


“The event of arithmetic towards better precision has led, as is well-known, to the formalization of enormous tracts of it, in order that one can show any theorem utilizing nothing however just a few mechanical guidelines.”
— Ok. Gödel
In Half 1, we constructed a proof checker and developed a psychological mannequin for why we must always belief proofs that come out of an LLM: so long as now we have formalized reasoning and a sound verifier, a “few mechanical guidelines” are all we want. So how can we practice an LLM to generate legitimate proofs?
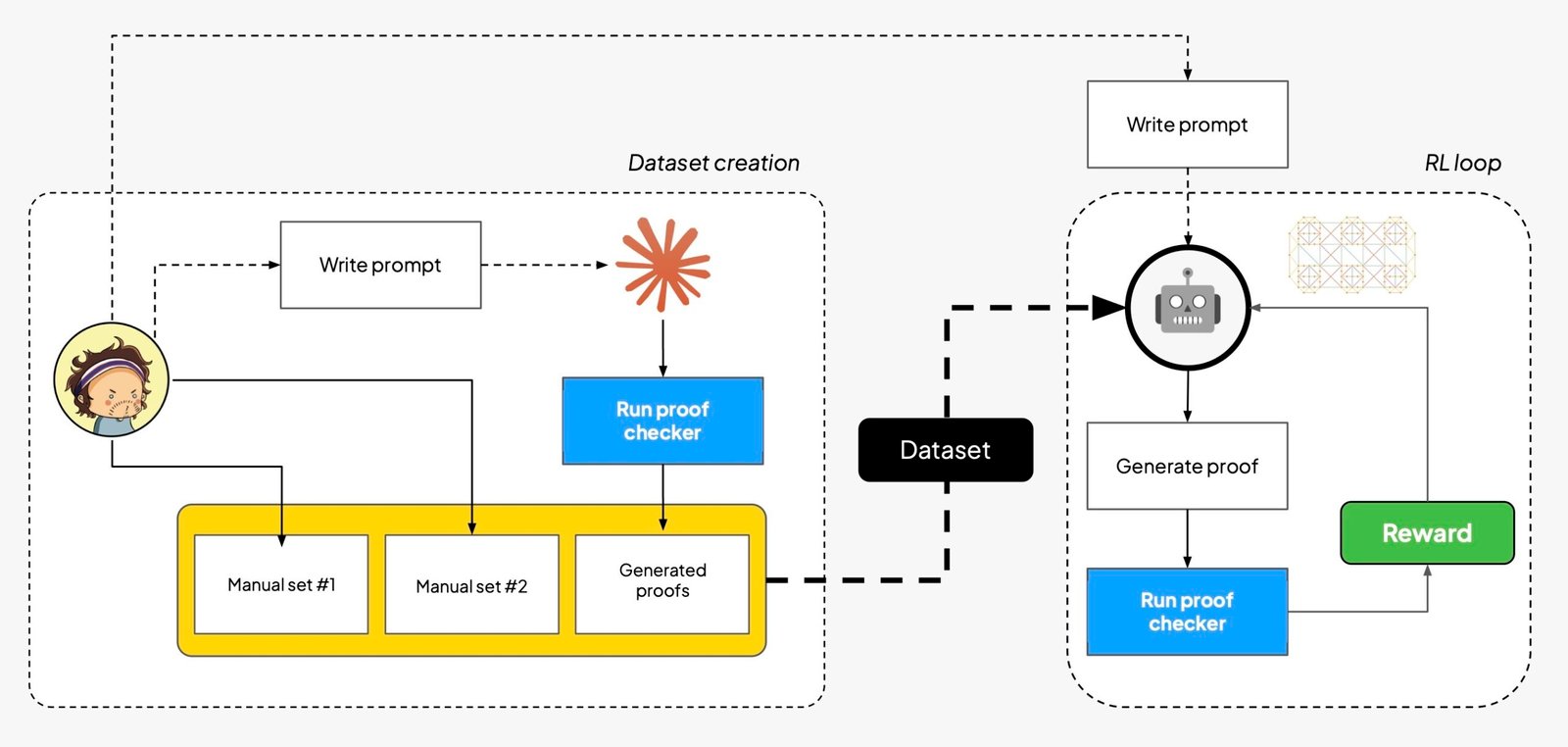
As DeepSeek fantastically confirmed, the identical instinct behind AI studying the sport of Go works for AI studying how you can motive, so long as reasoning may be checked (and now we all know it will possibly). On this second half we put to good use our verifier and construct an end-to-end RL coaching loop to fine-tune an open-source mannequin to supply proofs within the language we launched partly 1: at a look, the next determine reveals the essential substances of the circulate.

TL;DR: after some machine-human collaboration to generate a dataset (leveraging our checker as a sanity verify on LLM-generated examples), we run on Tinker an RL loop to do LoRA-style fine-tuning of open-source fashions. We immediate the mannequin with (1) how our language works, (2) how you can apply guidelines to construct proofs, and (3) how you can format solutions so that they’re simple to parse. Each proof is then run by the proof checker, and the reward will get propagated again to enhance the mannequin’s skills: ideally, the mannequin will begin with largely failing proof makes an attempt, after which get progressively higher because the coaching progresses.
Notice that whereas the sequence particularly targets mathematical reasoning, verifiable proofs are elementary in constructing confidence in distributed software program techniques. As some specialists argued, AI could be the lacking ingredient for proving software program correctness at scale!
Buckle up, clone the repo, and code alongside. Should you skipped the primary half, you’ll be able to learn it right here!
Dataset technology
“Folks assume arithmetic is sophisticated. Arithmetic is the easy bit. It’s the stuff we are able to perceive. It’s cats which can be sophisticated.” — J. Conway
To get a reward to enhance our mannequin, we want examples of proofs within the first place: ideally, we want a mixture of simple and laborious proofs, written in our personal reasoning language. We are able to’t simply generate random strings in our alphabet as a result of we’d just like the mannequin to attempt to show issues that we all know are provable within the first place! How can we bootstrap the method?
Our coaching combination is a mixture of three sources:
- A guide translation of workouts (premises->conclusion) taken from forallx, which we assume are solvable proofs;
- A guide translation of workouts (premises->conclusion) taken from Language, Proof and Logic, which we assume are solvable proofs;
- A corpus of proofs generated by a strong LLM (Sonnet by Anthropic). Since we can’t assume that LLM-generated premises->conclusion tuples are appropriate, we immediate the LLM to generate a full proof, which (you guessed it!) will get checked by our proof checker earlier than being added to the coaching set.
A single remark within the dataset appears like the next object:
{"premises": ["P", "Q"], "conclusion": "P and Q", "num_steps": 1}
i.e., a set of premises, a conclusion and what number of steps Sonnet took to generate a legitimate proof: premises and conclusion will find yourself within the immediate throughout RL (as we are going to ask the mannequin to discover a proof of the conclusion from the premises), and num_steps is a handy worth to print out some statistics on the perceived issue of the coaching set (assuming for simplicity that the size of a proof loosely correlates with its issue).
Reinforcement Studying on Tinker
“One of the simplest ways to have a good suggestion is to have plenty of concepts.”
— attributed to L. “
We at the moment are able to get our personal, smaller, open-source LLM for Vibe Proving. There are lots of recipes and providers on-line to carry out RL on open-source fashions, however we picked Tinker because it guarantees to summary away the infrastructure and many of the boilerplate required (it’s also the brand new child on the block, so it’s an opportunity to try it out!).
The coaching loop itself doesn’t have many surprises:
- Pattern: given the immediate and a tuple (premises->conclusion), we ask the mannequin to generate a number of proof makes an attempt.
- Confirm: we run every try by the proof checker.
- Reward: legitimate proofs (i.e. proofs which can be totally parseable and logically appropriate) get reward 1, each different end result will get 0 (‘Do or don’t‘, certainly). Notice that we additionally verify that the generated proof has the identical (premises->conclusion) as our request, to keep away from having the LLM simply gaming the system by at all times producing a trivially appropriate proof.
- Replace: we alter the mannequin weights to make profitable proofs extra possible.
Following Tinker’s personal pointers, we select to experiment with MoE reasoning fashions in just a few sizes: gpt-oss-20b, gpt-oss-120b and Qwen3-30B-A3B-Instruct-2507. Throughout coaching, logs and proofs are saved within the training_logs folder: on the finish, our (vibe coded!) app can be utilized to visualise the metric developments and examine the generated proofs.

If you’re utilizing an AI assistant to watch the coaching (which I experimented with for the primary time with this challenge), an attention-grabbing knowledge slice to trace is the proofs from textbooks, since they’re designed to be tough. For instance, the next is a standing replace from Claude Code:

How good is our vibe proving?
Throughout just a few runs and a little bit of tinkering with the parameters, we at all times find yourself with fashions that may show nearly all of the generated examples, however wrestle on some textbook proofs. It’s instructive and barely amusing to examine the generated proofs.
On the success facet, that is an try at proving DeMorgan’s legislation, i.e. exhibiting how you can go from ['not A or not B'] to not (A and B), by first assuming A and B and proving a contradiction:
- not A or not B (premise)
- | A and B (subproof)
- | A (2)
- | B (2)
- || not A (nested subproof, from 1)
- || ~ (3,5)
- || not B (nested subproof)
- || ~ (4,7)
- | (1, 5-6, 7-8)
- QED
On the failure facet, no mannequin efficiently proved from 'A or B', 'not A or C', 'not B or D' that C or D , struggling to correctly handle nested subproofs and apply the rule of explosion, as proven from this hint:
- A or B (premise)
- not A or C (premise)
- not B or D (premise)
- | A (subproof)
- || not A (nested subproof)
- || ~ (4,5)
- | C (5-6) ← ERROR
- ….
How simple was Tinker?
Our small proof of idea is hardly a stress check for a coaching service at scale, however it was sufficient to get some grounded impressions of the system.
The mixture of excellent public examples, Claude-friendly documentation and {hardware} abstraction made for a pleasing, light introduction to RL, at an inexpensive value (all of the experiments for the weblog publish value $60 or so, together with preliminary runs that – in hindsight! – had been clearly a waste of money and time!).
Whenever you get the dangle of it and begin to run just a few jobs in parallel, the shortage of monitoring and observability turns into a problem: generally my runs slowed down considerably (getting try_again responses for a very long time, as if the system was overloaded), and a few jobs failed in some unspecified time in the future for unclear causes (however, positive sufficient, you’ll be able to restart from a earlier checkpoint). Contemplating the affordable worth and the prototype nature of my workloads, none of those points outweighed the professionals, and I walked away with a optimistic sufficient Tinker expertise that I might undoubtedly use it once more for a future challenge.
See you, RL cowboys!
“We do this stuff not as a result of they’re simple, however as a result of we thought they had been going to be simple.” — Nameless
Whereas Tinker certainly makes the coaching course of (largely) seamless, the satan continues to be within the (RL) particulars: we barely scratched the floor to date, as our purpose was to go from zero to a Vibe Proving stack, not optimizing RL per se.
The excellent news is that the circulate is pretty modular, so that every one parts might be improved and tinkered with (type of) independently:
- mannequin selection: mannequin sort, mannequin measurement, supplier …
- coaching parameters: choose studying charge, batch measurement, LoRA rank …
- code abstractions: re-write the code with RL Envs …
- immediate optimization: higher directions, simpler formatting, helpful in-context examples, …
- dataset optimization: extra numerous examples, curriculum studying (not simply various the proof issue, however for instance beginning with proofs which can be executed aside from one lacking step, then proofs with two lacking steps and so forth. till the mannequin must fill the whole proof) …
In the identical vein, our personal customized proof language is certainly not sufficient to get attention-grabbing outcomes: we might enhance on it, however attending to one thing usable truly would require an astounding quantity of labor. For these causes, you’re higher off migrating to a purpose-built language, corresponding to Lean: importantly, now that you realize about proofs-as-formalized-reasoning, the identical psychological mannequin carries over to a language that’s (method) extra expressive. Furthermore, Lean has just about the identical type for writing down proofs, i.e. guidelines for introducing and eliminating logical operators.
In different phrases, as soon as we nail the mathematics behind Vibe Proving and construct an preliminary RL harness, what’s left is sweet ol’ engineering.
Acknowledgements
Due to Patrick John Chia, Federico Bianchi, Ethan Rosenthal, Ryan Vilim, Davis Treybig for valuable suggestions over earlier variations of this draft.
Should you just like the intersection of genAI, reasoning about distributed techniques and verification, you can too try our analysis at Bauplan.
AI coding assistants had been used to jot down the companion repository, however no assistant was used to jot down the textual content (if not for proof-reading and typo correction).
















{kind=link}