of the cash continues to be spent on re-ranking, not on including context.
What we are able to conclude
Let’s deal with what labored, what failed, and why. We see that neighbor enlargement could pull it’s weight when questions are diffuse, however every pipeline has it’s personal failure modes.
The clearest discovering from this experiment is that neighbor enlargement earns its maintain when retrieval will get onerous and one chunk can’t reply the query.
We did a take a look at within the earlier article that checked out how a lot of the reply was generated from the expanded chunks, and on clear corpus questions, solely 22% of the reply content material got here from expanded neighbors. We additionally noticed that the A/B outcomes right here on this article confirmed a tie.
On messy questions, this rose to 30% with a 10-point margin for the A/B take a look at. On random questions, it hit 41% (used from the context) with a 44-point margin for the A/B take a look at. This sample is plain.
What’s taking place beneath is a distinction in failure modes. When naive fails, it fails by omission. The LLM doesn’t have sufficient context, so it both offers an incomplete reply or fabricates info to fill the gaps.
We noticed this clearly within the immediate injection instance, the place naive scored 0.0 on faithfulness as a result of overreached on the details.
When advanced fails, it fails by inflation. It has a lot context that the LLM over-synthesizes and makes claims broader than any single supply helps. However a minimum of these claims are grounded in one thing.
The faithfulness scores replicate this asymmetry. Naive bottoms out at 0.0 or 0.35, whereas advanced’s worst circumstances nonetheless land round 0.73.
The question optimizer is more durable to name. It helped on 38% of questions, damage on 27%, and made no distinction on 35%. The wins have been dramatic after they occurred, rescuing questions like “why is everybody saying RAG doesn’t scale?” the place direct search returned nothing.
However the losses have been additionally not nice, corresponding to when the person’s phrasing already matched the corpus vocabulary and the optimizer launched drift.
This most likely suggests you’d need to tune the optimizer rigorously to your customers, or discover a option to detect when reformulation is probably going to assist versus damage.
On price and latency, the numbers weren’t the place I anticipated. Including 10x extra chunks solely elevated era time by 24% as a result of studying tokens is quite a bit cheaper.
The true price driver is the reranker, at 70% of the naive pipeline’s complete.
The question optimizer contributes essentially the most latency, at almost 3 seconds per query. If you happen to’re optimizing for velocity, that’s the place to look first, together with the re-ranker.
So extra context doesn’t essentially imply chaos, but it surely does imply you have to management the LLM to a bigger diploma. When the query doesn’t want the complexity, the naive pipeline will rule, however as soon as questions turn out to be diffuse, the extra advanced pipeline could begin to pull its weight.
Let’s speak limitations
I’ve to cowl the principle limitations of the experiment and what we must be cautious about when deciphering the outcomes.
The plain one is that LLM judges run on vibes.
The metrics moved in the fitting path throughout datasets, however I wouldn’t belief absolutely the numbers sufficient to set manufacturing thresholds on them.
The messy corpus confirmed a 10-point margin for advanced, however truthfully the solutions weren’t totally different sufficient to warrant that hole. It it might be noise.
I additionally didn’t isolate what occurs when the docs genuinely can’t reply the query.
The random dataset included questions the place we didn’t know if the papers had related content material, however I handled all 66 the identical. I did although hunt via the examples, but it surely’s nonetheless attainable among the advanced pipeline’s wins got here from being higher at admitting ignorance relatively than higher at discovering info.
Lastly, I examined two options collectively, question optimization and neighbor enlargement, with out absolutely isolating each’s contribution. The seed overlap evaluation gave us some sign on the optimizer, however a cleaner experiment would take a look at them independently.
For now, we all know the mixture helps on onerous questions and that the associated fee is 41% extra per question. Whether or not that tradeoff is smart relies upon solely on what your customers are literally asking.
Notes
I feel we are able to conclude from this text that doing evals is difficult, and it’s even more durable to place an experiment like this on paper.
I want I may offer you a clear reply, but it surely’s difficult.
I might personally say although that fabrication is worse than being overly verbose. However nonetheless in case your corpus is extremely clear and every reply often factors to a selected chunk, the neighbor enlargement is overkill.
This then simply tells you that these fancy options are a type of insurance coverage.
Nonetheless I hope it was informational, let me know what you thought by connecting with me at LinkedIn, Medium or through my web site.
❤
Keep in mind you possibly can see the total breakdown and numbers right here.













{kind=link}